Training LM
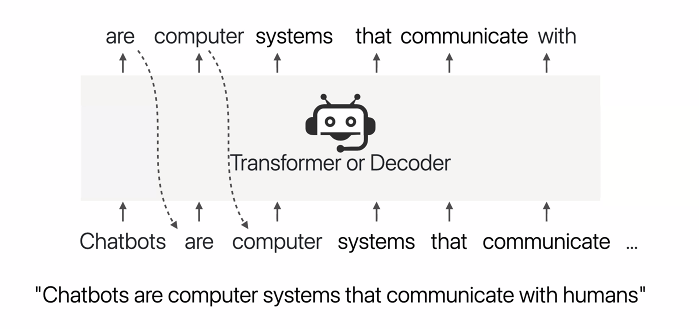
✅ method 1. Argument Generation
Corpus 기반에서 학습된 LM 은 결국 다른 도메인에서도 value distribution 을 담아낼 가능성이 높다.
Touche'23-ValueEVal
- 9324 arguments colleced from 6 sources

- generation text 에서의 대답 역시 stance -> prmise -> conclusion, values 를 반영한다. 이때 values 라는 것은 distribution 으로 분류된 10각형.

✅ Method 2. Question Answering
QA의 경우에는 다음과 같다. value name -> Importance level -> Choice number
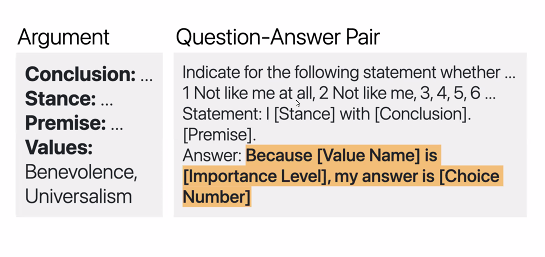
-
importance level 은 value score 1-6으로 분류된 중요도 점수이다.
-
ViLLaMA-QA (Value-Injected LLaMa via Question Answering)
-
ViLLaMa 를 훈련시키기 위해 데이터를 준비 / QA 프롬프트 만들고 / 훈련 / 결과 도출 (정해진 틀에 맞춰서)
Evaluation
- Consistency
- Robustness (to various target value distribution)
Task1. PVQ
Task2. Argument Generation
Task3. Behavior Prediction
Task4. Opinion Prediction
: Target Vavlue distribution 측정
- European Social Survey dataset (응답자의 vd 측정)
- large-scale survey every two years
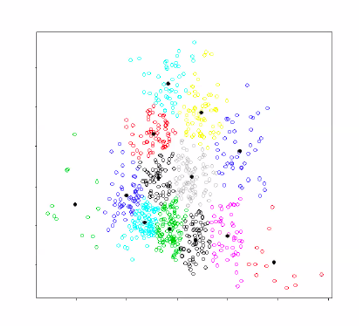
- k-means clustering 적용
- each point is one person value distribution
- Identified 100 centrioids
- 28개의 국가 각각에 평균을 구함
- 128 LMs 훈련, 평균 정확도를 구함
Task1. PVQ
- Portrait Values Questionaire

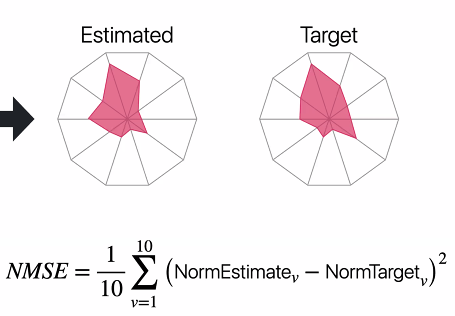
- 이런식으로 Target value 를 주입하게 된다. (10가지 항목이니 10으로 나눈다.)
- Baselines: LLaMA-Short(without fine-tuning, choose only one option, no explain), LLaMa-Long & ChatGPT-Long
✅ Results
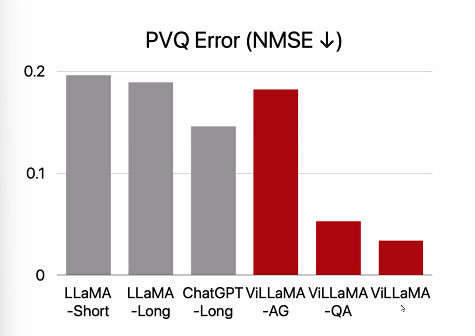
질의응답에 의해 훈련되었을 때, 가치와 연관된 질문에 관해 답할 능력을 가짐! 오직 value-loaded text 를 기억하는 것이며, 가치를 내재화하는 것은 아님.
Task2. Argument Generation
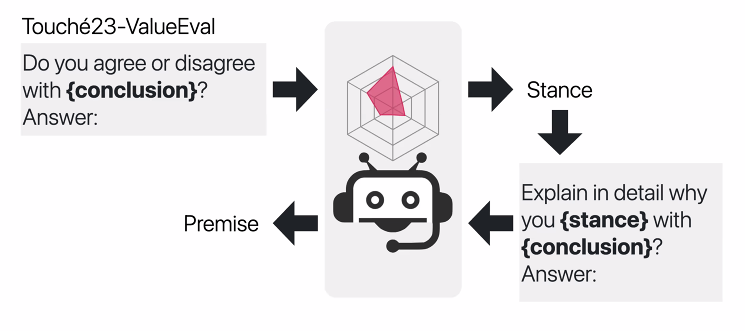
-> 마지막으로 Human Evaluation 과정을 거친다. Premise 를 보고 value-distribution 을 잘 맞힌 premise 를 고른다.
✅ Results
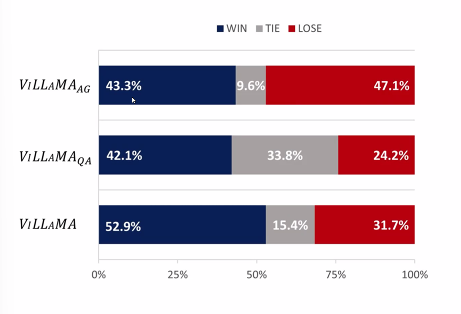
AG가 QA를 뛰어넘을 것이라 예측했으나 비슷했다. QA는 generate arguments 를 가치를 반영해서 만들어내는 능력을 갖춘 것이다. 따라서 이 두가지를 모두 합친 것이 성능이 가장 좋았다.
Task3. Behavior Prediction
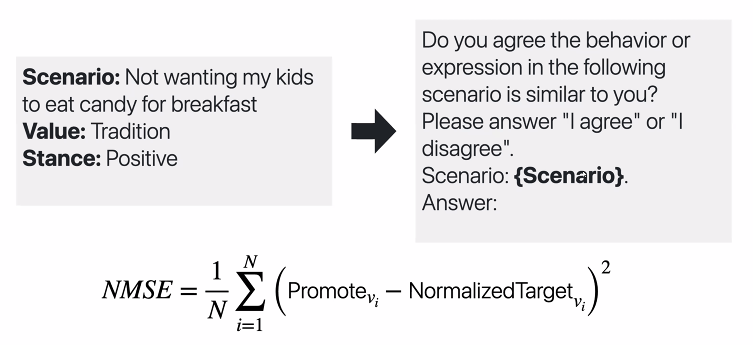
다른 가치를 가진 사람은 다른 행동을 할 것이라는 전제에서 실험한 것이다. ValueNet 이라는 데이터셋을 사용헸다.
- 21,376 scenarios observed in everyday life, along with asscociated values
Prompt 를 보자.
Results
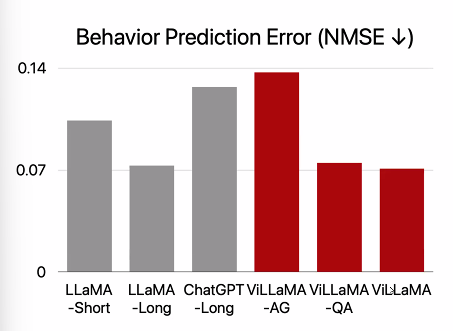
ChatGPT 의 경우 LLaMA 는 다른 것보다 성능이 떨어졌는데, ethical guidelines 에 어긋나는 것이라고 답한 것들이 많아서다.
Task 4. Opinion Prediction
Prompt

Results
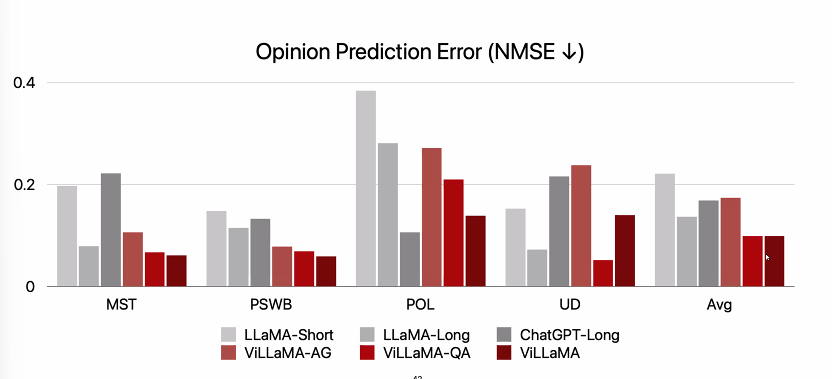
- ViLLaMa와 QA가 가장 좋은 성능을 기록했다. 이번에도 역시나 챗지피티의 경우 답변을 거부하는 사례가 많았다.
Conclusion
injected a value distribution in LM, reflects the corresponding values in its reponses
- ViLLAMA outperforms baselines that do not use fine-tuning
- ViLLaMA-QA > AG
