01 서버와 클라이언트
웹의 동작원리를 간단히 알아보자.
서버: 서버란 서비스를 제공해주는 쪽을 뜻한다.
클라이언트: 클라이언트란 서비스를 요청하는 쪽을 뜻한다.
클라이언트는 우리가 사용하는 웹 브라우저를 포함한다. 예컨대 우리가 크롬에서 페이스북 사이트에 접속하는 상황을 상상해보자.
클라언트인 크롬에서 페이스북 URL 을 검색하면, 서버에 그 요청이 전송된다. 서버는 클라이언트가 페이지를 렌더링하기 위한 정보를 전달하는데, 이때 전달하는 것이 HTML, CSS, JS 의 코드가 될 것이다. 코드를 받은 웹 브라우저는 그것을 해석할 수 있으므로 웹 페이지에 그것을 보여줌으로서 우리가 접근할 수 있는 것이다.
02 필요한 라이브러리 설치하기
pycharm 에서 필요한 라이브러리 설치하는 두 가지 방법을 알아보자. 지금 설치해볼 것은 requests 라이브러리다.
✅ 1. termianl 로 설치하기
터미널 명령은 단순하다.
pip install reqeusts 다음과 같은 코드를 터미널에 쳐줬다. 나같은 경우는 pip version 자체가 맞지 않아서 한 줄의 코드를 더 써줘야 했다.
python -m pip instal --upgrade pip이후에 다시 인스털 명령을 수행하여 설치할 수 있었다. 삭제하고 싶으면 pip uninstall requests 명령을 수행하면 된다. 하나 중요한 것은 이렇게 파이참에서 설치된 라이브러리는 프로젝트 단위 라는 것이다. 다른 프로젝트를 생성하면 또다시 라이브러리를 따로 관리해야 하는데, 이는 프로젝트 간 버전 호환성 문제 때문에 그렇다고 한다.
✅ 2. pycharm 자체에서 설치하기
pycharm 에서 설치하는 방법도 있다. Windwow 의 경우, 왼쪽 상단 [File] > [Settings] 를 들어간다. 검색하는 도구에서 interpreter 를 검색하면 깔려져 있는 라이브러리 목록이 나온다.
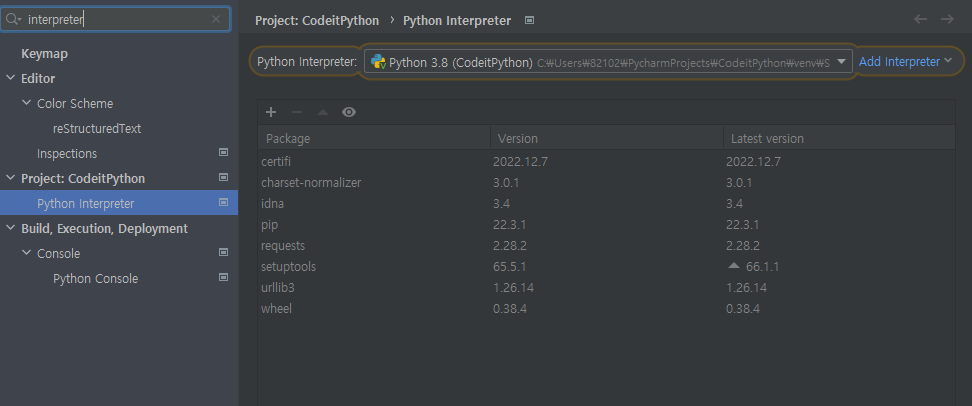
저기서 + 버튼을 누른다음, 원하는 라이브러리 이름을 검색한 후 설치를 누르면 된다.
03. 파이썬으로 요청 보내기
서버에 원하는 서비스를 제공받기 위해 요청을 보내는 것을 클라이언트라 해봤다.
requests 라이브러리는 파이썬 자체가 이러한 클라이언트가 되어 요청을 보내는 역할을 할 수 있게 하는 것이다. 코드를 보자.
import requests
response = requests.get("https://google.com")
print(response.text)(결과는 너무 길어 생략)
.get() 메서드 안에 요청을 보낼 URL 을 넣어서 결과를 변수에 저장했다. 변수.text 를 찍어주면 해당 URL을 렌더링할 수 있는 코드들을 확인할 수 있다. 클라이언트는 이 코드들을 받아 웹 브라우저를 통해 우리에게 보여주는 것이다. requests를 통해 파이썬으로 서버에 요청을 보내고, HTML 코드를 받아 저장해봤다.
04. TV 시청률 데이터 가져오기
import requests
# 여기에 코드를 작성하세요
rating_page = requests.get('https://workey.codeit.kr/ratings/index')
# 테스트 코드
print(rating_page.text)해당 URL 은 티비 시청률 데이터 목록을 가지고 있는 페이지인데, requests 라이브러리를 통해 HTML 코드를 가져올 수 있었다.
05. 웹 사이트 주소 이해하기
URL 주소를 정확히 파헤쳐보자.
https://www.apple.com/airpods-max/https : 서버와 통신하는 방식을 말한다. 주로 http, 조금 변형되어 https 를 사용한다.
www.apple.com : 도메인 주소를 말한다. 사이트의 이름이다.
airpods-max : 도메인 주소에서 더 들어가면 확인할 수 있는 경로의 이름이다.
다른 주소 하나를 더 보자.
walmart.com/search?q=cabbage역시나 도메인 주소 뒤에 경로가 있는데, ?q 는 무엇일까?
?q = cabbage : 쿼리의 약어로, 내가 cabbage 를 검색했기 때문에 뜨는 것이다. 이때 2페이지로 넘어가면 & ?page = 2 가 추가된다.
06. 여러 웹 사이트 한번에 가져오기
단순히 반복문을 이용해주면 된다! 다음은 티비 시청률 랭킹 페이지의 url 이다.
https://workey.codeit.kr/ratings/index?year=2010&month=1&weekIndex=02010년 1월의 주차에 따라 weekindex 가 달라지는 것인데, 0부터 4까지 5개를 불러오는 코드를 만들자.
import requests
ratings = []
for i in range(5):
url = "https://workey.codeit.kr/ratings/index?year=2010&month=1&weekIndex={}".format(i)
response = requests.get(url)
rating = response.text
ratings.append(rating)
print(len(ratings))
print(ratings[0])
raings 라는 리스트를 만들어 거기에 하나씩 넣어줬다. 최종적으로는 들어간 5개의 HTML 태그와, 첫번째 HTML 코드를 출력할 수 있었다.
07 TV 시청률 데이터 가져오기
2010-2012 년의 모든 달과 주에 대한 데이터를 받아오는 것이었는데, 단순히 반복문을 중첩으로 구성시키면 되었다.
import requests
# 여기에 코드를 작성하세요
rating_pages = []
for i in range(3):
for j in range(12):
for k in range(5):
url = 'https://workey.codeit.kr/ratings/index?year=201{}&month={}&weekIndex={}'.format(i,j+1,k)
response = requests.get(url)
rating_pages.append(response.text)
# 테스트 코드
print(len(rating_pages)) # 가져온 총 페이지 수
print(rating_pages[0]) # 첫 번째 페이지의 HTML 코드