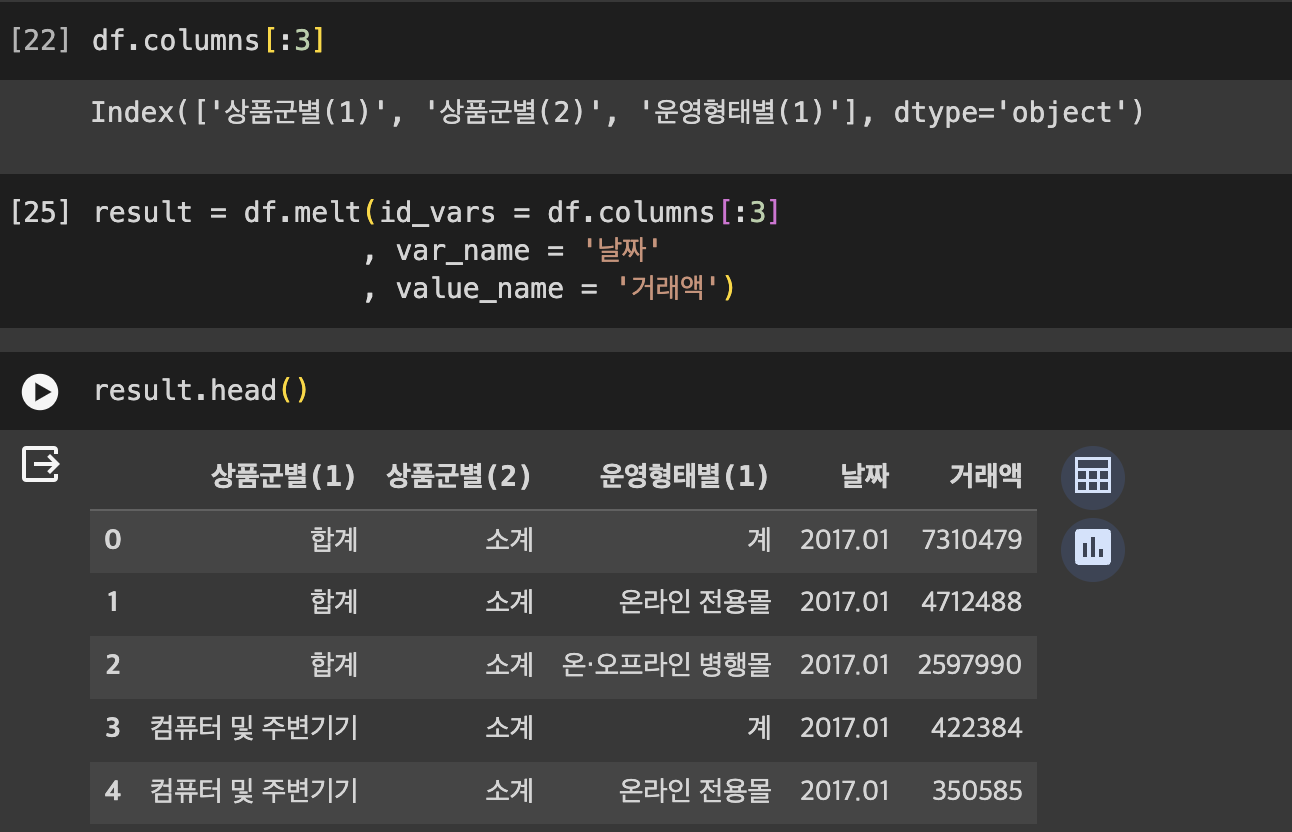
pd.melt()
pandas.melt(frame # 변경할 df
, id_vars=None # 유지할 컬럼
, value_vars=None # 변환할 컬럼
, var_name=None # 변환 후 생성되는 컬럼이름
, value_name='value' # 'value' 컬럼에 들어가는 값
, col_level=None
, ignore_index=True)pandas documentation에 명시된 melt의 파라미터다.
frame 자리엔 바꿀 df를 넣어주고, id_vars에는 ID 변수를 지정해준다.
melt는 ID 변수를 기준으로 원래 데이터셋에 있던 컬럼명들을 'variable' 컬럼의 값들로 위에서 아래로 길게 나열하고, 'value' 컬럼에 ID 변수와 variable에 있는 값대로 차례차례 넣어주는 식으로 작동한다.
value_vars는 'value' 컬럼에 들어가는 값을 지정해준다.

pd.pivot()
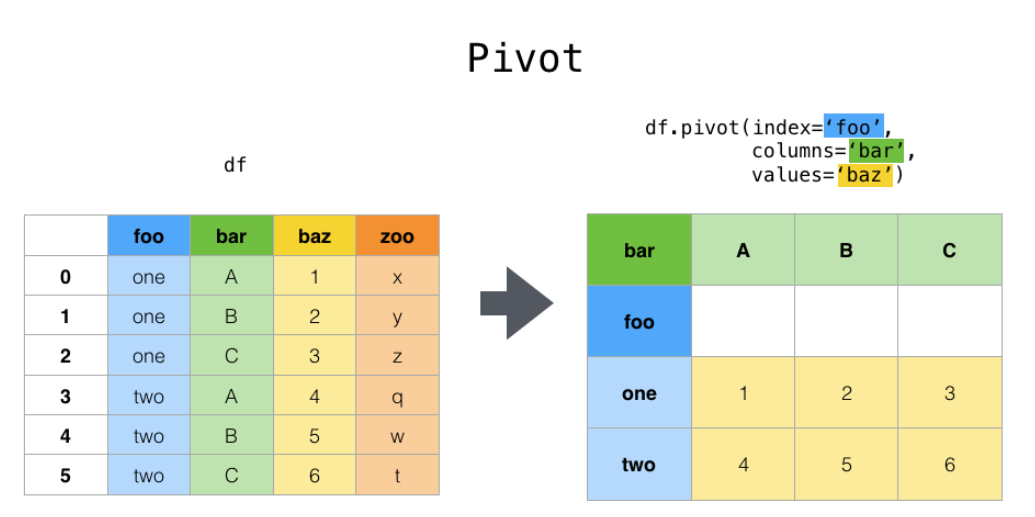
pivot()은 위처럼 melt()되거나 해서 여러 형식으로 뒤죽박죽인 데이터프레임을 구별하기 쉽게 바꾸고 싶을 때 사용한다.
df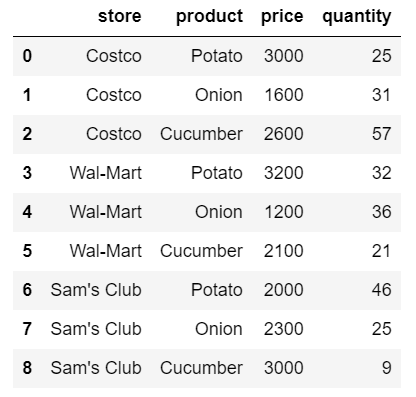
df에 index, column, value를 각각 지정해서 피봇해보자.
df.pivot(
index='product', # 인덱스 헹
columns='store', # 지정된 값을 열로 지정
values='Price') # 값을 지정
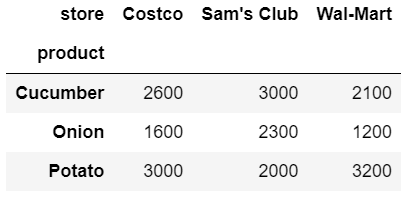
야채 이름과 야채를 파는 스토어가 교차하는 지점의 야채 가격들이 알맞게 들어가 있다.
-
추가
pivot()은 index 데이터와 columns나 values 데이터의 조합? 중 중복되는 게 있으면 에러가 뜬다. 그럴 땐 중복되지 않게 데이터프레임을 정제해주거나, pivot_table()을 써서 해결한다. -
피벗테이블은 데이터를 요약하고 분석하여 요약 데이터를 제공하는데 유용하다.
-
pivot()이 인덱스와 행, 열을 하나하나 지정해서 데이터를 재구조화/보기 좋게 구축화하는 것이라면,
-
melt()는 ID 변수를 하나 혹은 여러 개 지정해서 그것들을 기준으로 나머지 열의 이름과 열 값들을 아래로 쭉 나열하여 재구조화한다. melt()를 쓰면 얇고 긴 데이터프레임이 만들어 진다.
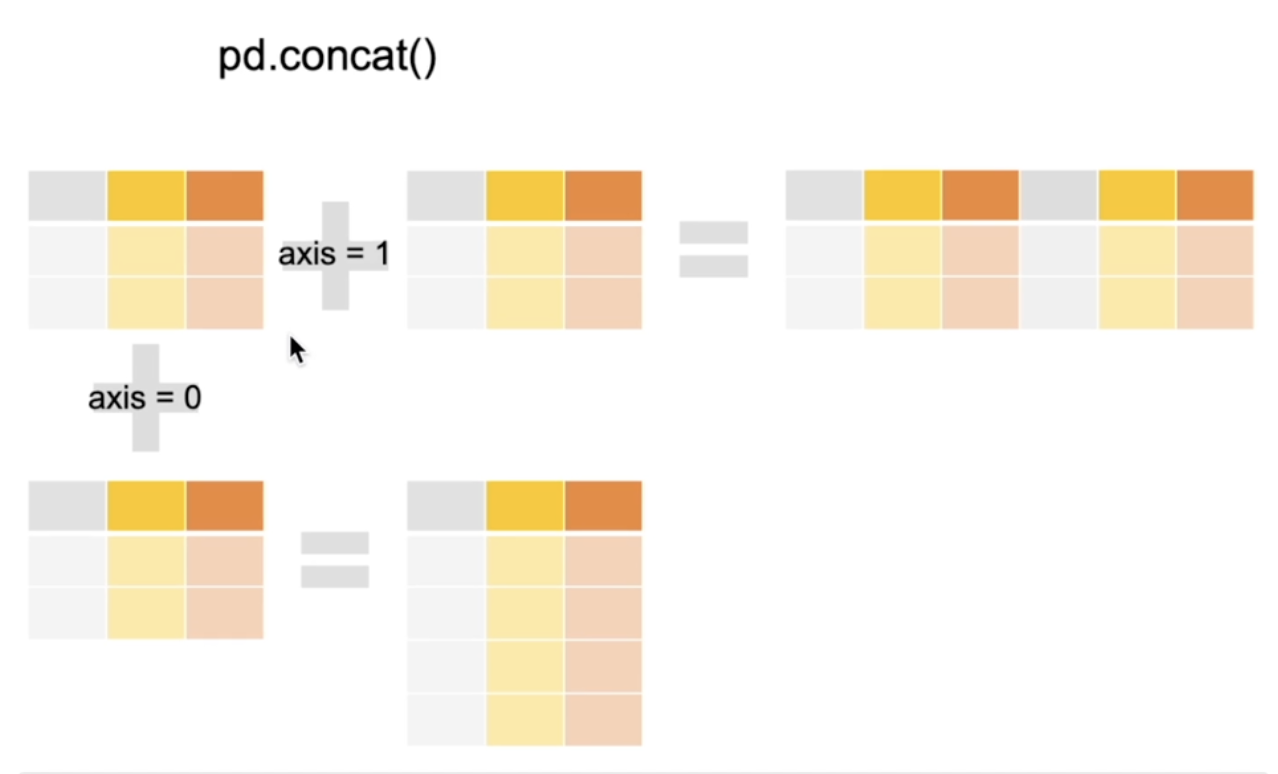
pd.concat()
- axis 개념 참고용

뭐가 됐든 데이터분석가