[학부연구생]
1.[Paper] SimCSE: Simple Contrastive Learning of Sentence Embeddings

교수님이 추천해주신 논문 중 첫번째인 SimCSE: Simple Contrastive Learning of Sentence Embeddings 를 살펴보려고 한다. 논문은 역시나 SimCSE 에 대해 다루고 있는데, 논문의 첫 줄에서 소개한 SimCSE는 다음과 같다.
2.[Plan] 공부할 것들

https://velog.io/@stapers/Contextual-Embedding-How-Contextual-are-Contextualized-Word-Representationshttps://wikidocs.net/31379https://
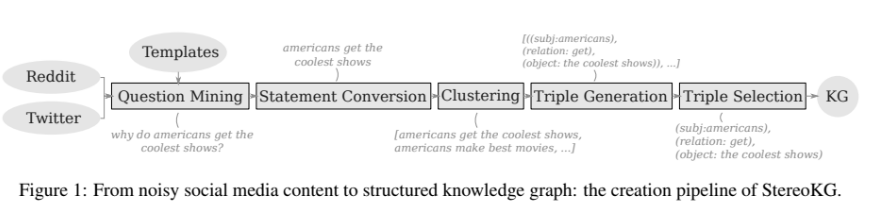
3.[Plan] StereoKG: Data-Driven Knowledge Graph Construction for Cultural Knowledge and Stereotypes
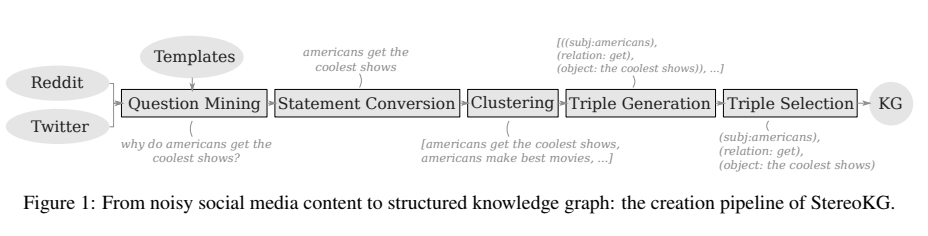
다음 논문 을 읽고 정리한 글입니다. present a fully data-driven pipeline for generating a knowledge graph (KG) of cultural knowledge and stereotpyes (문화 지식과 stereoty
4.[Plan] Mitigating Gender Bias in NLP: Literature Review

Bias 에 대한 기본 개념 논문을 정리한 글이다. 원본 논문 보기 NLP 모델이 다양한 적용 분야에서 성공적이었지만 기존 text corpora 의 gender bias 를 propagate, evem amplify 하는 문제가 존재한다. 이 논문은 현재의 recog
5.[Paper] A Contrastive Framework for Neutral Text Generation

역시나 Contrastive learning에 관한 논문이긴한데, 이전에 살펴본 논문과는 다른 loss 식을 적용하여 비슷한 문장은 큰 오류, 다른 문장에 작은 오류를 줬다. 결론적으로 비슷한 단어가 나오지 않도록 학습하는 것이 목적인데, 구체적으로 살펴보자! A Co
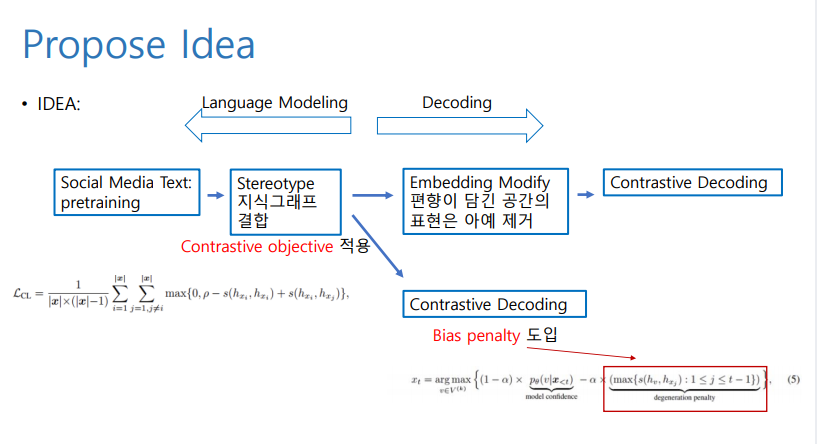
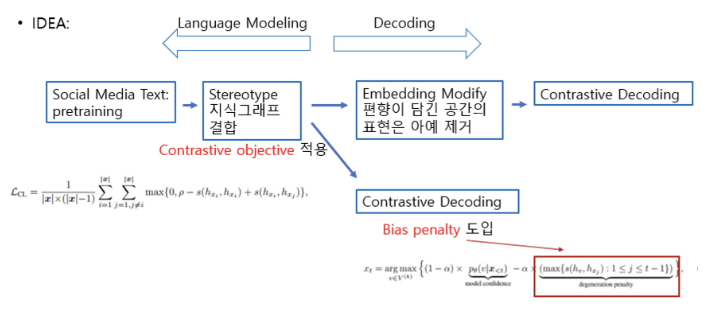
6.[Idea] Seminar Ideas
왜 읽게 되었는지? 논문의 어떤 부분이 중요한지?논문 내용과 실험 결과 문제 해결을 원하는 부분과 Idea 구체적으로 어떤 method or model 을 사용할지 소셜 미디어 텍스트 (편향 포함) + 지도 학습의 경우 neural LM 편향이 발생. 소셜 미디어 텍스
7.[PPT] Seminar ppt

보충할 부분 제외하고 세미나 할 PPT를 완성했다!
8.[Idea] Seminar Idea (2)
내일 할 세미나 아이디어 정리랑 Research Qeustion 까지 조금 더 구체적으로 생각해봤다!
9.[Plan] 공부할 것들
기본적으로 틀은 잘 짜여져있고 앞쪽 loss 식에 Contrastive 아이디어를 더하는 방향으로 연구하자고 하셨다. 전체적인 구조를 잘 생각해왔다고 말씀해주셔서 다행이었다 ㅎㅎ
10.[Code] SimCTG 코드 뜯어보기
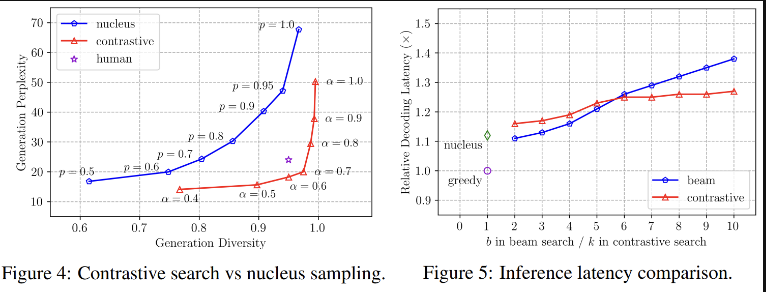
기존에 SimCTG 의 loss function 을 이용해 훈련시키고자 하는 언어모델은 다음과 같았다. SimCTG를 왜 쓰는가? 의 문제. SimCTG 는 언어모델링 시에 Contrastive Learning 을 하기위해 끌고온 아이디어이다.Anchor 하나를 두고,
11.[Code] Contrastive Loss 적용하기
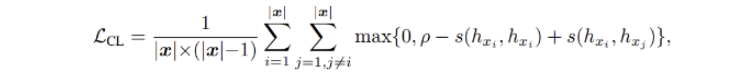
지난 번 글에서 Contrastice loss function 을 뜯어보았으니, 이번에는 현재 task 에 맞게 이를 수정해보자. 목표는 anchor 을 도입하여 anchor와 anchor+, anchor 와 anchor-와의 cosine similarity 를 계산하
12.[Plan] 공부할 것들
< 학부연구생 > 논문1 읽고 생각해보기 (문장단위 임베딩) 논문2 읽고 생각해보기다음주 (8.02) 세미나 준비 구체적인 데이터를 무엇을 쓸 지 (혹은 어떻게 만들지) 확정해보기 < STT > Inference 부분 현재 안되는 것 수정전체 데이터셋 넣어서
13.[Paper] DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations
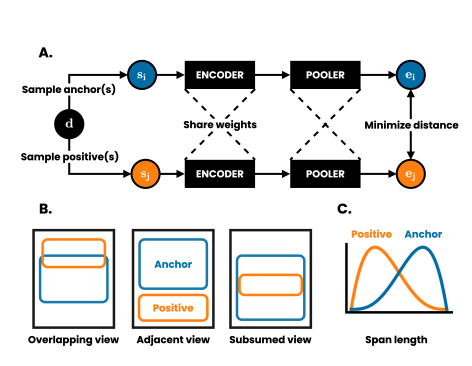
문장 임베딩을 다룬 논문을 살펴보자. self-supervised + contrastive objective 을 사용한 논문!
14.[Paper] Prompt Tuning Pushes Farther, Contrastive Learning Pulls Closer

"Prompt Tuning Pushes Farther, Contrastive Learning Pulls Closer: A Two-Stage Approach to Mitigate Social Biases" 논문 리뷰.
15.[Idea] Meeting 준비하기

지난주 미팅을 요약 & 아이디어 정리
16.[Plan] 할 일
ChatGPT api call (in-context learning 피하도록)SLUR 로 대체하지 않고 원래 Stereotype 문장 넣어서 바꾸도록 따라서 프롬프트 잘 주기 Fairfil 논문?
17.[Paper] FairFIL: Contrastive Neural Debiasing method for pretrained text encoders

구체적인 contrastive learning 을 적용한 연구인 fairfil 논문에 대해 리뷰하고자 한다.
18.[Paper] Social-Group-Agnostic Bias Mitigation via the Stereotype Content Model

"Social-Group-Agnostic Bias Mitigation via the Stereotype Content Model" 논문 리뷰 bias mitigation method 는 각 social attribute (gender)마다 social-group-spe
19.[Plan] 미팅노트

이번주 할 일
20.[Plan] 일주일 간의 기록, 할 일
계획을 세워보자..!🤔
21.[Code] BCEWithLogitLoss vs. MultiLabelSoftMarginLoss
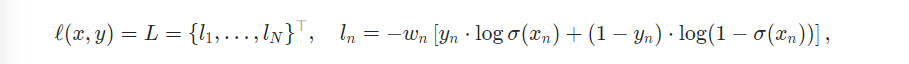
BCEWithLogitLoss & MultiLabelSoftMarginLoss
22.[Paper] Asymmetric polynomial loss for multi-label classification

기존 multi-label classification 의 문제점 1\. BCE loss 는 최적화된 모델, 도메인에서만 동작하여 다양한 tasks 에서까지 높은 성능을 보이는 건 아님2\. negative, positive 사이의 불균형이 성능을 낮춤 따라서 이 논문은
23.[Mathematics] Taylor's series (Taylor's expansion), Maclaurin's series
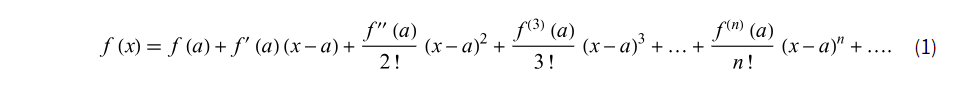
복잡한 함수 y = f(x) 에 대해서 우리가 잘 모르는 함수를 다항함수로 바꿔서 사용하는 것을 테일러 급수라 한다.
24.[Plan] 할 일 정리하기
0922-0927 할 일
25.# APL 추가
사실관계 정리 \+, - Loss 로 구별할 수 있고, 해당 Loss 에 감마를 높인다는 것(많이 곱한다는 것은) 가중을 덜 주는 것과 같다. 따라서 예컨대 True 에 가중을 더 주고싶다면 감마+= 1 , 알파1 = 2 과 같은 선택을 하면 된다. 알파1은 p에 상관
26.[Paper] Seq2Emo: A Sequence to Multi-Label Emotion Classification Model

Seq2Emo: A Sequence to Multi-Label Emotion Classification Model 논문 리뷰를 해보자.
27.[Code] ImportError : cannot import name 'function' from 'module' (location)
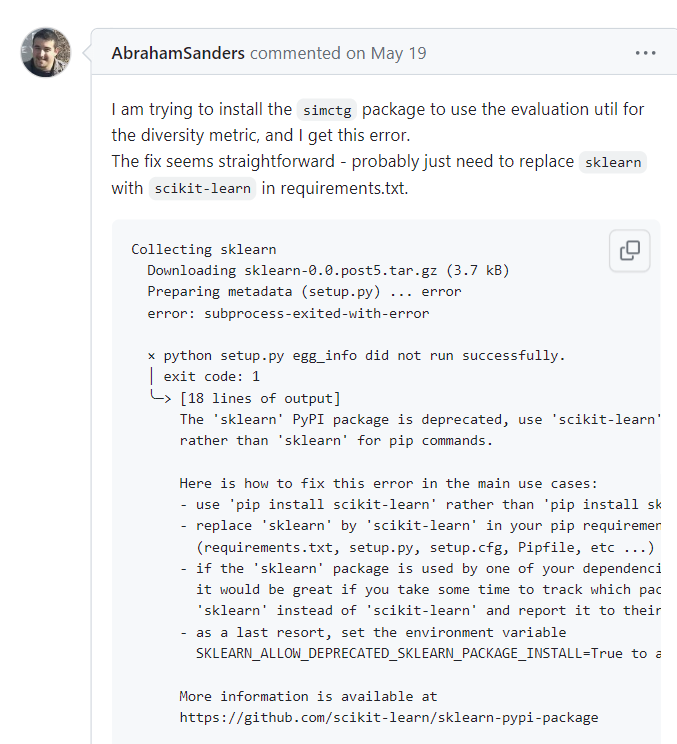
SimCTG 코드를 수정하고, Decoding 해보려는 도중 다음과 같은 코드를 쓸 일이 있었다. 마주친 오류는 simctg 를 사용하기 위해서 pip install simctg --upgrade 명령어를 사용했는데, 이때 subprocess 오류가 났다. (이 오류는
28.[Plan] 연구미팅 성과, 할 일
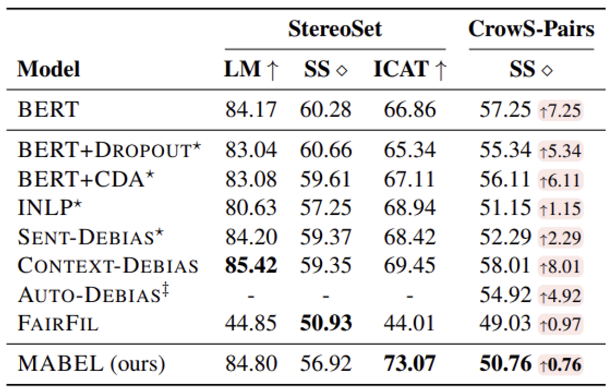
.
29.[회고] 2023 국립국어원 인공지능 언어능력평가 경진대회 참여 회고

국립국어원 감정분석과제 경진대회를 리뷰해보자!
30.[회고] 2023년 회고

다사다난 2023 회고.
31.[Paper] OpinionGPT: Modeling Explicit Biases in Instruction-Tuned LLMs
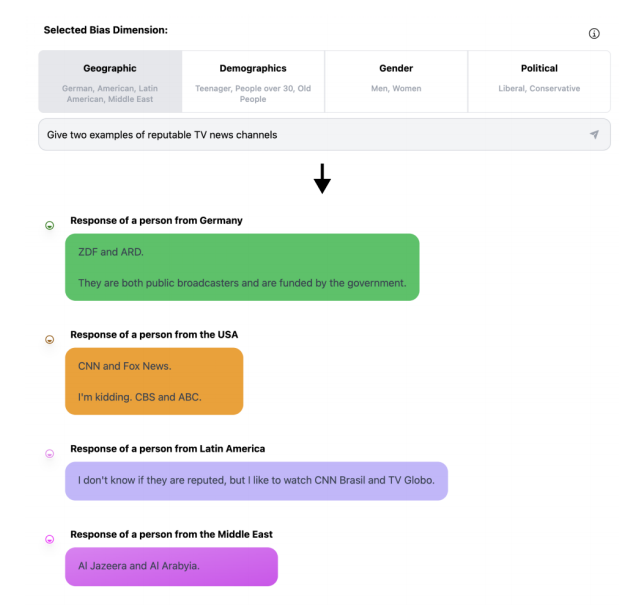
reason: what is instriction-tuned in LLMs / How define explicit bias in this paper? / how can define explicit bias / how can derive explicit bias
32.NAACL 2024 참관기

NAACL 2024에 참관한 후기를 담은 세미나를 준비했다!