POS_CASH_balance, installments_payments, credit_card_balance 개요
월별 현금 대출 잔액, 대출 채무 이행 이력, 월별 카드 대출 잔액을 뜻한다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import os, sys
from google.colab import drive
drive.mount('/content/gdrive')
%cd '/content/gdrive/My Drive/'
!ls
def get_balance_data():
pos_dtype = {
'SK_ID_PREV':np.uint32, 'SK_ID_CURR':np.uint32, 'MONTHS_BALANCE':np.int32, 'SK_DPD':np.int32,
'SK_DPD_DEF':np.int32, 'CNT_INSTALMENT':np.float32,'CNT_INSTALMENT_FUTURE':np.float32
}
install_dtype = {
'SK_ID_PREV':np.uint32, 'SK_ID_CURR':np.uint32, 'NUM_INSTALMENT_NUMBER':np.int32, 'NUM_INSTALMENT_VERSION':np.float32,
'DAYS_INSTALMENT':np.float32, 'DAYS_ENTRY_PAYMENT':np.float32, 'AMT_INSTALMENT':np.float32, 'AMT_PAYMENT':np.float32
}
card_dtype = {
'SK_ID_PREV':np.uint32, 'SK_ID_CURR':np.uint32, 'MONTHS_BALANCE':np.int16,
'AMT_CREDIT_LIMIT_ACTUAL':np.int32, 'CNT_DRAWINGS_CURRENT':np.int32, 'SK_DPD':np.int32,'SK_DPD_DEF':np.int32,
'AMT_BALANCE':np.float32, 'AMT_DRAWINGS_ATM_CURRENT':np.float32, 'AMT_DRAWINGS_CURRENT':np.float32,
'AMT_DRAWINGS_OTHER_CURRENT':np.float32, 'AMT_DRAWINGS_POS_CURRENT':np.float32, 'AMT_INST_MIN_REGULARITY':np.float32,
'AMT_PAYMENT_CURRENT':np.float32, 'AMT_PAYMENT_TOTAL_CURRENT':np.float32, 'AMT_RECEIVABLE_PRINCIPAL':np.float32,
'AMT_RECIVABLE':np.float32, 'AMT_TOTAL_RECEIVABLE':np.float32, 'CNT_DRAWINGS_ATM_CURRENT':np.float32,
'CNT_DRAWINGS_OTHER_CURRENT':np.float32, 'CNT_DRAWINGS_POS_CURRENT':np.float32, 'CNT_INSTALMENT_MATURE_CUM':np.float32
}
pos_bal = pd.read_csv('POS_CASH_balance.csv', dtype=pos_dtype)
install = pd.read_csv('installments_payments.csv', dtype=install_dtype)
card_bal = pd.read_csv('credit_card_balance.csv', dtype=card_dtype)
return pos_bal, install, card_bal
pos_bal, install, card_bal = get_balance_data()데이터 세트를 가져와서 pos_bal, install, card_bal 을 가져왔다. dtypes 는 데이터를 가져올 때 타입을 뜻한다. 예컨대 pos_bal 을 read_csv 에 다른 파라미터를 입력해주지 않으면 int64로 모두 가져와서 메모리가 매우 커지는 문제가 생긴다. pos_dtype 에 딕셔너리 형태로 각 컬럼에 따라 비트를 제한시킴으로써 메모리를 줄일 수 있다. 다른 install 과 card_bal 도 이 딕셔너리로 해결해준다.
import gc
del pos_bal_temp
gc.collect()
#객체 죽이기객체를 죽이는 코드다.
app_train = pd.read_csv('application_train.csv')
app_test = pd.read_csv('application_test.csv')
apps = pd.concat([app_train, app_test])applicatoin 세터도 가져와 apps 에 저장해줬다.
컬럼 설명
본격적으로 어떤 컬ㄹ럼이 있는지 살펴보도록 하자.
pos_bal 데이터에는 SK_ID_PREV 와 SK_ID_CURR 이 기본으로 있다.
pos_bal.groupby('SK_ID_CURR')['SK_ID_CURR'].count() #SK_ID_CURR 레벨 별로 몇 건 있는지.월별 현금 대출 잔액을 나타내고 있는 pos_bal 이다. 현재 대출 ID 별로 몇 건 있는지 세보자.

pos_bal.groupby('SK_ID_CURR')['SK_ID_CURR'].count().mean()
pos_bal.groupby('SK_ID_PREV')['SK_ID_PREV'].count().mean()
pos_bal.groupby('SK_ID_CURR')['SK_ID_PREV'].nunique().mean() #CURR 별로 봤을 때 PREV 가 몇 건?
평균적으론 현재 대출에 관해 평균 29, 과거 대출에 관해 10, 현재 별로 봤을 때 과거 대출은 2회를 볼 수 있다.
신청일 기준 잔 월을 확인하는 MONTHS_BALANCE 를 확인해보자.
pos_bal['MONTHS_BALANCE'].value_counts().head(40)
다음과 같이 잔월과 그에 대한 건수를 확인할 수 있다. 다음은 히스토그램으로 시각화한 것이다. 10개월 잔월 정도가 가장 높은 수치를 기록하고 있다.
pos_bal['MONTHS_BALANCE'].hist(bins=100)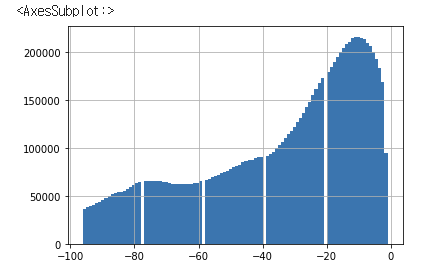
card_bal 에 대한 히스토그램이다. 이 경우 10개월보다 낮은 잔월이 가장 높은 수치를 기록하고 있다.
card_bal['MONTHS_BALANCE'].hist(bins=100)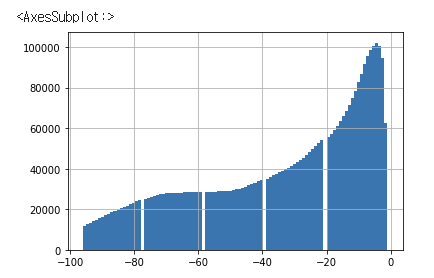
card_bal 를 박스플롯으로 나타내보자. 10개월이 조금 넘을 때부터 55개월까지 많이 분포한다.
sns.boxplot(card_bal['MONTHS_BALANCE'])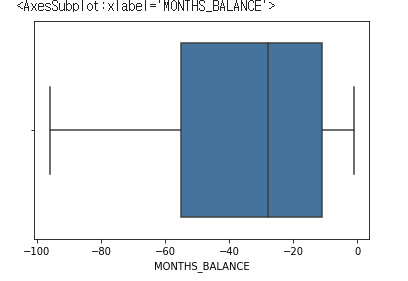
install 에 대한 히스토그램이다. 365일 1년 정도 안으로 많이 분포하고 있다.
install['DAYS_INSTALMENT'].hist(bins=100) #실제 납부 예정일 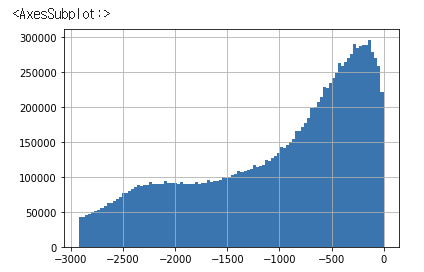
Feature Engineering
POS_CASH_balance
FE 를 진행해보자.
pos_bal['SK_DPD'].value_counts() #연체 일자 (0인 것이 당연히 많음) SK_DPD 의 경우 연체일자를 나타내는 피처이다. value_counts() 를 찍어보자.

다음과 같이 연체일자 0 인 것이 당연히 많으나 그렇지 않고 연체인 것도 많다.
이제 변수를 통해 연체일자가 0이 넘는 것, 0-30, 30-120, 120 이상인 자료를 추출해보자. pos_bal.shape 을 하면 전체 row 의 개수가 출력되는데, 이를 통해 비율을 알아보자.
# 연체 일자(SK_DPD)가 0 보다 큰 경우, 0-30 사이, 30-120 사이, 120보다 큰 경우 조사
cond_over_0 = pos_bal['SK_DPD'] > 0
cond_over_0_30 = (pos_bal['SK_DPD'] > 0) & (pos_bal['SK_DPD'] <= 30)
cond_over_30_120 = (pos_bal['SK_DPD'] > 30) & (pos_bal['SK_DPD'] < 120)
cond_over_120 = pos_bal['SK_DPD'] >= 120
print('연체비율: ', pos_bal[cond_over_0].shape[0]/pos_bal.shape[0]) #전체 중 연체 비율
print('연체비율 30일 미만: ', pos_bal[cond_over_0_30].shape[0]/pos_bal.shape[0])
print('연체비율 30-120: ', pos_bal[cond_over_30_120].shape[0]/pos_bal.shape[0])
print('연체비율 120 이상: ', pos_bal[cond_over_120].shape[0]/pos_bal.shape[0])
코드에는 어려운 것이 크게 없고, 두 가지 이상 조건을 결합할 때 괄호로 묶어주는 것과 개수를 측정하기 위해 .shape[0] 을 이용한다는 정도를 기억해두자. 나타난 비율에 따르면 연체 비율이 0.02, 30일 미만이 0.01, 30-120 일이 0.001, 120 이상은 0.01 정도 된다.
# 연체여부, 연체일수 0~ 120 사이 여부, 연체 일수 120보다 큰 여부
pos_bal['POS_IS_DPD'] = pos_bal["SK_DPD"].apply(lambda x: 1 if x > 0 else 0)
pos_bal['POS_IS_DPD_UNDER_120'] = pos_bal["SK_DPD"].apply(lambda x:1 if (x>0) & (x<120) else 0)
pos_bal['POS_IS_DPD_OVER_120'] = pos_bal['SK_DPD'].apply(lambda x: 1 if x>120 else 0)다음은 실제로 새로운 칼럼 가공 과정이다. .apply(lambda) 를 이용하고, 조건에 맞는 식은 x 에 1을 그렇지 않으면 0 을 부여하면 된다. 실제 결과를 확인하자.
120 이상 연체만 추출했을 때 연체, 120일 이상 연체에 각각 1이 잘 표시된 것을 확인할 수 있다.
신규 agg 컬럼 추가 생성
역시나 이전에 해준 작업과 비슷하게 기존 칼럼과 가공 칼럼 (위) 3개를 바탕으로 신규 agg 컬럼을 생성해보자. 중간자를 만들고, 딕셔너리를 인자로 전달하는 것까지 같다!
pos_bal_grp = pos_bal.groupby('SK_ID_CURR')
pos_bal_agg_dict = {
'SK_ID_CURR':['count'],
'MONTHS_BALANCE':['min', 'mean', 'max'],
'SK_DPD':['min', 'max', 'mean'],
# 가공 컬럼
'POS_IS_DPD':['mean', 'sum'],
'POS_IS_DPD_UNDER_120':['mean', 'sum'],
'POS_IS_DPD_OVER_120':['mean', 'sum']
}
# SK_ID_CURR레벨로 Aggregation 컬럼들 aggregation groupby 수행.
pos_bal_agg = pos_bal_grp.agg(pos_bal_agg_dict)
# 컬럼 변경
pos_bal_agg.columns = [('POS_')+('_').join(column).upper() for column in pos_bal_agg.columns.ravel()]이제 posbal_agg 에는 POS (이름) 이 붙은 새로운 컬럼들이 생성되었다.
최근 데이터 별도로 agg 가공
MONTHS_BALANCE 중 20개월 이내의 최근 데이터를 agg 가공해 조인하자. 다루는 컬럼은 같으나 조건을 추가하는 것이다.
cond_months = pos_bal['MONTHS_BALANCE'] > -20 #조건 추가가
pos_bal_m20_grp = pos_bal[cond_months].groupby('SK_ID_CURR') #조건 + groupby
#나머지 같음.
pos_bal_agg_dict = {
'SK_ID_CURR':['count'],
'MONTHS_BALANCE':['min', 'mean', 'max'],
'SK_DPD':['min', 'max', 'mean'],
# 가공 컬럼
'POS_IS_DPD':['mean', 'sum'],
'POS_IS_DPD_UNDER_120':['mean', 'sum'],
'POS_IS_DPD_OVER_120':['mean', 'sum']
}
pos_bal_m20_agg = pos_bal_m20_grp.agg(pos_bal_agg_dict)
# 컬럼 변경
pos_bal_m20_agg.columns = [('POS_M20')+('_').join(column).upper() for column in pos_bal_m20_agg.columns.ravel()]나머지 코드는 같으나 pos_bal['MONTHS_BALANCE'] > -20 조건을 추가했다. pos_bal_m20_agg 를 기존 pos_bal_agg 에 조인해주자. 이름은 pos_bal_agg 로 유지한다.
os_bal_agg = pos_bal_agg.merge(pos_bal_m20_agg, on='SK_ID_CURR', how='left') #기존 가공과 최근 가공을 조인
pos_bal_agg = pos_bal_agg.reset_index()installments_payments
install 에는 다음과 같은 컬럼이 있다.
DAYS_INSTALMENT : 납부 예정 일자
DAYS_ENTRY_PAYMENT : 실제 납부 일자
AMT_INSTALMENT : 실제 납부 금액
AMT_PAYMENT : 예정 납부 금액
본격적으로 FE 를 진행해보자. 계산하고 싶은 신규 컬럼 3개는 다음과 같다.
- 예정 납부 금액-실제 납부 금액
- 예정 납부 금액 / 실제 납부 금액 (+1씩 해줌)
- 실제 납부 일자-예정 납부 일자
# 예정 납부 금액과 실제 납부 금액 차이와 비율 가공
install['AMT_DIFF'] = install['AMT_INSTALMENT'] - install['AMT_PAYMENT'] #예정 - 실제
install['AMT_RATIO'] = (install['AMT_PAYMENT'] +1)/ (install['AMT_INSTALMENT'] + 1) #예정 - 실제 비율율
# 예정 납부 일자 대비 실제 납부 일자 비교로 DPD 일자 생성
install['SK_DPD'] = install['DAYS_ENTRY_PAYMENT'] - install['DAYS_INSTALMENT'] #실제 - 예정 일자
install.head(20)신규 컬럼 3개가 만들어졌다. 다음은 install 에서도 연체 여부, 0-120 사이 여부, 120 이상 여부를 0과 1로 체크하는 컬럼을 가공할 것이다. 일단 비율 조사를 진행해보자.
# 연체 일자(SK_DPD)가 0 보다 큰 경우, 30-120 사이, 120보다 큰 경우 조사 (앞의 코드와 같음)
cond_over_0 = install['SK_DPD'] > 0
cond_over_0_30 = (install['SK_DPD'] <= 30) & (install['SK_DPD'] > 0)
cond_over_30_120 = (install['SK_DPD'] < 120) & (install['SK_DPD'] > 30)
cond_over_120 = (install['SK_DPD'] >= 120)
print(' 연체 비율:', install[cond_over_0].shape[0]/install.shape[0] )
print(' 연체 비율 30일 미만:', install[cond_over_0_30].shape[0]/install.shape[0] )
print(' 연체일자 30일이상 120이하 비율 :', install[cond_over_30_120].shape[0]/install.shape[0] )
print(' 연체일자 120이상 비율 :', install[cond_over_120].shape[0]/install.shape[0] )
연체 비율만 0.08, 30일 미만은 0.08, 30-120 은 0.002, 120 이상은 0.0007 정도로 조사된다. 이제 새로운 컬럼 3개에 연체, 0-120, 120 이상 여부를 체크해보자. 코도는 .apply(lambda) 를 이용한다.
# 연체여부, 연체일수 0~ 120 사이 여부, 연체 일수 120보다 큰 여부
install['INS_IS_DPD'] = install['SK_DPD'].apply(lambda x: 1 if x > 0 else 0)
install['INS_IS_DPD_UNDER_120'] = install['SK_DPD'].apply(lambda x:1 if (x > 0) & (x <120) else 0 )
install['INS_IS_DPD_OVER_120'] = install['SK_DPD'].apply(lambda x:1 if x >= 120 else 0)
다음과 같이 또다시 3개의 컬럼을 추가했다!
기존, 신규 컬럼 agg 생성
install_grp = install.groupby('SK_ID_CURR')
install_agg_dict = {
'SK_ID_CURR':['count'],
'NUM_INSTALMENT_VERSION':['nunique'],
'DAYS_ENTRY_PAYMENT':['mean', 'max', 'sum'],
'DAYS_INSTALMENT':['mean', 'max', 'sum'],
'AMT_INSTALMENT':['mean', 'max', 'sum'],
'AMT_PAYMENT':['mean', 'max','sum'],
# 추가 컬럼
'AMT_DIFF':['mean','min', 'max','sum'],
'AMT_RATIO':['mean', 'max'],
'SK_DPD':['mean', 'min', 'max'],
'INS_IS_DPD':['mean', 'sum'],
'INS_IS_DPD_UNDER_120':['mean', 'sum'],
'INS_IS_DPD_OVER_120':['mean', 'sum']
}
# SK_ID_CURR레벨로 Aggregation 컬럼들 aggregation groupby 수행.
install_agg = install_grp.agg(install_agg_dict)
# aggregation된 새로운 컬럼들에 컬럼명 생성.
install_agg.columns = ['INS_'+('_').join(column).upper() for column in install_agg.columns.ravel()]
install_agg.head()agg 연산을 수행해주자. 이를 install_agg 에 저장한다.
최근 데이터 별도 가공, 조인
이번엔 DAYS_ENTRY_PAYMENT 실제 납부 일자 기준 최근 데이터만 별도로 가공해 추출한다.
# DAYS_ENTRY_PAYMENT가 비교적 최근(1년 이내) 데이터만 추출.
cond_day = install['DAYS_ENTRY_PAYMENT'] >= -365
install_d365_grp = install[cond_day].groupby('SK_ID_CURR')
install_d365_agg_dict = {
'SK_ID_CURR':['count'],
'NUM_INSTALMENT_VERSION':['nunique'],
'DAYS_ENTRY_PAYMENT':['mean', 'max', 'sum'],
'DAYS_INSTALMENT':['mean', 'max', 'sum'],
'AMT_INSTALMENT':['mean', 'max', 'sum'],
'AMT_PAYMENT':['mean', 'max','sum'],
# 추가 컬럼
'AMT_DIFF':['mean','min', 'max','sum'],
'AMT_RATIO':['mean', 'max'],
'SK_DPD':['mean', 'min', 'max'],
'INS_IS_DPD':['mean', 'sum'],
'INS_IS_DPD_UNDER_120':['mean', 'sum'],
'INS_IS_DPD_OVER_120':['mean', 'sum']
}
# SK_ID_CURR레벨로 Aggregation 컬럼들 aggregation groupby 수행.
install_d365_agg = install_d365_grp.agg(install_d365_agg_dict)
# aggregation된 새로운 컬럼들에 컬럼명 생성.
install_d365_agg.columns = ['INS_D365'+('_').join(column).upper() for column in install_d365_agg.columns.ravel()]실제 납부 일자가 1년 이내엔 데이터는 install_d365_agg 에 저장했다. 이제 이 둘을 조인하여 install_agg 에 넣어주면 된다.
install_agg = install_agg.merge(install_d365_agg, on='SK_ID_CURR', how='left')
install_agg = install_agg.reset_index()credit_card_balance
card_bal FE 를 수행해보자.
- 잔고 / 월별 카드 허용한도
- 인출 금액 / 월별 카드 허용한도
컬럼 2개를 만들고 싶다.
card_bal['BALANCE_LIMIT_RATIO'] = card_bal['AMT_BALANCE']/card_bal['AMT_CREDIT_LIMIT_ACTUAL'] #잔고 / 월별 허용한도
card_bal['DRAWING_LIMIT_RATIO'] = card_bal['AMT_DRAWINGS_CURRENT'] / card_bal['AMT_CREDIT_LIMIT_ACTUAL'] #인출 금액 / 월별 허용한도-연체 여부, 연체 일수 0-120, 연체일수 120 이상 컬럼 3개를 만들고 싶다. 우선 비율 조사부터 진행해보자.
# 연체 일자(SK_DPD)가 0 보다 큰 경우, 30-120 사이, 120보다 큰 경우 조사
cond_over_0 = card_bal['SK_DPD'] > 0
cond_over_0_30 = (card_bal['SK_DPD'] <= 30) & (card_bal['SK_DPD'] > 0)
cond_over_30_120 = (card_bal['SK_DPD'] < 120) & (card_bal['SK_DPD'] > 30)
cond_over_120 = (card_bal['SK_DPD'] >= 120)
print(' 연체 비율:', card_bal[cond_over_0].shape[0]/card_bal.shape[0] )
print(' 연체 비율 30일 미만:', card_bal[cond_over_0_30].shape[0]/card_bal.shape[0] )
print(' 연체일자 30일이상 120이하 비율 :', card_bal[cond_over_30_120].shape[0]/card_bal.shape[0] )
print(' 연체일자 120이상 비율 :', card_bal[cond_over_120].shape[0]/card_bal.shape[0] )
앞서 말했던 여부를 세 칼럼으로 각각 1과 0 으로 표시해보자.
# 연체여부, 연체일수 0~ 120 사이 여부, 연체 일수 120보다 큰 여부 추가 가공.
card_bal['CARD_IS_DPD'] = card_bal['SK_DPD'].apply(lambda x: 1 if x > 0 else 0)
card_bal['CARD_IS_DPD_UNDER_120'] = card_bal['SK_DPD'].apply(lambda x:1 if (x > 0) & (x <120) else 0 )
card_bal['CARD_IS_DPD_OVER_120'] = card_bal['SK_DPD'].apply(lambda x:1 if x >= 120 else 0)기존, 신규 컬럼 agg 생성
기존 컬럼과 신규 컬럼 6개를 바탕으로 agg 도 생성해보자.
# 기존 컬럼과 가공 컬럼으로 SK_ID_CURR 레벨로 aggregation 신규 컬럼 생성.
card_bal_grp = card_bal.groupby('SK_ID_CURR')
card_bal_agg_dict = {
'SK_ID_CURR':['count'],
#'MONTHS_BALANCE':['min', 'max', 'mean'],
'AMT_BALANCE':['max'],
'AMT_CREDIT_LIMIT_ACTUAL':['max'],
'AMT_DRAWINGS_ATM_CURRENT': ['max', 'sum'],
'AMT_DRAWINGS_CURRENT': ['max', 'sum'],
'AMT_DRAWINGS_POS_CURRENT': ['max', 'sum'],
'AMT_INST_MIN_REGULARITY': ['max', 'mean'],
'AMT_PAYMENT_TOTAL_CURRENT': ['max','sum'],
'AMT_TOTAL_RECEIVABLE': ['max', 'mean'],
'CNT_DRAWINGS_ATM_CURRENT': ['max','sum'],
'CNT_DRAWINGS_CURRENT': ['max', 'mean', 'sum'],
'CNT_DRAWINGS_POS_CURRENT': ['mean'],
'SK_DPD': ['mean', 'max', 'sum'],
# 추가 컬럼
'BALANCE_LIMIT_RATIO':['min','max'],
'DRAWING_LIMIT_RATIO':['min', 'max'],
'CARD_IS_DPD':['mean', 'sum'],
'CARD_IS_DPD_UNDER_120':['mean', 'sum'],
'CARD_IS_DPD_OVER_120':['mean', 'sum']
}
# SK_ID_CURR레벨로 Aggregation 컬럼들 aggregation groupby 수행.
card_bal_agg = card_bal_grp.agg(card_bal_agg_dict)
# aggregation된 새로운 컬럼들에 컬럼명 생성.
card_bal_agg.columns = ['CARD_'+('_').join(column).upper() for column in card_bal_agg.columns.ravel()]최근 데이터 별도 agg 생성, 조인
MONTHS_BALANCE 컬럼에 잔월이 표시되어 있는데, 3개월 이내 데이터를 가지고 별도로 가공하자.
# MONTHS_BALANCE가 3개월 이하 최신 데이터만 별도로 가공.
cond_month = card_bal['MONTHS_BALANCE'] >= -3
card_bal_m3_grp = card_bal[cond_month].groupby('SK_ID_CURR')
card_bal_agg_dict = {
'SK_ID_CURR':['count'],
#'MONTHS_BALANCE':['min', 'max', 'mean'],
'AMT_BALANCE':['max'],
'AMT_CREDIT_LIMIT_ACTUAL':['max'],
'AMT_DRAWINGS_ATM_CURRENT': ['max', 'sum'],
'AMT_DRAWINGS_CURRENT': ['max', 'sum'],
'AMT_DRAWINGS_POS_CURRENT': ['max', 'sum'],
'AMT_INST_MIN_REGULARITY': ['max', 'mean'],
'AMT_PAYMENT_TOTAL_CURRENT': ['max','sum'],
'AMT_TOTAL_RECEIVABLE': ['max', 'mean'],
'CNT_DRAWINGS_ATM_CURRENT': ['max','sum'],
'CNT_DRAWINGS_CURRENT': ['max', 'mean', 'sum'],
'CNT_DRAWINGS_POS_CURRENT': ['mean'],
'SK_DPD': ['mean', 'max', 'sum'],
# 추가 컬럼
'BALANCE_LIMIT_RATIO':['min','max'],
'DRAWING_LIMIT_RATIO':['min', 'max'],
'CARD_IS_DPD':['mean', 'sum'],
'CARD_IS_DPD_UNDER_120':['mean', 'sum'],
'CARD_IS_DPD_OVER_120':['mean', 'sum']
}
# SK_ID_CURR레벨로 Aggregation 컬럼들 aggregation groupby 수행.
card_bal_m3_agg = card_bal_m3_grp.agg(card_bal_agg_dict)
# aggregation된 새로운 컬럼들에 컬럼명 생성.
card_bal_m3_agg.columns = ['CARD_M3'+('_').join(column).upper() for column in card_bal_m3_agg.columns.ravel()]이제 조인을 수행해보자.
card_bal_agg = card_bal_agg.merge(card_bal_m3_agg, on='SK_ID_CURR', how='left')
card_bal_agg = card_bal_agg.reset_index()지금까지 수행한 FE 를 별도의 함수로 생성한 코드는 (깃허브 링크) [https://github.com/KyungminPark-steck/Kaggle_HomeCreditDefaultRisk/blob/main/posh_cash_install_credit_card.py] 에 있다.
기존 application, previous, bureau, bureau_bal 데이터 가공 로직
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
def get_apps_processed(apps):
# EXT_SOURCE_X FEATURE 가공
apps['APPS_EXT_SOURCE_MEAN'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].mean(axis=1)
apps['APPS_EXT_SOURCE_STD'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].std(axis=1)
apps['APPS_EXT_SOURCE_STD'] = apps['APPS_EXT_SOURCE_STD'].fillna(apps['APPS_EXT_SOURCE_STD'].mean())
# AMT_CREDIT 비율로 Feature 가공
apps['APPS_ANNUITY_CREDIT_RATIO'] = apps['AMT_ANNUITY']/apps['AMT_CREDIT']
apps['APPS_GOODS_CREDIT_RATIO'] = apps['AMT_GOODS_PRICE']/apps['AMT_CREDIT']
# AMT_INCOME_TOTAL 비율로 Feature 가공
apps['APPS_ANNUITY_INCOME_RATIO'] = apps['AMT_ANNUITY']/apps['AMT_INCOME_TOTAL']
apps['APPS_CREDIT_INCOME_RATIO'] = apps['AMT_CREDIT']/apps['AMT_INCOME_TOTAL']
apps['APPS_GOODS_INCOME_RATIO'] = apps['AMT_GOODS_PRICE']/apps['AMT_INCOME_TOTAL']
apps['APPS_CNT_FAM_INCOME_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['CNT_FAM_MEMBERS']
# DAYS_BIRTH, DAYS_EMPLOYED 비율로 Feature 가공
apps['APPS_EMPLOYED_BIRTH_RATIO'] = apps['DAYS_EMPLOYED']/apps['DAYS_BIRTH']
apps['APPS_INCOME_EMPLOYED_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_EMPLOYED']
apps['APPS_INCOME_BIRTH_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_BIRTH']
apps['APPS_CAR_BIRTH_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_BIRTH']
apps['APPS_CAR_EMPLOYED_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_EMPLOYED']
return apps
def get_prev_processed(prev):
# 대출 신청 금액과 실제 대출액/대출 상품금액 차이 및 비율
prev['PREV_CREDIT_DIFF'] = prev['AMT_APPLICATION'] - prev['AMT_CREDIT']
prev['PREV_GOODS_DIFF'] = prev['AMT_APPLICATION'] - prev['AMT_GOODS_PRICE']
prev['PREV_CREDIT_APPL_RATIO'] = prev['AMT_CREDIT']/prev['AMT_APPLICATION']
# prev['PREV_ANNUITY_APPL_RATIO'] = prev['AMT_ANNUITY']/prev['AMT_APPLICATION']
prev['PREV_GOODS_APPL_RATIO'] = prev['AMT_GOODS_PRICE']/prev['AMT_APPLICATION']
prev['DAYS_FIRST_DRAWING'].replace(365243, np.nan, inplace= True)
prev['DAYS_FIRST_DUE'].replace(365243, np.nan, inplace= True)
prev['DAYS_LAST_DUE_1ST_VERSION'].replace(365243, np.nan, inplace= True)
prev['DAYS_LAST_DUE'].replace(365243, np.nan, inplace= True)
prev['DAYS_TERMINATION'].replace(365243, np.nan, inplace= True)
# 첫번째 만기일과 마지막 만기일까지의 기간
prev['PREV_DAYS_LAST_DUE_DIFF'] = prev['DAYS_LAST_DUE_1ST_VERSION'] - prev['DAYS_LAST_DUE']
# 매월 납부 금액과 납부 횟수 곱해서 전체 납부 금액 구함.
all_pay = prev['AMT_ANNUITY'] * prev['CNT_PAYMENT']
# 전체 납부 금액 대비 AMT_CREDIT 비율을 구하고 여기에 다시 납부횟수로 나누어서 이자율 계산.
prev['PREV_INTERESTS_RATE'] = (all_pay/prev['AMT_CREDIT'] - 1)/prev['CNT_PAYMENT']
return prev
def get_prev_amt_agg(prev):
# 새롭게 생성된 대출 신청액 대비 다른 금액 차이 및 비율로 aggregation 수행.
agg_dict = {
# 기존 컬럼 aggregation.
'SK_ID_CURR':['count'],
'AMT_CREDIT':['mean', 'max', 'sum'],
'AMT_ANNUITY':['mean', 'max', 'sum'],
'AMT_APPLICATION':['mean', 'max', 'sum'],
'AMT_DOWN_PAYMENT':['mean', 'max', 'sum'],
'AMT_GOODS_PRICE':['mean', 'max', 'sum'],
'RATE_DOWN_PAYMENT': ['min', 'max', 'mean'],
'DAYS_DECISION': ['min', 'max', 'mean'],
'CNT_PAYMENT': ['mean', 'sum'],
# 가공 컬럼 aggregation
'PREV_CREDIT_DIFF':['mean', 'max', 'sum'],
'PREV_CREDIT_APPL_RATIO':['mean', 'max'],
'PREV_GOODS_DIFF':['mean', 'max', 'sum'],
'PREV_GOODS_APPL_RATIO':['mean', 'max'],
'PREV_DAYS_LAST_DUE_DIFF':['mean', 'max', 'sum'],
'PREV_INTERESTS_RATE':['mean', 'max']
}
prev_group = prev.groupby('SK_ID_CURR')
prev_amt_agg = prev_group.agg(agg_dict)
# multi index 컬럼을 '_'로 연결하여 컬럼명 변경
prev_amt_agg.columns = ["PREV_"+ "_".join(x).upper() for x in prev_amt_agg.columns.ravel()]
return prev_amt_agg
def get_prev_refused_appr_agg(prev):
# 원래 groupby 컬럼 + 세부 기준 컬럼으로 groupby 수행. 세분화된 레벨로 aggregation 수행 한 뒤에 unstack()으로 컬럼레벨로 변형.
prev_refused_appr_group = prev[prev['NAME_CONTRACT_STATUS'].isin(['Approved', 'Refused'])].groupby([ 'SK_ID_CURR', 'NAME_CONTRACT_STATUS'])
prev_refused_appr_agg = prev_refused_appr_group['SK_ID_CURR'].count().unstack()
# 컬럼명 변경.
prev_refused_appr_agg.columns = ['PREV_APPROVED_COUNT', 'PREV_REFUSED_COUNT' ]
# NaN값은 모두 0으로 변경.
prev_refused_appr_agg = prev_refused_appr_agg.fillna(0)
return prev_refused_appr_agg
def get_prev_agg(prev):
prev = get_prev_processed(prev)
prev_amt_agg = get_prev_amt_agg(prev)
prev_refused_appr_agg = get_prev_refused_appr_agg(prev)
# prev_amt_agg와 조인.
prev_agg = prev_amt_agg.merge(prev_refused_appr_agg, on='SK_ID_CURR', how='left')
# SK_ID_CURR별 과거 대출건수 대비 APPROVED_COUNT 및 REFUSED_COUNT 비율 생성.
prev_agg['PREV_REFUSED_RATIO'] = prev_agg['PREV_REFUSED_COUNT']/prev_agg['PREV_SK_ID_CURR_COUNT']
prev_agg['PREV_APPROVED_RATIO'] = prev_agg['PREV_APPROVED_COUNT']/prev_agg['PREV_SK_ID_CURR_COUNT']
# 'PREV_REFUSED_COUNT', 'PREV_APPROVED_COUNT' 컬럼 drop
prev_agg = prev_agg.drop(['PREV_REFUSED_COUNT', 'PREV_APPROVED_COUNT'], axis=1)
return prev_agg
# bureau 채무 완료 날짜 및 대출 금액 대비 채무 금액 관련 컬럼 가공.
def get_bureau_processed(bureau):
# 예정 채무 시작 및 완료일과 실제 채무 완료일간의 차이 및 날짜 비율 가공.
bureau['BUREAU_ENDDATE_FACT_DIFF'] = bureau['DAYS_CREDIT_ENDDATE'] - bureau['DAYS_ENDDATE_FACT']
bureau['BUREAU_CREDIT_FACT_DIFF'] = bureau['DAYS_CREDIT'] - bureau['DAYS_ENDDATE_FACT']
bureau['BUREAU_CREDIT_ENDDATE_DIFF'] = bureau['DAYS_CREDIT'] - bureau['DAYS_CREDIT_ENDDATE']
# 채무 금액 대비/대출 금액 비율 및 차이 가공
bureau['BUREAU_CREDIT_DEBT_RATIO']=bureau['AMT_CREDIT_SUM_DEBT']/bureau['AMT_CREDIT_SUM']
#bureau['BUREAU_CREDIT_DEBT_DIFF'] = bureau['AMT_CREDIT_SUM'] - bureau['AMT_CREDIT_SUM_DEBT']
bureau['BUREAU_CREDIT_DEBT_DIFF'] = bureau['AMT_CREDIT_SUM_DEBT'] - bureau['AMT_CREDIT_SUM']
# 연체 여부 및 120일 이상 연체 여부 가공
bureau['BUREAU_IS_DPD'] = bureau['CREDIT_DAY_OVERDUE'].apply(lambda x: 1 if x > 0 else 0)
bureau['BUREAU_IS_DPD_OVER120'] = bureau['CREDIT_DAY_OVERDUE'].apply(lambda x: 1 if x >120 else 0)
return bureau
# bureau 주요 컬럼 및 앞에서 채무 및 대출금액 관련 컬럼들로 SK_ID_CURR 레벨의 aggregation 컬럼 생성.
def get_bureau_day_amt_agg(bureau):
bureau_agg_dict = {
'SK_ID_BUREAU':['count'],
'DAYS_CREDIT':['min', 'max', 'mean'],
'CREDIT_DAY_OVERDUE':['min', 'max', 'mean'],
'DAYS_CREDIT_ENDDATE':['min', 'max', 'mean'],
'DAYS_ENDDATE_FACT':['min', 'max', 'mean'],
'AMT_CREDIT_MAX_OVERDUE': ['max', 'mean'],
'AMT_CREDIT_SUM': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_DEBT': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_OVERDUE': ['max', 'mean', 'sum'],
'AMT_ANNUITY': ['max', 'mean', 'sum'],
# 추가 가공 컬럼
'BUREAU_ENDDATE_FACT_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_FACT_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_ENDDATE_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_DEBT_RATIO':['min', 'max', 'mean'],
'BUREAU_CREDIT_DEBT_DIFF':['min', 'max', 'mean'],
'BUREAU_IS_DPD':['mean', 'sum'],
'BUREAU_IS_DPD_OVER120':['mean', 'sum']
}
bureau_grp = bureau.groupby('SK_ID_CURR')
bureau_day_amt_agg = bureau_grp.agg(bureau_agg_dict)
bureau_day_amt_agg.columns = ['BUREAU_'+('_').join(column).upper() for column in bureau_day_amt_agg.columns.ravel()]
# 조인을 위해 SK_ID_CURR을 reset_index()로 컬럼화
bureau_day_amt_agg = bureau_day_amt_agg.reset_index()
#print('bureau_day_amt_agg shape:', bureau_day_amt_agg.shape)
return bureau_day_amt_agg
# Bureau의 CREDIT_ACTIVE='Active' 인 데이터만 filtering 후 주요 컬럼 및 앞에서 채무 및 대출금액 관련 컬럼들로 SK_ID_CURR 레벨의 aggregation 컬럼 생성
def get_bureau_active_agg(bureau):
# CREDIT_ACTIVE='Active' 인 데이터만 filtering
cond_active = bureau['CREDIT_ACTIVE'] == 'Active'
bureau_active_grp = bureau[cond_active].groupby(['SK_ID_CURR'])
bureau_agg_dict = {
'SK_ID_BUREAU':['count'],
'DAYS_CREDIT':['min', 'max', 'mean'],
'CREDIT_DAY_OVERDUE':['min', 'max', 'mean'],
'DAYS_CREDIT_ENDDATE':['min', 'max', 'mean'],
'DAYS_ENDDATE_FACT':['min', 'max', 'mean'],
'AMT_CREDIT_MAX_OVERDUE': ['max', 'mean'],
'AMT_CREDIT_SUM': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_DEBT': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_OVERDUE': ['max', 'mean', 'sum'],
'AMT_ANNUITY': ['max', 'mean', 'sum'],
# 추가 가공 컬럼
'BUREAU_ENDDATE_FACT_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_FACT_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_ENDDATE_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_DEBT_RATIO':['min', 'max', 'mean'],
'BUREAU_CREDIT_DEBT_DIFF':['min', 'max', 'mean'],
'BUREAU_IS_DPD':['mean', 'sum'],
'BUREAU_IS_DPD_OVER120':['mean', 'sum']
}
bureau_active_agg = bureau_active_grp.agg(bureau_agg_dict)
bureau_active_agg.columns = ['BUREAU_ACT_'+('_').join(column).upper() for column in bureau_active_agg.columns.ravel()]
# 조인을 위해 SK_ID_CURR을 reset_index()로 컬럼화
bureau_active_agg = bureau_active_agg.reset_index()
#print('bureau_active_agg shape:', bureau_active_agg.shape)
return bureau_active_agg
# bureau_bal을 SK_ID_CURR 레벨로 건수와 MONTHS_BALANCE의 aggregation 가공
def get_bureau_bal_agg(bureau, bureau_bal):
# SK_ID_CURR레벨로 Group by하기 위해 bureau에서 SK_ID_CURR 컬럼을 가져오는 조인 수행.
bureau_bal = bureau_bal.merge(bureau[['SK_ID_CURR', 'SK_ID_BUREAU']], on='SK_ID_BUREAU', how='left')
# STATUS에 따라 월별 연체 여부 및 120일 이상 연체 여부 속성 가공.
bureau_bal['BUREAU_BAL_IS_DPD'] = bureau_bal['STATUS'].apply(lambda x: 1 if x in['1','2','3','4','5'] else 0)
bureau_bal['BUREAU_BAL_IS_DPD_OVER120'] = bureau_bal['STATUS'].apply(lambda x: 1 if x =='5' else 0)
bureau_bal_grp = bureau_bal.groupby('SK_ID_CURR')
# SK_ID_CURR 레벨로 건수와 MONTHS_BALANCE의 aggregation 가공
bureau_bal_agg_dict = {
'SK_ID_CURR':['count'],
'MONTHS_BALANCE':['min', 'max', 'mean'],
'BUREAU_BAL_IS_DPD':['mean', 'sum'],
'BUREAU_BAL_IS_DPD_OVER120':['mean', 'sum']
}
bureau_bal_agg = bureau_bal_grp.agg(bureau_bal_agg_dict)
bureau_bal_agg.columns = [ 'BUREAU_BAL_'+('_').join(column).upper() for column in bureau_bal_agg.columns.ravel() ]
# 조인을 위해 SK_ID_CURR을 reset_index()로 컬럼화
bureau_bal_agg = bureau_bal_agg.reset_index()
#print('bureau_bal_agg shape:', bureau_bal_agg.shape)
return bureau_bal_agg
# 가공된 bureau관련 aggregation 컬럼들을 모두 결합
def get_bureau_agg(bureau, bureau_bal):
bureau = get_bureau_processed(bureau)
bureau_day_amt_agg = get_bureau_day_amt_agg(bureau)
bureau_active_agg = get_bureau_active_agg(bureau)
bureau_bal_agg = get_bureau_bal_agg(bureau, bureau_bal)
# bureau_day_amt_agg와 bureau_active_agg 조인.
bureau_agg = bureau_day_amt_agg.merge(bureau_active_agg, on='SK_ID_CURR', how='left')
# STATUS가 ACTIVE IS_DPD RATIO관련 비율 재가공.
#bureau_agg['BUREAU_IS_DPD_RATIO'] = bureau_agg['BUREAU_BUREAU_IS_DPD_SUM']/bureau_agg['BUREAU_SK_ID_BUREAU_COUNT']
#bureau_agg['BUREAU_IS_DPD_OVER120_RATIO'] = bureau_agg['BUREAU_BUREAU_IS_DPD_OVER120_SUM']/bureau_agg['BUREAU_SK_ID_BUREAU_COUNT']
bureau_agg['BUREAU_ACT_IS_DPD_RATIO'] = bureau_agg['BUREAU_ACT_BUREAU_IS_DPD_SUM']/bureau_agg['BUREAU_SK_ID_BUREAU_COUNT']
bureau_agg['BUREAU_ACT_IS_DPD_OVER120_RATIO'] = bureau_agg['BUREAU_ACT_BUREAU_IS_DPD_OVER120_SUM']/bureau_agg['BUREAU_SK_ID_BUREAU_COUNT']
# bureau_agg와 bureau_bal_agg 조인.
bureau_agg = bureau_agg.merge(bureau_bal_agg, on='SK_ID_CURR', how='left')
#bureau_bal_agg['BUREAU_BAL_IS_DPD_RATIO'] = bureau_bal_agg['BUREAU_BAL_BUREAU_BAL_IS_DPD_SUM']/bureau_bal_agg['BUREAU_BAL_SK_ID_CURR_COUNT']
#bureau_bal_agg['BUREAU_BAL_IS_DPD_OVER120_RATIO'] = bureau_bal_agg['BUREAU_BAL_BUREAU_BAL_IS_DPD_OVER120_SUM']/bureau_bal_agg['BUREAU_BAL_SK_ID_CURR_COUNT']
#print('bureau_agg shape:', bureau_agg.shape)
return bureau_agg
def get_apps_all_with_prev_agg(apps, prev):
apps_all = get_apps_processed(apps)
prev_agg = get_prev_agg(prev)
print('prev_agg shape:', prev_agg.shape)
print('apps_all before merge shape:', apps_all.shape)
apps_all = apps_all.merge(prev_agg, on='SK_ID_CURR', how='left')
print('apps_all after merge with prev_agg shape:', apps_all.shape)
return apps_all
def get_apps_all_encoded(apps_all):
object_columns = apps_all.dtypes[apps_all.dtypes == 'object'].index.tolist()
for column in object_columns:
apps_all[column] = pd.factorize(apps_all[column])[0]
return apps_all
def get_apps_all_train_test(apps_all):
apps_all_train = apps_all[~apps_all['TARGET'].isnull()]
apps_all_test = apps_all[apps_all['TARGET'].isnull()]
apps_all_test = apps_all_test.drop('TARGET', axis=1)
return apps_all_train, apps_all_test
def train_apps_all(apps_all_train):
ftr_app = apps_all_train.drop(['SK_ID_CURR', 'TARGET'], axis=1)
target_app = apps_all_train['TARGET']
train_x, valid_x, train_y, valid_y = train_test_split(ftr_app, target_app, test_size=0.3, random_state=2020)
print('train shape:', train_x.shape, 'valid shape:', valid_x.shape)
clf = LGBMClassifier(
nthread=4,
n_estimators=2000,
learning_rate=0.02,
max_depth = 11,
num_leaves=58,
colsample_bytree=0.613,
subsample=0.708,
max_bin=407,
reg_alpha=3.564,
reg_lambda=4.930,
min_child_weight= 6,
min_child_samples=165,
silent=-1,
verbose=-1,
)
clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)], eval_metric= 'auc', verbose= 100,
early_stopping_rounds= 200)
return clf모든 데이터 세트 조인 결합
# apps와 prev_agg, bureau_agg, pos_bal_agg, install_agg, card_bal_agg를 개별 함수 호출하여 생성후 조인 결합
def get_apps_all_with_all_agg(apps, prev, bureau, bureau_bal, pos_bal, install, card_bal):
apps_all = get_apps_processed(apps)
prev_agg = get_prev_agg(prev)
bureau_agg = get_bureau_agg(bureau, bureau_bal)
pos_bal_agg = get_pos_bal_agg(pos_bal)
install_agg = get_install_agg(install)
card_bal_agg = get_card_bal_agg(card_bal)
print('prev_agg shape:', prev_agg.shape, 'bureau_agg shape:', bureau_agg.shape )
print('pos_bal_agg shape:', pos_bal_agg.shape, 'install_agg shape:', install_agg.shape, 'card_bal_agg shape:', card_bal_agg.shape)
print('apps_all before merge shape:', apps_all.shape)
# 생성된 prev_agg, bureau_agg, pos_bal_agg, install_agg, card_bal_agg를 apps와 조인하여 최종 학습/테스트 집합 생성.
apps_all = apps_all.merge(prev_agg, on='SK_ID_CURR', how='left')
apps_all = apps_all.merge(bureau_agg, on='SK_ID_CURR', how='left')
apps_all = apps_all.merge(pos_bal_agg, on='SK_ID_CURR', how='left')
apps_all = apps_all.merge(install_agg, on='SK_ID_CURR', how='left')
apps_all = apps_all.merge(card_bal_agg, on='SK_ID_CURR', how='left')
print('apps_all after merge with all shape:', apps_all.shape)
return apps_all원본 데이터세트 재로딩
def get_dataset():
app_train = pd.read_csv('application_train.csv')
app_test = pd.read_csv('application_test.csv')
apps = pd.concat([app_train, app_test])
prev = pd.read_csv('previous_application.csv')
bureau = pd.read_csv('bureau.csv')
bureau_bal = pd.read_csv('bureau_balance.csv')
pos_bal, install, card_bal = get_balance_data()
return apps, prev, bureau, bureau_bal, pos_bal, install, card_bal
apps, prev, bureau, bureau_bal, pos_bal, install, card_bal = get_dataset()가공, 인코딩, 분리, 학습 수행
# application, previous, bureau, bureau_bal 관련 데이터셋 가공 및 취합.
apps_all = get_apps_all_with_all_agg(apps, prev, bureau, bureau_bal, pos_bal, install, card_bal)
# Category 컬럼을 모두 Label 인코딩 수행.
apps_all = get_apps_all_encoded(apps_all)
# 학습과 테스트 데이터로 분리.
apps_all_train, apps_all_test = get_apps_all_train_test(apps_all)
#학습수행.
clf = train_apps_all(apps_all_train)
preds = clf.predict_proba(apps_all_test.drop(['SK_ID_CURR'], axis=1))[:, 1 ]
apps_all_test['TARGET'] = preds
apps_all_test[['SK_ID_CURR', 'TARGET']].to_csv('pos_install_credit_01.csv', index=False)