OOF (Out Of Fold) prediction
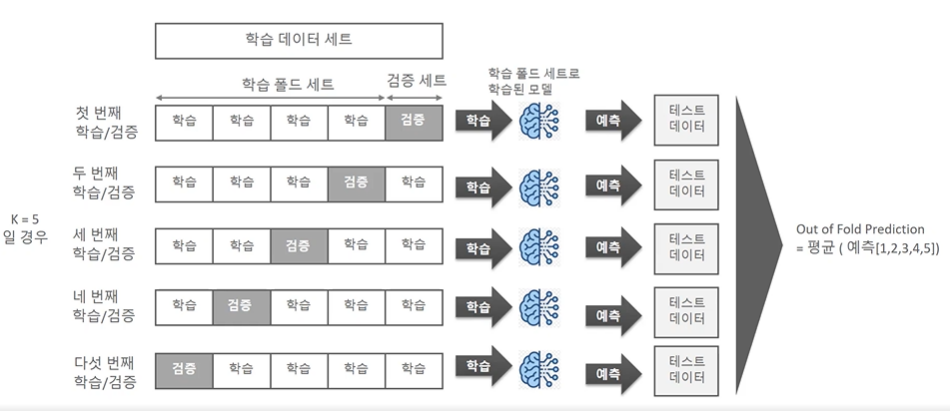
K-fold 교차검증과 같은 방식이다. 데이터세트를 본래 학습-검증으로 나누는데 이를 K 번 실행하고, K개 중 하나에 검증데이터 역할을 모두 부여하는 것이다. 학습을 시킨다음 모델의 최종 예측을 각 모델의 예측을 평균하여 확정하는 것이다.
적용
from sklearn.model_selection import KFold
def train_apps_all_with_oof(apps_all_train, apps_all_test, nfolds=5):
ftr_app = apps_all_train.drop(['SK_ID_CURR', 'TARGET'], axis=1)
target_app = apps_all_train['TARGET']
# nfolds 개의 cross validatin fold set을 가지는 KFold 생성
folds = KFold(n_splits = nfolds, shuffle = True, random_state = 2020)
# Out of Folds로 학습된 모델의 validation set을 예측하여 결과 확률을 담을 array 생성.
# validation set가 n_split갯수만큼 있으므로 크기는 ftr_app의 크기가 되어야 함.
oof_preds = np.zeros(ftr_app.shape[0])
# Ouf of Folds로 학습된 모델의 test dataset을 예측하여 결과 확률을 담을 array 생성.
test_preds = np.zeros(apps_all_test.shape[0])
# n_estimators를 4000까지 확대.
clf = LGBMClassifier(
nthread=4,
n_estimators=4000,
learning_rate=0.01,
max_depth = 11,
num_leaves=58,
colsample_bytree=0.613,
subsample=0.708,
max_bin=407,
reg_alpha=3.564,
reg_lambda=4.930,
min_child_weight= 6,
min_child_samples=165,
silent=-1,
verbose=-1,
)
# nfolds 번 cross validation Iteration 반복하면서 OOF 방식으로 학습 및 테스트 데이터 예측
for fold_idx, (train_idx, valid_idx) in enumerate(folds.split(ftr_app)):
print('##### iteration ', fold_idx, ' 시작')
# 학습용 데이터 세트의 인덱스와 검증용 데이터 세트의 인덱스 추출하여 이를 기반으로 학습/검증 데이터 추출
train_x = ftr_app.iloc[train_idx, :]
train_y = target_app.iloc[train_idx]
valid_x = ftr_app.iloc[valid_idx, :]
valid_y = target_app.iloc[valid_idx]
# 추출된 학습/검증 데이터 세트로 모델 학습. early_stopping은 200으로 증가.
clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)], eval_metric= 'auc', verbose= 200,
early_stopping_rounds= 200)
# 검증 데이터 세트로 예측된 확률 저장. 사용되지는 않음.
oof_preds[valid_idx] = clf.predict_proba(valid_x, num_iteration=clf.best_iteration_)[:, 1]
# 학습된 모델로 테스트 데이터 세트에 예측 확률 계산.
# nfolds 번 반복 실행하므로 평균 확률을 구하기 위해 개별 수행시 마다 수행 횟수로 나눈 확률을 추후에 더해서 최종 평균 확률 계산.
test_preds += clf.predict_proba(apps_all_test.drop('SK_ID_CURR', axis = 1), num_iteration = clf.best_iteration_)[:, 1]/folds.n_splits
return clf, test_predsimport datetime
print(datetime.datetime.now())
clf, test_preds = train_apps_all_with_oof(apps_all_train, apps_all_test, nfolds=5)
print(datetime.datetime.now())
Mathematics, Algorithm, and IDEA for AI research🦖