학습 데이터에 다양한 feature engineering 수행
라이브러리와 app 데이터 세트 로딩
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import gc,os,sys
import random
from sklearn.model_selection import KFold, StratifiedKFold
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 300)
pd.set_option('display.max_colwidth', 30)import os, sys
from google.colab import drive
drive.mount('/content/gdrive')
%cd '/content/gdrive/My Drive/'
!ls
app_train = pd.read_csv('application_train.csv')
app_test = pd.read_csv('application_test.csv')결측값, TARGET 값, info 확인
app_train.isnull().sum()
app_train['TARGET'].value_counts()
app_train.info()연속형 숫자 컬럼들에 대해 TARGET 값이 0과 1일때 히스토그램 시각화
시각화를 하는데, 지금은 어떤 정보를 취득하고자 했냐면, TARGET이 0이냐 1이냐에 따라 속성에 따라 달라지는 분포를 시각화하고 싶다. 예컨대 신용이 높은 사람은 그렇지 않은 사람보다 채무된 분포가 적지 않을까 하는 것이다. 코드는 함수로 구현했다. 불리언 인덱싱 해준 것을 히스토그램으로 넣어줬다. 주석에 코드에 대한 설명이 있다.
#함수로 구성, 데이터프레임과 분석 열 받기
def show_hist_by_target(df, columns):
#TARGET 값이 1일 때와 0일 때 나눠서 불리언 인덱싱
cond_1 = (df['TARGET'] == 1)
cond_0 = (df['TARGET'] == 0)
for column in columns:
print("column name: ", column)
#한 번 돌때 1행 2열 만들기.
fig, axs = plt.subplots(figsize = (12, 4), nrows = 1, ncols = 2, squeeze = False)
#하나는 바이올린. [0][0] 으로 표시
sns.violinplot(x = "TARGET", y = column, data = df, ax = axs[0][0])
#다른 하나는 히스토그램에서 두 개 그래프 겹쳐보이기. [0][1] 로 표시
sns.distplot(df[cond_1][column], label = '1', color = 'red', ax = axs[0][1])
sns.distplot(df[cond_0][column], label = '0', color = 'blue', ax = axs[0][1])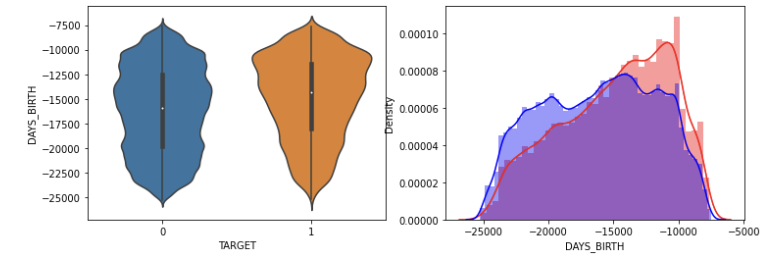
DAYS_BIRTH 출생일 정보에서 늦게 태어난 사람이 더 채무를 잘 이행했다. 젊은 사람일수록 채무를 이행하지 않는 정도가 높았다.
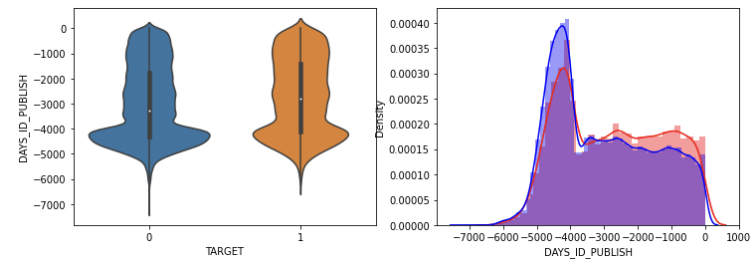
등록한지 얼마 되지 않은 사람의 채무 이행하지 않는 정도가 높았다.
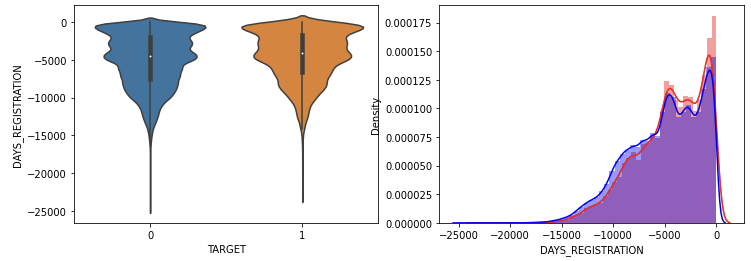
가입한지 얼마 되지 않을수록 채무 불이행의 정도가 높았다.
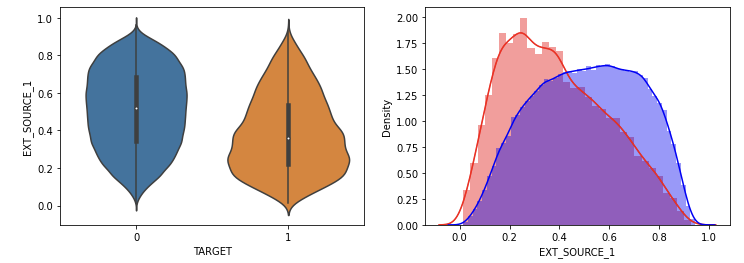
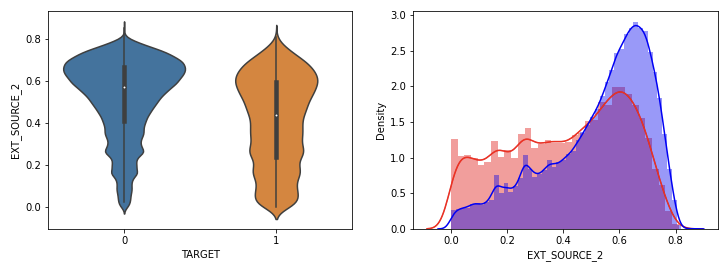
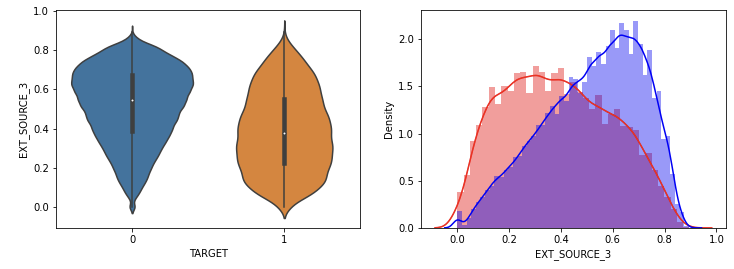
신용평가 점수가 낮을수록 채무 불이행의 정도가 높았다.
연령대가 낮은, 신용평가가 낮은, 가입한지 얼마 안된 대출에서 연체 비중이 높았다.
연속형 숫자값이 아닌 object 컬럼을 TARGET 에 따라 Count 비교
그러나 단순히 숫자값 컬럼들만이 TARGET 을 결정짓지는 않을 것이다. object 컬럼의 영향도 조사하고 싶은데, 이때 연속형은 distplot을, 카테고리값은 countplot을 이용한다는 것을 기억하자.
카테고리값은 countplot, 연속형은 distplot을 이용한다.
countplot은 sns.countplot 을 쓸 수도 있지만 그래프 자체가 일정하게 나오지 않는다는 단점이 있다. sns.catplot을 이용해보자.
sns.catplot(x = column, col = '행 구성 변수', data = 데이터프레임, kind = 'count')
#dtypes 로 object 형들만 가져와 리스트로 반환
object_columns = app_train.dtypes[app_train.dtypes == 'object'].index.tolist()
#반복문 돌며 시각화하는 함수
def show_category_by_target(df, columns):
for column in columns:
print('column name: ', column)
chart = sns.catplot(x = column, col = 'TARGET', data = app_train, kind = 'count')
chart.set_xticklabels(rotation = 65)
show_category_by_target(app_train, object_columns)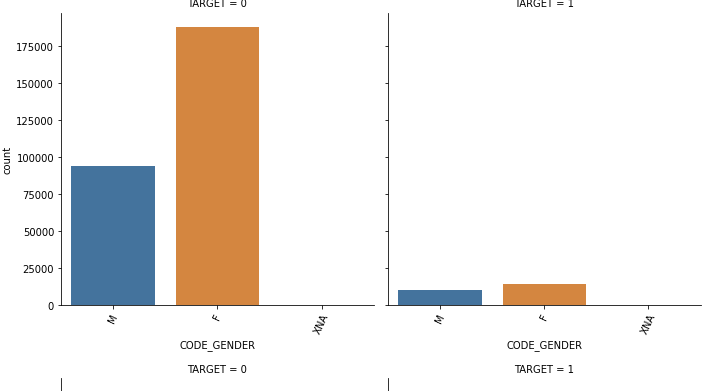
여러 그래프 중 의미있는 인사이트를 지닌 건 CODE_GENDER 예서 TARGET = 1 의 연체자들의 경우 male 비율이 연체가 되지 않은 사람들의 male 비율보다 높았다는 것이다.
value counts로 확인
실제 남성의 비율이 연체에서 높아졌는지 확인하기 위해서 cond 를 주고 다음과 같이 value_counts 해주었다.
cond_1 = (app_train['TARGET'] ==1)
cond_0 = (app_train['TARGET'] ==0)
print(app_train["CODE_GENDER"].value_counts()/app_train.shape[0])
print(app_train[cond_1]['CODE_GENDER'].value_counts()/app_train[cond_1].shape[0])
print(app_train[cond_0]['CODE_GENDER'].value_counts()/app_train[cond_0].shape[0])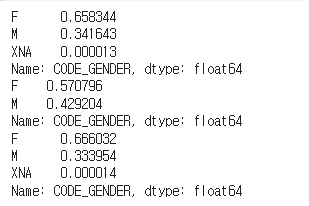
순서대로 전체 비율, 0에서 비율, 1에서 비율인데 연체에서 남성의 비율이 높은 것을 확인할 수 있었다.
주요 컬럼 target 과 상관도 분석
추가로 중요한 컬럼을 확인하기 위해 target 과 상관도 분석을 진행했다.
corr_columns = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH', 'AMT_CREDIT', 'AMT_ANNUITY', 'AMT_GOODS_PRICE',
'DAYS_EMPLOYED','DAYS_ID_PUBLISH', 'DAYS_REGISTRATION', 'DAYS_LAST_PHONE_CHANGE', 'AMT_INCOME_TOTAL', 'TARGET']
col_corr = app_train[corr_columns].corr()
col_corr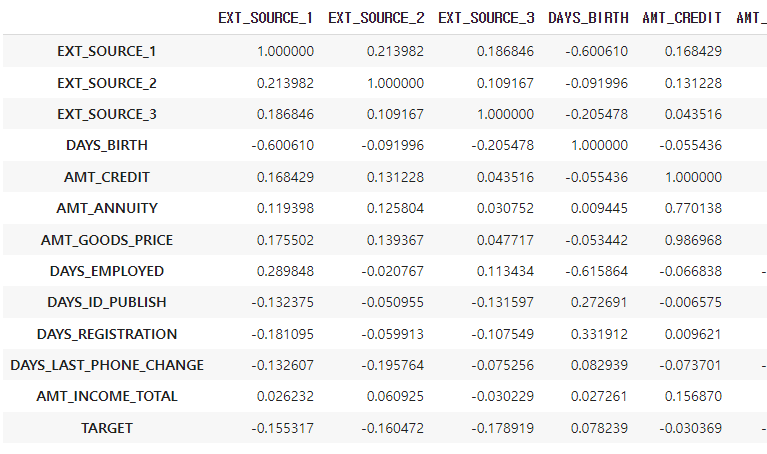
숫자로 보기 힘들어 heatmap 을 찍어보았다.
plt.figure(figsize= (8,8))
sns.heatmap(col_corr, annot = True)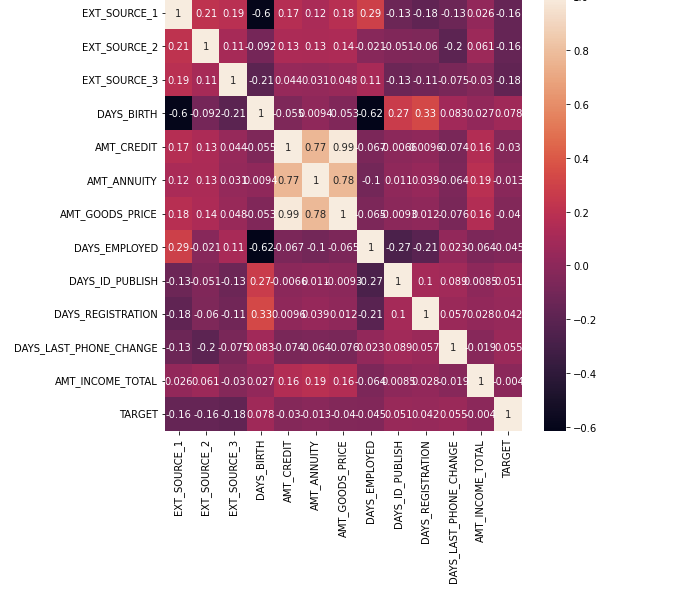
이상치 데이터 확인및 변경
DAYS_EMPLOYED 는 특정 값 때문에 hist 가 잘 보이지 않아 변경해주었다. 특정 값이 365243으로 많이 찍여 있어 nan 으로 바꿨다.
app_train['DAYS_EMPLOYED'] = app_train['DAYS_EMPLOYED'].replace(365243, np.nan)
app_train['DAYS_EMPLOYED'].value_counts()
깔끔!
feature engineering 수행
주요 feature 을 알았으니 engineering 을 수행할 차례다.
데이터를 가공하기 전 apps 라는 데이터 프레임으로 학습과 테스트용 데이터를 결합한다. (결합하는 이유는 피처들을 가공할 때 둘 다 해줘야 하기 떄문이다.)
apps = pd.concat([app_train, app_test])
print(apps.shape)
가장 눈에 띄는 것은 EXT_SOURCE_1,2,3 피처들이었다. 이런 경우 평균과 분산을 모아 따로 새로운 열을 생성하는 것도 좋은 방법이다.
apps['EXT_SOCURCE_MEAN'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].mean(axis = 1)
apps['APPS_EXT_SOURCE_STD'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].std(axis = 1)
#표준편차 평균으로 채워주기.
apps['APPS_EXT_SOURCE_STD'] = apps['APPS_EXT_SOURCE_STD'].fillna(apps['APPS_EXT_SOURCE_STD'].mean())표준편차의 경우 NaN는 계산이 되지 않으므로 일단 연산 후 빈자리를 표준편차 평균으로 채워준다.
AMT_CREDIT 사용하여 가공
apps['APPS_ANNUITY_CREDIT_RATIO'] = apps["AMT_ANNUITY"] / apps["AMT_CREDIT"] #달 / 전체
apps['APPS_GOODS_RATIO'] = apps["AMT_GOODS_PRICE"] / apps['AMT_CREDIT'] #상품 / 전체
apps['APPS_CREDIT_GOODS_DIFF'] = apps['AMT_CREDIT'] - apps["AMT_GOODS_PRICE"] #대출 금액 - 상품 가격순서대로 각각 전체 대출 금액대비해서 달에 갚아나가야 하는 돈, 상품 가격을 알 수 있고 마지막은 대출 금액에서 상품 가격을 뺀 금액이다.
AMT_INCOME_TOTAL 사용하여 가공
수입을 가지고 가공을 해보자.
# AMT_INCOME_TOTAL 비율로 Feature 가공
apps['APPS_ANNUITY_INCOME_RATIO'] = apps['AMT_ANNUITY']/apps['AMT_INCOME_TOTAL']
apps['APPS_CREDIT_INCOME_RATIO'] = apps['AMT_CREDIT']/apps['AMT_INCOME_TOTAL']
apps['APPS_GOODS_INCOME_RATIO'] = apps['AMT_GOODS_PRICE']/apps['AMT_INCOME_TOTAL']
#가처분 소득 피처
apps['APPS_CNT_FAM_INCOME_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['CNT_FAM_MEMBERS']수입대비 월에 갚아야 할 비용, 수입 대비 전체 대출 금액, 수입 대비 상품 가격, 가족 구성원 수 대비 수입으로 가처분 소득도 알아봤다.
DAYS_BIRTH, DAYS_EMPLOYED 사용하여 가공
태어난 날짜와 고용 기간도 중요한 피처였으므로 새로 가공해보자.
# DAYS_BIRTH, DAYS_EMPLOYED 비율로 Feature 가공
apps['APPS_EMPLOYED_BIRTH_RATIO'] = apps['DAYS_EMPLOYED']/apps['DAYS_BIRTH']
apps['APPS_INCOME_EMPLOYED_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_EMPLOYED']
apps['APPS_INCOME_BIRTH_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_BIRTH']
apps['APPS_CAR_BIRTH_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_BIRTH'] #나이대비 차 나이
apps['APPS_CAR_EMPLOYED_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_EMPLOYED'] #일한 기간 대비 차 나이순서대로 나이 대비 고용 기간, 나이 대비 수입, 나이 대비 차량의 나이, 고용기간 대비 차량의 나이등을 추출했다.
그런데 상관관계가 너무 높은 피처들을 가공을 하면 가끔 성능이 좋아지지 않는 경우도 있다. 잘 따져가며 하자!
데이터 레이블 인코딩
object_columns = apps.dtypes[apps.dtypes == 'object'].index.tolist()
for column in object_columns:
apps[column] = pd.factorize(apps[column])[0]데이터 레이블을 인코딩하는 코드는 이전과 같다. object_columns 를 추출하는 위의 코드는 반복되고 매우 중요하니 그냥 외워두자.
이제 apps 를 다시 원본으로 쪼개야 한다.
학습 데이터와 테스트 데이터 다시 분리
다시 분리하는 방법은 TARGET 값을 기준으로 분리하면 된다. 현재 TARGET 값이 null 값이 아니라 0과 1의 값으로 존재하는 건 학습을 위한 학습 데이터 뿐이므로 isnull 로 구분할 수 있다.
데이터프레임 = 데이터프레임['컬럼'].isnull() : 빈 값 추출
데이터프레임 = ~데이터프레임['컬럼'].isnull() : 비지 않은 값 추출. isnotnull 대신 물결 사용
apps_train = apps[~apps['TARGET'].isnull()] #판다스는 isnotnull 이 없음.물결로.
apps_test = apps[apps['TARGET'].isnull()]학습데이터 내 입력변수와 y값 분리. LGBM 으로 학습
#분리
from sklearn.model_selection import train_test_split
ftr_app = apps_train.drop(['SK_ID_CURR', 'TARGET'], axis=1)
target_app = app_train['TARGET']
train_x, valid_x, train_y, valid_y = train_test_split(ftr_app, target_app, test_size=0.3, random_state=2020)
#학습 모델 clf
from lightgbm import LGBMClassifier
clf = LGBMClassifier(
n_jobs=-1,
n_estimators=1000,
learning_rate=0.02,
num_leaves=32,
subsample=0.8,
max_depth=12,
silent=-1,
verbose=-1
)
clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)], eval_metric= 'auc', verbose= 100,
early_stopping_rounds= 100)
기준은 검증데이터엔 valid_1 auc 를 보면 되는데 기존에 0.74대이던 수치가 0.7664로 올랐다!
피처 중요도 시각화
from lightgbm import plot_importance
plot_importance(clf, figsize=(16, 32))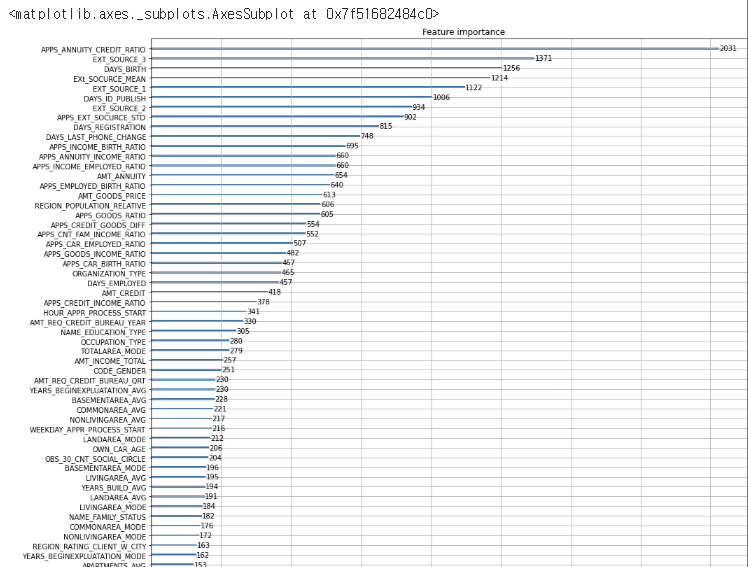
새로 가공한 APPS_ANNUITY_CREDIT_RATIO 와 EXT_SOURCE_MEAN 등이 굉장히 높은 중요도를 보였다.
학습된 clf 이용해 테스트 데이터 예측
preds = clf.predict_proba(apps_test.drop(['SK_ID_CURR', 'TARGET'], axis=1))[:, 1 ]
#파일 만들기
app_test['TARGET'] = preds
app_test[['SK_ID_CURR', 'TARGET']].to_csv('apps_baseline_02.csv', index=False)
!ls학습데이터 중 입력 데이터를 만들 때 두가지를 뺐으니 마찬가지로 빼줘야 한다.
캐글에 업로드하면 다음과 같이 수치가 오른 것을 확인할 수 있다.