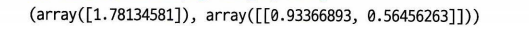💡모델이 어떻게 동작하는 지 알아야 하는 이유
- 작업에 맞는 적절한 모델 선택
- 작업에 맞는 올바른 훈련 알고리즘 선택
- 작업에 맞는 좋은 하이퍼파라미터 선택
- 디버깅, 에러 분석
그럼 알아보자!
- 모델 훈련 방법
- 다항 회귀
- 학습 곡선(과대적합 감지)
- 규제 기법(과대적합 기법)
- 로지스틱 회귀, 소프트맥스 회귀
4.1 선형 회귀
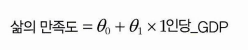
이처럼 간단한 선형 회귀 모델을 일반화해보자.

쉽게 말해 예측 = 특성1 가중치1 + 특성2 가중치2 + ... + 특성n * 가중치n
은 예측값이다.
은 특성의 수
는 i번째 특성
는 j번째 모델 파라미터
이를 다음과 같이 간추려서 쓸 수 있다. 벡터 형태로 표현한 것!

는 세타0 - 세타n까지의 특성 가중치를 담은 모델의 파라미터 벡터이다.
는 X0 - Xn까지의 값을 담은 특성 벡터이다.
는 점곱이다.
는 모델 파라미터 세타를 사용한 가설함수라 한다.
이와중에 점곱할 때는 당연히 하나는 열이고 하나는 행 벡터여야 하고, 아니면 전치(transpose) 시켜줘야 한다.
- 위는 선형 회귀 모델이다
- 모델을 훈련한다는 것은 훈련 세트에 잘 맞도록 파라미터를 업데이트 하는 것이다.
- 업데이트를 위해선 예측과 실제 값의 차이를 이용한다
- 주로 RMSE 를 사용하고, 결국은 RMSE 를 최소화하는 파라미터를 찾는 것이 목표
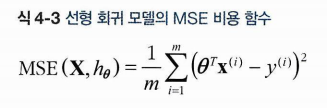
MSE 비용함수는 다음과 같이 계산한다. 평균은 평균인데,
i번째 예측값 - i번째 실제값을 제곱한 것들의 합이다.
i번째 예측값은 역시나 세타 행렬(파라미터 행렬)과 입력변수 행렬의 곱이 된다. 앞으로는 MSE(theta) 로 표기한다고 한다.
4.1.1 정규방정식
비용함수를 최소화하기 위한 세타 값을 찾을 수 있는 공식은 다음과 같다.

다음과 같은 선형 데이터가 있다고 가정하자.
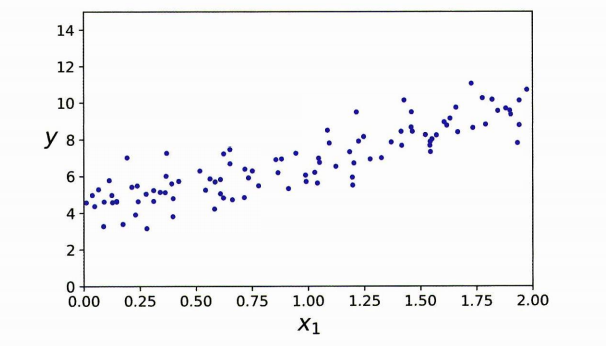
???
사이킷런에서 선형 회귀
간단한 코드를 확인해보자.
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X, y)
각각 x=0 일 때 y 좌표, 계수를 의미한다.
lin_reg.intercept_, lin_reg.coef_여기에 lin_reg로 예측을 진행해주면 각각 예측을 진행해준다.
LinearRegression 클래스가 scipy.linalg.lstsq()에서 왔으므로 이 함수를 직접 호출할 수 있다.
# 싸이파이 lstsq() 함수를 사용하려면 scipy.linalg.lstsq(X_b, y)와 같이 씁니다.
theta_best_svd, residuals, rank, s = np.linalg.lstsq(X_b, y, rcond=1e-6)
theta_best_svd이 함수는 를 계산한다.
- X+ 는 X의 유사역행렬이고, np.linalg.pinv() 를 사용해 구할 수 있다.
- 유사역행렬 자체는 특잇값 분해 (SVD)라 부르는 표준 행렬 분해 기법을 사용한다.
- SVD는 훈련 세트 행렬 X를 3개의 행렬 곱셈으로 분해한다.
- 정규방정식 계산보다 이 방식이 효율적이다.
- 행렬 의 역행렬이 없다면 정규방정식은 작동하지 않지만 유사역행렬은 항상 구할 수 있다.
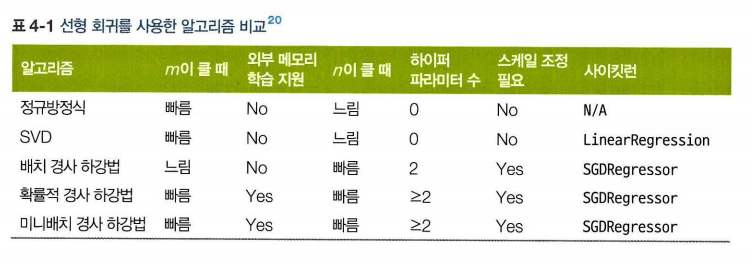
4.1.2 계산 복잡도
의 역행렬을 계산하는 정규방정식.
- 역행렬을 계산하는 계산 복잡도는 에서 사이.
- LinearRegression 클래스는 O(n^2)
- 예측 계산 복잡도는 샘플 수와 특성 수에 선형적.
이제 다른 방법으로 모델을 훈련시키자!
4.2 경사하강법
경사하강법 (gradient descent, GD) 일반적인 최적화 알고리즘이다. 비용함수를 최소화하기 위해 반복해서 파라미터를 조정해나간다.
- 빨리 내려가는 방법은 가장 가파르게 내려가는 것이다.
- 임의의 세타에서 시작한다 (무작위 초기화, x축은 세타의 값이고, 그에 따른 비용의 그래프이다.)
- 해당 비용함수를 미분한 값을 계산한다
- 기울기가 감소하는 방향으로 진행한다. (업데이트)
- 기울기가 0이 되면 최솟값에 도달!
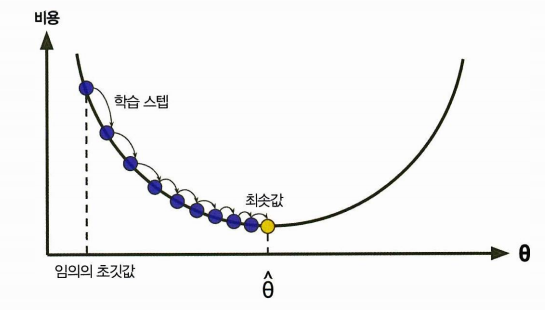
이때 학습률이란 하이퍼파라미터 중 하나로 등장하며, 스텝의 크기를 뜻한다.
-
학습률이 너무 작으면 반복이 너무 오래 걸리고
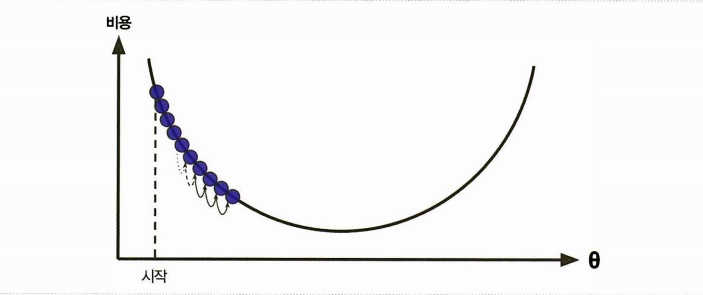
-
학습률이 너무 크면 = 스텝이 크면 반대편으로 가게 되어 비용이 증가할 수도.
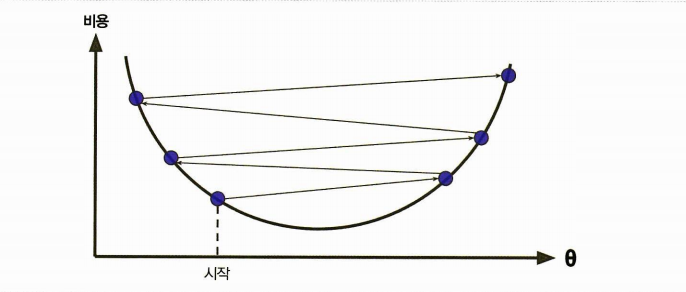
🤔경사하강법의 문제점
- 무작위 초기화 (세타를 임의로 시작한다는 점)
- 때문에 알고리즘이 왼쪽에서 시작했다고 하면 전역 최솟값보다 덜 좋은 지역 최솟값에 수렴.
- 오른쪽도 내려오는데까지 시간이 오래 걸림 (평지라)
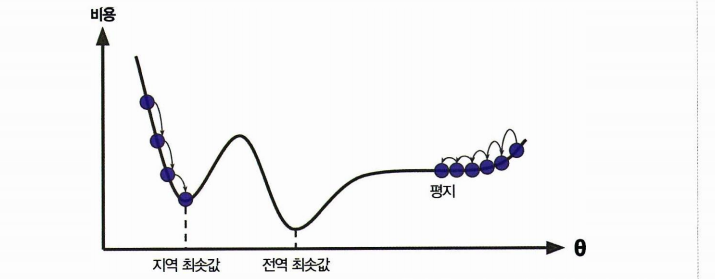
선형회귀의 MSE 비용함수는 항상 볼록함수로 하나의 전역 최솟값만 존재한다. 그리고 연속이며 기울기가 일정하게 변한다. ➡️ 경사하강법만으로도 전역 최솟값에 다가간다!
비용함수에 스케일링이 들어가지 않은 다양한 형태를 보자.
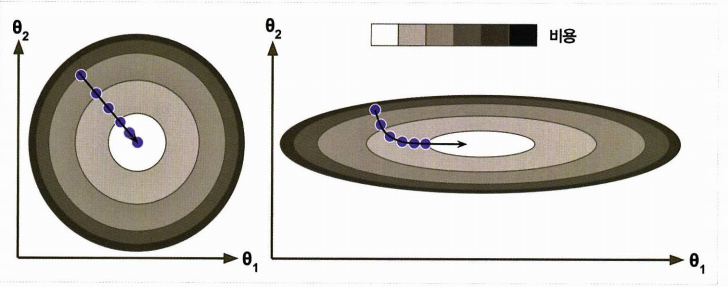
왼쪽은 스케일이 적용되었고, 오른쪽은 세타1이 스케일이 더 작아 영향을 주기 위해서 세타가 많이 바뀌어야 하므로 길쭉해진 모양이다. 이와 같은 경우
- 왼쪽은 같은 벡터를 적용시켜 빠르게 도달
- 오른쪽은 돌아가므로 시간이 오래걸린다 (같은 스케일이 아니라면 수렴하는데 시간이 오래걸린다.)
- 파라미터가 많을수록 차원은 커지고 검색이 어려워진다.
4.2.1 배치 경사 하강법
편도함수란 모델 파라미터 (세타) 가 변경될 때 비용함수가 얼마나 바뀌는지 계산한 것이다.
이는 모든 차원에 대해서 'N쪽을 바라봤을 때 발밑에 느껴지는 산의 기울기'를 계산한 것이다. 편도함수는 다음과 같다.

그리고 이러한 모든 차원에 대한 질문을 한꺼번에 계산한 것이 다음 그레디언트 벡터이다.

어려워보이지만 사실 기존 비용함수에다가 를 곱해준 것이 끝이다! 운이 좋게도 비용함수를 세타에 대해서 미분한 값이 기존 비용함수에 X를 곱해준 형태가 된다. (우연히 계산 결과가 그렇게 된 것이다.)
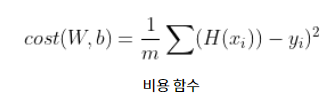
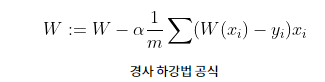
또한 배치 경사하강법은 이 공식을 매 경사하강법마다 반복하는 것을 말한다. (매 스텝에서 훈련 데이터 전체를 사용하는 것)
- 기울기 벡터가 구해지면 반대로 가야한다
- 이는 기존 기울기에서 해당 세타에서 구한 기울기를 뺀 것과 같다
- 그냥 빼지 않고 학습률 알파를 사용한다
- 학습률 알파는 이전에 말했듯이 내려가는 스텝의 크기다.

다음은 학습률에 따른 경사하강법이다. 학습률이 너무 낮은 경우 시간이 오래 걸리고, 적당한 경우 최적에 수렴, 너무 높은 경우 발산할 것이다.
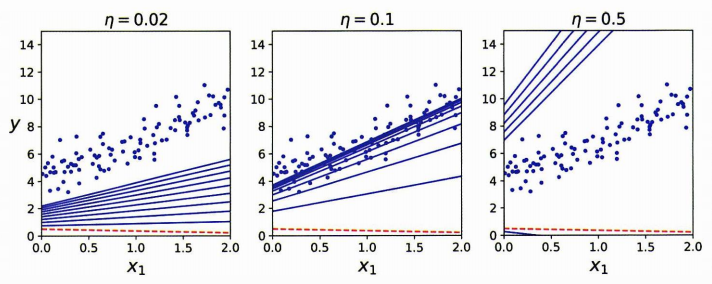
- 학습률은? 그리드탐색을 이용해 찾는다. (그저 하이퍼파라미터 중 하나다!)
4.2.2 확률적 경사하강법
-
1개 샘플 무작위 선택, 1개에 대한 기울기 계산
-
알고리즘이 훨씬 빠름
-
매우 큰 훈련세트도 훈련 가능 (하나의 샘플만 메모리에)
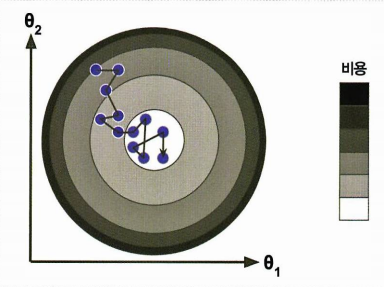
-
최솟값에 근접할 수 있으나 안착하지 못할 수 있음
-
전역 최솟값을 찾을 가능성이 높음
-
무작위성은 지역최솟값은 탈출시키지만 전역 최솟값에 다다르는 것은 보장하지 않음.
-
학습률을 점진적으로 감소시켜 전역 최솟값에 다다르게 할 수 있음.
-
시작할 때는 학습률을 크게, 점차 작게 줄여서 전역에 도달
-
학습 스케줄이란 매 반복에서 학습률을 결정하는 것임.
결과적으로 다음과 같이 스텝이 불규칙한 (학습률이 컸다가 작아지는) 것을 확인할 수 있다.

- 사이킷런의 SGDClassifier 은 훈련 세트를 섞은 후 하나씩 선택하고 다음 에포크에서 다시 섞는 방법을 사용한다.
- 기본적으론 어떤 샘플이 한 에포크에서 여러 번 선택될 수도 있다.
4.2.3 미니배치 경사하강법
이제 둘의 중간인 미니배치의 순서다!
미니배치는 샘플 여러개를 묶어둔 작은 샘플 세트이다. 미니배치에 따라 학습을 진행하고, 업데이트를 진행하는 것이다.
미니배치를 크게하면 확률적 경사하강법보다 덜 불규칙하게 움직이므로 최솟값에 더 가까이 도달할 수 있다. (그만큼 지역 최솟값은 빠져나오기 힘들다.)
세가지 알고리즘의 경로를 보면 이제 짐작이 가능하다!
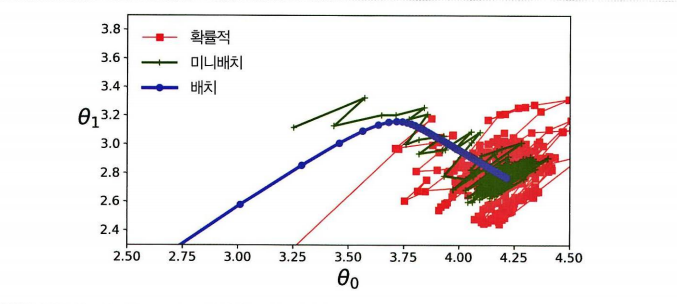
- 배치 경사하강법은 최솟값에서 멈춘다
- 확률과 미니배치는 맴돈다
- 배치는 스텝에서 소요시간이 길다
- 학습 스케줄을 이용하면 확률과 미니배치도 최소에 도달할 수 있다!
4.3 다항 회귀
데이터가 단순 직전이 아닌 복잡한 곡선이라면 어떻게할까?
다항 회귀란 기존 선형 모델을 조금만 번형시켜 각 특성의 거듭제곱을 새로운 특성으로 추가하고, 이 특성을 포함한 데이터셋을 훈련 데이터로 준다.
사이킷런의 PolynomialFeatures를 이용하면 훈련데이터의 각 특성을 제곱하여 새로운 특성으로 추가하는 변환기같은 역할을 한다.
from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree=2, include_bias = False)
X_poly = poly_features.fit_transform(x)X_poly 는 기존 특성 X와 이 특성의 제곱도 포함한다. 이를 훈련 데이터에 적용시키면
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y)
lin_reg.itercept_, lin_reg.coef_