
01 웹 자동화
- 웹 스크래핑
- 실시간 검색어 수집
- 자동 메일 발송
- 자동 블로그 포스팅
02 하이퍼텍스트
하이퍼텍스트(HyperText) 는 텍스트 너머 무언가를 의미한다.
과거에 활자가 종이로 인쇄된 형태로만 정보가 존재했을 떄는 책을 읽다가 모르는 내용이 나오면 일일이 다른 책을 다 찾아보아야 했다.
그러나 웹(Web) 에서는 그렇지 않다. 간단히 하이퍼링크(HyperLink) 를 걸어주어 하나의 텍스트에서 다른 텍스트로 건너갈 수 있게 만들어 놓았다. 이것은 웹에서만 가능한 웹의 중요하면서 효율적인 특징이다.
03 하이퍼텍스트 구현
04 하이퍼텍스트 구현 실습
하이퍼텍스트 구현은 어렵지 않다. 일단 코드는 다음과 같다.
하이퍼텍스트를 걸어주고 싶은 코드 앞과 뒤에
a 태그를 달아준다.
<a href = '연결할 문서주소'> 링크를 만들 텍스트 </a>본래 문서는 romeo.html , 연결할 문서는 william.html 이다.
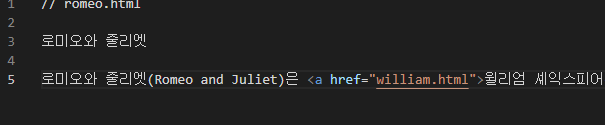
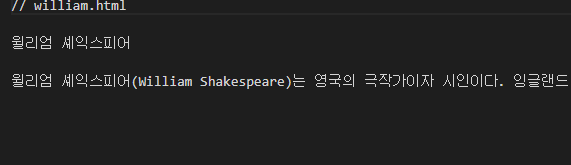
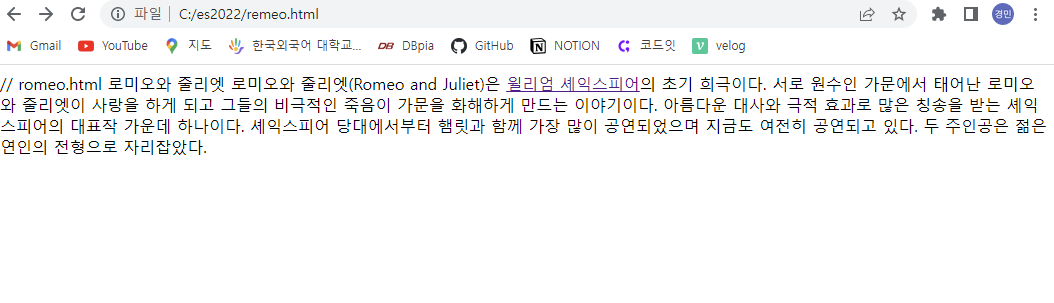
다음과 같이 셰익스피어 텍스트에 하이퍼링크가 걸려있는 것을 확인할 수 있다.
05 웹의 확장
웹의 확장은 어떻게 이뤄졌을까? 어떻게 많은 정보들이 하나로 묶일 수 있었던 것일까?
URL : 흔히 웹의 주소라고 불리는 이것은 우리가 단순히 <a href> </a> 사이에 다른 사람의 주소 를 넣으면서 확장되기 시작하였다.
검색엔진 : 문제는 다른 사람의 주소도 존재함에도, 어디서 그것을 검색할지 하는 것이었는데 알고리즘과 추천 등 검색 엔진이 발달됨에 따라 모든 URL 을 그 검색엔진에다 모아둠으로서 그것이 가능케 되었다.
웹 크롤링: 연결된 URL 들을 검색엔진에다 때려 넣는 것이다. 이때 URL 과 키워드들을 매칭하는 역할도 하는데, 매칭된 키워드가 검색되면 해당 URL 을 반환하는 것이다. 좋은 추천 알고리즘을 지닌 구글이나 네이버가 많은 검색엔진에서 살아남을 수 있었다.
06 웹 크롤링 VS 웹 스크래핑

웹 스크래핑은 검색엔진을 통해 검색된 URL 의 많은 것들(웹 사이트, 블로그, 등등) 을 돌아다니며 필요한 정보를 수집하는 것을 이야기한다. 가끔 웹 크롤링과 혼동하곤 하는데, 정리하면 다음과 같다.
웹 크롤링 : 검색엔진 사이드에서 엔진이 URL 을 돌아다니며 키워드 들을 수집하는 것. 검색엔진이 웹사이트를 인덱싱 하는 것.
웹 스크래핑 : 사용자 사이트에서 웹사이트에서 필요한 데이터를 수집하는 것.
07 웹의 발전
HTML: 기본적인 텍스트 문서를 렌더링
CSS : HTML에 스타일을 입힘
JavaScript: 실제로 사용자에 맞게 구현. 동작
웹 브라우저: 사용자에게 렌더링, 북마크, 개발자 도구 등 다양한 기능 지원 요구.
