📄 [원문]
Abstract
non-parallel의 다대다 vc와 zero-shot vc를 수행하기 위해 GAN 그리고 CVAE가 새로운 해결책으로 등장했었다. 하지만 GAN의 training은 복잡하고 CVAE의 training은 간단하지만 GAN만큼의 좋은 성능을 내지 못한다. 따라서 이논문에서는 AutoVC라는 autoencoder를 포함하는 스키마를 가진 새로운 style transfer를 소개한다.
Introduction
[ 기존 방식들의 문제점 ]
- 대부분이 parallel한 데이터를 가정한 vc system
- 소수의 non-parallel한 데이터가 사용가능한 연구 중에서 다대다 conversion은 더 소수
- zero-shot conversion이 가능한 vc는 없음
최근엔 deep style transfer로 GAN, CVAE등이 vc에서 인기를 얻고 있다. 하지만 GAN은 훈련시키기 매우 어렵고 수렴이 잘 안된다. 생성한 speech의 품질도 그렇게 좋지 않다. 반면에 CVAE는 훈련이 비교적 쉽다. 하지만 CVAE는 알맞은 distribution matching을 보장하지 않고 conversion output의 over-smoothing으로부터 어려움을 겪는다.
적절한 style transfer 알고리즘은 GAN처럼 distribution을 일치시키고 훈련은 CVAE처럼 간단하면 되지 않을까라는 의문에 동기를 부여받아 이논문은 AutoVC라는 새로운 style transfer scheme을 주장한다.
AutoVC는 parallel data없이도 다대다 vc가 가능한 알고리즘이다. autoencoder 프레임워크를 따르고 오직 autoencoder loss로 훈련된다. 하지만 이는 미세하게 조정된 차원 축소와 일시적 downsampling을 도입한다.
그리고 최초로 zero-shot vc가 가능한 모델이다.
Style Transfer Autoencoder
앞으로 등장할 수식에서의 정의
- 대문자 글자(ex. X) : 랜덤 변수,벡터들
- 소문자 글자(ex. x) : 랜덤 변수들의 결정 변수 또는 인스턴스
- : entropy
- : 조건부 entropy
Problem Formulation
- U : speaker identity
- Z : content vector
- X(t) : speech waveform의 샘플 또는 speech spectorgram의 프레임
- 여기서는 각 화자가 같은 양의 gross information을 생성한다고 가정한다
- [ Eq.(1) ]
- source speaker :
- target speaker :
- 목표
- 에서 content를 보존하면서 의 변환 output를 생성하는 speech converter
- 그러면서 speaker U_2의 화자 특성은 일치시킨다
- ideal한 speech converter은 다음 수식을 따른다
- [ Eq.(2) ]
- target speaker의 identity인 와 source speech에서 content , 변환된 speech는 처럼 들려한다는 의미이다
The Autoencoder Framework

Autovc는 위 그림과 같은 단순한 autoencoder 프레임워크에서 vc를 수행한다.
[ 3가지 모듈 구성 ]
- content encoder
- speech로부터 content embedding 생성
- speaker encoder
- speech로부터 speaker embedding 생성
- decoder
- content와 speaker embedding으로부터 speech 생성
이 모듈들에서의 input은 conversion과 training과정에서 각기 다르다.
Conversion
변환 과정에서 source speech 은 content 정보를 추출하기 위해 content encoder 로 입력된다
target speech 는 target 화자의 정보를 제공하기 위해 speaker encoder 로 입력된다.
디코더는 source speech에서 content 정보와 target speech에서 target 화자 정보를 기반으로 변환된 speech를 생성한다.
- [ Eq(3) ]
Training
이 논문에서는 speaker encoder가 이미 pre-trained됐다고 가정하기에, contetn encoder와 decoder만 훈련을 진행한다.
parallell data를 가정하지 않기 때문에 training에서는 오직 self-reconstruction만 요구된다.
더 자세하게는, content encoder의 input은 여전히 이지만, style encoder에서 input은 로 나타나는 같은 화자 의 발화가 된다.
- [ Eq(4) ]
loss function은 다음과 같다:
[ Eq(5) & Eq(6) ]
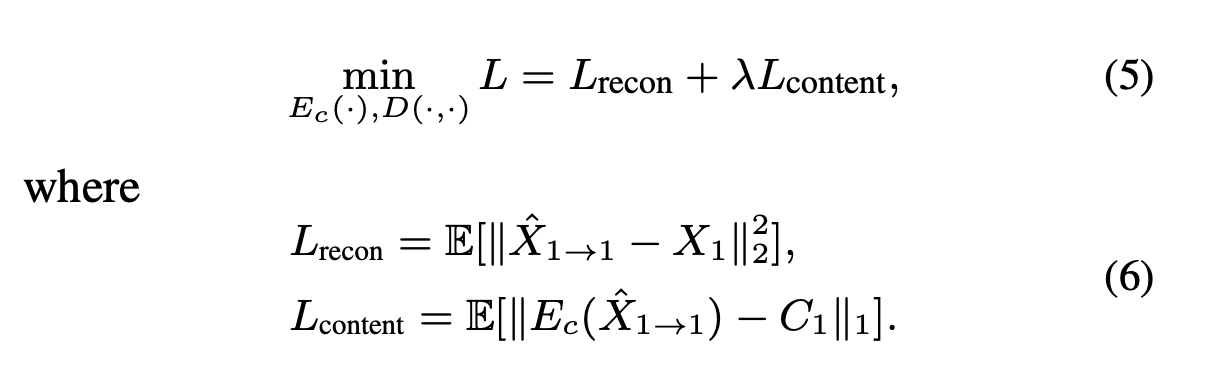
Why does it work?
autoencoder기반 훈련 스키마가 이상적인 vc를 가능케하는 핵심 이유는 적절한 information bottelneck를 갖는 것에 있다.
AutoVC의 프레임워크는 다음의 이론 및 가정을 따른다.
[ Theorem 1]
Eq3, Eq4를 고려했을 때,
- 같은 화자의 다른 발화들의 speaker embedding은 같다. 라면 이다
- 서로 다른 화자들의 speaker embedding은 다르다. 라면 이다
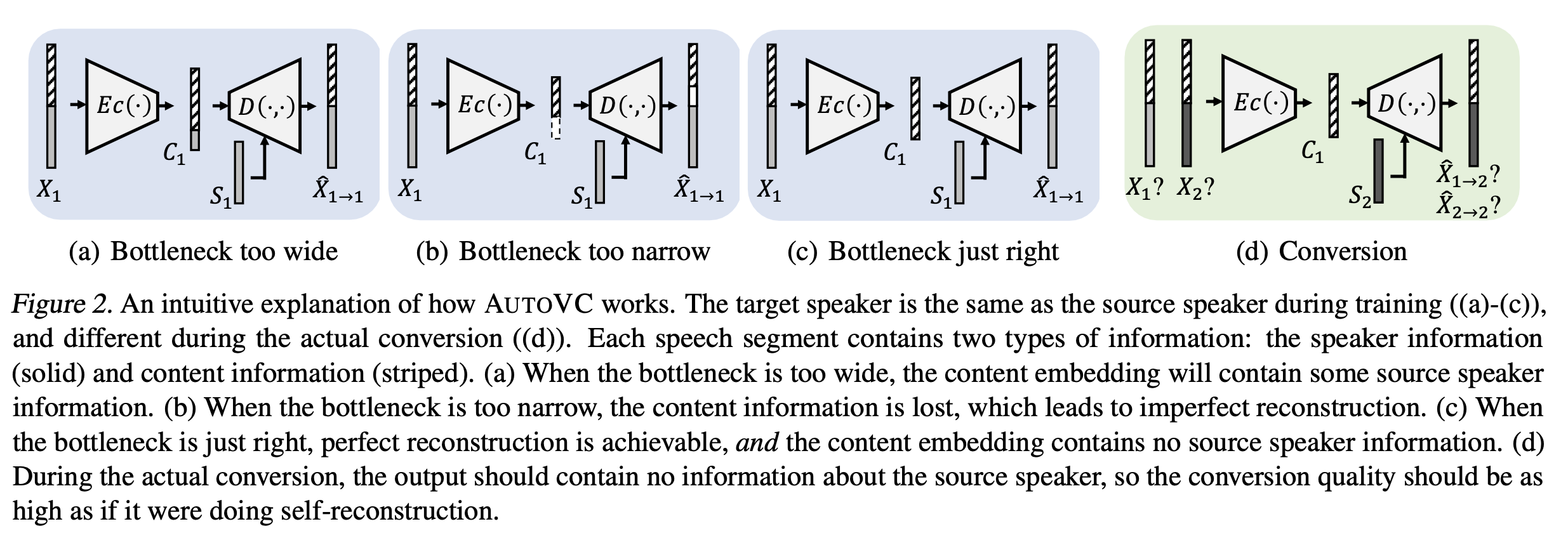
위 사진에서 보이듯이 speech는 두가지 종류의 정보를 포함한다 : 화자 정보 & 화자와 독립적인 정보(=content 정보)
bottleneck이 너무 넓으면, content embedding인 의 차원이 축소되기 때문에 은 정보를 손실하게 된다.
반면에 bottleneck이 너무 좁으면, content encoder는 화자 정보 뿐만 아니라 content 정보까지 너무 많은 정보를 잃게 된다. 이 경우 완벽한 reconstruction은 불가능하다.
그러므로 위사진에서 (c)처럼 의 차원은 content 정보를 손상시키지 않으면서 모든 화자 정보를 제거가능한 만큼 충분한 정도로 차원이 축소되어야 한다.
적절한 Bottleneck 범위를 정할 경우, 다음이 가능하다.
- 완벽한 reconstruction이 가능하다
- content embedding인 은 source speaker 에 관한 어떤 정보도 포함하지 않는다(= speaker disentaglement)
AutoVC Architecture
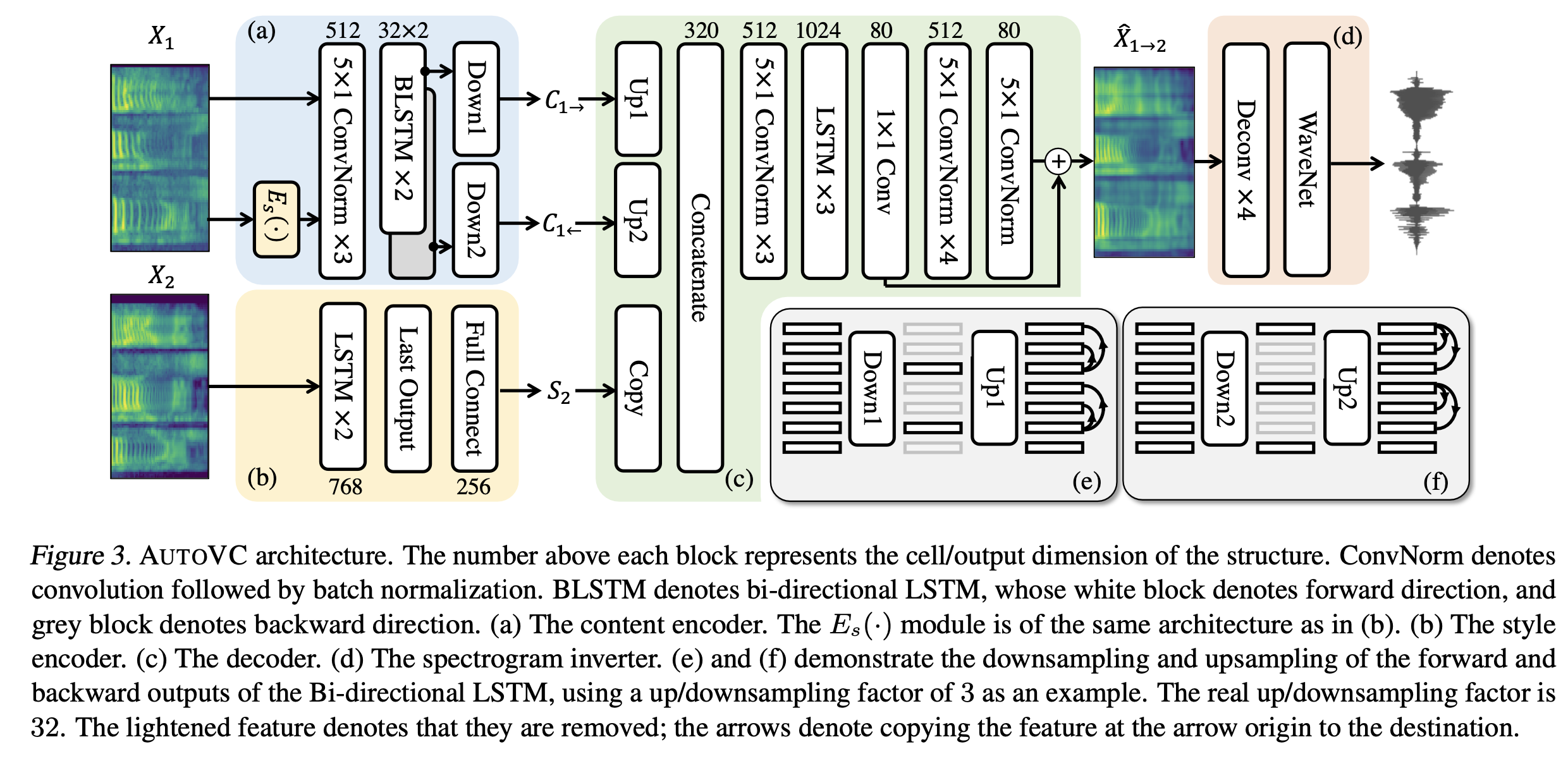
Speaker Encoder
speaker encoder의 목표는 같은 화자의 다른 발화들에서도 같은 임베딩을 만드는 것이다.
zero-shot cv를 위해서는 unseen한 화자들에서도 일반화가능한 임베딩을 적용하는 것이 필요하다. 그러므로 위 그림에서 (3)(b)처럼 speaker encoder는 cell 크기 768인 2개의 LSTM 레이어로 구성되어 있다. output에서 마지막 시간만 fc 레이어로 256차원으로 선택되었다.
speaker embedding의 결과는 256의 1벡터이다.
이는 GE2E loss로 pre-trained되었다.
- GE2E loss는 같은 화자의 다른 발화들 사이에서 임베딩 유사성을 최대화하고, 다른 화자들 사이에서 임베딩 유사성을 최소화한다.
Content Encoder
위 사진에서 3(a)처럼 content encoder에서 input은 화자 임베딩 과 합쳐진 의 80차원의 mel-spectrogram이다
합쳐진 피쳐들은 3개의 5x1 conv 레이어들에 입력된다.
채널의 수는 512이기에 output은 2개의 bidirectional LSTM 레이어들은 통과한다.
information bottleneck을 구성하는데 중요한 단계는, BLSTM의 foward와 backward ouput들이 32로 다운샘플링되는 것이다.
content embedding의 결과물은 2개의 32-by-T/32 matrices이다.
- 각각 로 표현된다.
Decoder
위 사진에서 3(c)에 해당하는 디코더
먼저 content, speaker 임베딩은 둘다 원래의 시간 해상도를 복구하기 위해 copying함으로써 업샘플링된다.
- 각각 로 표현된다.
업샘플링된 임베딩들은 합쳐지고 3개의 512채널을 가진 5x1 conv 레이어들에 입력된다. 이 이후에는 배치 정규화, ReLU 그리고 cell dimension 1024를 가진 3개의 LSTM레이어들을 통과한다. LSTM의 output들은 차원 80의 1x1 conv 레이어들에 투영된다. 이 투영의 output은 로 나타나는 변환된 speech의 초기 추정치이다.
마지막 변환 결과는 초기 추정치에 residual를 더함으로써 생성된다.
- [ Eq(10) ]
훈련동안 reconstruction loss는 초기와 마지막 reconstruction 결과들 모두에 적용된다.
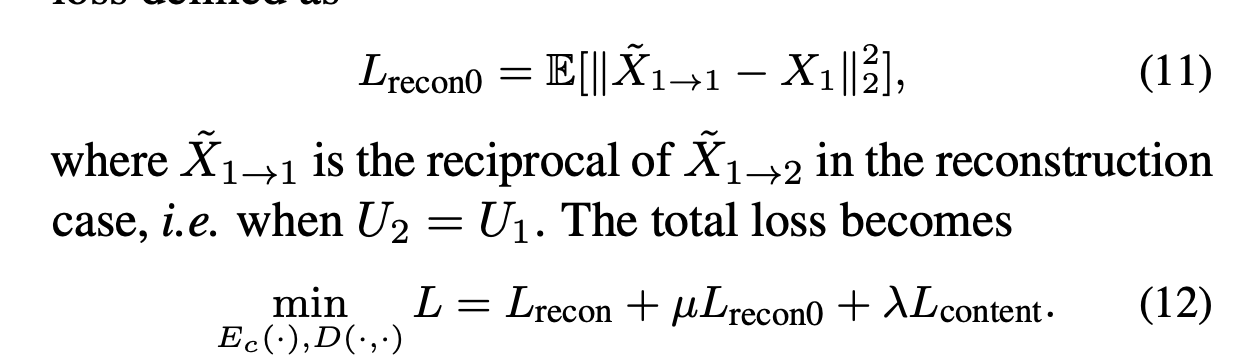
Total loss
[ Eq(12) ]
Spectrogram inverter
autoVC는 4개의 deconv 레이어들로 구성된 WaveNet 보코더를 적용한다.
공식적인 구현에서는 mel-spectrogram의 frame rate는 62.5Hz이고 speech waveform의 sampling rate는 16kHz이다.
pre-trained된 WaveNet vocoder를 사용했다.
