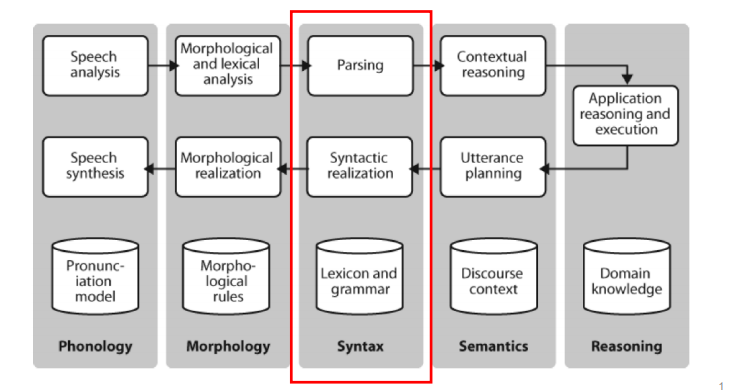
Syntax
어떤 인간 화자는 infinite number of possible sentences 를 만들고 이해할 수 있다. 어떻게 이게 가능할까? >> Syntax 덕분! 덕분에 우리는 문장을 통째로 외우는 게 아니라 부분부분으로 조합하고 쪼개어 말하고 이해할 수 있는 것이다. 따라서 Syntax 는 문장형성 규칙이다.
문법에 포함되지 않는것들로는
- 문법은 meaningfulness 나 truthfulness 은 포함하지 않는다. >> 문법이 맞아도 의미가 없거나 사실이 아닐 수 있음.)
- 같은 맥락에서 문법적으로 맞지 않지만 이해 가능한 문장이 있을 수 있다.
문법에 포함되는 것들로는
- Syntax 는 기본적으로 문장을 이루는 규칙이다. 단어를 구로 결합하거나 구를 문장으로 결합하는데 Syntax 규칙 사용.

- 문장의 형성뿐 아니라 형성된 문장을 이해하는데도 이러한 규칙을 이용한다.
- 따라서 Compositionality 합성성을 가진다고 함.
What the Syntax Rules Do
-
Specify the correct word order for a language
영어의 SVO든, 한국어의 SOV 와 같은 구조이든 언어에 맞게 적절한 단어 순서를 제시한다. S, V, O 를 순열하면 경우의 수는 6가지이며 대부분이 SVO, SOV 로 이루어져 있다. -
Describe the relationship between the meaning of a group of words and the arrangement of the words
단어와 단어 사이 관계를 정의한다는 것으로 올바른 어순이라도 어순에 따라 의미가 달라진다. 예컨대 'I mean what I say' 와 'I say what I mean' 이라는 두 문장이 있다고 하자. 문장 구성 요소는 같고, 어순은 두 문장 모두 가능한 어순이다. 그러나 의미가 다르다는 점.. -
Specify the grammatical relations
무엇이 주어이고 목적어인지 격을 결정한다. 특히나 영어의 경우 다른 표지 없이 어순으로 격을 결정하기 때문에 어순에 따른 언어, 어순이 의미를 결정한다고 하는 것이다. 예컨대 'Your dog chased my cat' 은 너의 강아지가 내 고양이를 쫓아온 것, 'My cat chased your dog' 은 내 고양이가 너의 강아지를 쫒아온 것이다. 한국어는 postposition 덕분에 이러한 단어 순서로부터 자유롭다. -
Specify constraints on sentences based on the verb of the sentences
동사에 따라 문장의 제약이 가능하다. 예컨대 'found' 라는 동사 뒤에는 목적어가 등장하는 것이 제약이고, 'slept' 라는 동사 뒤에는 목적어가 등장하지 않는 것이 제약이다.
High-context vs. Low-context
말을 전달하는데는 context, information, meaning 이 있으며, LC의 경우 information 을 통해 의미를 전달하고, HC의 경우 context 를 통해 의미를 전달하는 경우가 많다. 동양의 언어가 보통 HC, 서양의 언어들이 LC 인 경우가 많다.
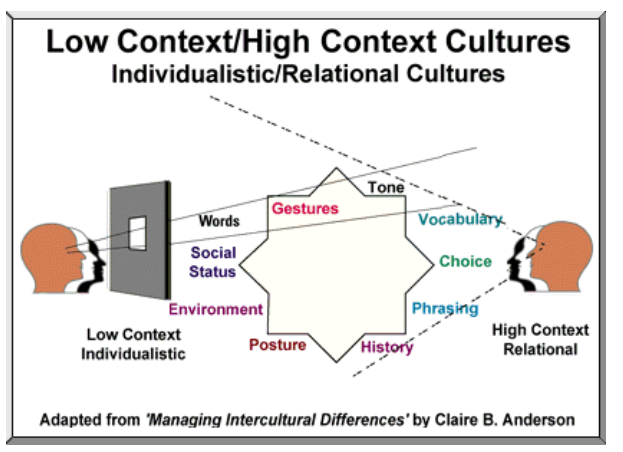
High-context culture
- 아시안 언어 또는 종의 다양성이 떨어지는 문화권이 주로 속하며, 맥락에 의존하는 경우가 많아 Hard to enter 하다.
- close-knit community (닫힌 좁은 커뮤니티 지향)
- context 에 의존, coded(쓰인), explicit(겉으로 드러난), transmitted(전달된) part of the message 의 비중은 적음.
- 많은 것들이 unsaid.
- in-group solidarity / reliance / support
Low-context culture
- mass of information is vested in the explicit code
- data, logical, rational
- Easy to enter
- Self-reliance
- Wide network, shallow interaction
Sentence Structure
"The child found the puppy" : Det - N - V - Det - N
그러나 문장은 위와 같이 flat 하지 않고 hierarchical organization 이다. 따라서 Tree diagram 으로 그려볼 수 있는데, 위 문장을 트리로 그려보자.
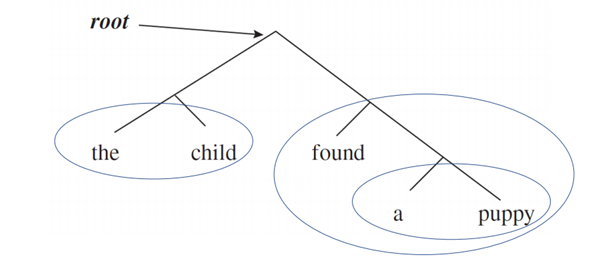
[the child][found a puppy] 와 같은 덩어리들을 Syntactic Category 라고 한다. 공통점들을 가지고 만나는 묶음을 의미한다.
- 대체하더라도 문법성을 해치지 않는다: 'the child' 위치에 'A police officer'이 들어갈 수 있다.
- Phrasal categories 로 NP, VP, PP, AdjP, AdvP 가 있다.
- Korean POS tagging 의 경우 형태소 단위로 먼저 쪼개는 과정을 거치고, 쪼갠 형태소에 category 를 붙이는 작업을 한다. (decompose)
- 이렇게 쪼개고 단 라벨을 다시 compose 하는 과정도 필요하다.
Phrase Structure Rules
품사를 태깅한 이후 이들이 결합되어서 이루는 구를 어떻게 구성할지에 대한 규칙이다. 이를 PS 규칙이라 하며, 다음과 같은 규칙이 있다.

그러나 이러한 규칙을 정리하려면 굉장히 많은 규칙이 필요하고 / 규칙끼리 충돌하기도 하며 / 생각보다 잘 동작하지 않는다. / 언어에 따라 잘 될 수도, 잘 되지 않을 수도.
- 모든 구의 core 는 head 라 한다. 예컨대 VP 'walk the pugs' 에서는 walk 가 head 이다.
- head 의 의미를 정교화하고 보충해주는 것은 complement 라 한다. 예컨대 PP 'over the river' 에서 NP the river 는 complement 이다.
- PS tree 에서 모든 부모 노드는 그 아래 자식 노드를 dominate 한다고 한다. 따라서 S dominates everything
- 바로 아래 자식노드는 immediately dominates 한다고 한다.
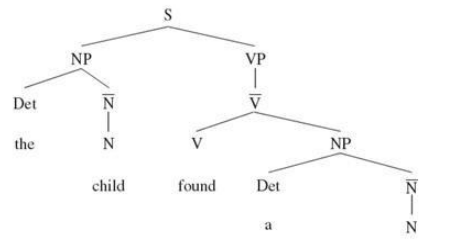
How words form groups?
"The captain ordered the old men and women off the ship" 이라는 문장이 있을 때, 만들어질 수 있는 중의성에 대해 알아보자.
- The captain ordered the [old [men and women]] off the ship.
- The captain ordered the [old men] and [women] off the ship
위와 같이 그룹화되는 순서에 따라 의미는 달라질 수 있다. 1. 의 경우 남자와 여자 모두 나이가 들었음을 지칭하며, 2의 경우 나이든 남자, 그렇지 않은 전체 여자를 의미한다.
이 외에도 하나의 문장은 두가지 이상의 의미로 해석될 수 있는데, 이를 Ambiguity 라 한다. >> 어떻게 disambiguate 할까? 바로 hierarchically 한 특성을 이용하는 것! hierarchically 하다는 것은 sentece grouped 의 순서에 따라 의미가 달라질 수 있는 것을 말한다. 어떻게 그룹을 묶는지에 따라 달라지는 의미를 분석하고, 맥락, 어조, 휴지 등을 추가로 고려하자.
다른 유명한 예시로 "The boy saw the man with the telescope" 가 있다.
1. The boy used the telescope to see the man.
2. The boy saw the man who had a telescope.
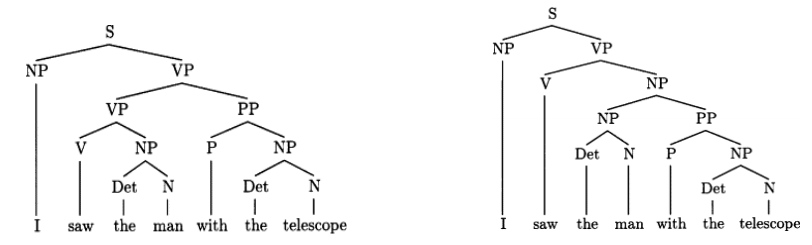
Cf. lexical ambiguity
문장 구조보다 단어 그 자체로 발생하는 ambiguity 를 말한다.
- 철수의 집이 기울었다
- 비서가 차를 준비했다 etc...
Cf. Examples of another ambiguity
다른 형태의 ambiguity 를 말한다.
- 모든 남자들이 한 여자를 사랑한다. (모든 남자들이 각자의 한 여자를 사랑한다 / 모든 남자들이 딱 1명의 여자를 사랑한다)
Selection
앞에서 본 constraints 와 같은 맥락의 개념이다. 잘 만들어진 문장은 구조적인 제약을 지켜야 하며 (C-selection) 의미적인 요구사항 (S-selection) 도 맞아야 한다. 아까는 문법적인 constraint 만 논했다면 S-selection 도 추가하여 Selection 개념으로 이해해자.
C-selection 또는 subcategorization: head 가 어떤 complements 를 가질 수 있고 가져야 하는지를 말한다.
예컨대
- find 라는 동사는 NP 가 뒤에 필요하다
- put 이라는 동사는 NP, PP 둘 다 필요하다
- sleep 이라는 동사는 뒤에 complement 가 필요없다. etc..
S-slection: 동사는 또한 semantic 한 properties 에 따라 subject 와 complements 를 선택할 수 있다.
예컨대
- The beer drank the lamp
- Colorless green ideas sleep furiously
등과 같은 문장이 있다.
Levanshtein 한글 자모 분리 버전
# 초성 리스트. 00 ~ 18
CHOSUNG_LIST = ['ㄱ', 'ㄲ', 'ㄴ', 'ㄷ', 'ㄸ', 'ㄹ', 'ㅁ', 'ㅂ', 'ㅃ', 'ㅅ', 'ㅆ', 'ㅇ', 'ㅈ', 'ㅉ', 'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ']
# 중성 리스트. 00 ~ 20
JUNGSUNG_LIST = ['ㅏ', 'ㅐ', 'ㅑ', 'ㅒ', 'ㅓ', 'ㅔ', 'ㅕ', 'ㅖ', 'ㅗ', 'ㅘ', 'ㅙ', 'ㅚ', 'ㅛ', 'ㅜ', 'ㅝ', 'ㅞ', 'ㅟ', 'ㅠ', 'ㅡ', 'ㅢ', 'ㅣ']
# 종성 리스트. 00 ~ 27 + 1(1개 없음)
JONGSUNG_LIST = [' ', 'ㄱ', 'ㄲ', 'ㄳ', 'ㄴ', 'ㄵ', 'ㄶ', 'ㄷ', 'ㄹ', 'ㄺ', 'ㄻ', 'ㄼ', 'ㄽ', 'ㄾ', 'ㄿ', 'ㅀ', 'ㅁ', 'ㅂ', 'ㅄ', 'ㅅ', 'ㅆ', 'ㅇ', 'ㅈ', 'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ']
def korean_to_be_englished(korean_word):
r_lst = []
for w in list(korean_word.strip()):
## 영어인 경우 구분해서 작성함.
if '가'<=w<='힣':
## 588개 마다 초성이 바뀜.
ch1 = (ord(w) - ord('가'))//588 # ord('가') 는 44032, 588은 중성 21개와 종성 없음 포함 28개를 곱한 수, 즉 초성은 588개마다 바뀜
## 중성은 총 28가지 종류
ch2 = ((ord(w) - ord('가')) - (588*ch1)) // 28 # 중성은 종성 28개가 다 돌고 난후 바뀜
ch3 = (ord(w) - ord('가')) - (588*ch1) - 28*ch2
r_lst.extend([CHOSUNG_LIST[ch1], JUNGSUNG_LIST[ch2], JONGSUNG_LIST[ch3]])
else:
r_lst.extend([w])
return r_lst
# 한글 자모 분리버전 레반슈타인 (update ver)
def LevenDist(word1, word2):
word1 = korean_to_be_englished(word1)
word2 = korean_to_be_englished(word2)
len1, len2 = len(word1), len(word2) # word1의 길이가 len1, word2 의 길이가 len2
# 현재 len1 은 5, len2는 4
Leven = [[0]*(len2+1) for _ in range(len1+1)]
for k in range(1,len2+1): Leven[0][k] = k
for k in range(1,len1+1): Leven[k][0] = k
for i in range(1, len1+1): # 1-5까지
for j in range(1, len2+1): # 1-4 까지
if word1[i-1] == word2[j-1]: Leven[i][j] = Leven[i-1][j-1]
else: Leven[i][j] = min(Leven[i-1][j], Leven[i][j-1], Leven[i-1][j-1])+1
return Leven[len1][len2]
LevenDist('내동생고기', '냉동생고기')위와 같은 형태로 함수를 구성할 경우
- 내동생고기, 냉동생고기의 거리와
- 내동생고기, 제동생고기의 거리를 다르게 처리할 수 있다. (기존에는 해결 불가능했던 문제)


