
교수님이 추천해주신 논문 중 첫번째인 SimCSE: Simple Contrastive Learning of Sentence Embeddings 를 살펴보려고 한다.
Abstract
논문은 역시나 SimCSE 에 대해 다루고 있는데, 논문의 첫 줄에서 소개한 SimCSE는 다음과 같다.
- A simple contrastive learning framework that greatly advances state-of-the-art sentence embeddings
결국은 문장 임베딩에서 더 적절한 임베딩 방법을 찾는 것이 SimCSE 라는 것.
지도학습과 비지도학습 모두에 적용했고, 두 학습 다 성능의 향상을 가져왔다고 한다.
- Unsupervised approach
- takes an input sentence and predict itself (in a contrastive objectives)
- with standard dropout used as noise >> data augumentation 의 역할, dropout 이 필수.
- Supervised approach
- annotated natural language inferences datasets (태깅을 달아주는 것, 어떻게?) >>
- using "entailment" pairs as positive, "contradiction" pairs as hard negatives.
성능적 부분은 다음과 같다.
- Bert 를 베이스모델로한 비지도와 지도학습 semantic textual similarity task 에서 기존보다 각각 4.2%, 2.2% 향상된 결과
- contrastive learning objectives regularize pre-trained embeddings' anistropic space to be more uniform. (비등방 > 일정한 임베딩으로 규제하는 효과)
1. Introduction
- BERT, RoBERTa 과 결합되었을 때 매우 효과적
- Unsupervised SimCSE
- predict input sentence itself + dropout used as noise
- pass the same sentence to the pre-trained encoder twice (여기에 standard dropout 도 두 번 적용. 🤔) 따라서 두 개의 다른 임베딩이 만들어짐 => positive pairs
- 같은 배치에서 다른 문장 => negative pairs
- negatives 중 positive 를 예측하도록 학습.
- dropout 은 hidden representation 에 있어 data augmentation 역할
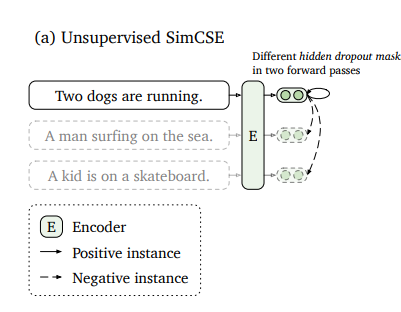
"Two dogs are running" 의 학습 과정에서, 이 문장을 두 번 넣고 / 다른 문장도 두 번 넣고 / Two dogs are running 임베딩 2개는 positive pairs 로. / "A man~", 'A kid~" 임베딩들은 negatives 로.
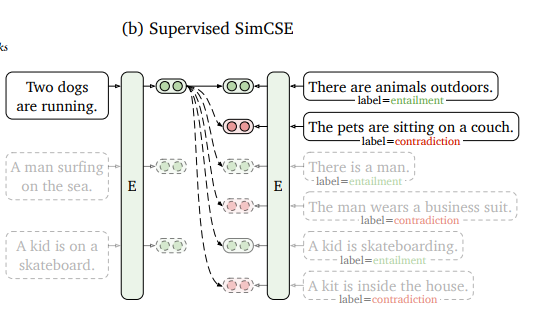
- Supervised SimCSE
- 역시나 하나의 문장에서 두 개의 임베딩 생성
- 차이점은 Unsupervised 의 경우 배치 안의 그 문장과 다른 문장을 고려한다면
- Supervised 의 경우 인코더 또한 2개이며, NLI datasets 에서 그 문장의 entailment, contradiction 을 이용한다는 것.
- "Two dogs are running" 이란 문장의 entailment ("There are animals outdoors")의 임베딩은 positive, contradiction ("The pets are sitting on a couch") 페어는 negative
- 이 외 다른 문장의 entailment 이든 contradiction 이든 negative 로.
기존 연구들에서 표현공간 상에서의 anistropy 문제 => CSE 의 경우
- "flattens" the singular value distribution (단일 값에 대해 평평하게 한다는 게 무슨말이지? 🤔)
- improving uniformity
2. Background: Contrastive Learning
목표: Learn effective representation by pulling semantically close neighbors together and pushing apart non-neighbors.
- Data: , i = 1부터 m까지
- Cross entrophy 사용
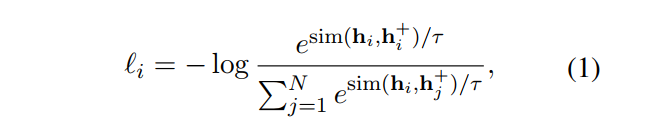
- : temperature hyperparameter
- : cosine similarity
방법은 사전훈련된 모델에 인풋 문장을 넣고 encode 하는 것. 이후 contrastive learning ojbective 를 통해 fine-tuning!
✅ Positive instances
그렇다면 하나의 문제는 를 어떻게 추출(또는 구성)할 것인가 하는 문제가 있다. 그 방법으로 여러 가지를 제시하는데
- 이미지의 경우 random transformation
- 언어의 경우 word deletion, reordering, substitution
- 또는 simply using standard dropout on intermediate representation (🤔 근데 이 중간 단계가 정확히 어디인지..? 문장을 가지고 2개의 벡터를 만들고(이때까진 같은 벡터) / 학습할 때 dropout 하면 와 같은 효과를 가질 수 있다는 건가?)
- 또는 dual-encoder framework 에서 question-passage pair 을 그대로 사용할 수 있다는 아이디어도 있다.
✅ Alignment and uniformity
두가지는 행렬 표현의 퀄리티를 평가해주는 중요한 요소로 사용되었다.
Alignment: calculated expected distance between embeddings of the paired instances. >> ${(x_i, x_i^+)} 사이의 기대 거리를 말한다.
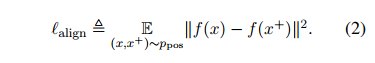
거리가 클수록 alignment 가 늘어나고, 거리가 가까울수록 alignment 가 줄어들 것이다. (거리가 가까울수록 좋다.)
Uniformity: expected how well the embeddings are uniformly distributed. >> x, y 사이 거리가 얼마나 일정하게 떨어져있는지를 말한다.
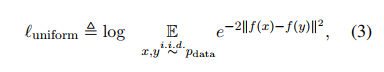
e함수를 사용했으므로 생각해보면 그 문장과 다른 문장 사이 거리가 멀수록 uniform 값은 작을 것이고, 거리가 가까울수록 uniform 값은 클 것이다. (거리가 멀수록 좋다.)
3. Unsupervised SimCSE
트랜스포머 문서 >> dropout mask 를 이해할 때 쓰자.
Unsupervised 에서 SimCSE 를 만드는 방법은 use of independently sampled dropout masks for and . (Transformer 내부에서 사용하는 것이며 추가 dropout을 말하는 것이 아님)
- : x가 input 으로 들어오면 random mask z를 적용.
- 따라서 아예 동일한 문장을 인코더에 두 번 넣고 나온 동일한 2개의 임베딩에 다른 dropmask z, z' 를 적용하는 것. (이부분이 가장 중요)
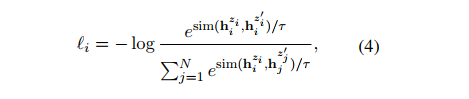
Dropout noise as data augmentation
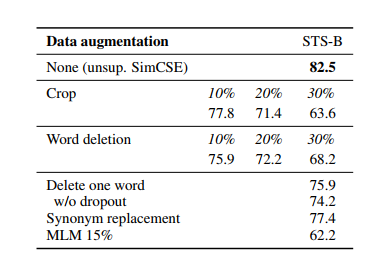
따라서 이러한 Dropout 을 적용하는 것을 결국 augmentation 을 적용한다고 여겼고, 관련해 다른 기술은 적용하지 않았다.
- 기존의 NLP augmentation 기술이었던 crop이라든지 word deletion, replacement은 SimCSE 에 다른 augmentation 추가하지 않은 것과 비교했을 때 성능이 다 떨어졌다.
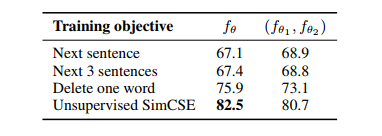
또한 objective 를 무엇으로 두느냐에 따라 다른 성능을 비교한 테이블도 있었다.
- 변수를 objective을 next sentence 로 두냐 / SimCSE를 쓰냐와, encoder 개수 1개이냐 / 2개이냐로 뒀는데 SimCSE + encoder 1개 조합이 좋았다.
Why does it work?
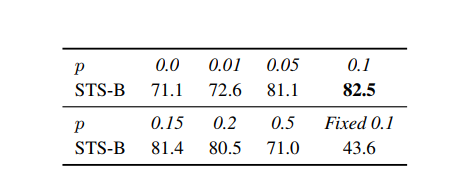
어느정도의 dropout noise 가 가장 좋냐를 따졌을 때, Transformers default dropout probability 인 p = 0.1 이 가장 좋았다.
표 하나를 더 보면
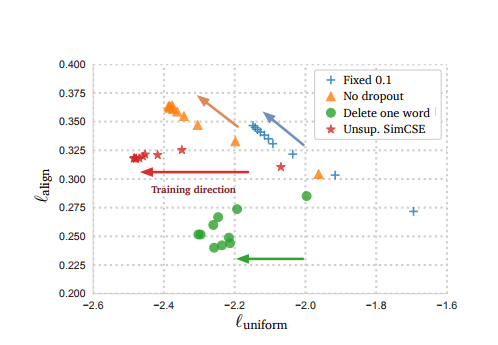
- No dropout vs. Fixed 0.1: 같은 방향으로 움직이나 No dropout 이 더 좋았다. 랜덤하지 않은 같은 임베딩이면 그냥 정보를 다 담고 있는 게 좋다는 결론.
- SimCSE vs. Delete one word: Delete one word 의 경우 align 에 관해선 굉장히 좋았으나 전체적으로 보았을 땐 SimCSE에게 조금 밀린다. 한 단어 삭제가 왜 align 에선 좋고 uniform 은 따라가지 못하는데에 대한 고민을 해보았다.
<Skip 가능>
"I walk the dog": 한 단어를 삭제하면 pair 가 서로 각각 다른 임베딩을 갖고 있겠지만 단어가 삭제된 부분에 대해선 한 임베딩은 그 단어를 나타내고 있고, 다른 하나의 임베딩은 아예 나타내지 않기 때문에 accuracy 가 높지 않을까? 가깝게 표현될 것이다.
"I walk the cat": 문제는 한 단어를 삭제해서 "I walk the dog", "I walk the cat" 에서 "I walk the", "I walk the" 라는 문장을 학습하게 된다면 의미가 완전히 다른 문장임에도 같은 임베딩을 도출할 것이다. extreme 한 예시를 들었지만 이 부분 때문에 다른 문장이 멀리 떨어지지 않은 곳에 위치했을 것.
4. Supervised SimCSE
페어를 어떻게 정할 것이냐하는 문제가 Supervised 에선 매우 중요한데, 과거에 NLI로 특정 문장이 주어지면 entailment, neutral, contradiction 으로 '예측'하는데 쓰인 데이터들을 '데이터셋'으로 활용했다는 점이 특이하다.
Choices of labeled data
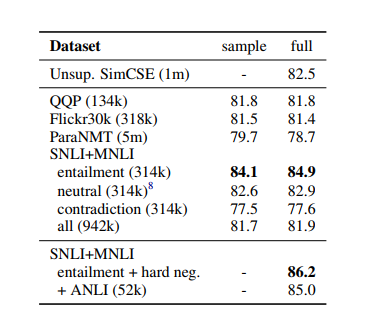
아래의 표에 등장한 데이터셋 모두 시도했고, SNLI + MNLI 인 NLI datasets 이 가장 좋았다고 한다.
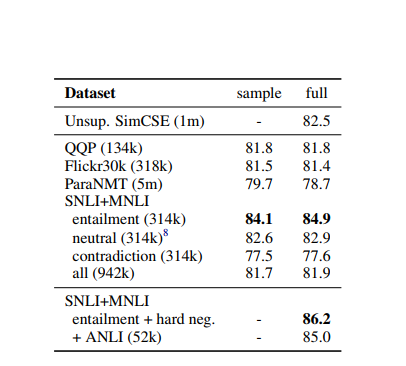
Contradiction as hard negatives
이제 논문이 사용한 최종 모델을 확인할 수 있다.
NLI datasets 에서 가장 큰 장점은 기존 페어를 로 확장시킬 수 있다는 것이고, 각각 x는 premise, x+는 entailment, x-는 contradiction 으로 간주하면 된다. 따라서 아래와 같은 loss 식을 정의할 수 있다.
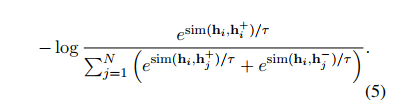
하나의 premise 에 해당 entailment는 x+로 간주하고, 나머지 모든 조합은 모두 negatives 로 간주하면 된다. 따라서 단순히 premise + entailment 만 사용했을 때보다 + contradiction(hard negatives) 를 추가했을 때 가장 성능이 좋았으며(84.9 => 86.2), 이를 final supervised SimCSE 로 사용했다 한다.
5. Connection to Anisotropy
anisotropy 와 관련된 설명은 다음 블로그를 참조하자. Anisotropy 간략히 설명
단어 벡터가 비슷한 방향으로 향하는 문제인 anisotopy 문제를 contrastive learning 으로 해결할 수 있다고 논문은 설명하고 있다.
직관적으로 생각해봐도 anisotropy 문제는 uniformity 와 연관되어 있다. 왜? 다른 문장의 다른 벡터는 멀리 떨어져있어야 하는데 그렇지 못한 것이 anisotropy 이기 때문이다. 즉, uniformity 가 좋을수록 anisotropy 문제는 없을 것이다. 따라서 Contrastive learning 을 성능을 향상시키는 것 자체가 anistropy 문제의 해결과 강하게 연결되어 있다.
SO, "contrastive learning objective can "flatten" the sigular value distribution of sentence embeddings and make the representations more isotropic!"
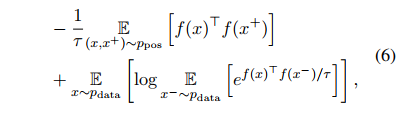
우리가 정의했던 alignment 와 uniformity 를 기대값으로 한 번에 표현하면 위와 같이 표현할 수 있다. 앞부분은 positive instance similar, 뒷부분은 pushes negative pairs apart 를 의미한다.
라 하면 다음과 같은 식으로 바꿀 수 있다.
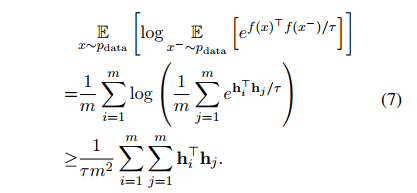
여기서 추가로, W를 1부터 m까지의 문장에 대한 임베딩이라 하면
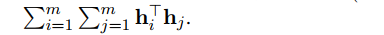
이 식을 로 간단히 표현할 수 있게 된다. 따라서 이를 Optimizing 한다는 것은 minimize an upper bound of the summation of all elements in 를 뜻한다.
다시, 만약 의 모든 요소가 positive라면, 는 의 largest eigenvalue 의 상한선일 것이다. 따라서 우리가 의 상한선을 줄이고 inherently "flatten" the singular spectrum of the embedding space 하는 게 가능해진다.
6. Experiment
6.1 Evaluation Setup
실험은 7 semantic textaul similarity tasks에 대해 진행되었다.
- pretrained checkpoints of BERT, RoBERTa (sentence embedding 을 얻음)
- train unsupervised SimCSE (sentence from Engilsh Wikipedia)
- train supervised SimCSE on the combination of MNLI and SNLI datasets.
6.2 Main Results
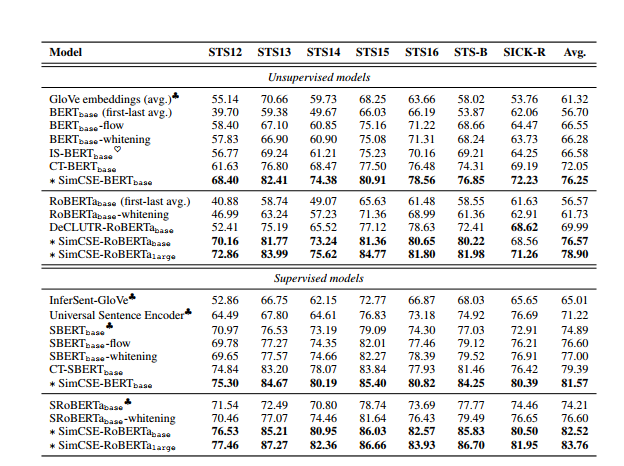
결과적으로 SimCSE는 7 STS tasks 에 관해 기존의 어떤 모델의 성능을 모두 뛰어넘었다. (별로 표시된 성능이 결론!)
6.3 Ablation Studies
다른 pooling methods 와 hard negatives 의 영향도 측정했다.
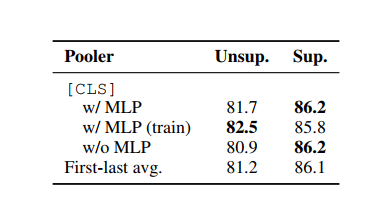
- CLS representation 이라 표기된 부분은 BERT 표현 + MLP layer 을 가장 위에 추가한 것이다. CLS 종류에도 다음과 같이 환경을 달리했다
- 표의 순서대로 MLP 레이어 추가, MLP 레이어 훈련 때만 추가, MLP 레이어 추가하지 않음! 순서이다.
- Unsup의 경우 MLP 레이어를 훈련 때에만 추가하는 것이, Sup 의 경우 MLP 레이어를 추가하는 것이 가장 성능이 좋았다. (또는 별 차이가 없었다.)
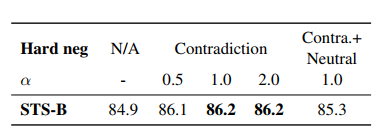
- 직관적으로 배치의 negative 중에서도 hard negatives(=contradiction;) 을 더 분리하는 것이 좋아보이므로 여기에 가중치를 줬다.(다른 문장 속에서도 contradiction 아닌 것과 contradiction 인 것 분리)
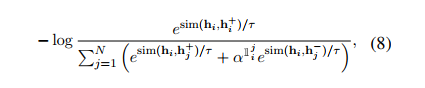
- 결과적으론 가중치 = 1.0 인 것이 가장 성능이 좋았다. (🤔1.0이면 기존과 같은 것 아닌가?)
7. Analysis
Uniformity and alignment
inner workings 를 알아보자.
1. pre-trained 의 alignment 가 좋더라도, uniformity 는 별로였다. (anisotropic 문제)
2. post-processing 방법은 uniformity 를 향상시킬 수 있었으나 alignment 는 별로였다. (BERT-flow, BERT-whiltening)
3. unsup SimCSSE 는 좋은 alignment 를 유지하면서도 uniformity 에서 좋았다.
4. sup data 를 사용한 SimCSE 는 alignment 를 더 향상.
9. Conclusion
Contrastive objective 기반의 모델은
- text input 에 있어서 data augmentation의 새로운 관점을 제시할 것임
- 다른 continuous representation 으로 확장되거나
- language model pre-training 과 결합되어 사용될 수 있을 것임.
