연속형 변수
연속형 변수는 무한하고 가산할 수 없는 값들로 구성됩니다. 이는 변수가 취할 수 있는 값이 연속적인 범위 내에 있다는 것을 의미합니다. 예를 들어, 사람의 키, 무게, 온도, 거리 등이 이에 해당합니다. 연속형 변수는 일반적으로 실수로 표현되며, 두 값 사이에는 항상 또 가른 값이 존재할 수 있다.
회귀 분석에서 연속형 변수는 종종 종속변수(예측하고자 하는 변수)로 사용됩니다. 예를 들어, 집의 크기(독립변수)가 주택가격(연속형 종속 변수)에 어떤 영향을 미치는지 분석할 수 있습니다.
이산형 변수
이산형 변수는 셀 수 있는 분리된 값들로 구성됩니다. 이 변수들은 일반적으로 정수로 표현되며, 두 값 사리에 다른 값이 존재하지 않습니다. 예를 들어, 사람의 자녀 수, 학급의 학생 수, 제품의 결함 수 등이 이산형 변수에 해당됩니다.
회귀 분석에서 이산형 변수는 독립 변수로 사용될 때가 많습니다. 예를 들어, 광고 횟수(이산형 독립 변수)가 판매량(연속형 종속 변수)에 미치는 영향을 분석할 수 있습니다. 이산형 변수는 때때로 '범주형 변수'로도 간주될 수 있습니다.
연속형변수의 예시
-
연속형 변수의 예시
물의 온도 / 몸무게 / 키 -> 연속적으로 변할 수 있다 -
이산형 변수의 예시
학급에 있는 학생의 수 / 성별 / 나이 -> 셀 수 있는 값
결론적으로
연속형 변수는 측정하는 값이 연속적으로 변할 수 있으며, 정밀한 측정이 가능한 경우에 사용됩니다. 반면, 이산형 변수는 개별적으로 셀 수 있는 값으로 구성되어 있으며, 특정한 수치만을 가질 수 있습니다.
회귀분석에서 변수 유형을 이해하는 것은 모델의 설계와 해석에 있어 매우 중요합니다. 변수의 유형에 따라 데이터를 처리하고 분석하는 방법이 달라지며, 이는 결과의 정확성과 해석 가능성에 직접적인 영향을 미칩니다.
데이터 스케일링과 정규화
데이터 표준화란
StandardScaler는 특성의 평균을 0, 분산을 1로 조정하여 모든 특성이 동일한 스케일을 갖도록 변환하는 방법입니다.
언제, 왜 사용하는가
StandardScaler를 쓰는 이유는, 우리가 다루는 데이터들의 크기가 너무 다를 때 발생하는 문제를 해결하기 위해서입니다.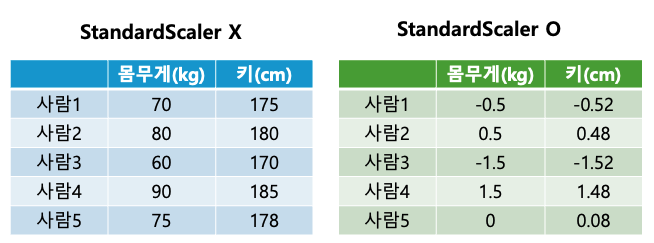
- 왼쪽 표에서 몸무게는 60kg에서 90kg사이고, 키는 170cm에서 185cm사이로 측정되어있다. 이러한 데이터를 기계학습 모델에 직접 적용하면, 더 큰 숫자를 갖는 특성('키')이 모델에 더 큰 영향을 미칠 위험이 있다. 모델은 단순히 숫자의 크기 때문에 한 특성을 더 중요하게 여길 수 있고, 그 결과 학습이 왜곡될 수 있다.
- 오른쪽 표는 StandardScaler를 적용하여 몸무게와 키 데이터를 표준화한 결과를 보여준다. 표준화는 각 특성의 평균을 0으로, 표준편차를 1로 맞추어줌으로써 모든 특성이 동일한 척도를 갖게 한다. 오른쪽 표에서는 모든 값이 -1.5부터 1.5사이로 범위가 좁아졌다. 결과적으로 데이터의 모든 특성은 모델 학습에 동등하게 기여할 수 있게 되며, 이는 더 공정하고 균형잡힌 학습결과를 가져다준다.
데이터 스케일링과 정규화
장점
- 특성 간 스케일 차이를 감소시켜, 모델이 각 특성을 좀 더 균등하게 취급할 수 있도록 도와준다
- 데이터를 정규분포에 가깝게 만들어, 많은 머신러닝 알고리즘의 기본 가정에 부합하게 해준다
- 표준화된 특성은 최적화 알고리즘의 수렴을 빠르고 효율적으로 만들어, 모델 학습 과정의 성능을 향상시켜준다.
단점
- 이상치가 있는 데이터에 적용할 때, 이상치들이 결과를 왜곡시킬 수 있습니다.
- 데이터를 표준화하는 과정에서 특성의 원본 분포가 변경되어, 특정 분석에 필요한 데이터의 구조적 특성이나 본질적인 정보가 감소할 위험이 있습니다.
수식
각 특성 X에 대해, StandardScaler는 다음과 같이 계산된다.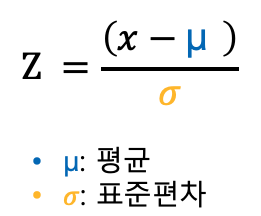
주의사항
이상치가 포함된 데이터를 표준화할 때는 StandardScaler사용에 주의해야합니다. 이상치는 평균과 표준편차에 큰 영향을 미쳐, 데이터의 전반적인 스케일 변환 결과를 왜곡할 수 있다.
데이터 표준화
사이킷런 라이브러리의 StandardScaler를 이용하여 데이터를 표준화하는 과정을 보여준다. 표준화는 데이터의 특성들을 평균이 0이고 표준편차가 1이 되도록 변환하는 과정
scaler.fit(data)fit메서드에서는 데이터에 대한 평균과 표준편차를 계산한다. 이 계산된 평균과 표준편차는 이후 데이터를 표준화하는데 사용된다. 여기서 data는 표준화할 원본 데이터를 의미
scaler_data = scaler.transform(data)transform메서드는 앞서 fit메서드에서 계산된 평균과 표준편차를 사용하여 데이터를 표준화한다. 즉, 각 특성의 값에서 평균을 빼고, 그 결과를 표준편차로 나누어준다. 이렇게 변환된 데이터는 scaler_data에 저장된다.
(1) StandardScaler 객체 생성
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler(2) 데이터 표준화
scaler.fit(data)
scaled_data = scaler.transform(data)
scaled_data(3) 표준화된 데이터를 DataFrame으로 변환
scaled_data_df = pd.DataFrame(scaled_data, columns=['몸무게_scaled', '키_scaled'])
scaled_data_df(4) 표준화된 데이터 평균과 표준편차 계산
import numpy as np
print(scaled_data_df['몸무게_scaled'].sum())
print(scaled_data_df['몸무게_scaled'].std())
print(scaled_data_df['키_scaled'].sum())
print(scaled_data_df['키_scaled'].std())로그변환
로그변환?
로그 변환은 데이터의 범위를 조정하고 왜곡된 분포를 개선하기 위해 사용되는 기법입니다. 특히 데이터 값 사이에 큰 차이가 있거나, 한쪽으로 치우친 분포를 보일 때 이 변환 방법을 사용하곤 한다.
로그 변환의 목적
로그 변환의 주된 목적은 데이터를 변환하여 분석이나 모델링을 더 효과적으로 수행할 수 있도록 만드는 것 입니다. 이 변환은 데이터의 크기 차이를 줄여서, 모든 데이터 포인트가 분석에 거의 동등한 영향을 미치도록 도와줍니다.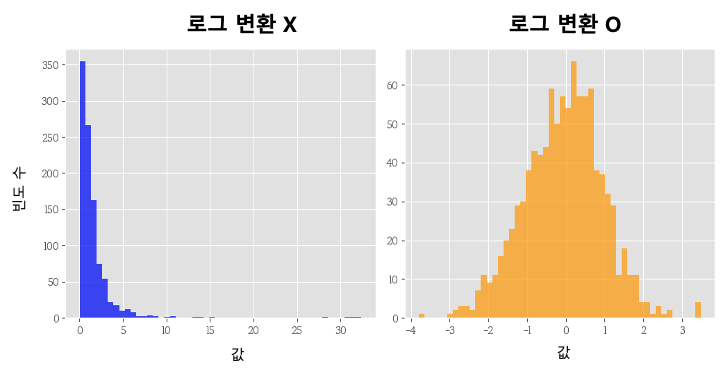
-
로그 변환은 특히 데이터가 정규 분포를 따르지 않고, 특정 방향으로 치우친 비대칭 분포를 보일 때 유용합니다. 변환을 통해 데이터는 보다 정규 분포에 가까워지며, 이는 통계적 분석과 머신러닝 모델에서 중요한 가정에 부합하게 만들어 줍니다.
-
로그변환은 언제, 왜 사용하는가?
로그변환은 데이터의 분포가 한쪽으로 심하게 치우쳐 있거나, 극단적인 값이 존재할 때 사용됩니다. 예를 들어, 소득, 인구수, 일부 생물학적 측정값 등은 오른쪽으로 긴 꼬리를 가진 분포를 보일 수 있습니다.
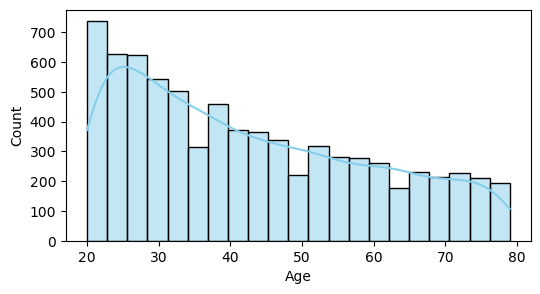
로그 변환전 분포 확인
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(6, 3))
sns.histplot(train['Age'], kde=True, color="skyblue")
plt.show()