
캐글(kaggle) 에 있는 트럼프 대통령 트윗 자료를 분석하는 프로젝트.
✅ 요구 사항 정리
//문제 확인
-자료 보고 선거 대책 관련 문제 정의.
-트럼프 트윗이 이용자들에게 어떠한 영향을 미칠지 가설 설정
//데이터수집
-결측값 확인
-결측값 처리
//데이터 전처리
- 분석에 필요한 데이터 컬럼 추출
- 분석할 내용 ( 트윗 게시글 수 증감 / 트윗 반응 분석)
- 문자열 함수(split / 이용하여 시간 정보 추출)
//데이터 시각화
- 분석 내용을 plot 을 이용해 시각화 (게시글 수 / 반응에 대해 시각화 자료 2개 이상)
- wordcloud 이용해서 트윗 텍스트 시각화
//가설 검증 및 해석
-수립한 가설, 분석 내용에 대한 해석 제시 (2회 이상)
//분석 의견
-최종 분석 의견
-가설에 따른 제안
✅ 문제 정의
//문제 확인
-자료 보고 선거 대책 관련 문제 정의.
-트럼프 트윗이 이용자들에게 어떠한 영향을 미칠지 가설 설정
🍀 게시 배경에 대한 가설
-하루 두 개 이상 트윗보다 하루 하나의 트윗이 더 많은 retweets 과 favorites 을 이끌어냈을 것이다.
-하루 오전 8∼10시, 점심 시간인 11∼13시, 밤 17∼18시가 많은 retweets 와 favorites 을 이끌어냈을 것이다.
https://techrecipe.co.kr/posts/26618
-그 중에서도 favorites은 12-6 사이에, retweets은 오후 6-12오후 사이에 많았을 것이다.
🍀 게시글 형식에 대한 가설
-mention과 hashtags 가 아예 없는 글보다 하나라도 있는 글이 더 많은 retweets + favorites 을 이끌어냈을 것이다
-많은 사람들에게 전달되도록 하는 hashtags 가 하나라도 있는 글이 mentions 보다 retweets + favorites 을 받았을 것이다.
-가장 많은 retweets + favorites 을 받아낸 것은 mention 2개, hashtags 2개 글 일 것이다.
🍀 게시글 내용에 대한 가설
-모든 영어가 대문자로 된 트윗이 그렇지 않은 트윗보다 더 많은 반응을 받았을 것이다.
-트럼프 본인을 뜻하는 I 가 들어간 트윗이 그렇지 않은 트윗보다 더 많은 반응을 받았을 것이다.
-영어가 아닌 다른 언어가 들어간 트윗은 영어로 된 트윗보다 더 적은 반응을 보였을 것이다.
-일반적인 문자보다 지정한 문자 ("" 따옴표, ! 느낌표, ? 물음표) 가 들어간 트윗이 더 많은 반응을 보였을 것이다.
✅ 데이터 수집
//데이터수집
-결측값 확인
-결측값 처리
주피터 노트북을 통해 캐글에 있는 csv 자료를 가지고 왔다.
import pandas as pd
df = pd.read_csv('downloads/trumptweets.csv')
df.head()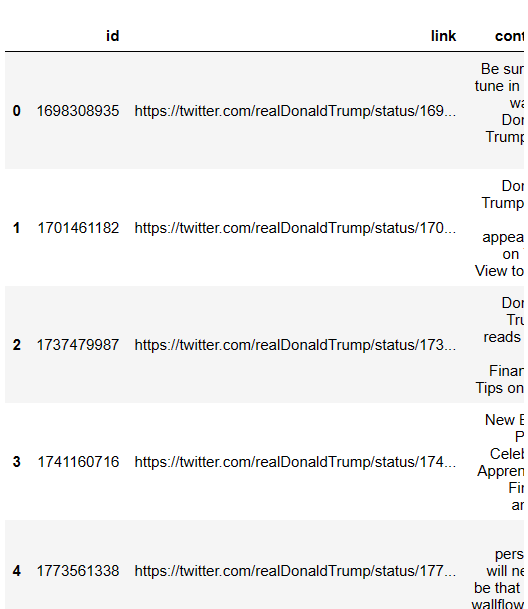
사진에 다 담진 못하지만 모든 열과 행 성공적으로 가지고 왔다!
mentions, hashtags, geo 을 제외한 셀에 결측값이 있을지 확인했다.
df.isnull().sum()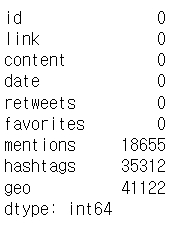
다행히 나머지 셀에 결측값은 없었다. 따라서 위 자료는 적어도 완결성을 가지는 자료다.
id 가 중복되는 값이 있을 지 확인했다.
dup = df.duplicated(['id'], keep = False)
혹시 있다면 중복 행을 지우는 새로운 데이터 프레임을 찾아 반환해봤다.
df1 = df.drop_duplicates(['id'], keep= 'first')
마찬가지로 41121 개의 트윗이 발견되어 중복 ID 도 없는 것으로 체크했다. 이 자료는 이제 완결성과 더불어 유일성도 가진다고 결론 내렸다.
✅ 데이터 전처리
//데이터 전처리
- 분석에 필요한 데이터 컬럼 추출
- 분석할 내용 ( 트윗 게시글 수 증감 / 트윗 반응 분석)
- 문자열 함수(split / 이용하여 시간 정보 추출)
다시 가설 검증을 위해 가설로 돌아가 어떤 정보들이 필요한지 구체적으로 정의하도록 하겠다.
🍀 게시 배경에 대한 가설
-하루 두 개 이상 트윗보다 하루 하나의 트윗이 더 많은 retweets 과 favorites 을 이끌어냈을 것이다.
가설 검증에 있어서 retweets 과 favorites은 '반응'이라고 묶기로 하자.
반응 / 연, 월, 일 정보 / 연월일 중복 정보 /
-하루 오전 8∼10시, 점심 시간인 11∼13시, 밤 17∼18시가 많은 retweets 와 favorites 을 이끌어냈을 것이다.
시간대 정보 / 반응 정보
https://techrecipe.co.kr/posts/26618
-그 중에서도 favorites은 12-6 사이에, retweets은 오후 6-12오후 사이에 많았을 것이다.
favorites / 오후 12-6 시간대 트윗 favor / 오후 6-12 시간대 트윗 favor
🍀 게시글 형식에 대한 가설
-mention과 hashtags 가 아예 없는 글보다 하나라도 있는 글이 더 많은 retweets + favorites 을 이끌어냈을 것이다
mention, hashtags 있음, 없음 / 반응
-많은 사람들에게 전달되도록 하는 hashtags 가 하나라도 있는 글이 mentions 보다 retweets + favorites 을 받았을 것이다.
hashtag 있음 반응 / mention 있음 반응 비교
-가장 많은 retweets + favorites 을 받아낸 것은 mention 2개, hashtags 2개 글 일 것이다.
mention 수에 따른 반응 / hashtag 수에 따른 반응
🍀 게시글 내용에 대한 가설
-모든 영어가 대문자로 된 트윗이 그렇지 않은 트윗보다 더 많은 반응을 받았을 것이다.
content 컬럼에서 소문자들어간 트윗 반응 / 나머지 트윗 반응
-트럼프 본인을 뜻하는 I 가 들어간 트윗이 그렇지 않은 트윗보다 더 많은 반응을 받았을 것이다.
대문자 I와 띄어쓰기 트윗 반응 / 나머지 트윗 반응
-영어가 아닌 다른 언어가 들어간 트윗은 영어로 된 트윗보다 더 적은 반응을 보였을 것이다.
영어 외 언어 포함 트윗 반응 / 나머지 트윗 반응
-일반적인 문자보다 지정한 문자 ("" 따옴표, ! 느낌표, ? 물음표) 가 들어간 트윗이 더 많은 반응을 보였을 것이다.
특정 문자 포함 트윗 반응 / 나머지 트윗 반응
✅ 데이터 시각화를 통한 가설 검증
//데이터 시각화
- 분석 내용을 plot 을 이용해 시각화 (게시글 수 / 반응에 대해 시각화 자료 2개 이상)
- wordcloud 이용해서 트윗 텍스트 시각화
//가설 검증 및 해석
-수립한 가설, 분석 내용에 대한 해석 제시 (2회 이상)
wordcloud 시각화
word = []
for sen in df['content']:
sen = sen.replace('.', ' ').replace(',',' ').replace(':', ' ').replace('!', " ").replace("?", " ")
w = sen.split(' ')
for i in w:
if i != '':
word.append(i)
from collections import Counter
word_count = Counter(word)
from wordcloud import WordCloud, STOPWORDS
wordcloud = WordCloud(width = 400, height = 400,
background_color ='black',
stopwords = set(STOPWORDS),
max_words=100,
max_font_size = 100,
).generate_from_frequencies(word_count)
plt.figure(figsize = (4, 4), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout()
plt.show()
🍀 게시 배경에 대한 가설
-하루 두 개 이상 트윗보다 하루 하나의 트윗이 더 많은 retweets 과 favorites 을 이끌어냈을 것이다.
반응에 대한 열은 response 로 추가하였다.
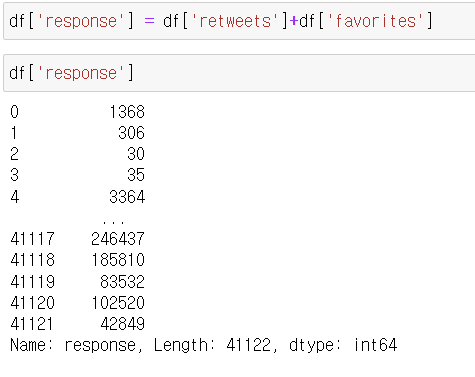
일 자료도 스플릿하여 day 에 넣어주었다.
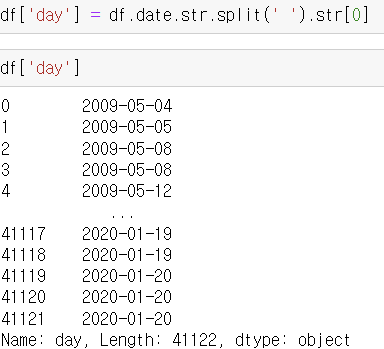
dup 이라는 변수에 일 자료에서 반복되는 날 (하루에 여러 트윗을 올린 날) 은 True 로 처리하도록 했다. 그리고 나서 데이터프레임 ['dup'] 이라는 열에 중복되는 날의 반응을 넣었다. 반대로 중복되지 않은 날은 ['Nodup'] 이라는 새로운 열을 지정해 반응을 각각 넣어 그래프를 찍어보았다.
df['day'] = df.date.str.split(' ').str[0]
df['response'] = df['retweets']+df['favorites']
df['dup'] = df.loc[dup, 'response']
df['Nodup'] = df.loc[dup == False, 'response']
df[['dup', 'Nodup']].plot()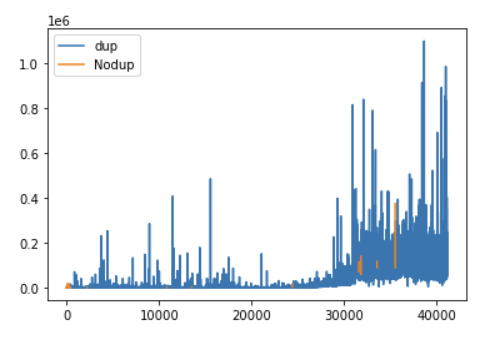
결과는 다음과 같았다.
결론적으로 모든 수치에서 dup 자료가 Nodup 자료보다 많은 반응을 이끌어내었다. 하루에 한 개의 트윗보다 많은 트윗을 올리는 것이 좋다는 것이 확인되었고, 기존 가설은 기각되었으나 아예 반대의 의미있는 인사이트(하루에 두개 이상의 트윗을 올리는 것이 많은 반응을 이끌어낼 수 있다는 것)를 얻을 수 있었다.
-하루 오전 8∼10시, 점심 시간인 11∼13시, 밤 17∼18시가 많은 retweets 와 favorites 을 이끌어냈을 것이다.
https://techrecipe.co.kr/posts/26618
시간에 대한 정보를 얻기 위해 이번에는 'date' 컬럼에서 시간 (분, 초 제외) 정보를 가져와서 'time' 컬럼을 새로 만들어 넣어줬다.
이후에, 기존 df 이외에 df1 을 만들어 시간 순 대로 오름차순 정렬한 새로운 프레임을 만들었고, 새로운 프레임의 time 컬럼을 x 좌표로, response 컬럼을 y 좌표로 설정하여 그래프를 찍어보았다.
df['time'] = df['date'].str[-8:-6]
df1 = df.sort_values(by = 'time', ascending = True)
df1.plot(x = 'time', y = 'response')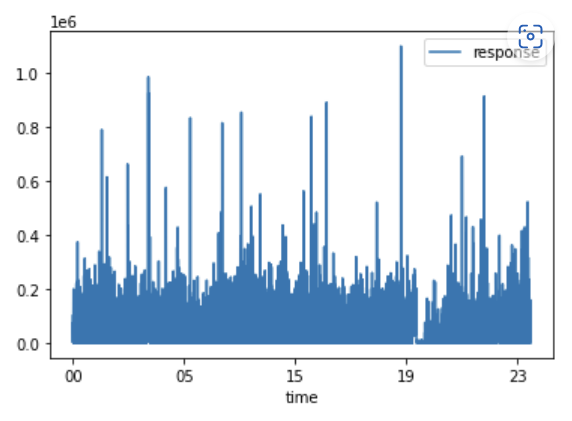
그러나 이렇게 살피면 너무 많은 자료들이 분산되어 있어 한 눈에 보기가 어려웠다. 시간대별로 그룹화를 위해 코드를 추가했다.
grouped = df['response'].groupby(df['time'])
grouped.mean().plot()결과는 다음과 같았다.
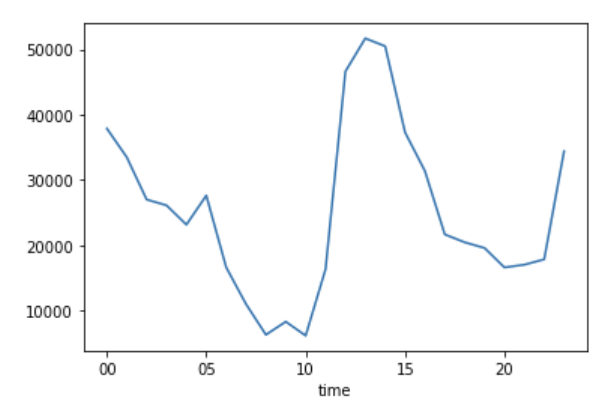
예상과는 다르게 트위터에서 가장 많은 반응을 이끌어낸 시간은 13, 14, 12 시간대였다. 그 다음은 00 시가 뒤를 이었다. 출근시간이나 퇴근 시간즈음의 트위터 반응량은 상대적으로 적었다.
-그 중에서도 favorites은 12-6(afternoon 사이에, retweets은 오후 6-12오후 사이(evening)에 많았을 것이다.
이번엔 반응을 한대 모이지 않고 좋아요와 리트윗으로 나눠서 시간대 별로 분석하는 것을 시도했다.
grouped2 = df['favorites'].groupby(df['time'])
grouped2.mean().plot()
grouped3 = df['retweets'].groupby(df['time'])
grouped3.mean().plot()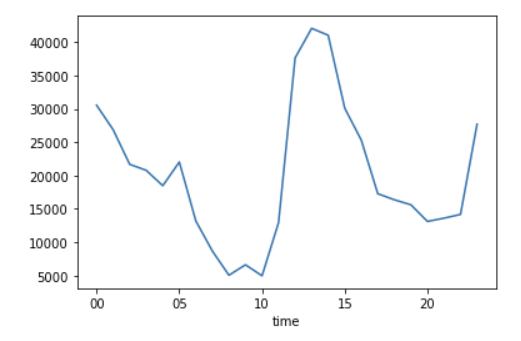
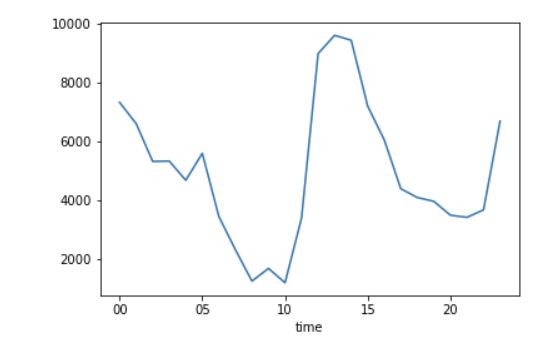
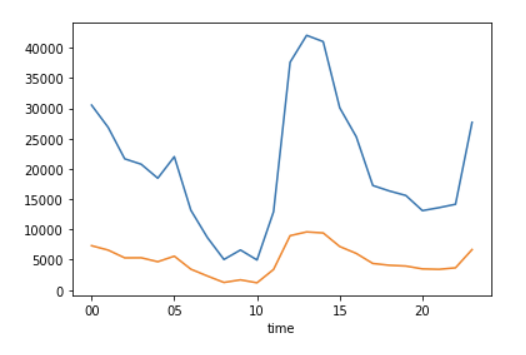
1번이 좋아요 그래프, 2번이 리트윗 그래프이다. 왼쪽 y 축의 눈금만 다르고 그래프의 모양은 놀랍도록 일치했다.
따라서 좋아요와 리트윗을 많이 받을 수 있는 시간대가 다를 것이라는 가설은 기각하고, 오히려 좋아요와 리트윗 간의 시간대별 차이는 거의 없다는 새로운 인사이트를 추출했다.
🍀 게시글 형식에 대한 가설
-mention과 hashtags 가 아예 없는 글보다 하나라도 있는 글이 더 많은 retweets + favorites 을 이끌어냈을 것이다
하나라도 있는은 isnull() 함수의 & 연산으로 구성했다. mention 과 hastag 가 모두 비었을 때와 그렇지 않을 때를 비교하여 그래프로 나타내면 다음과 같다.
condition = df['mentions'].isnull() & df['hashtags'].isnull()
df.loc[condition, 'response'].plot()
df.loc[condition == False, 'response'].plot()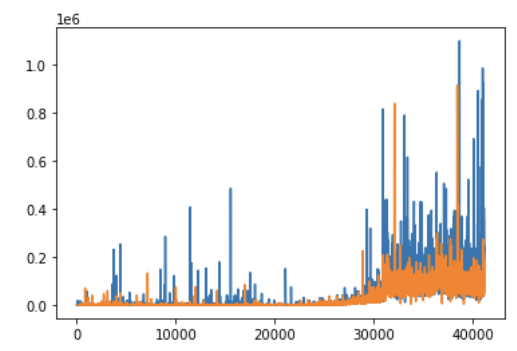
평균도 찍어보았다.
df.loc[condition, 'response'].mean()
df.loc[condition == False, 'response'].mean()53807.30816575259
10550.634388151506
5배 이상 차이가 났다! 가설과 완전히 반대의 결과가 나왔다.
결론적으로 hashtag나 mention 을 아예 사용하지 않은 글이 더 많은 반응을 이끌어낸 것을 확인할 수가 있었다.
-많은 사람들에게 전달되도록 하는 hashtags 가 하나라도 있는 글이 mentions 보다 retweets + favorites 을 받았을 것이다.
hash_condition = df['hashtags'].notnull()
men_condition = df['mentions'].notnull()
df.loc[men_condition, 'response'].describe()
df.loc[hash_condition, 'response'].describe()
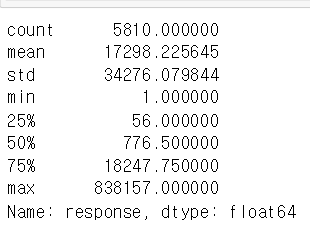
순서대로 mention 을 썼을 때와 hashtag 를 썼을 때에 관한 통계이다. 최대값을 기록한 트윗은 mention 에서 나왔지만 평균, 75% 값, 50%값, 25%값 모두 hash 가 높았다.
🍀 게시글 내용에 대한 가설
-모든 영어가 대문자로 된 트윗이 그렇지 않은 트윗보다 더 많은 반응을 받았을 것이다.
데이터프레임의 컬럼에 'condition' 을 추가해 트윗의 내용이 대문자로만 구성된 트윗을 뽑아내었다. 대문자 영어로만 된 트윗은 True를, 그렇지 않은 트윗은 False 를 가지게 했다.
df['condition'] = df['content'].str.isupper()
sns.catplot(data = df, x = 'condition', y = 'response', kind = 'box')그에따른 반응을 박스플롯으로 나타낸 결과는 다음과 같다.
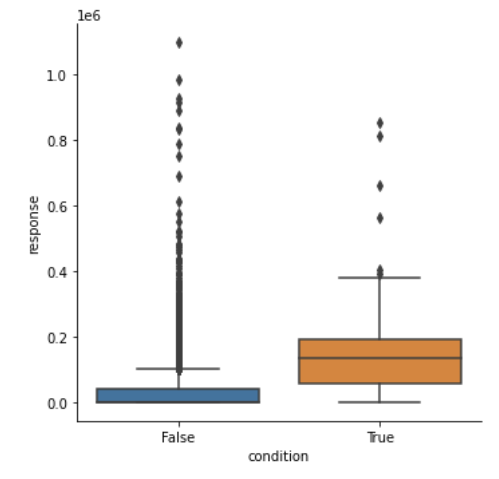
대문자로 되어있는 트윗은 그렇지 않은 트윗보다 25%, 50%, 75%, 최대값이 모두 높은 값을 보여주었으며 이는 유의미한 차이로 해석된다.
-트럼프 본인을 뜻하는 I 가 들어간 트윗이 그렇지 않은 트윗보다 더 많은 반응을 받았을 것이다.
일반적인 i 가 아닌 본인을 뜻하는 I 를 뽑아내야 했기에 대문자 + 다음 글자 공백을 원칙으로해서 박스 플롯을 그렸다. True 에 해당하는 값이 I 를 가지고 있는 문자열들이다.
df['I_contain'] = df['content'].str.contains('I ')
sns.catplot(data = df, x = 'I_contain', y = 'response', kind = 'box')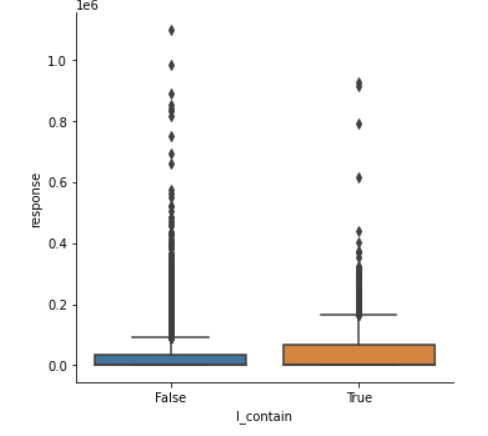
25% 을 제외한 나머지 값들에서 I 가 들어간 트윗이 더 많은 반응(최대값, 50%, 75% 지점)을 이끌어낸 것을 확인했다.
✅ 분석 의견 및 제안
//분석 의견
-최종 분석 의견
-가설에 따른 제안
각각의 가설에서 도출된 결론들을 바탕으로 트위터 관련 선거 대책을 제언할 내용은 다음과 같다.
게시 배경에 관해: 점심시간에 부지런히
트위터 사용량이 증가할수록 대중의 리트윗, 좋아요도 늘 것이라는 당초 예상과 달리, 트럼프 대통령의 트윗에 대한 반응은 점심 시간대인 12,13,14 시에 몰렸다. 또는 밤 시간대인 00시에 반응이 그 뒤를 이었다. 추가로, 하나의 트윗보다 하루에 한 개 이상의 트윗을 올렸을 때 그 각각의 트윗의 반응이 더 뜨거웠다는 점을 고려할 때, 12-14 사이에 하나 (또는 두 개 이상), 00시에 하나의 트윗을 올리는 것을 제안한다.
게시 형식에 관해: #, @는 줄일 것
해시태그나 멘션을 사용한 트윗에 관해선 그렇지 않은 트윗에 비해 5배나 적은 반응을 이끌어냈다. 대중의 관심을 위해선 그것을 배제한 그저 ‘순수한 트윗’ 이 필요하다고 판단되고, 정말 필요한 경우가 아니라면 오직 텍스트로만 트윗하는 것을 제안한다.
그러나 꼭 사용해야 하는 순간이라면 멘션 기능보다 해시태그를 쓸 것을 제안한다. 최대값을 제외한 모든 반응이 멘션보다 해시태그에서 더 높은 것을 확인할 수 있었다.
게시글 내용에 관해: 강조, 강조!
게시글 내용에 관해 세운 가설은 두 가지로 트럼프 본인을 뜻하는 ‘I’ 와 대문자로만 된 트윗에 따른 반응 여부였다.
결론적으로 ‘I’ 를 사용한 트윗은 그렇지 않은 트윗보다 평균적으로 더 나은 반응을 보였다. 또한 대문자로만 된 트윗은 그렇지 않은 트윗보다 최솟값이 최댓값 위에 있는 수치로 매우 큰 차이를 보였다. 따라서 게시글 내용에 관해 주목을 이끌기 위해선 강조의 문구가 중요해보이며, 이는 트럼프 본인의 생각을 피력하는 단어나 대문자 등 형식적인 노력으로도 충분히 발현될 수 있음을 확인했다.
