2023 국립국어원 인공지능 언어능력평가 경진대회 참여 회고
📚 이야기 할 것들
- 대회 개요
- 내가 맡았던 역할
- 팀원의 도움을 받았던 점
- 잘했던 점(K), 문제였던 것(P), 앞으로는 어떤걸?(T)
1. 국립국어원 인공지능 언어능력 평가: 대회개요
최근에 연구생으로써 한 두가지 일? 과제 중 하나였던 경진대회가 종료되었다. 우리 연구생이 참여한 경진대회는 다음과 같았다!

국립국어원 - 모두의 말뭉치 에 들어가면 찾을 수 있는 페이지이다. < 인공지능의 언어 능력 평가 > 를 대주제로, 1. 감정 분석 과제 2. 이야기 완성 과제 가 있었는데, 우리는 그 중 1에 참여했다. 과제 운영 기간은 2023.08.21 - 2023.10.20 까지로, 4일 전에 마무리.. 된 대회에 대한 회고를 하려한다.
대회는 트위터 텍스트에 드러나는 8가지 감정 유형 (joy, anticipation, trust, surprise, disgust, fear, anger, sadness) 에 대한 target 을 맞추는 것이었다. 한 트윗에 하나 이상의 감정이 정답일 수도 있었다! 데이터는 train, dev, test 로 구성되었으며 test 에는 정답이 달려있지 않고 inference 만 할 수 있게되어 최종적으로 test 에 대한 정답이 달린 jsonl 을 보고, public score 를 계산해서 리더보드에 표시되는 형태였다.
2. 내가 맡았던 역할
사실 나는 다른 연구과제를 하고 있었기에, 대회에 처음부터 참여한 것은 아니다. 우리 팀이 회의를 거치고 첫 baseline 모델을 올리기 시작한 것이 9월 4일인데, 내가 ASL 논문을 읽은 것은 9월 18일이다. 따라서 2주 정도 늦게 참여해서, 1달 정도의 기간을 같이 했다고 말할 수 있겠다.
늦게 참여한 탓에 점수와 노력에 대한 공은 팀원들에게 더 있다고 생각하나, 그래도 그 중에서도 내가 할 수 있었던 일, 했던 일들에 대해서 말해보고자 한다.
➡️ Asymmetric polynomial loss for multi-label classification 논문 적용
일명 ASL loss 라고 이름 붙여진 loss 에 대한 구현, 적용을 맡았다. ASL loss 는 이름에서도 알 수 있듯이 각 라벨에 대한 BCEwithLogitLoss 를 하는 대신에 Asymetric 한 loss 를 적용하는 것이다. 로그 계산을 다항식으로 변형시키고, true 와 false 간에 비율을 조정하는 loss 식인데.. ASL loss 를 도입한 이유는 다음과 같다.
- 데이터에 true 와 false 의 비율이 비슷하지 않아 (false로 몰려있어) 그에 대한 가중치 조정이 필요할 거 같다고 생각했기 때문이다.
- 가능한 시나리오로는 true 에 가중치를 줘서 적은 true 레이블에 대해 잘 반응하게 만들거나,
- false 의 비율이 압도적으로 많으므로 loss 도 이에 맞게 true 에 둔감, false 를 잘 뱉는 모델을 만들면 되었다
- 결과적으로 후자가 맞았다
따라서 다항식으로 변형시킨 다음 true 과 false 간의 거듭제곱 가중치를 찾고 (나의 실험에 따르면 0, 1 이 적절했다) 이를 또다시 모델에 적용시켜 맞는 하이퍼파라미터를 찾는 과정을 거쳤다.
➡️ KcELECTRA best hyperparameter tuning
ASL loss 를 적용시킨 건 KcELETRA base 의 모델이었다. 따라서 자연스럽게 모델에 loss 를 바꾼 후, 이에 맞는 적절한 하이퍼파라미터 튜닝을 하는 게 다음 목표가 되었다. 실험을 하면서 결과는 다음과 같이 스프레드 시트에 기록해서 공유했다.
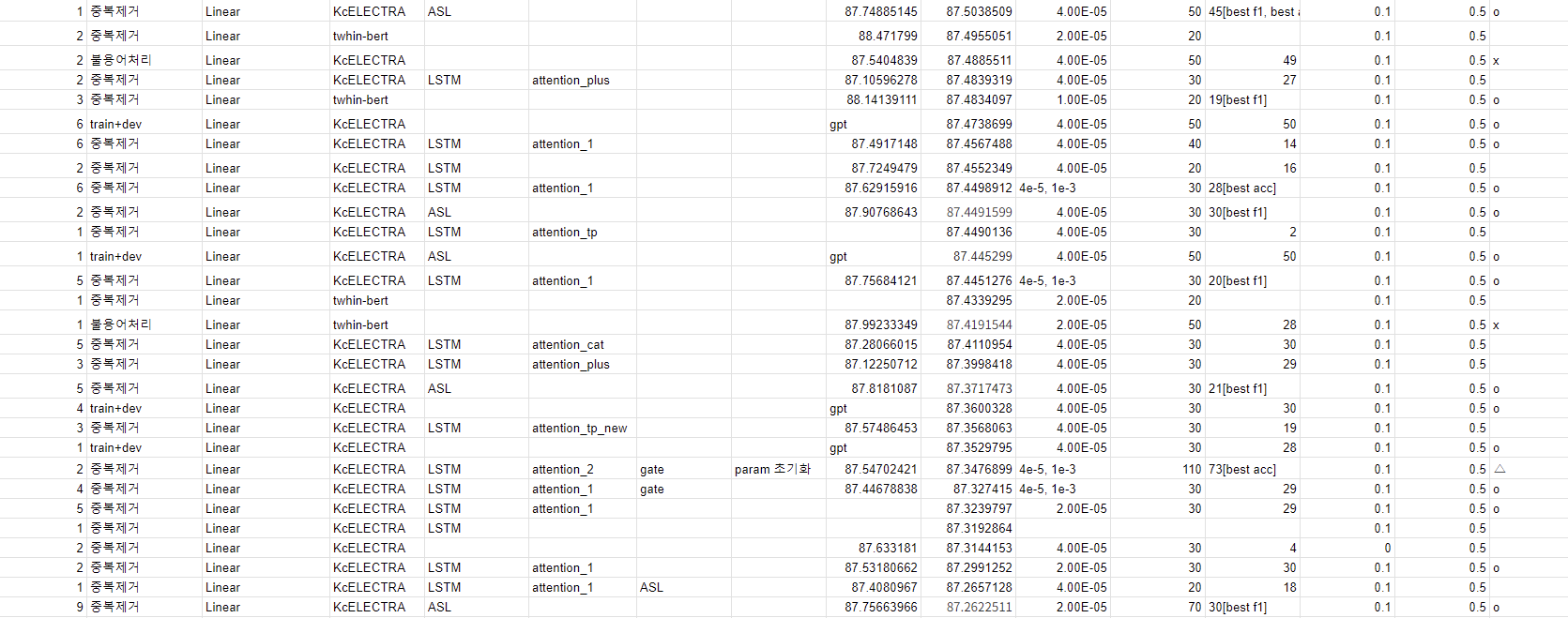
중간중간 ASL 이 끼어있는 것이 내가 훈련한 모델을 성능이며, 성능 상으로 기록했기에 아래에 더.. 있다. 보다싶이 내가 훈련한 모델이 항상 최고의 성능을 보이는 것은 아니었으며, 그러나 같은 조건에서 BCE loss 보다 좀 더 나은 dev/test score 을 뽑아내기도 했다. 어쨌든, 중요하게 여겼던 부분은
- dev score 의 상승 (87. 후반대를 계속해서 노렸다)
- dev score 와 test score 의 간극 줄이기 (overfitting 문제의 해결)
- 에폭 조정, 20, 30, 35, 40, 50, 70 등 정말 다양하게 시도했던 거 같다
- 훈련 에폭과 제출 에폭 사이 간극: 예컨대 dev score가 가장 좋다고 70에폭 중 20에폭 결과를 제출하면 크게 성능이 떨어졌다, 차라리 dev가 조금 낮은 60 후반 에폭의 결과가 나았다
- 에폭에 따른 lr 변화
- weight decay 0.01 을 default 로, 늘리거나 줄여가며 L2 규제를 조절
- accumulation
- seed: 같은 조건이라도 어디에서 출발하느냐도 차이가 심했고
- batch-size, valid-batch-size 심지어 배치 사이즈에 따라서도 차이가 심하게 난다는 걸 알았다
대회 후반부에 앙상블로 넘어가기 전까지는 정말 다양한 조건에서 실험해가며 개별 모델의 성능을 0.01 이라도 올리려고 노력했다. 이렇게 훈련을 반복하며 단일 조건이 아닌 여러 조건이 결합되었을 때 훈련의 양상에 대해서도 체감할 수 있었으며 (예컨대 같은 조건에서 30에폭이 최고 성능이 뒤에 나올 거 같다고 해서 에폭을 50으로 늘려도 Learning rate 의 분배로 그렇지 않다거나) VSCODE 를 통해 서버를 원격 접속해서 훈련하는 일련의 과정에 익숙해질 수 있었다. (tmux 라는 것도 처음 알아서 사용했다.)
3. 팀원의 도움
그러나 사실 전반적인 진행이나 점수와 관련해선 팀원들의 공이 다라고 생각한다. 이전에 참여한 대회와는 다르게 내가 주도하는 위치가 아니었으며, 오히려 초반에 합류했을 땐 뭐가뭔지 몰라 정말 막막했다. 그때 나는 기본을 지키려고 노력했고, 아래와 같이 도움을 요청했다.
- 내가 할 수 있는 선에서 최대한 searching
- 안되는 걸 찾고, 정리해서 간결하게 전달 (문제가 발생해서 이러이러하게 시도를 해봤는데, 여전히 막힌다거나, 다음 step 이 문제라거나)
- 도움을 얻으면 빠른 피드백 (해결 o or x)
- 팀 전체적인 시간이 없으면(질문을 통해 바로 해결될 것이라면) 나 혼자 끙끙대지 말고 바로 질문
정확히 몇 번째 팀플이었는진 기억이 안나지만, 팀플을 거치면서, 여러 사람과 협업하고 머리를 맞대는데 익숙해져야겠다고 또다시 느꼈던 시간들이었다. 다행히 팀원분들이 질문을 받아주실 때나 (카톡으로 질문을 했을 때에도) 언제든 편하게 질문하라고 말씀해주신 게.. 정말 큰 힘이 되었다.
KPT
➡️ K(Keep)
잘했던 것은, 또다시 새로운 경험을 하였으며, - 이번엔 아이디어와 실험보단, 물론 그 과정도 있었지만, 다양한 실험과 노가다를 거듭하며 공동의 목표인 점수 올리기에 열심인 - 새롭게 느끼게 된 감정들이 많다는 것이다. 대회에 참여하기 전까지만 해도 '경진대회? 점수만 올리면 재밌으려나..' 라는 생각이었는데 내가 생각했을 때 다음 조합을 생각하고, 안되면 다시 바꿔서 올리고 기다리고, 하는 과정이 꽤 흥미로웠다. 다음은 경진대회 중간에 나와 했던 개인톡..이다.
실험의 모든 의도를 스프레드 시트에 적을 수 없으니 간단히 실험을 올려두고 의도를 적기 좋은 게 쉽게 켤 수 있는 카톡이었던 거 같다 ㅎㅎ
➡️ P(problem)
코드 수준에서 많은 부족함을 느꼈다. 이해하는 건 가능하지만, 내가 저 많은 코드들을 직접 짜고 연결할 수 있을까? 하는 생각이 들었다. 올해 안으로나 내년에 이루고 싶은 목표는 매우 많은 라인의 코드에 익숙해지기 / 그걸 내가 직접 짤 수 있는 사람되기이다. 그리고 한편으론 코드보다 조금 더.. 이론/학문적인 공부도 하고싶지만 어차피 불가분의 관계일 거 같으므로.
➡️ T(trying)
우선 지난 수업 시간이었던 hugging face tutorial 부터 다시 시작해야겠다. 그리고, 올해나 내년 약간의 기간을 가지고 모델 구현하는 연습을 충분히 더 해야겠다고 생각했다. 모델은 내가 관심있어하는 모델이라면 어떤 것이든 다 좋을 거 같다!
