구현 목표
// 01 웹 서버 요청
- requests 활용 get 요청
- 응답 내용 확인(출력 한 번)
// 02 HTML 파싱
- BS 활용, 추출.
- 반복문 or 함수 통해 구조화
// 03 데이터 수집
- 네이버 영화 리뷰 데이터 수집
- df 로 변환
- 오류 여부 (결측, 유일성 확인)
// 04 형태소 분석
- 형태소 분석기 활용 (KoNLPy)
- 분석 의견과 부연 설명
// 05 벡터화 표현
- TF-IDE 변환 (텍스트 데이터 > 벡터화)
- sklearn 의 TfidfVectorizer 활용
- 말뭉치 구성 단어사전 확인
// 06 토픽 모델링
- LDA 기법 토픽 모델링
- pyLDAvis 라이브러러리 설치, 모델링 결과 해석
- 시각화
- 분석 결과 설명
- 분석 결과 의견
// 07 감성 분석
-로지스틱 회귀 모형 구성
-모델링 수행
-예측결과 설명, 의견 제시
01 웹 서버 요청
// 01 웹 서버 요청
- requests 활용 get 요청
- 응답 내용 확인(출력 한 번)
내가 접속한 사이트의 코드에 대해 요청을 받아보자.
✅ request 활용한 get 요청
import requests
url = "https://movie.naver.com/movie/bi/mi/review.naver?code=92075"
resp = requests.get(url)request 를 이해하기 위해선 서버의 동작 원리를 알아야 한다.
우리가 어떤 사이트를 접속하기 위해서는 서버와의 소통이 필요하다. 사이트를 방문하려고 요청하는 쪽을 클라이언트(client), 해당 url 을 클릭하면 코드를 보내 렌더링할 수 있게 해주는 서버(server) 가 있다.
request는 렌더링 되기 전 우리가 서버가 보낸 코드를 받아올 수 있게 해주는 라이브러리이다. 우리가 직접 클라이언트가 되는 것!
✅ 응답 내용 확인
print(resp.text)
외에도 request 를 통해 정상적으로 html 코드를 받아올 수 있었다.
resp.text[150:300]
02 HTML 파싱
// 02 HTML 파싱
- BS 활용, 추출.
- 반복문 or 함수 통해 구조화
✅ BeautifulSoup 활용, html 코드 파싱
받아온 코드는 우리가 직접 해석하기에 어렵게 되어있다. BS 라이브러리는 우리가 크롤링을 하면서 받은 html 코드를 쪼개 주는 역할로 한다. (태그 단위로). 쪼개진 코드는 우리가 find 나 find_all 메서드를 통해 추출하는 것을 가능하게 한다.
나는 BS가 이미 설치되어 있었으므로 임포트만 해줬다.
from bs4 import BeautifulSoup
soup = BeautifulSoup(resp.text, 'html.parser')
print(type(soup))
soup 의 타입은 다음과 같은 객체다. 성공적으로 파싱되었다!
03 데이터 수집
// 03 데이터 수집
- 네이버 영화 리뷰 데이터 수집
- df 로 변환
- 오류 여부 (결측, 유일성 확인)
✅ 네이버 영화 리뷰 데이터 수집
다음은 실제로 받아온 url 요청을 가지고 우리가 태그 이름을 확인해보아야 할 것이다.
태그를 찾을 땐 기본적으로 find 나 find_all 메서드를 사용한다. 태그 이름으로 찾거나 필요하다면 속성을 추가한다. 태그를 제외한 텍스트를 출력하기 위해선 get_text 메서드를 사용한다.
title_tag = soup.find(name = 'title')
print(title_tag)
title_text = title_tag.get_text()
print(title_text)
count_tag = soup.find(name = 'span', attrs = {'class', 'cnt'})
print("span 태그: ", count_tag)
count_tag = count_tag.find(name = 'em')
print("em 태그: ", count_tag)
count_text = count_tag.get_text()
print("텍스트: ", count_text)
각 어떤 태그가 내가 원하는 위치에 있는지는 F12 를 통해 개발자도구를 켜서 확인할 수 있다. 화살표 모양을 누르면 내가 가져오고 싶은 부분의 태그를 보여준다.
이렇게 어바웃타임 : 네이버 영화 부분은 title 태그에 들어있었다. 또한 영화 리뷰의 개수는 em 태그에 들어있었다.
review_list_tag = soup.find(name = 'ul', attrs = {'class': 'rvw_list_area'})
review_list_tags = review_list_tag.find_all(name = 'li')
print('li 태그의 수:' , len(review_list_tags))
print("\n")
print(review_list_tags[0])각 페이지에서 각각의 리뷰를 가져오는 코드는 다음과 같이 작성했다. 예컨대 한 페이지에는 각각 10개의 리뷰가 렌더링 되는데, 이 전체 리뷰를 감싸는 것은 ul 태그의 rw_list_area 태그이다.
이를 review_list_tag 에 담아줬다. 그리고 해당 변수에 관해 각각의 li 태그들을 모두 찾았다. 10개의 태그들이 ul이라면 각 1개는 li 로 구성되었기 때문이다. 따라서 review_list_tags 에는 각각의 li 태그 (각 리뷰)들이 리스트형태로 분리되어 들어가게 된다. 첫 번째 리뷰를 출력해봤다!

여기서 마음에 들지 않는 것은, 아직도 코드가 난잡하게 태그들이 얽혀 있다는 것이다. 우리가 필요한 정보가 제목, 작성자, 내용이라 할 때, 각각의 태그들을 확인해서 get_text() 메서드를 통해 텍스트만 추출해보자. 첫번째 리뷰에 관해서만 수행한 코드이다.
review_title = review_list_tags[0].find_all('a')[0].get_text()
print("제목", review_title, "\n")
review_uid = review_list_tags[0].find_all('a')[1].get_text()
print("사용자", review_uid, "\n")
review_content = review_list_tags[0].find_all('a')[2].get_text()
print("내용", review_content, "\n")
아까 본 사진의 첫 a 태그에는 제목, 두 번째는 사용자 id , 세 번째는 본문이 들어가있으므로 다음과 같이 [0][1] [2] 로 각각 가져온다. 결과는 다음과 같다.

review_nid = review_list_tags[0].find('a').get('onclick')
review_nid그런데 각각의 리뷰는 어떻게 들어가서 확인할까?
다음 클릭이 가능한 태그를 보면 showReviewDatail 에 다음 페이지로 가는 코드의 번호가 들어가 있다는 것을 알 수 있다. 결과는 다음과 같이 또다시 난잡히 나와서 정규 표현식으로 이를 추출하여 url 에 넣어줘야 한다.
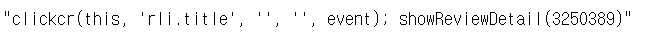
import re
review_nid = re.findall('\d{7}', review_nid)[0]
review_nid
review_url = f"https://movie.naver.com/movie/bi/mi/reviewread.naver?nid={review_nid}&code=92075&order=#tab"
review_url7자리 숫자를 뽑기 위함이므로 \d{7} 과 같이 구성했다. 리스트로 반환하므로 문자를 얻기 위해선 0으로 뽑아줘야 한다. 포매팅을 이용해 넣어준 결과는 다음과 같다.

review_nid 자리에 잘 들어가 구성되었다.
title_list = []
uid_list = []
url_list = []
for li_tag in review_list_tags:
review_title = li_tag.find_all('a')[0].get_text()
title_list.append(review_title)
review_uid = li_tag.find_all('a')[1].get_text()
uid_list.append(review_uid)
review_nid = re.findall('\d{7}', li_tag.find('a').get('onclick'))[0]
review_url = f"https://movie.naver.com/movie/bi/mi/reviewread.naver?nid={review_nid}&code=92075&order=#tab"
url_list.append(review_url)
print(len(title_list))
print(len(uid_list))
print(len(url_list))
for li in url_list:
print(li)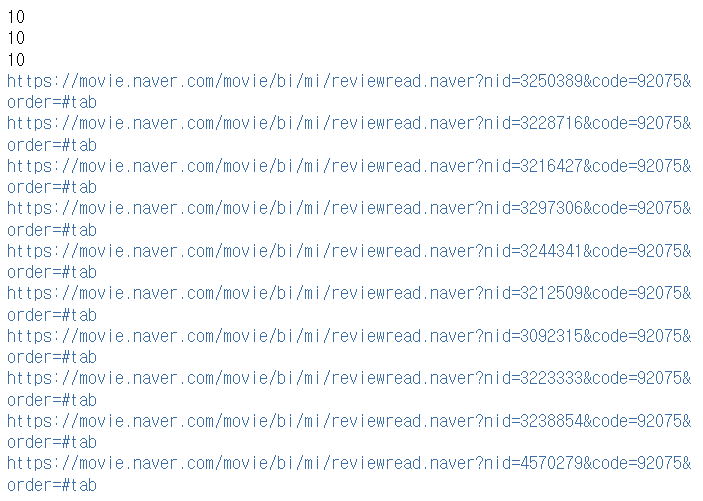
이제 아까 보았던 코드를 모든 태그들에서 돌려보자. li_tag에는 (밖에서 클릭 전) 각각 하나의 리뷰들이 들어가는데, 제목, 리뷰, (클릭 전 추출한) url 태그들의 목록을 각각 담았다. 본문은 클릭을 해서 추출하려 한다. url_list 에는 10개의 각기 다른 주소들이 잘 들어갔다.
resp_text = requests.get(url_list[0]).text
soup_text = BeautifulSoup(resp_text, 'html.parser')
review_text_tag = soup_text.find(name='div', attrs={'class':'user_tx_area'})
review_text = review_text_tag.get_text()
print(review_text)

url_list 는 각기 다른 리뷰의 (클릭되어 들어간) 주소다. 우리가 가지고 있는 것은 코드가 아닌 url 주소로 이를 처리하기 위해선 또다시 서버에 요청을 하고 파싱해줘야 한다. 텍스트의 위치를 보자.
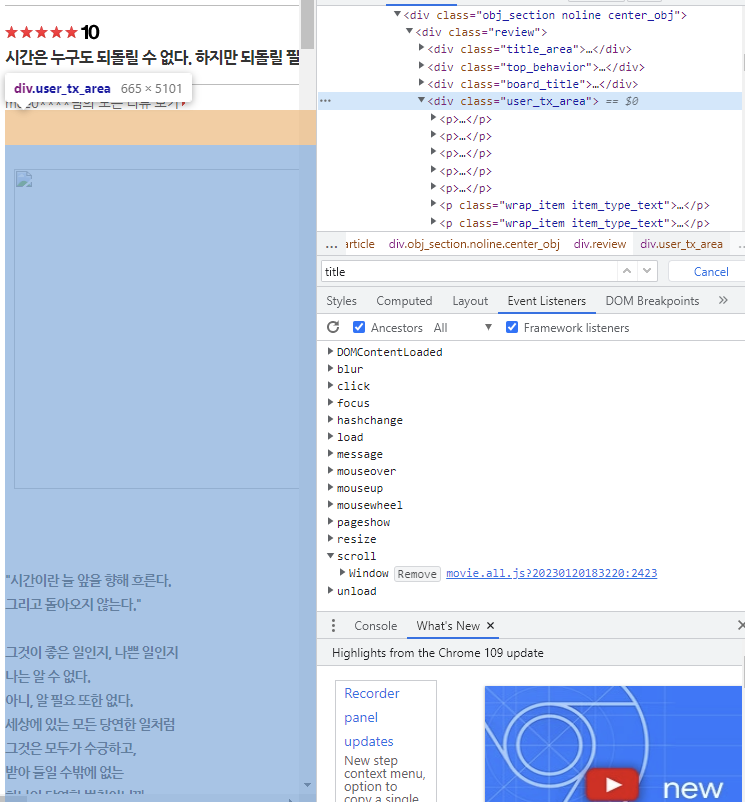
그렇다. 전체 유저의 텍스트는 div 태그의 user_tx_area 에 저장되어 있다. get_text()를 통해 가져오고 출력한 결과가 위의 사진인 것이다.
import time
text_list = []
for url in url_list:
resp_text = requests.get(url).text
soup_text = BeautifulSoup(resp_text, 'html.parser')
review_text_tag = soup_text.find(name='div', attrs={'class':'user_tx_area'})
review_text = review_text_tag.get_text()
text_list.append(review_text)
time.sleep(1)
print(len(text_list))
이번에는 텍스트가 직접 들어가는 코드를 최종 정리했다. 반복문으로 다룬 것 외에 특별한 것은 없다. time.sleep 은 코드가 잠시 쉬는 것이다. 동작이 끝나기도 전에 다음으로 넘어가 오류가 나는 것을 방지한다.
dict_data = {
'title' : title_list,
'user' : uid_list,
'review' : text_list
}
import pandas as pd
df = pd.DataFrame(dict_data)
df
df.to_csv("naver_review.csv")
해당 리스트에 있는 데이터들은 딕셔너리 형태로 저장한다음 pandas 데이터프레임으로 저장한다.
✅ 50 페이지 크롤링 최종 코드
import requests
'''url = "https://movie.naver.com/movie/bi/mi/review.naver?code=92075"
resp = requests.get(url)'''
from bs4 import BeautifulSoup
'''soup = BeautifulSoup(resp.text, 'html.parser')
print(type(soup))'''
title_list = []
uid_list = []
url_list = []
text_list = []
for page in range(1,51):
url = "https://movie.naver.com/movie/bi/mi/review.naver?code=92075&page={}".format(page)
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'html.parser')
#review_list_tag 는 클릭 전 페이지 (10개씩 있는 거), tags 는 그걸 리스트로 반환.
review_list_tag = soup.find(name = 'ul', attrs = {'class': 'rvw_list_area'})
review_list_tags = review_list_tag.find_all(name = 'li')
#review_nid 는
import re
# 10개 리스트에 1개씩 돌면서 제목, 아이디, 들어갈 url
for li_tag in review_list_tags:
review_title = li_tag.find_all('a')[0].get_text()
title_list.append(review_title)
review_uid = li_tag.find_all('a')[1].get_text()
uid_list.append(review_uid)
review_nid = re.findall('\d{7}', li_tag.find('a').get('onclick'))[0]
review_url = f"https://movie.naver.com/movie/bi/mi/reviewread.naver?nid={review_nid}&code=92075&order=#tab"
url_list.append(review_url)
print(len(url_list))
import time
for url in url_list:
resp_text = requests.get(url).text
soup_text = BeautifulSoup(resp_text, 'html.parser')
review_text_tag = soup_text.find(name='div', attrs={'class': 'user_tx_area'})
review_text = review_text_tag.get_text()
text_list.append(review_text)
time.sleep(1)
dict_data = {
'title': title_list,
'user': uid_list,
'review': text_list
}
import pandas as pd
df = pd.DataFrame(dict_data)

500개의 데이터가 잘 추출된 것을 확인할 수 있었다!
✅ 오류 여부 확인
🧩중복 여부 확인 (유일성)
현재 df 열은 각각 리뷰 제목, 작성자 아이디, 내용이 들어가 있다. 중복여부를 확인하기 위해 생각해보니
- 리뷰 제목은 충분히 일치할 수 있다. 예컨대 어바웃 타임에 대한 영화이므로 '어바웃 타임 후기' 라는 제목은 많을 수 있다.
- 작성자도 한 사람이 같은 영화를 보고 여러 개의 후기를 작성했을 수 있으므로 적합하지 않다.
- 그러나 내용이 완전히 같은 리뷰는 중복으로 인정이 가능할 거 같아 보인다. 악의적으로 타인의 리뷰를 복사 붙여넣지 않는 이상 내용이 중복될 가능성은 없어 보이기 때문이다. 혹은 그렇게 복사 붙여넣기 한 것은 어차피 중복으로 제거해보이는 것이 좋아 보인다.
따라서duplicated메서드를review열에 관하여 적용했다.
condition = df.duplicated(['review'])
df[condition]
condition 이라는 필터링 변수에 review 가 중복되면 True 를 반환하는 불리언 값을 넣고 확인해보니 빈 데이터프레임이 출력되었다. 따라서 중복되는 값은 없다고 판단할 수 있고, 유일성을 가진 것으로 인정된다.
🧩 결측 여부 확인 (완결성)
결측 여부는 빈 값이 있는지 확인하는 것이다. 가령 제목과 작성자는 있는데 내용이 없을 경우 의미 없는 결측된 데이터라고 할 수 있기 때문이다. 빈 셀을 확인하기 위해선 isnull 함수를 사용해서 수를 세어줬다.
df.isnull().value_counts()
숫자를 센 결과 빈 값이 있는 셀은 True 를 반환하는데 500개의 자료 모두 False 를 반환한 것을 확인할 수 있었다. 따라서 이 데이터프레임의 자료들은 유일성 과 더불어 결측값이 없는 완결성을 가지고 있다고 말할 수 있다.
04 형태소 분석
// 04 형태소 분석
- 형태소 분석기 활용 (KoNLPy)
- 분석 의견과 부연 설명
✅ 내가 만든 csv 파일 불러오기
jupyter notebook 에서 기존 df 파일을 csv 파일로 만들어준 후, 구글 드라이브에 업로드 해줬다.
df.to_csv('downloads/save.csv')구글 드라이브에 업로드 된 파일을 가져오기 위해선 다음과 같은 google 코랩에서 drive 를 임포트 해줘야 한다.
from google.colab import drive
drive.mount('/content/drive')
df = pd.read_csv('/content/drive/MyDrive/save.csv')
df.head()
다음과 같이 옮겨온 csv 파일도 df 란 이름에 넣어줬다.
✅ konlpy 설치와 분석
! pip install konlpy다음 명령을 통해 형태소 분석기인 konlpy 를 설치해줬다.
sample_text 변수에 기존 데이터 프레임 review 목록의 첫 번째 리뷰를 넣어줬다.
sample_text = df['review'].iloc[0]
print(type(sample_text))
print(sample_text)
사진이 잘리긴 했으나 잘 출력된 것을 확인할 수 있다!
konlpy 는 다양한 한국어 분석 라이브러리를 제공한다.
Hannanum: 한나눔. / Kkma: 꼬꼬마. / Komoran: 코모란. / Mecab: 메카브.
Open Korean Text: 오픈 소스 한국어 분석기. 과거 트위터 형태소 분석기.
현재는 Okt 라 불리는 오픈소스 한국어 분석기를 사용하여 분석할 것이다.
Okt 객체를 하나 만들어준다.
from konlpy.utils import pprint
from konlpy.tag import Okt
okt = Okt()
print(okt)
✅ pos 로 품사 태깅
이 okt 객체를 이용하면 단어 - pos(품사) 라 불리는 품사 태깅을 할 수 있다.
tokens = okt.pos(sample_text)
pprint(tokens)
pos 를 이용하여 모든 단어와 공백에 다음과 같은 품사가 붙었다! 공백의 제거를 하지 않았기 때문에 Foreign 이나 Punctuation 같은 태깅도 된 것을 확인할 수 있다.
✅ morphs 로 모든 형태소 반환, nouns 로 명사만 반환
tokens = okt.morphs(sample_text)
pprint(tokens)
morphs 를 사용하면 단어를 또다시 쪼개어 모든 형태소를 반환한다.
tokens = okt.nouns(sample_text)
pprint(tokens)
nouns 를 이용하면 명사만 추출하여 확인할 수 있다.
가져온 데이터에서 빈 셀이 있다면 dropna() 를 통해 제거해주고, 잘 들어갔는지 확인하기 위해 총 500개의 리뷰 데이터 중 첫 번째 리뷰를 넣어보는 코드를 작성했다.
review_data = df['review'].dropna().values
review_data = review_data[:500]
print(review_data.shape)
print(review_data[0])
✅ 모든 리뷰의 3글자 이상 명사 추출하기
500개의 리뷰와 첫 번째 리뷰가 잘 출력된 것을 확인할 수 있다.
이제 새로운 변수에 각 리뷰를 돌아가면서 명사만 추출, 그 중에서도 2글자가 넘는 명사만 추출하는 코드를 짰다.
cleaned_review_data = []
for review in tqdm(review_data):
tokens = okt.nouns(review)
cleaned_tokens = []
for word in tokens:
if len(word) > 2:
cleaned_tokens.append(word)
else:
pass
cleaned_review = " ".join(cleaned_tokens)
cleaned_review_data.append(cleaned_review)
print(len(cleaned_review_data))
print(cleaned_review_data[0])
이제 cleaned_review_data 에는 각 리뷰 중 3글자 이상의 명사만 잘 할당되게 된다. 예컨대 cleaned_review_data[0] 에는 첫 리뷰의 3글자 이상 명사가, cleaned_review_data[1] 에는 두 번째 리뷰의 3글자 이상 명사가 들어가 있는 것이다.
05 벡터화 표현
// 05 벡터화 표현
- TF-IDE 변환 (텍스트 데이터 > 벡터화)
- sklearn 의 TfidfVectorizer 활용
- 말뭉치 구성 단어사전 확인
✅ TfidVectorizer 활용 벡터화
현재 cleaned_review_data 에는 각 리뷰의 3글자 이상 명사가 들어가있다고 했다. 그 리스트를 상대로 tfid 변환을 수행해보자.
TF-IDF 변환
TF-IDF(Term Frequency-Inverse Document Frequency) 단어의 빈도와 역 문서 빈도(문서의 빈도에 함수 취함)를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법이다.
문서를 d, 단어를 t, 문서의 총 개수를 n이라고 표현할 때 TF, DF, IDF는 각각 다음과 같이 정의한다.
tf(d,t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수.
df(t) : 특정 단어 t가 등장한 문서의 수.
idf(d, t) : df(t)에 반비례하는 수.
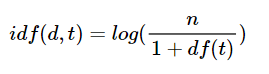
TF-IDF 변환은 최종적으로 각 단어를 벡터화하는 역할을 하는데, TFidVetorizer 를 임포트 해주고 fit_trasform 안에 아까 작업했던 텍스트 데이터를 넣어줘서 벡터화할 수 있다.
from sklearn.feature_extraction.text import TfidfVectorizer
tfid = TfidfVectorizer()
review_tfid = tfid.fit_transform(cleaned_review_data)
print(review_tfid.shape)
print(review_tfid[0])최종적으로는 review_tfid 에 500, 1732 의 데이터가 들어가 있음을 확인했다. 이때 1732는 각각 명사의 열로 각각의 값을 갖는다.
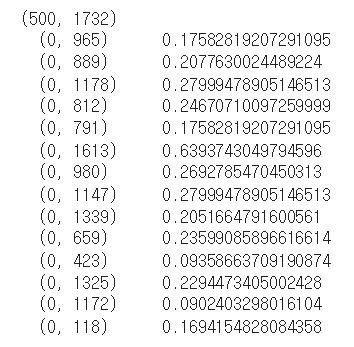
✅ 단어 사전 확인
단어 사전을 확인하기 위해선 tfid.vocabluary_ 를 수행해준다.
5개의 단어 - 값을 프린트해준다.
vocab = tfid.vocabulary_
print(len(vocab))
print({ k:v for i, (k,v) in enumerate(vocab.items()) if i < 5})
다음은 index_to_word 변수에 키와 값 값들을 바꿔주어 저장하고 5개를 프린트해보자.
index_to_word = {v:k for k, v in vocab.items() }
print({ k:v for i, (k,v) in enumerate(index_to_word.items()) if i < 5})
다음은 원래 단어를 복원하기 위해서 review_tfid 에서 첫 번째 리뷰의 단어를 가져와서 키 값에 넣어줌으로서 단어를 출력할 수 있다.
original_text = " ".join([index_to_word[word_idx] for word_idx in review_tfid[0].indices])
original_text
06 토픽 모델링
// 06 토픽 모델링
- LDA 기법 토픽 모델링
- pyLDAvis 라이브러러리 설치, 모델링 결과 해석
- 시각화
- 분석 결과 설명
- 분석 결과 의견
✅ LDA 기법 토픽 모델링
토픽 모델링이란 단어들의 분포를 확인하여 문서의 주제를 확인하는 것이다.
LDA 토픽 모델링을 통해 수행해보자. LatentDirichletAllocation 을 임포트하고 해석할 수 있다.
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_components = 2)
lda.fit(review_tfid)
ncomponents = 2 이란 두 개의 값 (긍정 / 부정) 으로 결과를 나눈다는 것이다.
이제 lda.components에는 다음과 같이 2가지로 나누어진 토픽 유형이 저장된다.
for idx, topic in enumerate(lda.components_):
print(f"토픽 유형 {idx+1}:", [(index_to_word[i], topic[i].round(3)) for i in topic.argsort()[:-11:-1]])
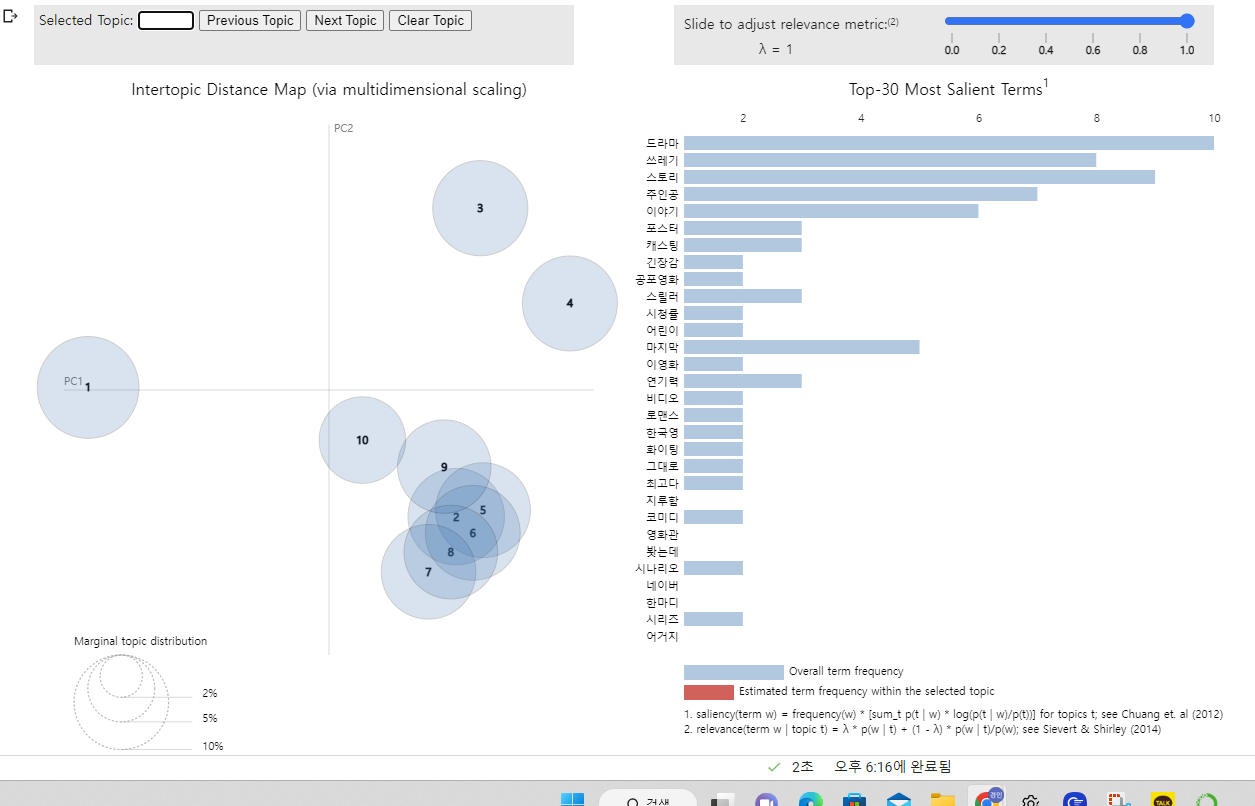
✅ pyLDAvis 설치, 시각화
시각화를 위해 pyLDAvis 를 설치해준다.
! pip install pyLDAvis
시각화를 위해선 임포트를 해준다. 다음은 시각화 결과이다.
이때 더 구체적인 시각화를 위해 n_components 에 10을 할당해주었다.
07 감성 분석
// 07 감성 분석
-로지스틱 회귀 모형 구성
-모델링 수행
-예측결과 설명, 의견 제시
지금까지는 본인이 분석한 데이터의 시각화를 위해 작업을 해보았다. 이제 감성 분석을 진행하기 위해 이전 코드들에 기존에 제시된 파일의 데이터를 넣어 학습을 시켜주겠다. 코드는 동일하고, 파일만 https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt 에서 가져온 파일을 이용했다.
해당 파일의 label 엔 0 과 1 로된 값들이 있었다. 이를 기반으로 TF-IDF 벡터를 입력하여 모델을 학습시키는 코드는 다음과 같다.
✅ 로지스틱 회귀 모형 구성
labels = data['label'].iloc[:1000].values
print(labels.shape)
print(labels[:5])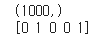
로지스틱 분류는 사이킷런 패키지를 활용하여 모델을 생성해줬다.
from sklearn.linear_model import LogisticRegression
# 로지스틱 분류 모델링 객체를 생성
lr = LogisticRegression()
# TF-IDF 벡터를 입력하여 모델 학습
lr.fit(review_tfid, labels)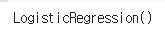
이제 아까 전 구성한 나의 df 자료에서 테스트 샘플을 가져오겠다.
test_sample = df['review'][1]
test_sample = re.sub(r"[^가-힣]", "", test_sample)
역시나 앞의 코드와 비슷한 방법으로 세 글자 이상의 명사만 추출, 벡터로 변환시켜주었다.
tokens = okt.nouns(test_sample)
cleaned_tokens = []
for word in tokens:
if len(word) > 2:
cleaned_tokens.append(word)
else:
pass
cleaned_review = " ".join(cleaned_tokens)
test_review_tfid = tfid.transform([cleaned_review])
print(test_review_tfid)
최종적으로 분류 예측을 수행하면 다음과 같은 결과를 출력할 수 있었다. 첫 번째 리뷰에 관해 모델이 예측한 결과는 이 리뷰가 부정적인 리뷰라는 것이었다.
test_pred = lr.predict(test_review_tfid)[0]
print("분석 결과 {}적인 리뷰로 예측됩니다. ".format("긍정" if test_pred > 0 else "부정"))
