이제 다른 데이터를 다뤄보자. 이전에 대출 이력을 나타내는 prev_application 데이터 세트를 볼 것이다.
prev_application 데이터 세트 EDA 와 FEATURE Engineering 수행 후 학습 모델 생성/ 평가
라이브러리, 데이터 세트 로딩
import numpy as np
import pandas as pd
import gc
import time
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
pd.set_option('display.max_rows', 100)
pd.set_option('display.max_columns', 200)
import os, sys
from google.colab import drive
drive.mount('/content/gdrive')
%cd '/content/gdrive/My Drive/'
!ls
app_train = pd.read_csv('application_train.csv')
app_test = pd.read_csv('application_test.csv')
#app 으로 합치는 함수
def get_apps_dataset():
app_train = pd.read_csv('application_train.csv')
app_test = pd.read_csv('application_test.csv')
apps = pd.concat([app_train, app_test])
return apps
apps = get_apps_dataset()
#이전 feature engineering 함수 복사
def get_apps_processed(apps):
# EXT_SOURCE_X FEATURE 가공
apps['APPS_EXT_SOURCE_MEAN'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].mean(axis=1)
apps['APPS_EXT_SOURCE_STD'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].std(axis=1)
apps['APPS_EXT_SOURCE_STD'] = apps['APPS_EXT_SOURCE_STD'].fillna(apps['APPS_EXT_SOURCE_STD'].mean())
# AMT_CREDIT 비율로 Feature 가공
apps['APPS_ANNUITY_CREDIT_RATIO'] = apps['AMT_ANNUITY']/apps['AMT_CREDIT']
apps['APPS_GOODS_CREDIT_RATIO'] = apps['AMT_GOODS_PRICE']/apps['AMT_CREDIT']
# AMT_INCOME_TOTAL 비율로 Feature 가공
apps['APPS_ANNUITY_INCOME_RATIO'] = apps['AMT_ANNUITY']/apps['AMT_INCOME_TOTAL']
apps['APPS_CREDIT_INCOME_RATIO'] = apps['AMT_CREDIT']/apps['AMT_INCOME_TOTAL']
apps['APPS_GOODS_INCOME_RATIO'] = apps['AMT_GOODS_PRICE']/apps['AMT_INCOME_TOTAL']
apps['APPS_CNT_FAM_INCOME_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['CNT_FAM_MEMBERS']
# DAYS_BIRTH, DAYS_EMPLOYED 비율로 Feature 가공
apps['APPS_EMPLOYED_BIRTH_RATIO'] = apps['DAYS_EMPLOYED']/apps['DAYS_BIRTH']
apps['APPS_INCOME_EMPLOYED_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_EMPLOYED']
apps['APPS_INCOME_BIRTH_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_BIRTH']
apps['APPS_CAR_BIRTH_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_BIRTH']
apps['APPS_CAR_EMPLOYED_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_EMPLOYED']
return appsprevious 데이터 세트는 prev 에 넣고 다룰 것이다.
prev = pd.read_csv('previous_application.csv')
#누락 집합 확인.outer 조인 수행하면 both, rigth_only, left_only 로 구분됨.
prev_app_outer = prev.merge(apps['SK_ID_CURR'], on = 'SK_ID_CURR', how = 'outer', indicator = True)
prev_app_outer['_merge'].value_counts()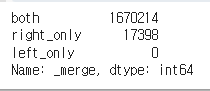
역시나 prev 는 이전 주문 이력들과 같으므로 'SK_ID_CURR' 에 관해서 M(prev) : 1(apps) 의 관계다.
주요 컬럼 EDA
SK_ID_CURR 당 평균 SK_ID_PREV 건수 구하기
groupby 를 이용하면 해당 칼럼에 대해 그룹을 지어주게 된다. 이를 prev에 있는 'SK_ID_CURR' 행에서만 관찰하면 한 사람이 과거에 몇 번의 대출을 했는지 확인할 수 있다.
#평균 내보자.
prev.groupby('SK_ID_CURR')['SK_ID_CURR'].count().mean()
#시각화
sns.boxplot(prev.groupby('SK_ID_CURR')['SK_ID_CURR'].count())
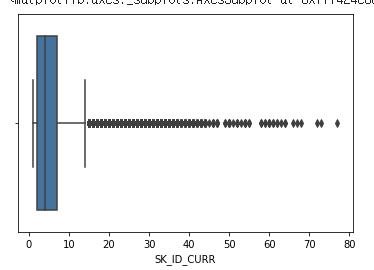
평균 4-5회 정도를 기록했으며, 박스 플롯은 다음과 같다.
숫자형 피처 TARGET 유형에 따라 비교
prev 프레임의 숫자형 피처들만을 뽑아 TARGET 0 과 1 에 유의미한 차이가 있는지 확인해보자. 이때 TARGET 유형은 prev 프레임에 없다. 따라서 SK_ID_CURR 에 맞춰서 TARGET 값을 가져오기 위해 병합을 해줘야한다.
app_prev =prev.merge(app_train[['SK_ID_CURR', 'TARGET']], on = 'SK_ID_CURR', how = 'left')
app_prev.shape
left 조인을 해줬으므로 기존 prev 에서 행의 숫자는 변하지 않았음을 확인할 수 있다. 이제 app_prev 에는 기존 prev 데이터에 SK_ID_CURR과 TARGET 정보가 포함되어있다.
#객체가 아닌 것은 모두 숫자값임. 숫자값을 가지는 행만 num_columns 에 넣는다.
num_columns = app_prev.dtypes[app_prev.dtypes != 'object'].index.tolist()
num_columns = [ column for column in num_columns if column not in ['SK_ID_PREV', 'SK_ID_CURR','TARGET']]
#시각화 함수. 이전에 썼던 것이다.
def show_hist_by_target(df, columns):
cond_1 = (df['TARGET'] == 1)
cond_0 = (df['TARGET'] == 0)
for column in columns:
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 4), squeeze=False)
sns.violinplot(x='TARGET', y=column, data=df, ax=axs[0][0] )
sns.distplot(df[cond_0][column], ax=axs[0][1], label='0', color='blue')
sns.distplot(df[cond_1][column], ax=axs[0][1], label='1', color='red')
#app_prev의 숫자형 컬럼만 시각화한다.
show_hist_by_target(app_prev, num_columns)이제 app_prev 의 숫자값을 가지는 행들만 뽑아 변수에 넣는다. (app_prev와 다르게 행 변수에는 SK_ID_PREV, CURR, TARGET 은 제외) 이를 시각화함수에 넣어준다. 시각화함수는 이전에 봤던 것으로, 서브플롯을 만들어준 다음 바이올린과 distplot 을 각각 보여주는 것이다. distplot 의 경우 df[불린값][각 행] 으로 2개를 띄운다.
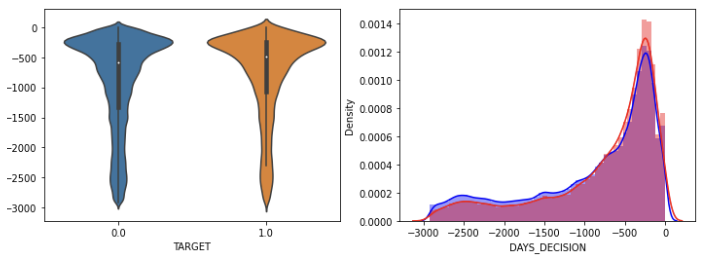
그래프 중 나머지 데이터는 조정이 필요해보였다. (특정 값이 찍힌 상태) 헌데 DAYS_DECISION 은 대출을 결정한 날짜를 뜻하는데, 오래 전보다 얼마 지나지 않았을 때 1.0 연체의 비율이 높은 것을 확인할 수 있었다.
Category 피처 Target 유형에 따라 비교
이번엔 dtypes 를 =='object' 그 자체로 줄 것이다. 그리고 나서 함수를 적용시킨 후 분석해보자.
#object 컬럼만 추출하여 리스트로 반환
object_columns = app_prev.dtypes[app_prev.dtypes=='object'].index.tolist()
#countplot 을 object 에 관해 수행하려면 catplot 을 쓰자.
def show_category_by_target(df, columns):
for column in columns:
chart = sns.catplot(x=column, col="TARGET", data=df, kind="count")
chart.set_xticklabels(rotation=65)
show_category_by_target(app_prev, object_columns)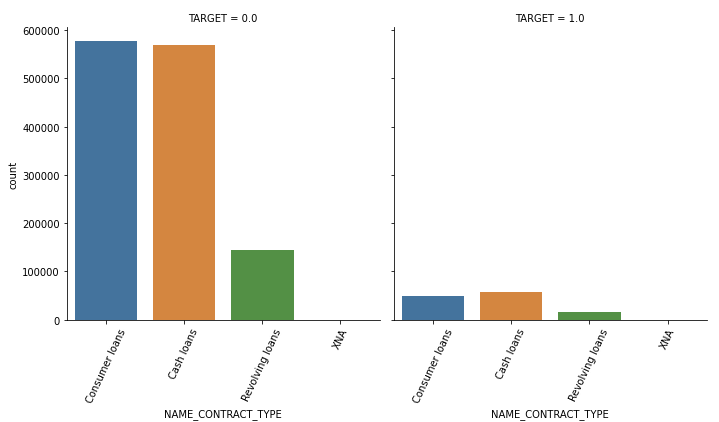
NAME_CONTRACT_TYPE 계약 방법의 경우 연체가 있는 곳에선 Consumer loans 보다 Cash가 더 많았다.
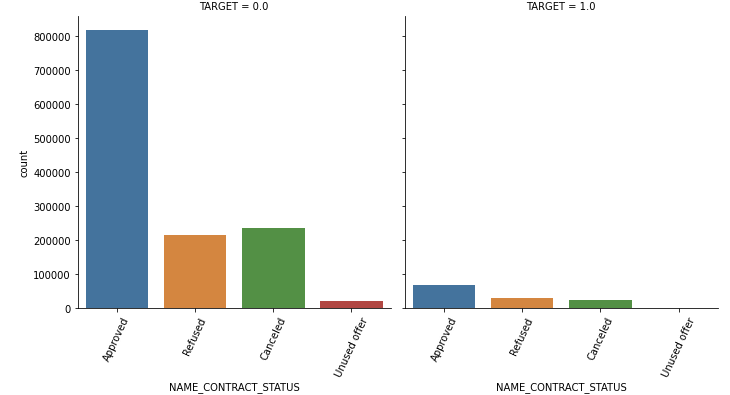
대출 허가 상태를 뜻하는 NAME_CONTRACT_STATUS 의 경우 refused 가 차지하는 비율이 많은 것은 1일 때였다.
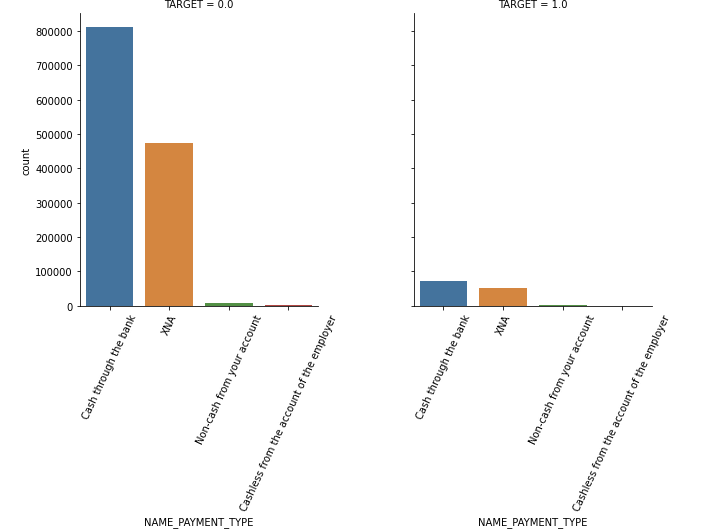
지불 방식인데 연체의 경우 XNA 가 차지하는 비중이 높았다.
feature engineering 수행
groupby 중간자를 만들어 agg 함수를 사용하는 것이다. 방법은 크게 세가지라고 배웠다.
- 중간자['컬럼명'].agg함수로 각각 할당
- 데이터프레임 = 중간자['컬럼명'].agg(['함수들']) 로 만든 데이터프레임들 병합
- 컬럼명 : 함수명 으로 된 딕셔너리를 만들어 agg()에 딕셔너리 넣기
세번째 방법의 코드만 기록할 것이다.
groupby 세번째 방법(유용)
중간자 변수 = 기존 데이터프레임.groupby('기준이 될 열 = 행이 될 열')
딕셔너리 = {'살피고 싶은 열' : ['함수1','함수2'..]
새로운 데이터프레임 = 중간자변수.agg(딕셔너리)
agg_dict = {
'SK_ID_CURR':['count'],
'AMT_CREDIT':['mean', 'max', 'sum'],
'AMT_ANNUITY':['mean', 'max', 'sum'],
'AMT_APPLICATION':['mean', 'max', 'sum'],
'AMT_DOWN_PAYMENT':['mean', 'max', 'sum'],
'AMT_GOODS_PRICE':['mean', 'max', 'sum']
}
prev_group = prev.groupby('SK_ID_CURR')
prev_amt_agg = prev_group.agg(agg_dict)
prev_amt_agg.head(10)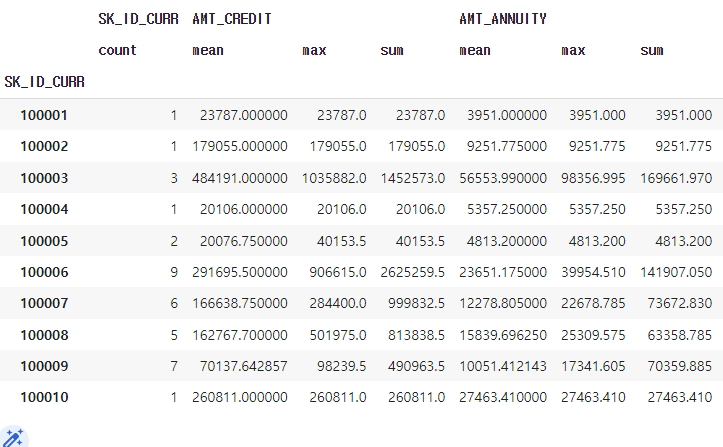
중간자를 만들고, 중간자.agg(딕셔너리) 를 넣어주면 SK_ID_CURR 가 한 행이 된 각각의 수치들이 나온다. 이렇게 만들면 상위, 하위 Multiindex 가 생겨 이를 변경시켜주는 것이 필요하다.
groupby 사용해 multiindex 된 컬럼명 바꾸기
컬럼명을 바꾸기 위해 일단 확인을 해줬다.
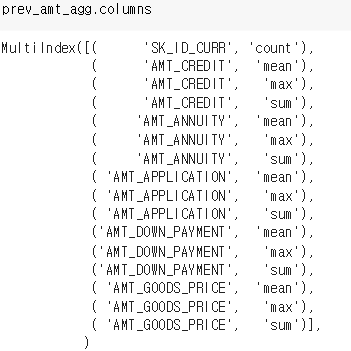
리스트 안에 튜플처럼 저렇게 할당되어 있었다. 이는 반복문들 돌며 joun 한 후 데이터프레임.columns 에 이름으로 할당하면 된다.
prev_amt_agg.columns = [ 'PREV_' + ('_').join(column).upper() for column in prev_amt_agg.columns.ravel()]요소를 _ 로 묶어 앞에 PREV 를 붙여줬다. 다음과 같이 멀티인덱스가 사라지고 정상적으로 된다.

대출 신청액 이용 피처 가공
prev['PREV_CREDIT_DIFF'] = prev['AMT_APPLICATION'] - prev['AMT_CREDIT'] #신청한 금액과 실제 대출 금액
prev['PREV_GOODS_DIFF'] = prev['AMT_APPLICATION'] - prev['AMT_GOODS_PRICE'] #신청한 금액과 상품 금액
prev['PREV_CREDIT_APPL_RATIO'] = prev['AMT_CREDIT']/prev['AMT_APPLICATION'] #신청한 금액 대비 대출 금액
prev['PREV_ANNUITY_APPL_RATIO'] = prev['AMT_ANNUITY']/prev['AMT_APPLICATION'] #신청 금액 대비 달 지불 금액
prev['PREV_GOODS_APPL_RATIO'] = prev['AMT_GOODS_PRICE']/prev['AMT_APPLICATION'] #신청 금액 대비 상품 금액 DAYS_XXX 피처 변환
DAYS_XXX 피처는 365243 이라고 하는 불필요 값이 너무 많아 이를 nan 으로 변환해줬다. 첫 번째 만기일과 마지막 만기일까지의 기간도 제공했다.
prev["DAYS_FIRST_DRAWING"].replace(365243, np.nan, inplace = True)
prev['DAYS_FIRST_DUE'].replace(365243, np.nan, inplace= True)
prev['DAYS_LAST_DUE_1ST_VERSION'].replace(365243, np.nan, inplace= True)
prev['DAYS_LAST_DUE'].replace(365243, np.nan, inplace= True)
prev['DAYS_TERMINATION'].replace(365243, np.nan, inplace= True)
# 첫번째 만기일과 마지막 만기일까지의 기간
prev['PREV_DAYS_LAST_DUE_DIFF'] = prev['DAYS_LAST_DUE_1ST_VERSION'] - prev['DAYS_LAST_DUE']이자율 관련 칼럼 문제로 새롭게 계산
이자율 관련 칼럼이 nan이 너무 많았다. 따라서 이자율을 다음과 같이 계산했다.
(실제 지불 금액 / 대출 금액 - 1) / 지불 달 수
실제 지불한 금액을 대출 금액으로 나누면 이자율이 관련이 된다는 것을 느낄것이다. 이자율 자체는 0.XXX 로 표기되므로 -1 을 해주고, 월 이자율을 계산하기 때문에 이를 월 수로 나눈다.
all_pay = prev["AMT_ANNUITY"] * prev["CNT_PAYMENT"] #월별 지불 금액 * 지불해야 하는 달 수
prev['PREV_INTEREST_RATE'] = (all_pay/prev["AMT_CREDIT"]-1)/ prev["CNT_PAYMENT"] #실제 총 지불 금액 / 예정 지불 금액 - 1 / 지불 달 수 새로운 칼럼들로 agg 수행
agg_dict = {
# 기존 컬럼.
'SK_ID_CURR':['count'],
'AMT_CREDIT':['mean', 'max', 'sum'],
'AMT_ANNUITY':['mean', 'max', 'sum'],
'AMT_APPLICATION':['mean', 'max', 'sum'],
'AMT_DOWN_PAYMENT':['mean', 'max', 'sum'],
'AMT_GOODS_PRICE':['mean', 'max', 'sum'],
'RATE_DOWN_PAYMENT': ['min', 'max', 'mean'],
'DAYS_DECISION': ['min', 'max', 'mean'],
'CNT_PAYMENT': ['mean', 'sum'],
# 가공 컬럼
'PREV_CREDIT_DIFF':['mean', 'max', 'sum'],
'PREV_CREDIT_APPL_RATIO':['mean', 'max'],
'PREV_GOODS_DIFF':['mean', 'max', 'sum'],
'PREV_GOODS_APPL_RATIO':['mean', 'max'],
'PREV_DAYS_LAST_DUE_DIFF':['mean', 'max', 'sum'],
'PREV_INTERESTS_RATE':['mean', 'max']
}
prev_group = prev.groupby('SK_ID_CURR')
prev_amt_agg = prev_group.agg(agg_dict)
prev_amt_agg = [ 'PREV_' + ('_').join(column).upper() for column in prev_amt_agg.columns.ravel()]
SK_ID_CURR 별로 NAME_CONTRACT_STATUS가 Refused 일 경우의 건수 및 과거 대출건 대비 비율
prev 데이터프레임 (과거 대출 자료) 에서 NAME_CONTRACT_STATUS 에는 다음과 같은 정보가 포함되어 있다.
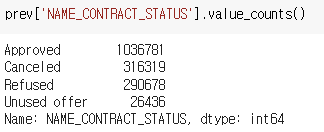
현재 궁금한 것은 Refused 일 경우를 활용한 정보이다.
groupby 적용된 데이터프레임과 filtering 된 데이터프레임을 조인하여 생성할 것이다
Refused 기준으로 필터링하고 필터링 된 데이터프레임에 groupby 적용할 것이다
기존 prev_amt_agg 와 조인할 것이다
이때 오류 방지를 위해 reset_index 를 사용할 것이다
먼저 NAME_CONTRACT_STATUS 가 Refused 인 필터링 데이터프레임 prev_refused 를 만들어보자.
cond_refused = (prev["NAME_CONTRACT_STATUS"] == 'Refused')
prev_refused = prev[cond_refused]
prev_refused.shape, prev.shape
그다음 prev_refused 에 groupby 를 적용해 중간자를 만들고, 중간자에서 SK_ID_CURR 에 따라 카운트 한 Series 를 갖는 prev_refused_agg 를 만들어보자.
#그룹 바이 중간자 만들기, 그 중에서도 SK_ID_CURR 에 따른 count 만 잡아낸 시리즈.
prev_refused_agg = prev_refused.groupby('SK_ID_CURR')['SK_ID_CURR'].count()
prev_refused_agg.shape, prev_amt_agg.shape #이 둘을 이제 결합할 것이다.

🤔 결합 문제 해결 부분
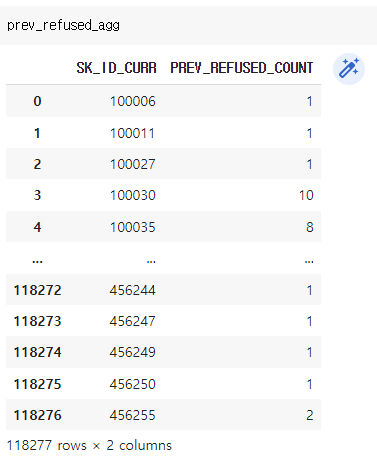
이제 둘을 결합할 것인데, 문제가 있다. prev_refused_agg 는 현재 아이디와 거절 횟수만 담긴 시리즈이다. (시리즈와 데이터프레임을 조인하는 게 불가능한 것은 아니나 조인 시 시리즈를 데이터프레임으로 만들려 할 때 자동으로 reset_index 를 시도한다) 이때 둘을 조인 시도하면 시리즈에 현재 SK_ID_CURR 컬럼이 두개가 되므로 오류가 난다. 아래 사진을 보자.
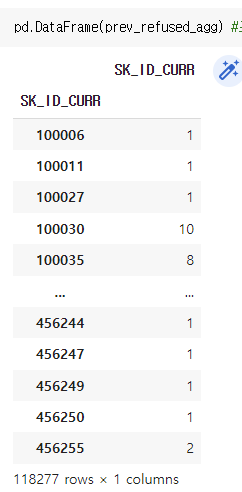
따라서 우리는 prev_refused_agg (아이디 - 거절 카운트) 를 리셋 인덱스 해주고, 이름을 바꿔줘야 한다.
prev_refused_agg = prev_refused_agg.reset_index(name = 'PREV_REFUSED_COUNT') #따라서 reset_index 를 활용한다. 이름은 PREV_REFUSED_COUNT 로 바꿔주었다.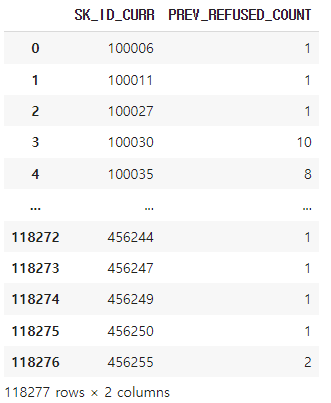
이제 prev_refused_agg 는 아이디와 (거절 당한 사람들만) 거절 카운트가 담긴 데이터프레임이 되었다.
이제 병합하는 코드를 보자.
prev_amt_agg = prev_amt_agg.reset_index() #33만건 대 프레임
#prev_refused_agg 는 그 중 거절된 횟수 정보보, 대프레임과 거절된 것을 조인. 따라서 NaN 값은 거절이 아닌 사람들임.
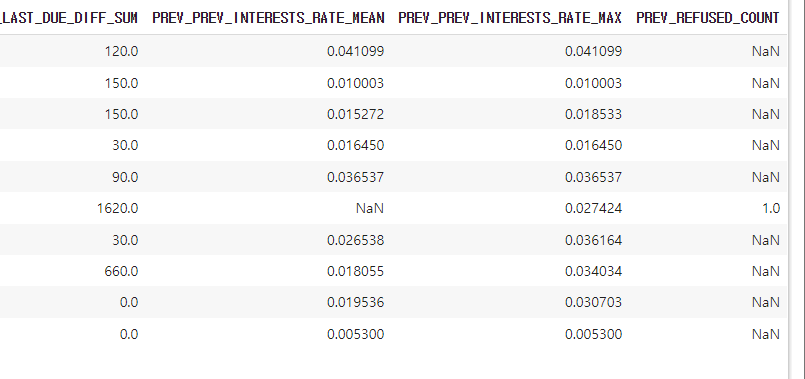
prev_amt_refused_agg = prev_amt_agg.merge(prev_refused_agg, on = 'SK_ID_CURR', how = 'left')
prev_amt_refused_agg.head(10)prev_amt_agg 이전 전체 대출 정보 프레임과 prev_refused_agg 거절된 사람 중 거절횟수를 센 프레임을 병합하려 한다. 오류 방지를 위해 prev_amt_agg 도 reset_index 를 해줬다. 그리고 left 조인을 해줬다. 따라서 당연히 거절되지 않은 사람들은 붙은 칸에 (prev_refused_count) NaN이 생긴다. 거절되지 않았기 때문이다.
거절되지 않음은 0으로 채워넣고 이전 대출 횟수를 거절 횟수로 나눠 거절 비율 구하기
따라서 이들을 0으로 채워넣어준다. 그리고 거절 비율을 PREV_REFUSED_RATIO 행으로 추가할 것이다. 최종 병합한 prev_amt_refused에는 PREV_SK_ID_CURR_COUNT 라는 이전 대출 횟수와 방금 추가한 PREV_REFUSED_COUNT 가 있다. 이를 나눠 비율을 구하자.
prev_amt_refused_agg = prev_amt_refused_agg.fillna(0)
prev_amt_refused_agg['PREV_REFUSED_RATIO'] = prev_amt_refused_agg['PREV_REFUSED_COUNT'] / prev_amt_refused_agg['PREV_SK_ID_CURR_COUNT']
prev_amt_refused_agg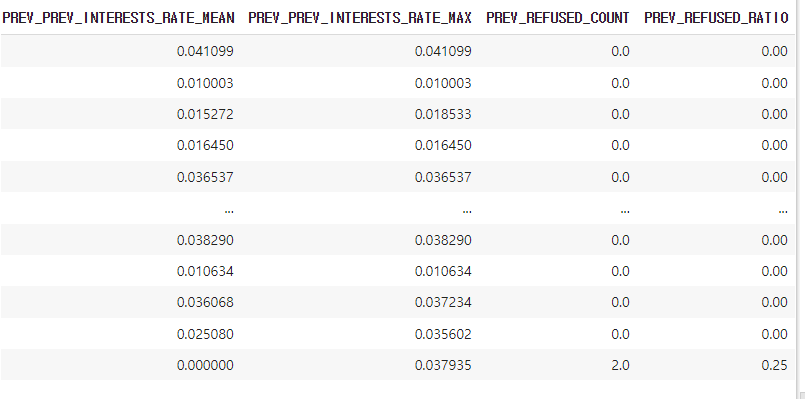
세부 조건이 2개 이상일 때 Group by Case when 구현
세부 조건이 2개 이상일 때는 어떻게 간단히 구현할 수 있을까? 아까 전과는 달리 좀 더 간단하게 해보자. 이때는 groupby 와 unstack() 을 이용한다.
# 원래 groupby 컬럼 + 세부 기준 컬럼으로 groupby 수행. 세분화된 레벨로 aggregation 수행 한 뒤에 unstack()으로 컬럼레벨로 변형.
prev_refused_appr_group = prev[prev['NAME_CONTRACT_STATUS'].isin(['Approved', 'Refused'])].groupby([ 'SK_ID_CURR', 'NAME_CONTRACT_STATUS'])
prev_refused_appr_agg = prev_refused_appr_group['SK_ID_CURR'].count().unstack()
prev_refused_appr_agg.head(30)count()와 count().unstack() 은 분명히 다르다. unstack() 을 사용하면 Approved와 Refused 가 분리된 컬럼으로 각각 count 을 해준다.
# 컬럼명 변경.
prev_refused_appr_agg.columns = ['PREV_APPROVED_COUNT', 'PREV_REFUSED_COUNT' ]
# NaN값은 모두 0으로 변경.
prev_refused_appr_agg = prev_refused_appr_agg.fillna(0)이제 이름을 제대로 변경해주고 NaN 값은 0 으로 바꿔주자.
prev_refused_appr_agg 에는 승인과 거절 횟수가 담겨있다.
# prev_amt_agg와 조인. prev_amt_agg와 prev_refused_appr_agg 모두 SK_ID_CURR을 INDEX로 가지고 있음.
prev_agg = prev_amt_agg.merge(prev_refused_appr_agg, on='SK_ID_CURR', how='left')
# SK_ID_CURR별 과거 대출건수 대비 APPROVED_COUNT 및 REFUSED_COUNT 비율 생성.
prev_agg['PREV_REFUSED_RATIO'] = prev_agg['PREV_REFUSED_COUNT']/prev_agg['PREV_SK_ID_CURR_COUNT']
prev_agg['PREV_APPROVED_RATIO'] = prev_agg['PREV_APPROVED_COUNT']/prev_agg['PREV_SK_ID_CURR_COUNT']
# 'PREV_REFUSED_COUNT', 'PREV_APPROVED_COUNT' 컬럼 drop
prev_agg = prev_agg.drop(['PREV_REFUSED_COUNT', 'PREV_APPROVED_COUNT'], axis=1)
# prev_amt_agg와 prev_refused_appr_agg INDEX인 SK_ID_CURR이 조인 후 정식 컬럼으로 생성됨.
prev_agg.head(30)이를 기존 agg 데이터프레임과 합쳐주자. left 조인을 수행한다. 또한 과거 대출 건수 대비 거절 횟수, 대출 건수 대비 승인 횟수 비율 컬럼도 추가한다. 그리고 나서 과거 거절 횟수와 승인 횟수는 삭제한다. (비율 정보만을 남겨두고) 이제 prev_agg 에 aggregation 정보 + 승인, 거절 비율 정보도 추가되었다.
가공된 최종 데이터 세트 생성
이전 application 데이터 세트와 previous 데이터 세트를 조인할 것이다. application 데이터 세트의 feature engineering 함수를 쓰고, 결합까지 하는 코드이다.
apps_all = get_apps_processed(apps) # apps 를 피 엔 후 결과가 apps_all
apps_all = apps_all.merge(prev_agg, on='SK_ID_CURR', how='left') #현재 대출, 과거 대출 정보 최종 결합.이제 apps_all 은 현재 대출과 과거 대출의 정보가 최종 결합된 데이터 프레임이다.
데이터 레이블 인코딩
object 인 컬럼만 뽑아내어 레이블 인코딩을 수행해준다. factorize(데이터프레임[컬럼])[0] 을 잊지말자!
object_columns = apps_all.dtypes[apps_all.dtypes == 'object'].index.tolist()
for column in object_columns:
apps_all[column] = pd.factorize(apps_all[column])[0]학습 데이터와 테스트 데이터 다시 분리
apps_all_train = apps_all[~apps_all['TARGET'].isnull()] #학습 데이터
apps_all_test = apps_all[apps_all['TARGET'].isnull()] #테스트 데이터
apps_all_test = apps_all_test.drop('TARGET', axis=1) #테스트 데이터의 TARGET 값은 아예 없애준다. 학습 데이터를 분리, LGBM 학습 수행
#학습 데이터 분리
from sklearn.model_selection import train_test_split
#입력변수 ftr_app은 아이디와 타깃 버림, 목표변수 target_app 는 target 만.
ftr_app = apps_all_train.drop(['SK_ID_CURR', 'TARGET'], axis=1)
target_app = apps_all_train['TARGET']
train_x, valid_x, train_y, valid_y = train_test_split(ftr_app, target_app, test_size=0.3, random_state=2020)
train_x.shape, valid_x.shape
#LGBM 학습 수행
from lightgbm import LGBMClassifier
clf = LGBMClassifier(
n_jobs=-1,
n_estimators=1000,
learning_rate=0.02,
num_leaves=32,
subsample=0.8,
max_depth=12,
silent=-1,
verbose=-1
)
clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)], eval_metric= 'auc', verbose= 100,
early_stopping_rounds= 50)테스트 데이터 예측, Kaggle Submit
#Classifier 에 테스트 데이터 (입력변수) 넣어 예측.
preds = clf.predict_proba(apps_all_test.drop('SK_ID_CURR', axis=1))[:, 1 ]
apps_all_test['TARGET'] = preds
#Submit 과정
import os, sys
from google.colab import drive
drive.mount('/content/gdrive')
# SK_ID_CURR과 TARGET 값만 csv 형태로 생성. 코랩 버전은 구글 드라이브 절대 경로로 입력
default_dir = "/content/gdrive/My Drive"
apps_all_test[['SK_ID_CURR', 'TARGET']].to_csv(os.path.join(default_dir,'prev_baseline_01.csv'), index=False)처음에 학습데이터와 테스트 데이터를 TARGET null 유무로 나눴고 테스트 데이터의 TARGET 은 아예 버렸다.
그 후 학습 데이터는 입력변수에 아이디, TARGET 값을 버렸고, 목표변수는 TARGET만 챙겼다.
따라서 테스트 데이터는 이미 버린 TARGET 이외에도 아이디를 버려야 한다는 점 잊지말자! 수가 안맞으면 오류가 나서 골치아프다.
