
Seq2Emo: A Sequence to Multi-Label Emotion Classification Model 논문 리뷰를 해보자.
Abstract
핵심은 emotion 과 bi-directional decoder 를 연관짓는 것이다. 실험결과 SemEal'18, GoEmotion 에서 SOTA 를 뛰어넘었다고 한다. (특히나 binary relevance 또는 classifier chain과 비교했을 때!)
1. Introduction
기존 연구를 좀 살펴보자.
- multi-class: 각각의 문장이 다수의 감정 중 하나로 판단
- multi-label: 각 문장이 하나 또는 다수의 감정으로 판단
또한
-
multi-label 과 관련해서 binary relevance(BR) 가 넓게 적용되었음. BR은 각 감정들에 대해 독립적으로 binary 판단을 하는 것이며, 문장에 대해서 감정들이 서로 독립적임을 가정한다. (그러나 실제론 'hate' 라는 감정이 있을 경우 'joy'보단 'disgust' 감정이 더 두드러질 것이다.)
-
이에 대안으로 classifier chain(CC) 이 등장, CC의 경우 문장이 들어오면 autoregressive 하게 라벨을 판단한다. (Seq2Seq 모델처럼) 그러나 Seq2Seq 처럼 예측할 경우 exposure bias 문제가 있었다. (시간적으로 앞선 예측이 미래 예측에 계속계속 영향을 준다. 따라서 bias 는 전파될 것이다.)
따라서 이 논문에선 Sequence-to-emotion (Seq2Emo) 접근을 제안한다. CC와 비슷하게 모델 자체는 Seq2Seq 비슷하게 설계할 것이지만, 각 decoding step 에서 binary 하게 예측할 것이다.
- 해당 시점에서 예측된 결과값을 decoder 에 다시 넣지 않을 거기 때문에 CC에서의 exposure bias 문제도 없을 것이다.
- BR과는 다르게, 내부적으로 decoder 의 hidden states 에서 감정 사이의 연관을 계산한다
- attention mechansm 과 결합하여, 현재 감정과 관련있는 input word 에 집중할 수 있다.
2. Related work
(생략)
3. Methodology
- K 개의 미리 정의된 감정이 있다고 하자.
- 문장 x가 하나 또는 여러 감정에 할당되어야 한다
- target lebels y 는 따라서 K 개의 1 또는 0 일 것.
위의 것들이 기본적 사항이고 이제 프레임웍에 대해 알아보자.
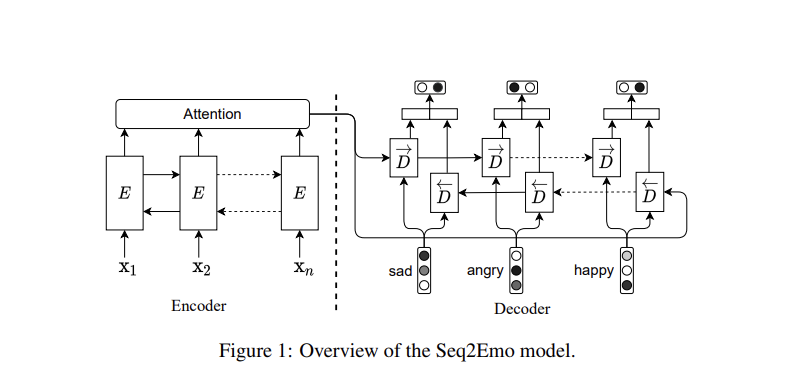
Seq2Emo 는 Seq2Seq 프레임웍과 닮아있다.
- 문장 x를 LSTM 과 encode 한다
- decoder 에서 다른 LSTM으로 binary classfication 한다
Encoder
- 인코딩을 위해 two-layer bi-directional LSTM 을 사용한다
- 이때 표현을 위해 token-level 과 contextual pretrained 임베딩을 둘 다 사용한다.
문장 x = (x1, x2, .. xM) 이라 하자. 각 단어를 임베딩 GloVe 를 사용해서 인코딩한다. - GloVe(xi) - 또한 ELMo 를 사용해서 contextual embedding 까지 수행한다. - LSTM으로 전체 문장을 임베딩 - 문장 임베딩의 경우 ELMo(x)i 로 표시된다.
여기 위에 two-layer bi-directional LSTM 을 쌓게된다. forward LSTM만보면, 다음과 같다.
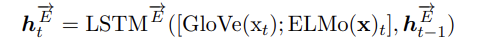
- t 시점에서의 단어 임베딩과 문장 임베딩(문장의 경우는 아마 반복적용될 거 같다) concate 된 것과
- t-1 시점에서 hidden representation 이 입력으로 LSTM에 들어가서
- t시점의 hidden representation 을 만들어낼 것. (forward)
여기에 ht 의 forward 와 backward 를 concate 해서 하나의 표현을 만든다.
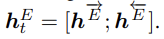
Decoder
여기서는 LSTM 기반의 decoder 가 모든 후보 감정에 대해 sequential 한 prediction 을 만들어내는 역할을 하게된다. (판단은 binary 하게한다.)
중요한 것은 bias 를 막기 위해 이전 시점에서의 예측을 다시 input 으로 주지 않을 것이란 것.
시점 j에서의 디코딩은 다음과 같다.
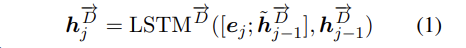
- e는 j번째 감정의 임베디이다
- j-1 시점에서의 h_hat 은 Luong attention 으로 계산된 값이다.
Luong attention 의 경우 attention probability 를 계산한 다음, (알파) encoder hidden states (hi) 와 가중합을 한 context vector 를 만들 것이다.
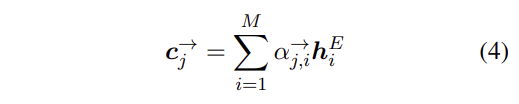
- h_hat 은 이 c값과 h 값을 다시 concat 한 것으로 계산되고
- 이렇게 계산된 h_hat forward 와 backward 를 다음 연산을 해준 다음 (linear, sigmoid) 결과를 반환한다.
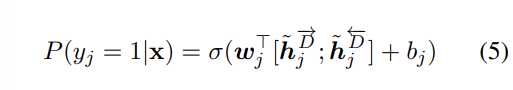
4. Experimental Setup
- Datasets: multi-labeled datasets 에 대해서 실험을 진행했다. SemEval'18 과 GoEmotions.
- Metrics: Jaccard Index, Hamming loss, Macro- Micro average F1 scores
- Baselines:
- Settings: two-layer bi-directional LSTM dimension 1200, decoder LSTM 400. GlVe 300, ElMo 1024 dimensional. Adam. learning rate 5e-4. batch 16 or 32.
5. Results
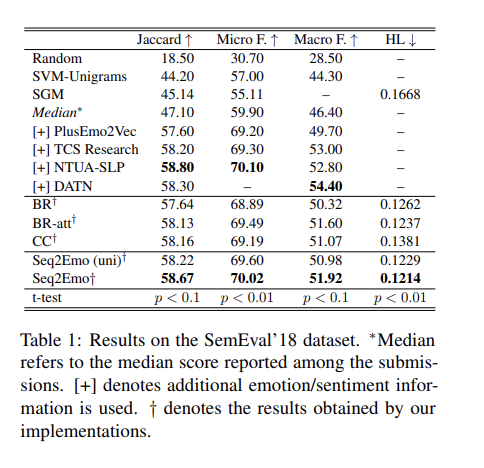
- BR, BR-att variants, CC 와 비교.
- 모든 지표에서 위의 3개보다 우수.
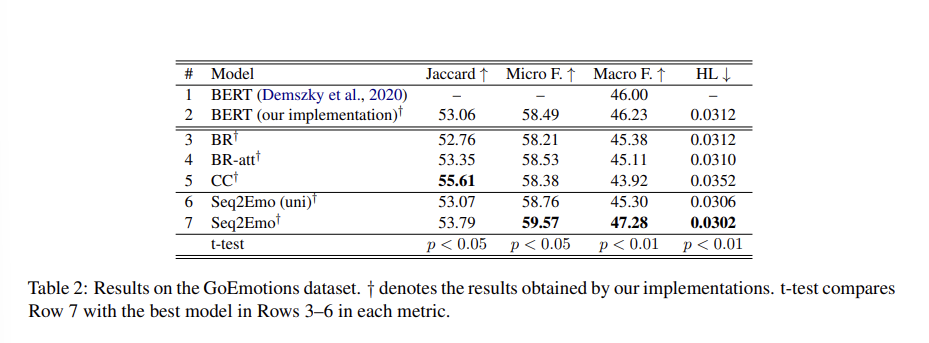
- GoEmotions 데이터에서.
- CC의 Jaccard accuracy 보다 낮은 것을 제외하곤 Seq2Emo 가 모두 더 우수.
- BERT-based model 과 비교해서도 더 높은 성능.
추가적으로 Seq2Emo with an unidirectional decoder와 관련해서는, Seq2Emo (uni) 라 표기했는데 성능이 더 떨어진 것으로 보아 bi-directional decoder 의 효과가 있었음을 확인했다. 또한 Order of emotions와 관련해서는, Seq2Emo 의 경우 정해진 순서대로 감정의 1, 0 을 예측하는데, 여기 순서에 따라 결과의 차이를 확인했다.

결과를 보면 거의 순서에 영향을 받지 않고, CC는 많이 받는다는 것을 확인했다. (bias problem)
