[Paper Review]
1.[DL/NLP] Improving Language Understanding by Generative Pre-Training
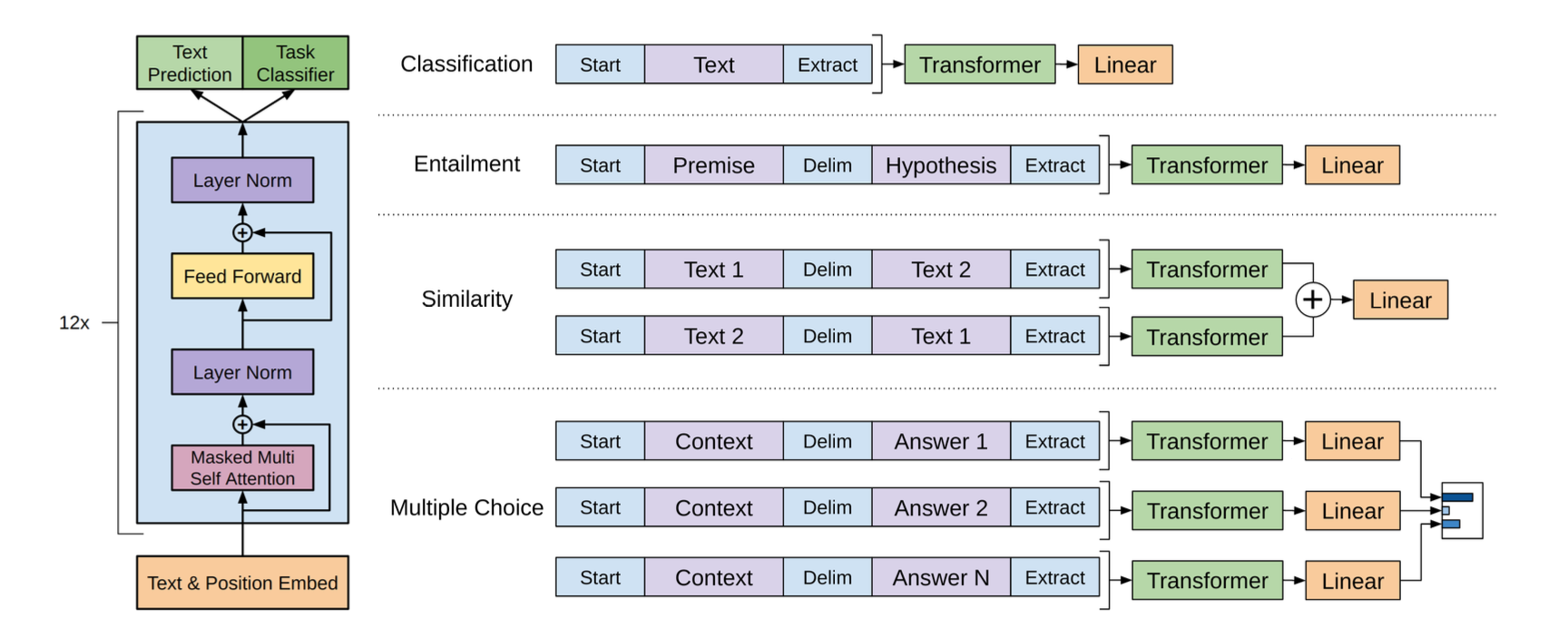
📄참고자료 Improving Language Understanding by Generative Pre-Training(논문 원본) https://kyujinpy.tistory.com/74 Abstract 자연어 이해는 텍스트 수반, 질문 답변, 의미론적 유사성 평가 및 문서 분류와 같은 광범위하고 다양한 작업으로 구성 라벨링 되지 않은 대규모 텍스트 ...
2.[DL/Audio] Audio Spectrogram Transformer
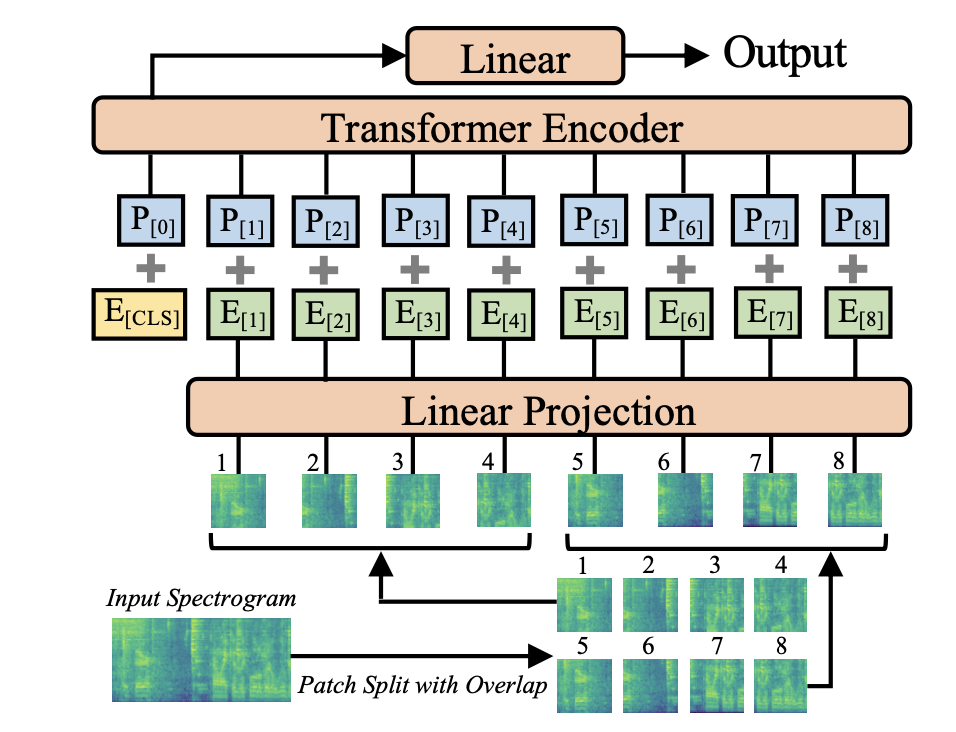
Abstract 지난 10년 동안 audio classifiaction에서 CNN이 주요하게 사용됐음 하지만 CNN에 대한 의존이 필요한지, 순전히 어텐션에만 기반한 신경망이 audio classification에서 좋은 성과를 얻기에 충분하지 않은지 불분명함 따라서 이 논문에서 convolution-free한, 순전히 attention-based인 ...
3.[DL/Audio] VQVC & VQVC+
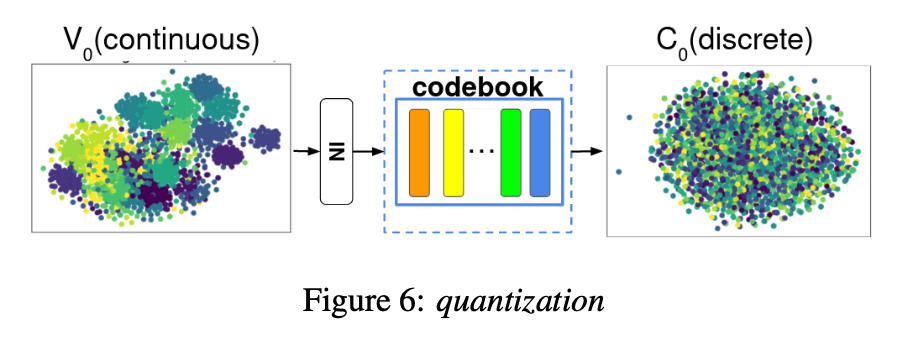
📄 참고 https://randomsampling.tistory.com/323 https://randomsampling.tistory.com/322 [원문 - VQVC] https://ieeexplore.ieee.org/document/9053854 [원문 - VQV
4.[DL/Audio] AUTOVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss

📄 [원문] https://arxiv.org/abs/1905.05879 Abstract non-parallel의 다대다 vc와 zero-shot vc를 수행하기 위해 GAN 그리고 CVAE가 새로운 해결책으로 등장했었다. 하지만 GAN의 training은 복잡하고 CVAE의 training은 간단하지만 GAN만큼의 좋은 성능을 내지 못한다. 따라서 이논...
5.[DL/AD]ANOMALY TRANSFORMER: TIME SERIES ANOMALY DETECTION WITH ASSOCIATION DISCREPANCY
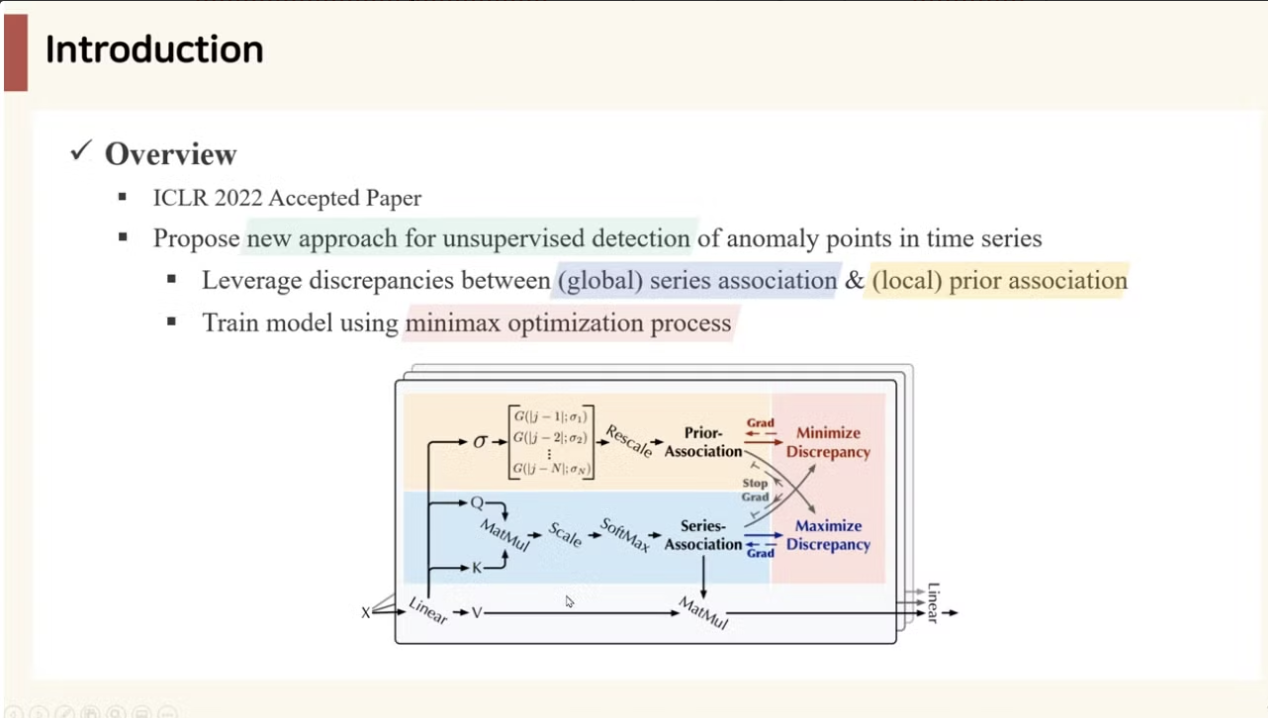
📄 참고https://www.youtube.com/watch?v=C3dphckvyn0📄 원문https://arxiv.org/abs/2110.02642v5시계열 이상 탐지는 복잡한 dynamic 특성을 다뤄야 하므로 기존의 pointwise(포인트별
6.[DL/Audio]HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
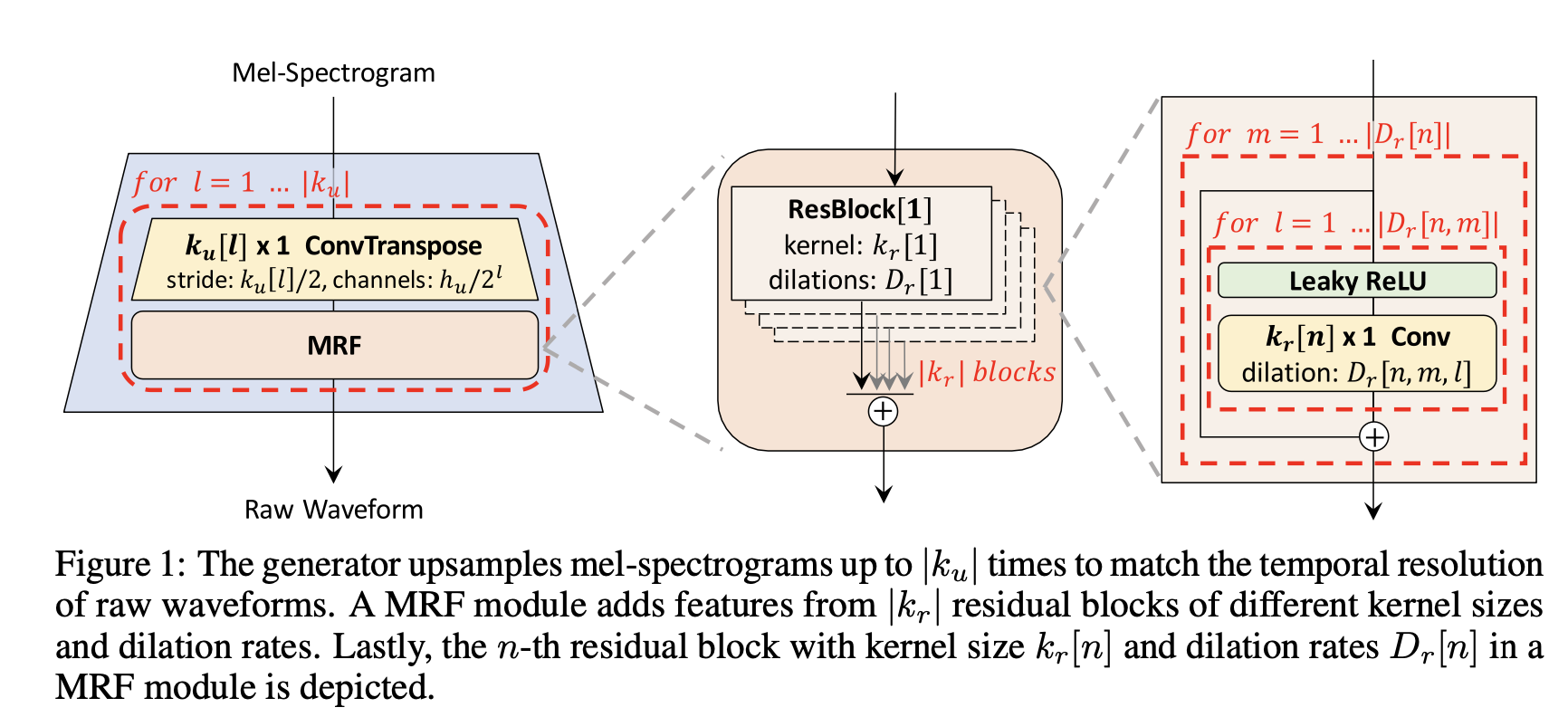
📄 원문https://arxiv.org/abs/2010.05646대부분의 음성 합성 모델의 2단계 파이프라인멜스펙토그램이나 linguistic feature 같은 low resolution intermediate representation 만듦intermed
7.[DL/XAI] "Exploring Explainability for Vision Transformers"

🔗 원문 링크 https://jacobgil.github.io/deeplearning/vision-transformer-explainability 1. Background 2020년에 등장한 여러 연구들은 Transformer를 컴퓨터 비전(CV) 분야에 본격적으로 도입하기 시작하였습니다. 그중에서도 의 Vision Transformer(ViT)와...
8.[DL/CV] Combining EfficientNet and Vision Transformers for Video Deepfake Detection
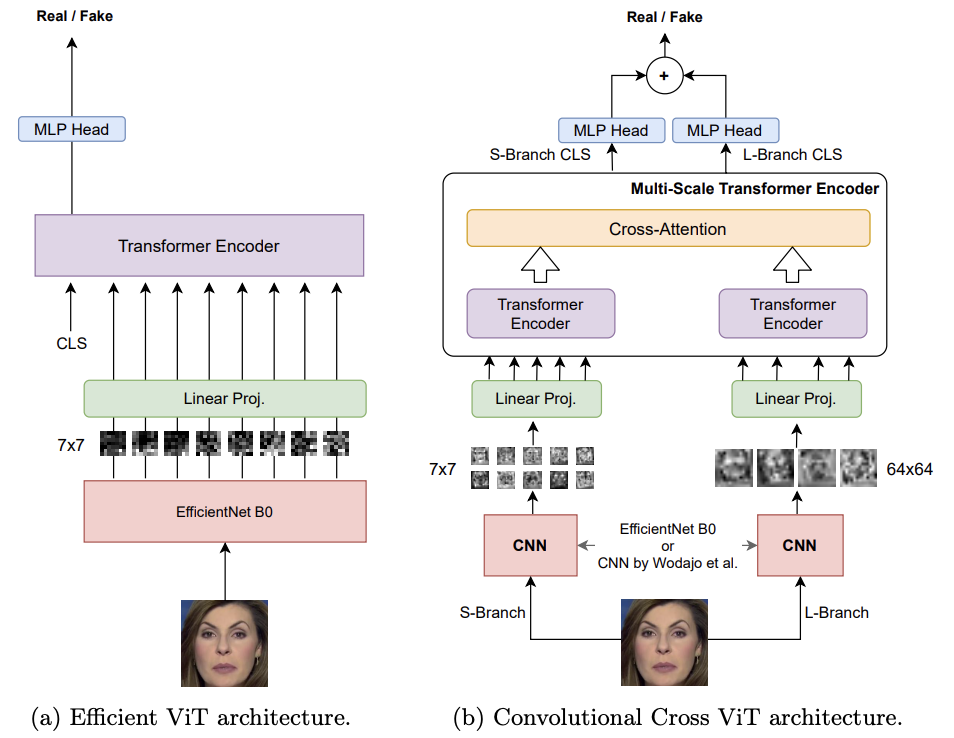
🔗원문 https://arxiv.org/pdf/2107.02612 📌github https://github.com/davide-coccomini/Combining-EfficientNet-and-Vision-Transformers-for-Video-Deepfake-