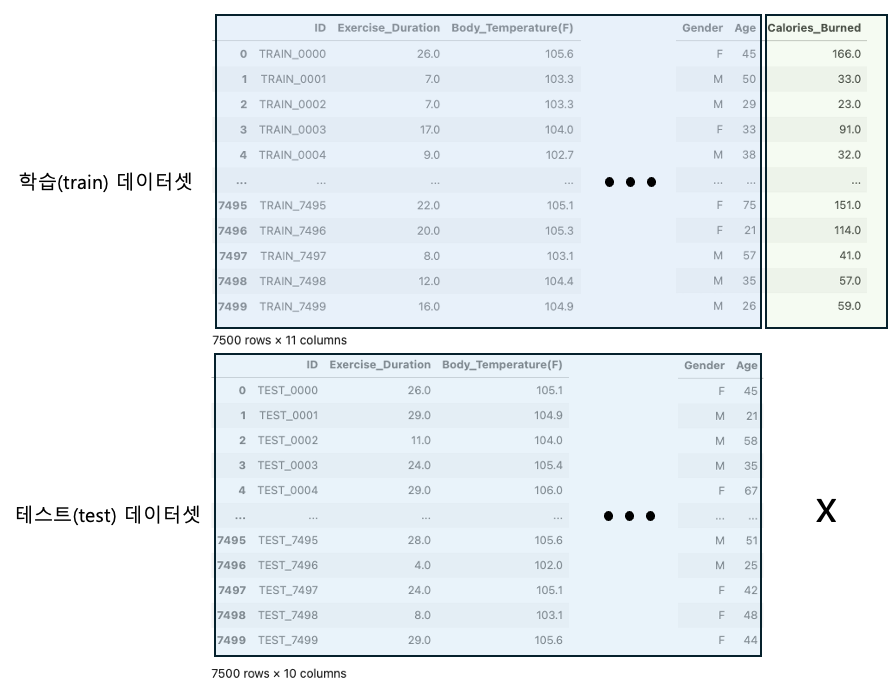
학습데이터와 테스트데이터
핵심 개념
지도학습
정답이 포함된 문제집으로 선생님이 학생을 가르치는 것 처럼, 머신러닝 모델도 정답이 있는 데이터로 학습을 한다. 그리고 이 학습을 바탕으로 새로운 문제에 대한 답을 찾는다
학습데이터셋
이는 모델의 교과서라고 할 수 있다. 각 데이터 포인트(예: 각각의 사진, 집에 대한 정보 등)는 정답또는 target이라는 답을 포함한다. 모델은 이 데이터를 통해 문제(특성)와 답(타겟)사이의 관계를 배운다
테스트 데이터 셋
학습이 끝난 후, 모델의 성능을 보는 단계이다. 이 데이터셋은 모델이 전에 본 적 없는 새로운 문제들로 구성되어 있고, 여기에는 답이 포함되어 있지 않다. 이를 통해 우리는 모델이 배운 지식을 얼마나 잘 적용하는지 평가할 수 있다.
머신러닝 주요 용어
Target Variable(목표변수) 예측하고자 하는 변수 '종속변수' 혹은 '정답지'
Independent Variable(독립변수) Target Variable을 예측하기 위해 사용되는 변수 '설명변수'라고도 불리며, 모델의 입력으로 사용
Feature(특성) 모델 학습에 직접 사용되는 독립변수들을 지칭한다. 이 변수들로 구성된 데이터셋을 'Feature Set'이라고 한다
Irrelevant Variables(불필요한 변수) Target Variable을 예측하는데 도움이 되지 않는 변수 이러한 변수는 데이터 전처리나 특성 공학 단계에서 제거되곤 한다

뭐가 됐든 데이터분석가