Words
단어는 언어 지식을 구성하는 중요한 요소이며, mental grammar 을 구성하기도 한다. 우리는 mental dictionary 을 가지고 있는데, 다음과 같은 정보를 포함한다. 아래의 네 가지를 다 알고 있어야 단어를 비로소 안다고 할 수 있다!
- Pronounciation
- Meaning
- Orthography (철자)
- Grammatical category
Morphology: 단어 구조와 형성 규칙을 연구하는 학문, 이론 분야이다.
- 나는 학교에 간다
- 학교에 나는 새
사람은 '나는 학교에 간다' 의 '나는'을 보면 바로 하늘을 나는이 아닌 자신이란 뜻의 나는을 떠올린다. '학교에 나는 새'의 '나는' 은 당연히 날다의 활용형임을 알아차릴 것이다. 구체적으로 논의해보면, '나는' 의 후보는 세 가지 정도이다
- 나/대명사 + 는/조사
- 나/동사 + 는/어미
- 날/동사 + 는/어미
'나는 학교에 간다' 라는 문장에선 1번을 선택하고, '하늘을 나는 새'는 3번을 선택할 것이다. 이러한 선택을 하는 것이 Morphology! 그러나 대부분의 데이터가 적절하지 못한 띄어쓰기, 특히나 한국어의 경우 어절의 문제로 어떠한 clue 를 가지고 tokenization 할 지의 고민이 생긴다.
Normalization
Normalization 이란 words/tokens 를 standard format 으로 변환시키는 작업을 말한다. 예컨대 마침표를 제거하거나, 모든 단어를 lowercase 로 바꾸는 작업이 있다.
Normalization 은 왜 진행하는가? 찾기 과정의 단순화, text matching 향상, 그러나 구체적으로 Normalization 을 어떻게 진행할지에 대한 문제가 있다. US 를 모두 lowercase 로 변환하면 미국이란 뜻의 US 와 우리라는 뜻의 us 를 어떻게 구별할 것인지..?
추가적인 예로
- Windows vs. windows,
- Mr.
- Possesive endings
- Hyphens (Calcium-dependent >> 한 단어, New York-New Jersey >> 두 단어이므로 쪼개기 필요)
- Word-internal punctuation
- Multi-token words (Rock 'n' roll)의 문제가 있다. 결국 결론은 최대한 정확도를 높이는 방향으로 가야하지만 완벽할 순 없다는 것.
Word tokenization
한국어/영어 문장을 general 하게 토큰화하는 것은 그리 어려운 일은 아니다. 보통 스페이스로 나누면 되기 때문. 그러나 스페이스로 나뉘어지지 않는 경우가 꽤 많아 hueristics 한 방법을 이용한다.
Stemming vs. Lemmatization
토큰화된 단어의 원형을 찾는 작업을 말한다.

우리 머릿속엔 단어의 활용형이 아닌 단어의 원형이 들어있으며, 원형을 찾는 과정이 필수적인데, 공통된 부분을 제외하고 단순히 잘라내는 것을 Stemming(따라서 기술적으로 더 쉽다) 사전에 등장하는 실제 원형을 찾아내는 것을 Lemmatization 이라 한다. 사진으론 왼쪽 chang을 찾은 것이 Stemming, 실제 원형인 change 를 찾은 것이 Lemmatization.
Content Words and Function Words
모든 언어에 적용되는 분류로 단어를 의미가 있는 말인 Content Word 와 기능만 하는 단어인 Function Word 로 분리해볼 수 있다. 우리의 머릿속에서도 Content Word 와 Function Word 를 다르게 처리한다.
-
Content word 는 nouns, verbs, adjectives 등이 있고 Function words 에는 articles, prepositions, conjunctions 등이 있다.
-
Content Word 는 의미를 가지고 있는 말로 Open class 이다. 그러나 Function Word 는 유한개의 변하지 않는 Set 로 Closed class 이다.
-
따라서 Function Word 는 대부분의 NLP처리에 있어서 stop words 이다.
Morphemes
Stemming, Lemmatization 을 한다는 것은 단어가 아닌 morpheme 을 찾는 과정이다. morpheme 이란 따라서 의미를 갖는 최소 단위를 의미한다! 아래의 예로 보자. 그 자체로 단어가 되는 경우가 있고, 여러 Morpheme 이 모여 하나의 단어를 구성하는 경우가 더 많다.

어떤 형태소는 혼자서 쓸 수 있고, 어떤 형태소는 혼자서 쓸 수 없다. 전자를 Free morphemes, 후자를 Bound morpheme 이라 한다.
- Free morpheme: stand alone; book, 새, 하늘 etc
- Bound morpheme: cannot stand alone must be attached to other morphemes (Prefixes, Suffixes)
영어는 비교적 형태소 분석이 단순, 한국어는 어렵다.(한국어는 교착어이므로)
-
Infixes: 가운데 들어가는 morpheme 이다. 영어에는 존재하지 않는다.
-
Circumfixes: 루트의 beginning 과 end 에 등장할 수 있는 affixes.
Rules of Word Formation
형태소를 다르게 보는 시각이다.
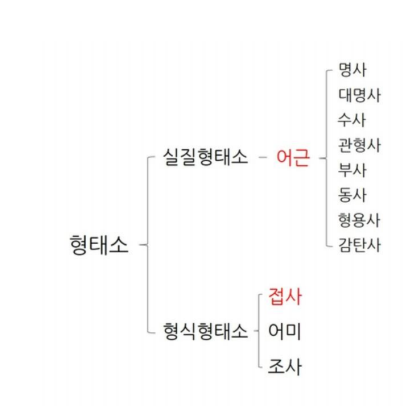
- Derivational Morpheme
- Inflectional Morpheme
unsystemic 을 쪼개어 보자.
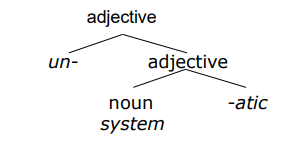
한국어 형태소
한국어는 교착어이며, 어근에 접사가 붙어 의미와 문법이 결정된다.
-
어근: 단어를 분석할 때 실질적 의미를 나타내는 중심 부분. '어른스럽다'에서는 '어른' 이다.
-
접사: 다른 어근에 붙어 새로운 단어를 구성. 접두사, 접미사가 있으며 '맨손'의 '맨', '선생님'의 '님'을 뜻한다.
-
조사: 단어에 붙어 문법적, 관계적 뜻을 나타내는 단어. 철수'가' 밥'을'
-
어미: 활용하여 변하는 부분. 어근+접사가 하나의 단어를 만들면 그 뒤로 자유롭게 활용하는 것이다. 먹'는다', 분석하'겠습니다'.
접사, 어미, 조사가 Bound morpheme 에 속하며 어근이 Free Morpheme 이자 content word 라 할 수 있다.
- 어머니가 책을 읽으셨겠네요
어머니(어근) 가(조사) 책(어근)을(조사) 읽(어근) 으시(어미) 었(어미) 겠(어미) 네요(어미)
- 몇 개의 문장을 통해 형태소 분석을 해 보겠습니다.
몇(관형사) 개(명사) 의(조사) 문장(명사) 을(조사) 통(어근) 하여(접사) 형태소(명사) 분석(명사) 을(조사) 하여(동사,어근) 보(어미) 겠(어미) 습니다(어미)
Other Process
-
Back-formations: new words through misanalysis of morpheme boundaries. editor에서 edit 이 만들어졌고, television 을 통해 televise 가 만들어졌다.
-
Acronym: named formed from the initial components. 줄임말이다! NASA, UCLA 등이 있다.
-
Abbreviation/Clipping: 뒤를 자르고 앞에만 남기는 줄임말. facsimile 에서 fax, advertisement에서 ad 등이 왔다.
-
Eponym : people's name > everyday words. 스카치테이프나 대일밴드가 누군가의 이름이었다..?
-
Blends: two words combined, parts of the words that are combined are deleted. smoke+fog = smog, breakfast+lunch = brunch.
-
Compounds: joining two or more words. landlord, headstrong, greenhouse 등이 있음.
Word tokenization (Subword Tokenization👍)
토큰화의 타입에는 3가지가 있다.
1. Word-based tokenization
2. Character-based tokenization
3. Subword tokenization
Word-based 는 큰 사전을 필요로 한다. 사전이 크지 않으면 OOV(Out of Vocab) 문제가 생기고, 따라서 드물게 나오는 경우 unk로 처리할 수 밖에 없어 문제가 된다. 이러한 문제에 대한 대응으로 등장한 것은 Character-based 이다.
Character-based 에서는 모든 글자를 쪼개며, 영어의 경우는 철자 1개씩 분리하게 된다. 이렇게 많이 분리하게 된다면.. 언어적으로 dollar / dog 의 경우 캐릭터만 보면 do 로 앞부분이 겹치지만 의미상으로 전혀 겹치지 않는다. 따라서 극단적인 쪼개기이며, 특정 언어에서만 괜찮다. (한 캐릭터가 의미를 가지는 중국어 등)
Subword 는 빈도를 고려한다. 빈도가 높은 'the' 와 같은 function word 들은 전체 단어로 인식하여 하나로 본다. 그러나 low freq 에 대해 한 번 쪼개는 과정을 거친다. 예컨대 'strwberries' 가 들어오면 'straw + berries' 로 쪼갤 수 있다. 본 적 없는 단어나 빈도가 낮은 단어를 처리할 수 있다는 장점. subword tokenization 을 사용한 알고리즘을 보자.

트레이닝 셋으로 단어장을 만든다음, 만든 단어장을 기준으로 들어온 단어를 쪼갠다. 이때 단어장을 만들 때 1. 빈도가 높은 단어들은 덩어리로 2. 빈도가 낮은 단어들은 쪼갤 수 있을만큼 쪼개는 아이디어를 사용한다.

Levenshtein Dist
- 0행과 0열을 0 - n까지 채운다
- 같으면 [-1][-1] 에서 그대로 가져온다
- 다르면 왼,대각,위에서 가장 작은 것을 가져오고 1을 더한다
def LevenDist(word1, word2):
len1, len2 = len(word1), len(word2) # word1의 길이가 len1, word2 의 길이가 len2
# 현재 len1 은 5, len2는 4
Leven = [[0]*(len2+1) for _ in range(len1+1)]
for k in range(1,len2+1): Leven[0][k] = k
for k in range(1,len1+1): Leven[k][0] = k
for i in range(1, len1+1): # 1-5까지
for j in range(1, len2+1): # 1-4 까지
if word1[i-1] == word2[j-1]: Leven[i][j] = Leven[i-1][j-1]
else: Leven[i][j] = min(Leven[i-1][j], Leven[i][j-1], Leven[i-1][j-1])+1
return Leven[len1][len2]
LevenDist('meron', 'maroon')그러나 한글의 경우
- 내동생고기
- 냉동생고기
- 제동생고기
- 나동생고기
에 각각 다른 점수를 줘야하고, 따라서 하나의 단어 역시나 character 단위로 decompose 하는 작업이 필요하다. decompose 까지 포함한 코드를 짜보자.
