- 인공 신경망의 초창기 구조에 대해 알아보자
- 다층 퍼셉트론 MLP 에 대해 알아보자
- 케라스 API 를 통해 인공신경망을 구현해보자
10.1 생물학적 뉴런에서 인공 뉴런까지
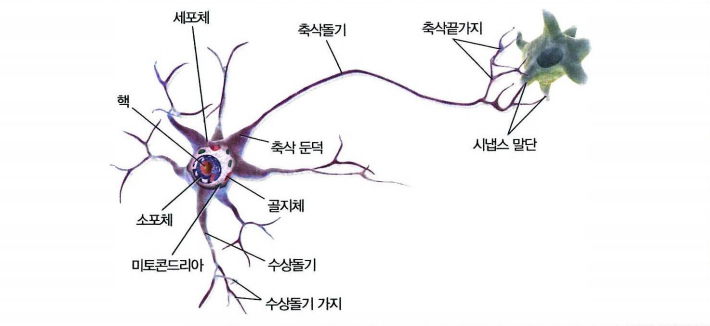
- 시냅스 말단을 통해 다른 뉴런의 수상돌기, 세포체에 연결된다
- 각 뉴런은 신호라 불리는 전기 자극을 만듦
- 신호는 축삭돌기를 따라 시냅스가 신경 전달물질을 만들 수 있도록 함
- 신경전달물질을 받으면 또다시 신호 발생
뉴런을 사용한 논리 연산
생물학적 뉴런에서 착안한 신경망 모델이 곧 인공 뉴런으로 발전하게 된다. 확인해보자.
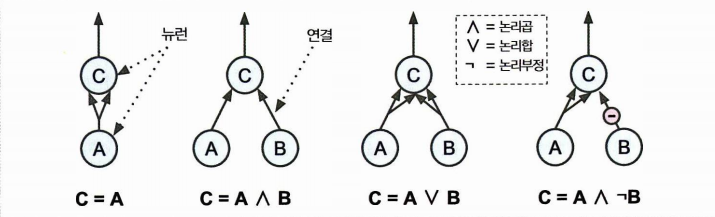
- 1개 이상의 이진 입력과 이진 출력 1개
- 일정 개수만큼 입력이 활성화되면 출력
퍼셉트론
퍼셉트론이란 가장 간단한 인공 신경망 구조 중 하나를 말한다.
- 이때는 입력,출력이 이진 값이 아닌 숫자이다
- 입력은 가중치와 연관된다
- TLU 의 경우 가중합에 계단함수를 적용하여 출력한다.
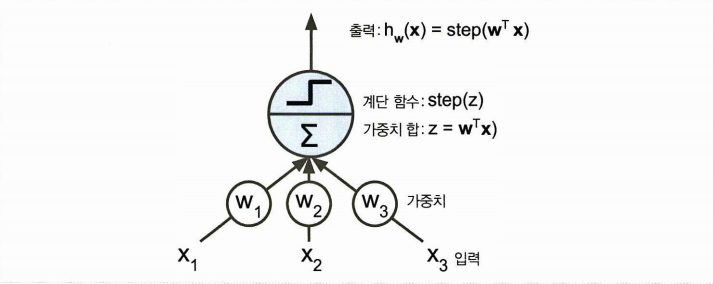
계단함수에는 heaviside step, sign function 등이 사용된다. 의도에 맞게 사용할 것!
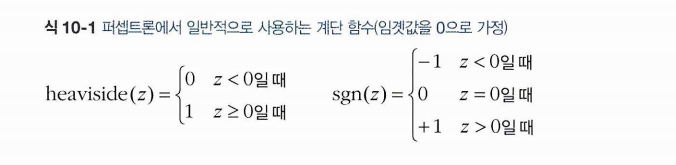
- 하나의 TLU는 이진분류 문제를 풀 수 있다
- TLU 를 훈련한다는 것은 입력과 연결된 최적의 w 를 찾겠다는 것.
퍼셉트론은 층이 하나인 TLU 로 구성된다. 이때 TLU 는 모든 입력에 연결되어 있다고 하여 밀집층 이라 하고, 들어오는 입력은 입력 뉴런을 통해 들어온다. 입력 뉴런으로 구성된 층은 입력층이라 한다.
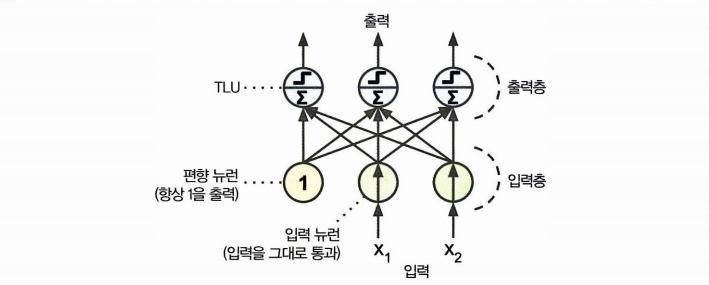
- 입력 뉴런 2개 / 편향 뉴런 1개 / 출력 뉴런 3개로 구성된 퍼셉트론
- 입력뉴런의 입력층과 TLU의 출력층이 존재
행렬식 덕분에 완전 연결 층에 대해 다음과 같이 출력을 계산할 수 있다.
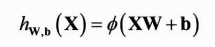
가중치 업데이트 규칙은 다음과 같이 표현할 수 있다.
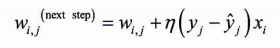
사이킷런에서는 from sklearn.linear_model import Perceptron 과 같이 TLU 네트워크를 구현한 퍼셉트론 클래스를 제공한다. = SGD
그러나 이러한 퍼셉트론은 XOR배타적 논리합 문제를 풀 수 없는 문제가 있었다. 따라서 퍼셉트론을 여러 개 쌓아올리는 방법이 고안되었고, 이를 MLP 다층 퍼셉트론이라 한다.
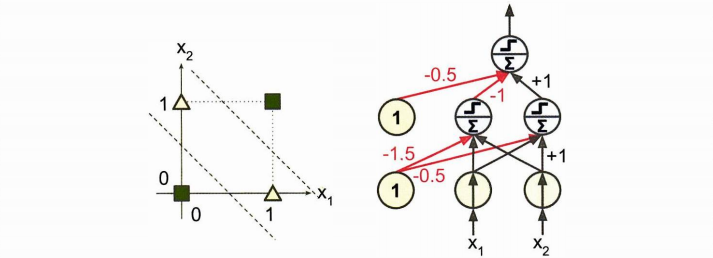
다층 퍼셉트론과 역전파
MLP 의 구성요소: 입력층, 은닉층, 출력층
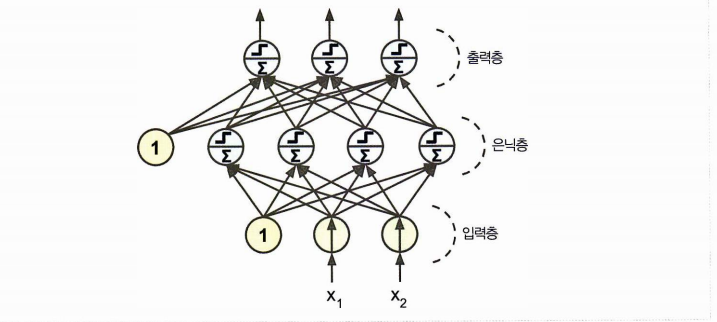
(이때 은닉층을 쌓아올리면 심층 신경망 DNN이 된다. 딥러닝이 연구하는 분야가 바로 여기 심층 신경망.)
- 다층 퍼셉트론은 역전파 알고리즘으로 훈련이 가능
- 모든 모델 파라미터에 대해 오차의 그레디언트 계산
- 자동으로 계산 = 자동미분
- 정방향 계산 > 출력 오차 > 출력 연결이 오차에 기여하는 정도 계산(chain rule) > 입력층까지 오차 그레디언트 측정 > 가중치 수정
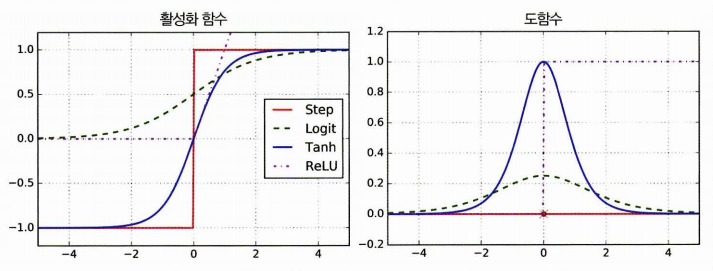
- 다층 퍼셉트론은 이러한 역전파를 잘 작동하고자 활성화함수를 시그모이드로 바꿈.
- 다른 활성화 함수는 하이퍼볼릭 탄젠트, ReLU 함수 등이 있음.
- 활성화 함수를 왜 쓸까? 비선형 연결을 추가하기 위해서이다! 도함수를 보자.
MLP - 회귀
- 값 하나만 예측한다면 출력 뉴런 하나만 필요. (예측 차원에 따라 변경)
- 회귀의 경우 활성화 함수를 아예 쓰지 않거나 ReLU, softplus 를 쓸 수 있다.
- 손실함수의 경우 MSE, MAE, Huber 사용
MLP - 분류
- 이진 분류의 경우 출력 뉴런 1개, 다중 레이블의 경우 레이블마다 1개. 다중 분류의 경우 클래스마다 1개
- 출력층에는 로지스틱 or 소프트맥스 함수
- 손실함수는 CE(log loss) 사용
케라스로 MLP 구현하기
케라스로는 모든 종류의 신경망을 구현, 훈련, 평가, 실행할 수 있다.
데이터 적재와 간편한 전처리가 가능한 tf.keras (텐서플로 번들) 를 사용하자!
텐서플로와 테라스는 설치 후 다음과 같이 간단하게 임포트하면 된다.
import tensorflow as tf
from tensorflow import keras이미지 분류기 만들기
데이터셋 적재
fashion_mnist = keras.datasets.fashion_mnist
(X_train_full, y_train_full), (X_test, y_test) = fashion_mnist.load_data()이때 사이킷런과 달리 케라스를 사용하여 MNIST 데이터를 적재하면 28X28 의 2D 배열로 불러오게 된다. 또한 픽셀 강도가 정수로 표현된다. (.shape 과 .dtype 을 찍어보면 알 수 있다)
전체 훈련 세트를 훈련세트와 검증세트로 만들고 입력 특성의 스케일을 조정해주자.
X_valid, X_train = X_train_full[:5000] / 255., X_train_full[5000:] / 255.
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]
X_test = X_test / 255.정답에 맞게 클래스 이름의 리스트를 만들어주자.
class_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]1. 시퀀셜 API 를 사용하여 분류용 MLP 모델 만들기
신경망을 만들어보자.
- 두 개의 은닉층, 분류용 다층 퍼셉트론
# 시퀀셜 모델 만들기
model = keras.models.Sequential()
# 첫번째 층 추가. 입력이미지를 1D로 변환.
model.add(keras.layers.Flatten(input_shape=[28, 28]))
# 뉴런 300개를 가진 Dense 은닉층 추가, relu 활성화 함수 사용
model.add(keras.layers.Dense(300, activation="relu"))
# 두번째 은닉층 추가
model.add(keras.layers.Dense(100, activation="relu"))
# 클래스마다 하나씩의 10개의 출력층 추가
model.add(keras.layers.Dense(10, activation="softmax"))이렇게 만들어진 모델의 sumary() 메서드는 모델에 있는 모든 층을 출력한다.
- 각 층의 이름
- 출력 크기
- 파라미터 개수
- 전체 파라미터/ 훈련되는 / 훈련되지 않은 파라미터 개수

.layers : 모델에 있는 층을 리스트로 출력
.layers[1]: 인덱스로 층 선택
층이름.name : 이름으로 선택
get_weights() , set_weights() : 층의 모든 파라미터에 접근
weights, biases = hidden1.get_weights()모델 컴파일
.compile() 메서드를 호출하면 모델을 만들고나서 손실함수, 옵티마이저, 평가 지표를 추가로 지정할 수 있다.
model.compile(loss="sparse_categorical_crossentropy",
optimizer="sgd",
metrics=["accuracy"])- 클래스가 배타적일 때 sparse 사용
- 샘플마다 클래스별 확률을 가지고 있다면 categorical_crossentropy
- 이진 분류라면 binary_crossentropy
모델 훈련과 평가
history = model.fit(X_train, y_train, epochs=30,
validation_data=(X_valid, y_valid))- 입력, 타깃, 에폭과 검증세트(선택사항) 전달
- fit 의 class_weight 매개변수: 훈련 세트의 편중 해결(가중치 부여)
- sample_weight 매개변수: 샘플별로 가중치 부여
history 객체에 파라미터, 에폭 리스트가 포함되어 있어 훈련세트, 검증 세트에 대한 손실을 파악할 수 있다.
.evaluate() 메서드로 일반화 오차를 추정한다.
model.evaluate(X_test, y_test)예측 만들기
.predict() 메서드를 사용하자.
X_new = X_test[:3]
y_proba = model.predict(X_new)
y_proba.round(2)
각 샘플에 대해 클래스마다 확률을 추정한 것을 확인할 수 있다.
2. 시퀀셜 API 를 사용하여 회귀용 MLP 만들기
