단어가방의 예시와 같은 경우 Yes/No 대답만 제시하여 응답이 부족하다.
BOWs 모델의 한계
1. 고정된 사이즈의 인풋.
2. 어순 고려 X
3. 고정된 사이즈의 아웃풋 (Yes/No)
Seq2Seq 구조
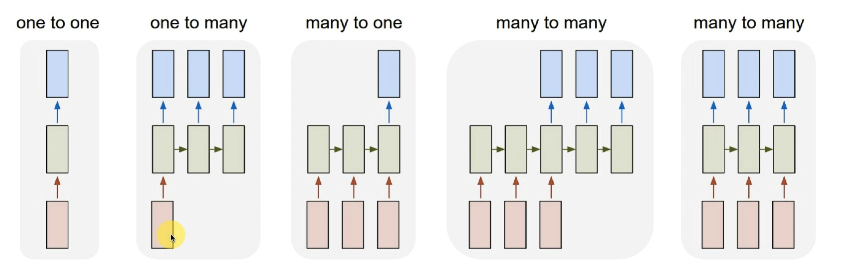
위의 사진은 RNNs 의 도식화이다.
- 한 박스는 하나가 아닌 뉴런의 전체 레이어를 의미한다. (차원을 축소해놓은 것)
구체적인 문장으로 돌아가서,
다음과 같은 문장에 쉼표, 마침표를 포함하여 모든 단어를 취합하자. 그리고 각각에 코드를 부여하자. 'hello' 는 5번, 'Kirill' 은 영어 단어가 아니라 0번, ',' 는 9번을 부여하자. SOS는 1이고, EOS 는 2이다.
- 번호 붙인 순서대로 가져오면 하나의 벡터이며, 벡터의 길이는 단어 수에 따라 변화한다.
- 다음과 같이 순환 신경망으로 표현할 수 있다.
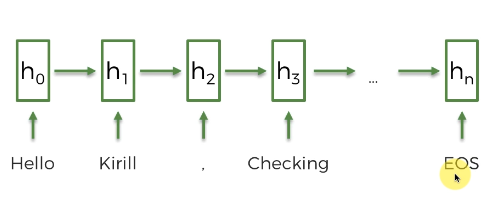
- hello 가 순환신경망의 첫 요소로 입력된다.
- 시간이 지남에 따라 정보를 추가하며 새로운 출력이 이어진다.
- 문장이 끝나면 Yes 를 출력할 수 있다.
- 여기서 답을 추가하며 I'm back EOS 를 추가할 수 있다.
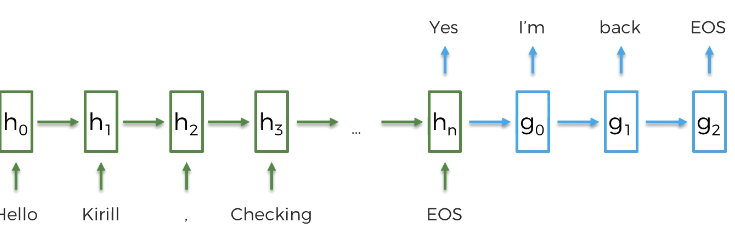
모든 입력단계가 끝나면 예측을 시작한다. (푸른색 단계)
가지고 있는 선택 사항에 대한 확률 점수를 산출한다.
2만 개의 단어 중 가장 높은 확률 선택 > 잔여정보 다음 레이어 > 선택 > 전달 > 전택 > 전달 > 선택.
이때 입력을 받으며 계속해서 정보를 업데이트하는 부분을 인코더, 이를 바탕으로 예측하며 전 단어에 기반에 다음 단어를 출력하는 것을 디코더라고 한다.
EOS 지점까지 인코딩, 그 이후에 디코딩을 진행한다.

Mathematics, Algorithm, and IDEA for AI research🦖