데이터를 보다보면 가끔 한 셀 안에 여러개의 값이 ;으로 구분된 값으로 들어가있는 경우가 있다.
오늘은 이런 중첩된 데이터에서 유니크한 값으로 뽑아보는 걸 배워봤다
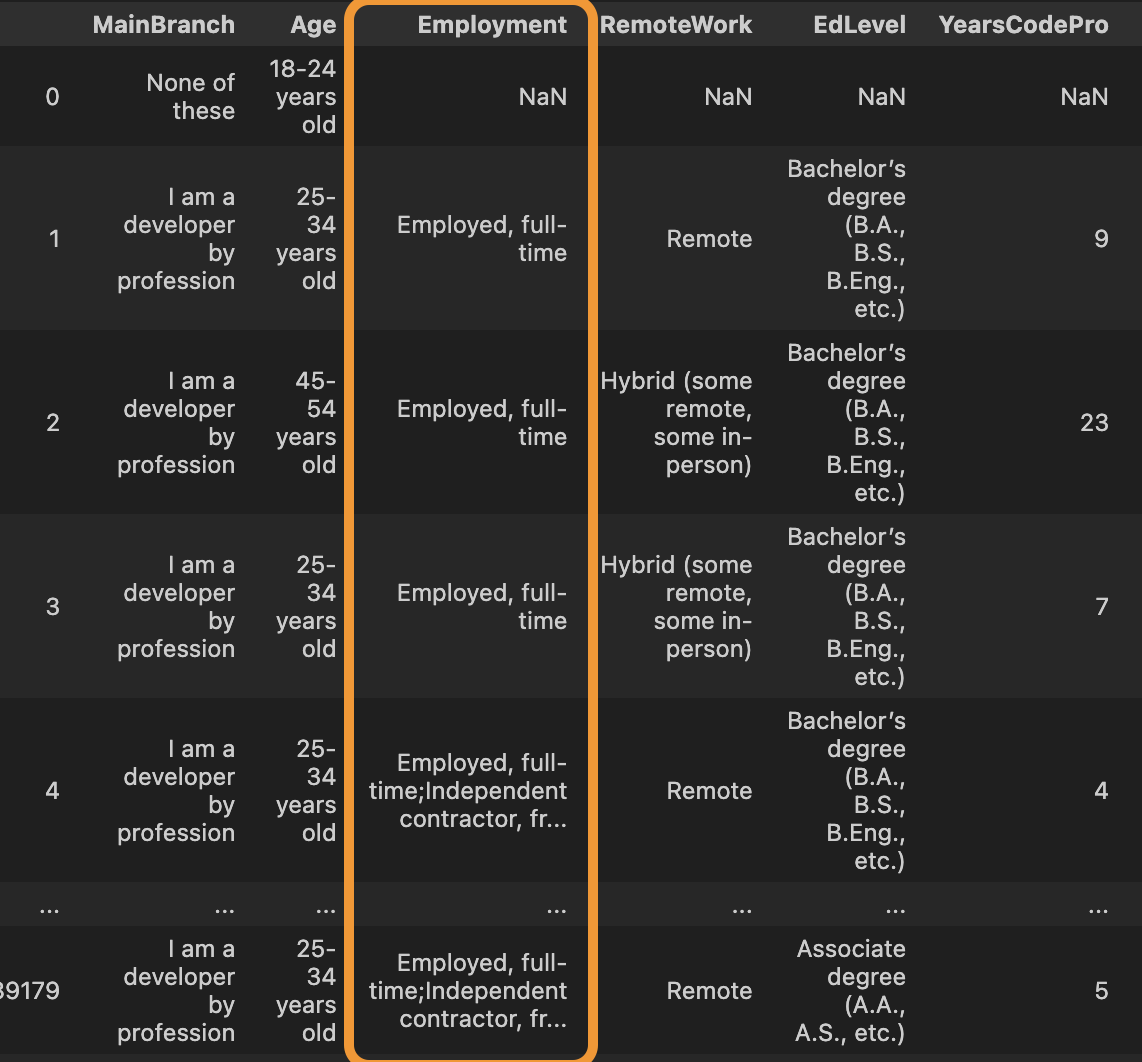 위 이미지와 같이 Employment데이터가 ;에 의해 여러개의 값이 중첩되어있는걸 확인해볼 수 있다.
위 이미지와 같이 Employment데이터가 ;에 의해 여러개의 값이 중첩되어있는걸 확인해볼 수 있다.
여기서 유니크한 각 값을 추출해볼것임!
01.value_count()
devs_df['Employment'].value_counts()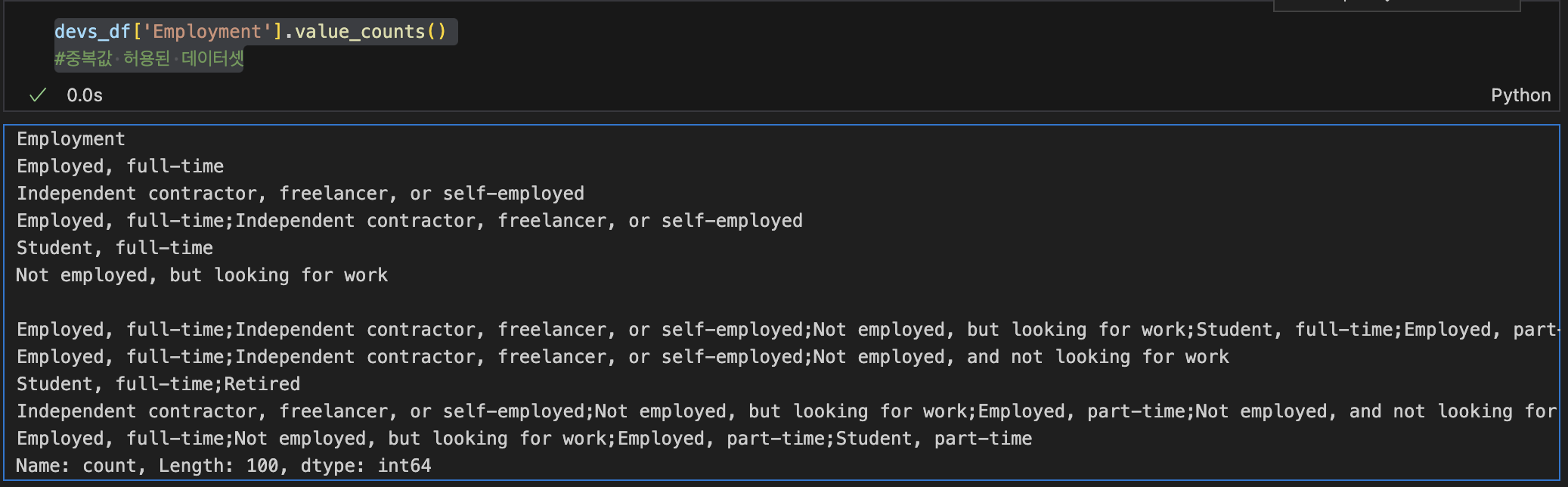
02.split_list
split_employment_lists = devs_df['Employment'].dropna().str.split(';')먼저 입력된 중첩된 시리즈에서 결측값을 제외하고, 각 요소를 세미콜론(';')을 기준으로 분할하여 분할된 리스트를 만든다. dropna()는 결측값을 제거하는 메서드이며, str.split(';')는 각 요소를 세미콜론으로 분할한다는 뜻이다.
03.평탄화(flatten)
flattened_employment_list = [val for sublist in split_employment_lists for val in sublist]
flattened_employment_list-
split_employment_lists는 중첩된 리스트로 구성되어 있음. 이 중첩된 리스트는 다양한 고용 형태를 각각의 요소로 포함
-
[val for sublist in split_employment_lists for val in sublist]는 리스트 컴프리헨션을 사용하여 중첩된 리스트를 평탄화하는 과정을 수행
-
for sublist in split_employment_lists는 split_employment_lists에 있는 각각의 하위 리스트(sublist)에 대해 반복
-
for val in sublist는 각 하위 리스트의 요소에 대해 반복
-
따라서 이중 리스트의 각 요소가 flattened_employment_list에 추가
이렇게 함으로써, flattened_employment_list에는 split_employment_lists에 포함된 모든 요소가 평탄화된 형태로 포함하게 된다. 이렇게 하면 중첩된 리스트를 단일 리스트로 변환할 수 있다.
자주쓰는 코드는 함수로 만들어 버릴 수도...?!
def get_flattened_list(nested_series):
split_list = nested_series.dropna().str.split(';')
return [val for sublist in split_list for val in sublist]