Seq2Seq Training
다음은 Seq2Seq 의 아키텍쳐이다. 입력이 들어오고, 메모리 셀에 저장되면서 각기 다른 값을 전달하며, 전 글자에 따라 다음 글자의 예측도 달라지는 모형!
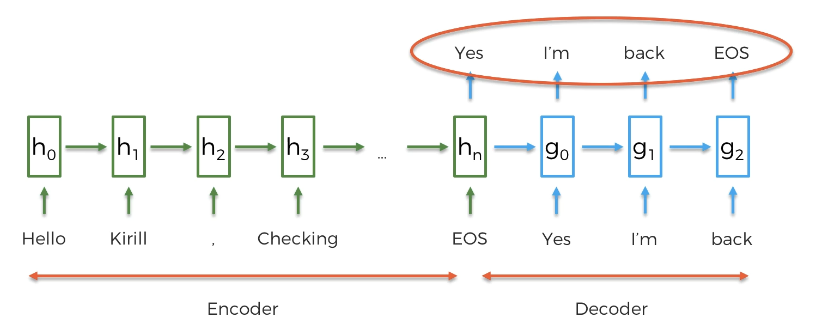
이는 훈련이 끝난 후 모델이 가능한 예측이며, 훈련 시에는 질문 메일과 답에 대한 문장도 역시나 주어진다.
-
입력값: Did you like that ~ = Encoder
-
출력값: Yes it was great = Decoder (디코더에서 출력값을 이미 안다.)
-
훈련하는 동안 W1, W2 를 업데이트 한다.
-
네트워크 학습이란?
-
문장을 인코더에 입력하고, 네트워크가 훈련을 통해 반복하는 과정
-
선택, 정확한 단어는 Yes 지만 2만개의 단어 중 선택하는 것이다
-
단어 Yes 에 가장 높은 확률이 존재하는지 확인
-
확률은 어떻게 계산? 인코더의 입력과, (전 단어가 있다면) 전 단어를 고려하는 것.
-
단어가 나오면 가중치 업데이트 (SGD, 역전파)
-
또 다시 인코더와 전 단어 고려, 확률 계산
-
가장 높은 확률의 단어를 선택한다. (it)
그렇다면 학습시킨 문장과 다른 길이의 문장이 입력으로 들어오거나 출력시키고 싶다면 어떻게 그것이 가능할까? ➡️ 가중치가 실제로 동일하게 작동하여 가능! (만약 자체 가중치나 파라미터가 존재하면 추가할 때마다 문제가 발생할 것이다.) ➡️ 가변적 입력과 출력이 가능하다.
Beam Search Decoding
결과를 도출하는데 쓰이는 디코딩 방법에 대해 알아보자.
Greedy Decoding vs. Beam Search Decoding
✅ Greedy Decoding
- 인풋이 주어지면 이후 가장 확률이 높은 단어를 선택한다
- 네트워크 생성, 다음 높은 확률 선택
- 끝 문장
✅ Beam Search Decoding
- 인풋 공급, 확률이 높은 상위 3개(또는 사용자 선택 개) 단어 파악.
- 3개의 다른 버전이라 봐도 좋다
- 각각에 가능한 옵션을 생성하는 것이 무엇인지 확인한다
- 결과값은 전체 빔에서 가장 높은 결합 확률을 확인하는 것이다.
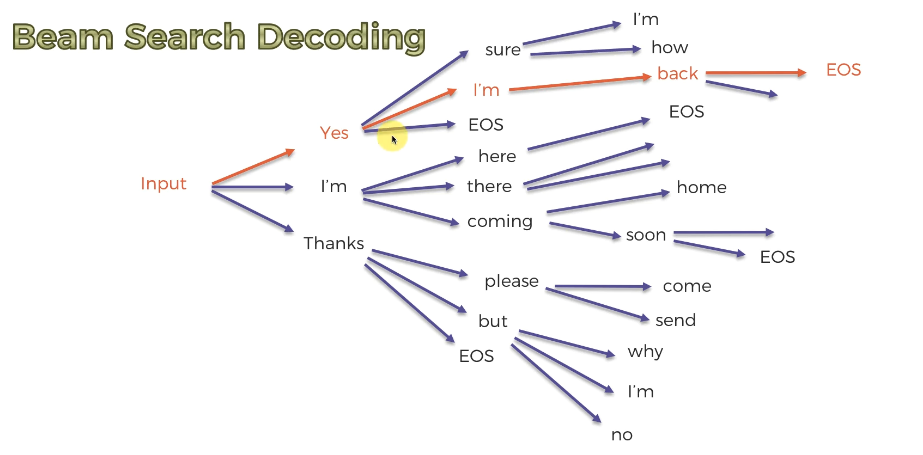
결과값의 문장이 다르다! 이렇게 결합 확률까지 계산한 것이 더 적합한 대답을 제시할 수 있다. (그러나 빔 탐색 디코딩은 가짓수가 너무 많다.)
가지수를 조금 잘라낼 수 있다! (자체적으로 특정 빔을 버린다.)
여러 선택지가 사용자에게도 주어진다면 빔 탐색 디코딩이 적용된 것이다!
Attention Mechanisms
- 단어를 예측할 때 전 단어와 인코더 레이어를 사용하므로
- 따라서 디코드는 이전에 사용했던 모든 정보에 접근이 가능하다고 말할 수 있다
- 훈련을 통해 디코더는 전에 등장한 요소 중 어떤 것에 주의를 기울여야 하는지 결정
- 인코더는 입력에 가중치 결정
- 가중치가 가장 많이 부여된 요소를 출력한다
- 소프트맥스 함수를 거친다
- 이 가중치를 통해 컨텍스트 벡터를 생성한다
- 가중치와 벡터를 곱한 것이 컨텍스트 벡터이다
- 디코더의 새로운 레이어에 추가 입력으로 컨텍스트를 넣는다.
- 다음 단어는 인코더로부터 온 인풋 + 전 단어 + 컨텍스트 벡터를 입력으로 받는다
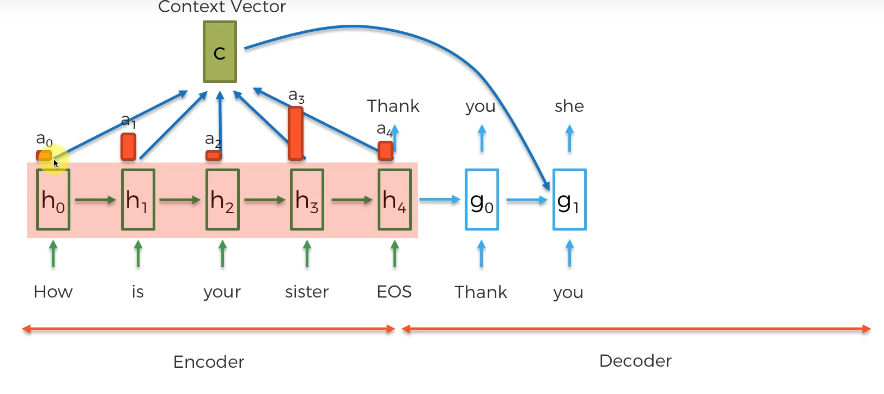
- 예컨대 다음 예측할 단어는 She 이고, he/she 중 she 를 선택하는 것은 의미적인 것이 아니라 컨텍스트 벡터에서 추출한 것이며, 그저 유사한 것을 학습한 것이다.

이는 전체 입력에 따른 가중치를 시각화한 것이다. (흰 색 점이 가중치)
- la 는 the 를 나타내면서도 Area 에 밝기가 밝다.
- 남성, 여성, 복수 관사가 존재하는 프랑스어
- 어텐션처리 필요
- zone 역시 area, was 에 주의
- was signed 가 3단어(a ete signe)로 해석된다.
- 중요도가 도움을 주므로 어텐션 메커니즘이 번역에 있어 성능이 좋다
만약 20단어 문장을 번역한다면 새로운 단어를 형성할 때 몇가지의 중요한 단어만 가져와 번역할 수 있다. (= 로컬 어텐션) 기본적으로 학습한 것은 글로벌 어텐션에 속한다!
Effective Approaches to Attention-based Neural Machine Translation
