범주형 변수 이해하기
1. 범주형 변수의 유형 및 특징
데이터분석과 머신러닝의 현장에서 자주 마주치는 중요한 요소 중 하나
이러한 변수는 주로 '문자열 타입'으로 표현되며, 데이터 프레임에서 이들의 유형은 'object'또는 'category'로 분류됩니다.
 이미지출처: 데이콘
이미지출처: 데이콘
단순한 수치를 넘어 데이터에 내재된 의미 혹은 카테고리를 부여
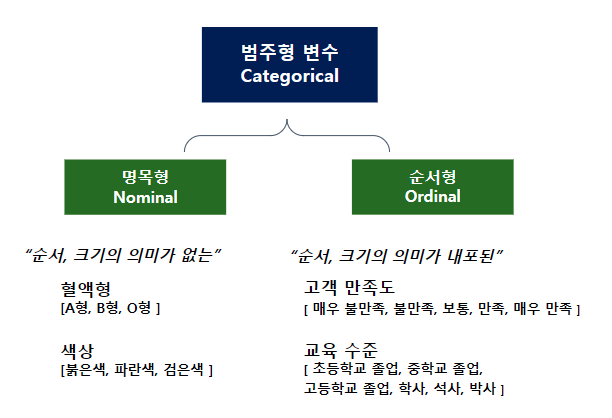
크게 명목형과 순서형으로 나뉜다
명목형 : 서로 비교 가능한 등급이나 순서, 크기의 의미가 없는 독립적인 범주
순서형 : 범주 사이에 명확한 순서가 있어 등급을 나타낼 수 있음
이러한 범주형 변수들을 효과적으로 처리하기 위해서는 데이터 분석과 모델링 과정에서 이들을 수치형 데이터로 변환하는 인코딩 과정이 필수적!
범주형 변수를 인코딩한다?
범주형 변수를 인코딩하는 이유는 대부분의 머신러닝 알고리즘이 숫자 데이터를 필요로 하기 때문입니다. 범주형 변수는 데이터의 명목형 값(예: "red", "blue", "green")이나 순서형 값(예: "low", "medium", "high")을 나타내는 데 사용됩니다. 이러한 값을 직접 사용할 수 없기 때문에, 이를 숫자로 변환하여 모델이 이해할 수 있도록 만드는 과정이 필요합니다.
- 모델의 입력으로 사용하기 위해:
많은 머신러닝 알고리즘(예: 선형 회귀, 로지스틱 회귀, SVM 등)은 숫자형 데이터를 필요로 합니다. 범주형 변수는 이를 직접 처리할 수 없으므로, 이를 숫자로 변환해야 합니다.
- 거리를 계산하기 위해:
KNN(최근접 이웃 알고리즘)과 같은 거리 기반 알고리즘은 데이터 간의 거리를 계산할 때 숫자형 데이터가 필요합니다. 범주형 변수를 숫자로 변환하지 않으면 이러한 거리를 올바르게 계산할 수 없습니다.
- 성능 향상을 위해:
적절한 인코딩은 모델의 성능을 향상시킬 수 있습니다. 예를 들어, 순서형 변수는 그 순서를 반영하는 방식으로 인코딩하여 모델이 이를 더 잘 이해할 수 있도록 할 수 있습니다.
- 표준화 및 정규화 가능:
숫자로 변환된 데이터는 표준화(Standardization) 및 정규화(Normalization)를 통해 스케일을 조정할 수 있습니다. 이는 모델 훈련 시 특정 변수의 값 범위가 다른 변수보다 크거나 작아서 발생할 수 있는 문제를 방지합니다.
인코딩 방법
- 레이블 인코딩(Label Encoding):
각 범주형 값을 고유한 숫자로 변환합니다. 예를 들어, "red" -> 0, "blue" -> 1, "green" -> 2.
장점: 간단하고 빠릅니다.
단점: 값의 순서가 의미를 가질 수 있어 순서가 없는 명목형 변수에는 적합하지 않습니다.
- 원-핫 인코딩(One-Hot Encoding):
각 범주형 값을 이진 벡터로 변환합니다. 예를 들어, "red" -> [1, 0, 0], "blue" -> [0, 1, 0], "green" -> [0, 0, 1].
장점: 값 간의 순서가 없다는 것을 반영할 수 있습니다.
단점: 범주가 많을 경우 차원의 저주(Curse of Dimensionality)가 발생할 수 있습니다.
- 임베딩(Embeddings):
주로 딥러닝에서 사용되며, 범주형 변수를 밀집 벡터(Dense Vector)로 변환합니다. 이 방법은 특히 자연어 처리(NLP)에서 유용합니다.
장점: 고차원 데이터를 저차원으로 변환하여 효율성을 높입니다.
단점: 복잡하고 학습이 필요합니다.
왜 굳이 '명목형'(Nominal), '순서형'(Ordinal) 구분을 해야 할까요
범주형 변수를 인코딩한다는 것은 모델이 범주형 변수를 이해하고 활용할 수 있도록 수치형 변수로 변환하는 것을 의미합니다.
이를 통해 모델은 범주형 변수에 대한 패턴이나 관계를 파악하고 예측에 활용할 수 있습니다.
범주형 변수가 '명목형'인지 '순서형'인지 알아야 하는 이유는 모델이 인지할 수 있는 수치형 변수로 변환하는 '인코딩(Encoding)'을 하는 방법이 달라져야 하기 때문입니다.
