2. socket address structures
대부분의 socket 함수들은 매개변수로 socket address structure의 포인터를 요구
1. IPv4 Socket Address Structure
sockaddr_in 구조체
#include <netinet/it.h>
struct in_addr{
in_addr_t s_addr; //32bit IPv4 address
};
//sockaddr 구조체에서 sa_family가 AF_INET인 경우에 사용하는 구조체
struct sockaddr_in {
uint8_t sin_len; //length of stucture(16)
sa_family_t sin_family; //AF_INET
in_port_t sin_port; //16bit TCP or UDP port number
//network byte ordered
struct in_addr sin_addr; //32bit IPv4 address
//network byte ordered
char sin_zero[8]; //전체 크기를 16비트로 맞추기 위한 dummy
}-
sin_len은 4.3BSD-Reno에서 추가되었다. 이전에는 첫번째 멤버는 sin_family였다.
Posix.1g에는 이 멤버를 필요로 하지 않는다. -
sin_len filed가 존재하더라도 이 멤버를 설정하거나 조사할 필요는 없다.
하지만 routing sockets(라우팅 소켓)을 사용할때는 다양한 프로토콜에서 socket address structure을 다루는 것은 routine에 의해 커널에서 이루어진다.
프로세스에서 커널로 socket address structure을 통과시키는 함수는 4개(bind, connect, sendto, sendmsg)
모두 Berkeley derived implementation에서 구현된 sockargs 함수를 거친다.
이 함수는 socket address structure를 프로세스로부터 복사하고, 명시적으로 sin_len 멤버를 위의 4개의 함수에서 매개변수로 받은 구조체의 길이로 설정한다.
커널에서 프로세스로 socket address structure를 통과시키는 함수는 5개(accept, recvfrom, recvmsg, getpeername, getsockname)
모두 프로세스로 반환하기 전에 sin_len 멤버를 설정(set)한다.
문제점
보통 socket address structure에 대한 길이 멤버를 네트워크 구현이 지원을 해주는지에 대한 간단한 컴파일 타임 테스트가 존재하지 않는다.
IPv6 구현들을 socket address structure이 길이 멤버를 가지고 있는지에 대한 SIN6_LEN의 정의가 필요함을 볼 수 있다.
몇몇 IPv4 구현들은 컴파일 타임에 사용할 수 있는 socket address structure의 길이 필드를 어플리케이션에게 제공해준다. 이러한 특징은 오래된 프로그램에 호환성 제공
routing
라우팅 코드는 네트워킹 하위 시스템 내의 모든 패킷 흐름을 제어함
지정된 목적지 주소를 가진 패킷이 다음에 보내져야하는 곳을 결정
routing sockets
routing table을 제어하는데 사용
-
Posix.1g은 오직 세가지 멤버만 필요: sin_family, sin_addr, sin_port
POSIX-compliant implementation에서 socket address structure의 추가 멤버를 정의하는 것이 가능하며, Internet socket address structure에서도 보통 가능하다.
대부분의 구현들은 socket address structure가 최소 16바이트 이상의 크기를 가지게 하기 위해서 sin_zero 멤버를 추가한다. -
POSIX 데이터 타입 s_addr, sin_family, sin_port 멤버에 대해서 알아보자.
in_addr_t 데이터 타입은 최소 32비트 이상의 unsigned integer
in_port_t는 최소 16비트 이상의 unsigned integer
sa_family_t는 아무 unsigned integer
길이 멤버를 지원하면 sa_family_t는 보통 8비트의 unsigned integer
길이 멤버를 지원해주지 않으면 16비트의 unsigned integerPOSIX datatype

-
u_char, u_short, u_int, u_long 데이터타입은 모두 unsigned
이들은 모두 이전의 호환에서 제공된다. -
IPv4 address와 TCP/UDP port는 반드시 network byte order에 따라 structure에 저장되어야한다. 우리는 이 멤버들을 사용할 때 이 사항을 반드시 알고 있어야한다. Section 3.4에서 호스트의 바이트 순서와 네트워크의 바이트 순서의 차이점을 볼 것이다.
컴퓨터에서는 저장되는 데이터의 최소 단위가 1바이트이기 때문에 데이터를 그대로 읽어서 낮은 주소에서 높은 주소 순서로 저장하느냐(마치 왼쪽부터 읽는 것처럼), 데이터를 오른쪽에서부터 읽어서 메모리에 저장하느냐 등 순서에 따른 방식이 나뉘진다.
BYTE + Order(순서) = 바이트 오더 라고 하고, 바이트 오더에는 빅엔디안 방식과 리틀 엔디안 방식이 있다.
- big endian
큰 단위가 앞에 나오는 것을 말합니다. - little endian
작은 단위가 앞에 나오는 것을 말해요 - middle endian
두 경우에 속하지 않거나, 둘을 모두 지원하는 것을 말합니다.
- 32비트의 IPv4 address는 접근 두가지 방법
ex) 만약 serv가 Internet socket address structure로 정의되어있으면, serv.sin_addr는 32비트의 IPv4 address를 in_addr structure로 참조하게 된다.
반면에 serv.sin_addr.s_addr은 같은 32비트의 IPv4 address를 in_addr_t로 참조하게 된다.(in_addr_t는 보통 32bit의 unsigned integer)
우리는 반드시 IPv4 address 참조를 정확히 해야한다.(특히 함수의 매개변수로 쓸 때)
왜냐하면 컴파일러는 이 구조체들을 integer와는 다르게 통과시키기 때문이다.
sin_addr 멤버가 구조체인 이유와 in_addr_t만 쓰지 않는 이유
옛날부터(전통적으로) 그래왔기 때문, 초기 release(4.2BSD)들은 in_addr 구조체를 다양한 구조체들의 union으로 정의했다. 그 이유는 32비트의 IPv4 주소안의 16-bit 값에 각각 접근이 가능하도록 하기 위해서이다. 이 값들은 class A, B, C 주소들과 함께 주소의 적절한 바이트들을 가지고 오도록 하기 위해 사용되었다. 그러나 subnet의 등장과 함께 이런 다양한 address class들이 사라지고 classless address들이 나오게 되었으며, union의 필요성이 사라지게 되었다.
subnet
클래스 단위로 네트워크를 분류하다보니, 어떤 기업에서는 적은 양의 호스트 주소가 필요한데, B class 네트워크를 할당받아서 IP주소에 여유가 생기게 되고, 어떤 기업에서는 많은 양의 호스트주소가 필요한데, C class 네트워크를 할당받아서 IP주소가 부족해지는 현상이 생기게된다.
따라서 클래스로만 네트워크를 분류하는것은 비효율적이라는 결론이 나오고 좀 더 적절한 단위로 네트워크를 분해해야할 필요성이 생기게 되엇 subnet이 개념이 등장
subnet이란 하나의 네트워크가 분할되어 나눠진 작은 네트워크이다.
오늘날의 대부분의 시스템들은 union을 사용하지 않고 단지 in_addr_t 멤버 하나만 가지고 있는 in_addr 구조체만 사용하게 되었다.
-
sin_zero 멤버는 사용되지 않지만 구조체내에서 항상 0으로 채워진다. 관습에따라 우리는 sin_zero 멤버뿐만아니라, 나머지 구조체 멤버를 채우기전에 0으로 초기화한다.
비록 이 구조체를 사용할 때 대부분은 이 멤버가 0이될 필요가 없지만, non-wildcard IPv4 address를 bind할 때 이 멤버는 반드시 0이 되어야한다. -
Socket address structure들은 주어진 호스트 상에서만 사용된다. 비록 특정한 멤버들이 통신하는데 사용된다고 하더라도 구조체 그 자체는 다른 호스트들과 통신하는데 사용되지 않는다.
Generic Socket Address Structure
#include <sys/socket.h>
struct sockaddr {
uint8_t sa_len;
sa_family_t sa_family; //address family: AF_xxx value
//주소체계를 구분하기 위한 변수, 2byte
char sa_data[14]; //protocol-specific address
//실제 주소를 저장하기 위한 변수
}- 일반적인 소켓 주소 구조체의 이름은 sockaddr이다.
- 소켓 주소 구조체는 항상 socket()Function에 Pass by Reference 방식으로 전달되는데, (포인터 타입으로 넘김) ANSI C에서는 포인터의 타입으로 void* 사용했다.
- 그러나 ANSI C보다 오래된 개념인 socket() Function에서는 포인터 타입 문제를 해결하기 위해 sockaddr을 정의하고, 포인터 타입으로 struct sockaddr* 를 사용했다.
- Kernel은 struct sockaddr* 타입(일반적인 소켓 구조)의 Argument를 통해 sa_family 값을 살펴서 세부적인 소켓 구조의 타입을 결정짓는다.
int bind(int, struct sockaddr *, socklen_t);
struct sockaddr_in serv; /* IPv4 socket address structure */
/* fill in serv{} */
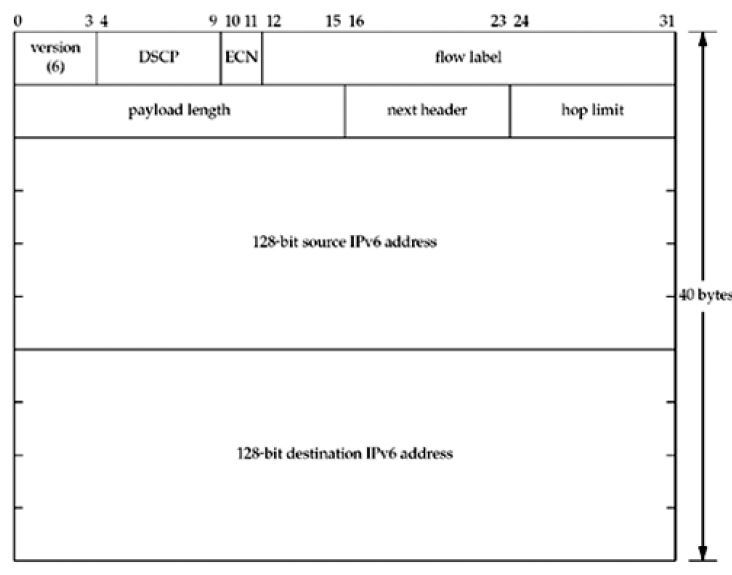
bind(sockfd, (struct sockaddr*)&serv, sizeof(serv));IPv6 Socket Address Structure
#include <netinet/it.h>
struct in6_addr {
uint8_t s6_addr[16];
}
#define SIN6_LEN
struct sockaddr_in6 {
uint8_t sin6_len; //length of this struct(24)
sa_family_t sin6_family; //AF_INET6
in_port_t sin6_port; //transport layer port
uint32_t sin6_flowinfo; //priority & flow label
struct in6_addr sin6_addr; //IPv6 address
};-
시스템이 socket address structure에 대한 길이 멤버를 지원한다면 SIN6_LEN 상수는 반드시 정의되어야한다.
-
이 구조체의 멤버들은 정렬되어있다. 왜냐하면 sockaddr_in6 구조체가 64비트 정렬이면 sin6_addr 멤버가 128비트여야하기 때문이다. 몇몇 64비트 프로세서들에선, 데이터들이 64비트 경계로 저장돼있으면 64비트 값들에 접근하는것이 최적화되어있다.
-
sin6_flowinfo: 32-bits 값은 세가지 부분으로 구분된다.
-
low-order 24bits : Flow Label에 사용
-
next 4bits : priority
-
next 4bits : 차후를 위해 Reserve해둔다.
Comparison of Socket Address Structures
아래 그림 6은 우리가 앞으로 보게 될 다섯가지 socket address 구조체들을 비교해 놓은 것이다. (IPv4, IPv6, Unix domain, datalink, storage)
이 그림에서 모든 socket address 구조체는 1바이트의 길이 필드와 1바이트의 family 필드를 가지고 있고, 다른 필드들은 최소한 몇 비트 이상이라고 가정하자.
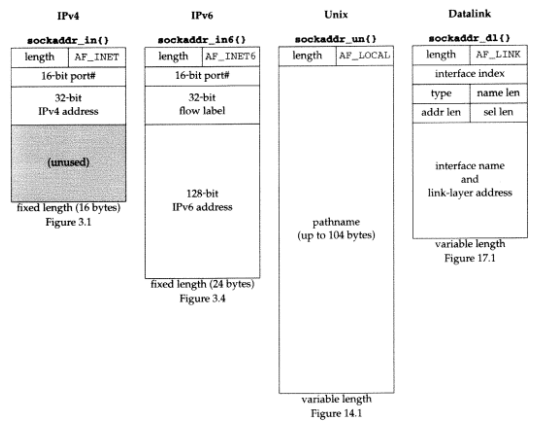
socket address 구조체들 중 2가지는 고정길이인 반면, Unix domain 구조체와 datalink 구조체는 가변길이다. 가변길이 구조체를 다루기 위해선, socket 함수에 socket address 구조체의 포인터를 매개변수로 넣을 때, 다른 매개변수로 길이도 함께 넣어줘야 한다. 몇 바이트 크기의 고정길이 구조체들이 각각의 구조체 아래 존재하는 것을 볼 수 있다.
sockaddr_un 구조체 자체는 가변길이가 아니다. 하지만 구조체 안의 pathname이 가변길이이다. 이 구조체의 포인터를 넘길 때, 우리는 반드시 길이필드를 어떻게 다룰지에 대해 고려해야한다. socket address 구조체 안의 길이 필드와 커널로 또는 커널로부터의 길이를 둘 다 고려해야한다.
위 그림에서 우리는 이책에서 앞으로 다룰 스타일을 알 수 있다: 구조체 이름은 항상 굵은 글씨이고, 꺽쇄 괄호가 함께 온다. (sockaddr_in{})
우리가 이전에 봤듯이, 길이 필드들은 4.3BSD Reno 릴리즈와 함께 모든 socket address 구조체에 추가되었다. 초기 릴리즈의 socket에 길이 필드가 존재했지만, 모든 socket 함수들에 길이 매개변수가 필요가 없다. (예를 들어, bind와 connet 함수의 3번째 매개변수) 대신 구조체의 크기는 구조체의 길이 필드에 포함될 수 있다.
3. Value-Result Arguments
-
모든 Socket Function들은 소켓 주소 구조체를 Pass by Reference 방식으로 넘겨받는다.
(즉, 소켓 주소 구조체를 포인터로 넘겨받는다.) -
하지만, 소켓 주소 구조체의 길이값은 Kernel to Process이냐, Process to Kernel에 따라 Passing의 방식이 다르다.
-
Process to Kernel에서는 구조체의 길이를 Passing by Value 형태로 넘기고,
Kernel to Process에서는 구조체의 길이를 Passing by Result 형태로 넘긴다.
(이런 점 때문에, 구조체의 길이를 값-결과 인수라 할 수 있는 것이다.)- 프로세스에서 커널로 전달 : bind, connect, sendto이 세개의 함수의 매개변수 중 하나는 socket address 구조체에 대한 포인터이며, 다른 매개변수 하나는 구조체의 integer 사이즈이다.

커널은 구조체의 포인터와 구조체의 크기를 둘 다 전달받기 때문에, 프로세스로부터 커널로 얼마만큼의 데이터를 복사 해야할 지 정확히 알고있다. 아래 그림은 이 시나리오를 보여준다.
다음 챕터에서 socket address 구조체의 사이즈 데이터타입이 사실 int가 아니라 socklen_t임을 보게될 것이다. 그러나 POSIX 명세에는 socklen_t가 uint32_t로 정의되는 것을 추천한다.
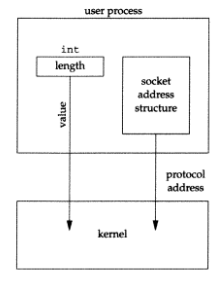
- 커널에서 프로세스로 전달 : accept, recvfrom, getsockname, getpeername
방금 전 시나리오와는 반대이다. 이 네개의 함수의 두 매개변수는 socket address 구조체의 포인터와 구조체의 크기를 담고있는 integer의 포인터이다.

사이즈의 타입이 integer에서 integer의 포인터로 바뀐 이유는 함수가 호출될 때는 value로 쓰이고(커널에게 구조체 사이즈를 알려준다.), 함수가 반환될 때는 result로 쓰이기 때문이다.(프로세스에게 커널이 구조체에 실제로 얼마만큼의 정보를 저장했는지 알려준다.) 이런 매개변수 타입을 value-result 매개변수라고 부른다. 아래 그림에 이 시나리오가 나와있다.
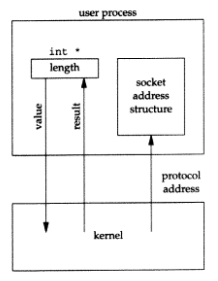
socket address 구조체의 길이를 value-result 매개변수로 사용할 때, 만약 socket address 구조체가 고정길이이면, 커널에서 반환되는 값은 항상 고정 크기이다. (예를들면, IPv4 sockaddr_in : 16, IPv6 sockaddr_in6 : IPv6) 그러나 가변길이 socket address 구조체(예를 들면, Unix domain sockaddr_un)일 때, 반환되는 값은 구조체의 최대 크기보다 작을 수 있다. (챕터 15의 그림 15.2에서 볼 수 있다.)
네트워크 프로그래밍에서 가장 흔한 value-result 매개변수 예제는 반환되는 socket address 구조체의 길이이다. 그러나 이 책에서 우리는 다른 value-result 매개변수들을 보게 될 것이다.
-select 함수의 중간에 3개 매개변수 (Section 6.3)
- getsockopt 함수의 길이 매개변수 (Section 7.2)
- ifconf 구조체의 ifc_len 멤버변수 (챕터 17의 그림 17.2)
- sysctl 함수의 두개의 길이 매개변수 중 첫 번째 (Section 18.4)
Byte Ordering Functions
2바이트짜리 정수가 있다고 가정하자. 이 정수를 저장하는 방법에는 두 가지가 있다.
- little-endian byte order : 낮은 순서(low-order)가 시작 주소에 오는 것, 메모리 주소가 오른쪽에서 왼쪽으로 증가
- big-endian byte order: 높은 순서(high-order)가 시작 주소에 오는 것, 왼쪽에서 오른쪽으로 증가
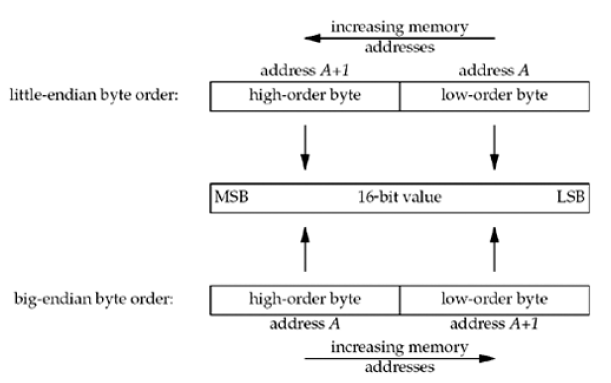
가장 왼쪽에 있는 비트인 most significant bit(MSB)와 가장 오른쪽에 있는 비트인 least significant bit(LSB)를 볼 수 있다.
"little-endian"과 "big-endian" 용어는 multibyte value의 시작주소의 값이 작은지 큰지를 지칭한다.
문제는 이 두가지 byte ordering 사이에 표준이 없다는 것이다. 그리고 앞으로 이 두가지 포멧을 만나게 될 것이다. 주어진 시스템에서 사용하는 byte order를 host byte order라고 부를 것이다. 아래 그림 6에 나와있는 프로그램은 host byte order를 출력한다.
byteordr.c
#include "unp.h"
int main(int argc, char **argv){
union{
short s;
char c[sizeof(short)];
}un;
//2바이트의 값 0x0102를 short integer에 저장
un.s = 0x0102;
printf("%s: ". CPU_VENDOR_OS);
//byte order를 확인하기 위해 연속된 2 바이트
//c[0](그림 5의 주소 A), c[1](그림 5의 주소 A+1)를 살펴본다.
if(sizeof(short) == 2){
if(un.c[0] == 1 && un.c[1] == 2)
printf("big-endian\n");
else if(un.c[0] == 2 && un.c[1] == 1)
printf("little-endian\n");
else
printf("unknown\n");
}else
printf("sizeof(short) = %d\n", sizeof(short));
exit(0);
}문자열 CPU_VENDOR_OS는 이 책 내의 소프트웨어가 구성되고 CPU 타입, 제조사, OS release가 식별될 때, GNU autoconf 프로그램에 의해 결정된다. 아래 그림 7에 이 프로그램을 다양한 시스템에서 실행했을 때 출력이 나와있다.

최근에는 little-endian, bit-endian 바이트 순서 사이를 시스템이 reset할 때 또는 실행 중에, 왔다갔다 할 수 있는 다양한 시스템이 있다.
ex) TCP에선 16bit의 port와 32bit의 IPv4 주소가 있다.
protocol stack을 송신, 수신하는 것은 반드시 그 byte order에 동의해야한다.
Internet protocol은 multibyte interger에 대해서 bit-endian byte order를 사용한다.
#include <arpa/inet.h> // Some systems require the inclusion of <netinet/in.h>
uint32_t htonl(uint32_t hostlong); // Host to Network Long (32-bits)
uint16_t htons(uint16_t hostshort); // Host to Network Short (16-bits)
uint32_t ntohl(uint32_t netlong); // Network to Host Long (32-bits)
uint16_t ntohs(uint16_t netshort); // Network to Host Short (16-bits)-
함수 이름에서 h는 host를 나타내고, n은 network, s는 short, l은 long
-
우리는 대신 s를 16-bit 값으로 생각해야 하고(TCP 또는 UDP 포트 넘버와 같은) l은 32-bit 값으로 생각해야 한다.(IPv4 주소와 같은)
사실 64-bit Digital Alpha에선, long integer가 64bit를 차지하지만 htonl, ntohl 함수는 32-bit 기준으로 동작한다. -
이러한 함수를 사용할 때, host byte order와 network byte order이 big-endian인지 little-endian인지 신경 쓸 필요 없다.
우리가 꼭 해야하는 것은 host, network byte order 사이에서 주어진 값을 변환하는 적절한 함수를 호출하는 것이다. Internet protocol(bit-endian)과 같이 byte order가 같은 시스템에선 이 네개의 함수는 보통 null macro로 정의된다.
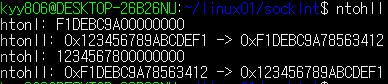
2 byte(short)나 4byte (int) 경우에는 htons(), htonl() 이나 ntohs(), ntohl() 을 사용
8byte(64bit에서)는 아직까지는 직접 만들어 사용// host -> network byte order (big endian) long long htonll(long long llvalue){ int x=1; // little endian if (*(char *)&x == 1) return (((long long)htonl(llvalue) << 32) + htonl(llvalue >> 32)); // big endian return llvalue; } // network byte order -> host (little endian) long long ntohll(long long llvalue){ int x=1; // little endian if (*(char *)&x == 1) return (((long long)ntohl(llvalue) << 32) + ntohl(llvalue >> 32)); // big endian return llvalue; }
left shift 연산자 <<
비트값을 주어진 숫자만큼 왼쪽으로 이동 시킨 후 빈자리는 0으로 채움<< 연산결과 int num1 = 3 num1 << 2; // num1 의 결과 값 3의 비트열을 2칸 왼쪽으로 이동한다 // num1 = 0000 0011 num1 = 0000 1100 // num1 의 결과 값이 3에서 12로 변한다right shift 연산자 >>
비트값을 주어진 숫자만큼 오른쪽으로 이동 시킨 후 빈자리는 정수 a의 최상의 부호비트와 같은 값으로 채움> 연산결과 int num1 = 9 num1 >> 2; // num1 의 결과 값 9의 비트열을 2칸 오른쪽으로 이동한다 // num1 = 0000 1001 num1 = 0000 0010 // num1 의 결과 값이 9에서 2로 변한다
Byte Manipulation Functions
바이트 조작 함수
- 첫번째 함수 그룹은 4.2BSD와 socket 함수를 지원하는 대부분의 시스템에서 제공되는, 이름이 b로 시작하는 함수들이다.
bzero(): nbytes만큼 0으로 초기화
#include <strings.h>
void bzero (void *dest, size_t nbytes);- *dest의 Bytes를 nbytes만큼 0으로 초기화한다.
- 소켓 주소 구조체를 0으로 초기화할 때 용이하게 사용된다.
- 2개의 Argument만을 요구하기 때문에, ANSI C의 memset() 함수보다 사용하기 쉽다.
(또한, 두 매개변수의 Type이 서로 다르기 때문에, 잘못 사용했을 경우 컴파일러가 이를 발견할 수 있다.) - 소켓 API를 제공하는 Vendor는 일반적으로 bzero()를 지원한다.
bcopy(): nbytes만큼 dest로 옮김
#include <strings.h>
void bcopy (const void *src, void *dest, size_t nbytes);- src에서 dest로 nbytes만큼의 bytes를 옮긴다.
bcmp(): nbytes만큼 비교
#include <strings.h>
int bcmp (const void *ptr1, const void *ptr2, size_t nbytes);- ptr1 바이트 열과 ptr2 바이트 열을 비교하여, 같으면 0을 리턴하고, 그렇지 않으면 0이 아닌 값을 리턴
- 두번째 함수 그룹은 ANSI C 표준과 ANSI C 라이브러리를 지원하는 시스템에서 제공되는, 이름이 mem으로 시작하는 함수들이다.
memset(): len 개수 만큼을 c값으로 초기화
#include <string.h>
void *memset(void *dest, int c, size_t len);- *dest에서 len 개수 만큼을 c값으로 초기화
- 3개의 Argument를 요구한다. (bzero()는 오직 2개의 Argument만 요구한다.)
- 두 번째, 세 번째 매개변수가 둘 다 int형이기 때문에 착각하기 쉽다.
memcpy(): *dest로 nbytes만큼의 bytes를 옮김
#include <string.h>
void *memcpy(void *dest, const void *src, size_t nbytes);- src에서 dest로 n Bytes만큼의 Bytes를 옮김
- memcpy()는 src와 dest가 겹쳐있는 경우에 대처방법이 정의되어 있지 않아, 겹침이 있는 경우 memmove() 함수를 사용해야 한다. (bcopy()는 겹침에 대한 처리가 구현되어 있다.)
memcmp(): nbytes만큼 비교
#include <string.h>
int memcmp(const void *ptr1, const void *ptr2, size_t nbytes);- ptr1 바이트 열과 ptr2 바이트 열을 비교하여 같으면 0을 리턴하고, 그렇지 않으면 0이 아닌 값을 리턴
inet_aton, inet_addr, and inet_ntoa Functions - IPv4만
1) inet_aton, inet_ntoa, inet_addr 함수는 dotted_decimal 문자열의 IPv4 주소(예를들면, "206.168.112.96")를 32-bit network 바이트 순서의 binary value로 변환한다.
dotted_decimal
각 바이트 의 값을 10진수 로 지정 하고 각 바이트를 점 으로 구분하여 IP 주소 를 작성하는 방법
inet_aton()/; 32bit로 변환하여 *addptr에 저장
#include <arpa/inet.h>
int inet_aton(const char *strptr, struct in_addr *addrptr);- strptr(C-String)를 32-Bits Network Byte Order의 binary Value로 변환하여 *addrptr에 저장한다.
- inet_aton()은 변환에 성공하면 1을 리턴하고, 그렇지 않으면 0을 리턴
- *addrptr이 NULL이면, inet_aton()은 strptr의 적합성만 검사하고, 실질적인 저장은 수행하지 않는다.
inet_addr(): 32bit로 변환 후 반환
#include <arpa/inet.h>
in_addr_t inet_addr(const char *strptr);- strptr(C-String)를 32-Bits Network Byte Order의 binary Value로 변환하여 리턴한다.
- 변환에 에러가 발생되면 inet_addr()은 상수INADDR_NONE(255.255.255.255)을 리턴한다. (즉, inet_addr()은IPv4 Limited Broadcast Address를 처리하지 못한다.)
inet_ntoa(): 32bit로 변환 후 반환
#include <arpa/inet.h>
char *inet_ntoa(struct in_addr inaddr);-
32-Bits Network Byte Order의 binary Value를 Dotted-Decimal String 형태인 C-String으로 변환하여 리턴
-
이 함수가 반환하는 문자열 포인터가 가리키는 것은 static memory에 존재한다. 이것이 의미하는 것은 이 함수가 reentrant하지 않다는 것이다.
reentrant 하지 않다는 것
다시 한번 실행했을 떄 이전의 결과에 영향을 받는다는 것
특히 스레드에서 동시에 실행될 때 문제 -
이 함수는 매개변수로 구조체 포인터를 받는게 아니고 구조체 자체를 받음
IPv4 and IPv6 Conversion Functions
- p : Presentation
- n : Numeric
inet_pton and inet_ntop Functions - IPv4, IPv6 둘다
2) 후에 나온 inet_pton, inet_ntop 함수는 IPv4와 IPv6주소를 둘 다 다룬다.
inet_pton(): IP주소 표현을 바이너리값으로 변환하여 *addptr에 저장
#include <arpa/inet.h>
int inet_pton (int family, const char *strptr, void *addrptr);- Presentation to Numeric : IP주소 표현을 Network Byte Order Binary Value로 변환한다.
- strptr를 Network Byte Order Binary Value로 변환하여 addrptr
에 저장한다. - family는 AF_INET(IPv4) 값이나, AF_INET6(IPv6) 값 둘 중 하나로 지정되어 IPv4 주소인지, IPv6 주소인지를 구분짓는다.
Return:
| inet_pton() Return Value | Description |
|---|---|
| +1 | 정상적인 변환에 성공한 경우: 변환 성공 |
| 0 | strptr에 주소군에 부합되지 않는 주소가 전달된 경우: 변환 실패 |
| -1 | errno = EAFNOSUPPORT |
inet_ntop(): 바이너리값을 IP 주소 표현으로 변환 후 *addrptr에 저장
#include <arpa/inet.h>
const char *inet_ntop (int family, const void *addrptr, char *strptr, size_t len);- Numeric to Presentation : Network Byte Order Binary Value를 IP주소 표현으로 변환한다.
- addrptr을 family에 지정된 IP주소 형태의 C-String으로 변환하여 strptr에 저장한다.
- Callerdml Buffer Overflow를 방지하기 위해, len에 목적지 버퍼의 크기를 Argument로 요구한다.
Return:
- 변환에 성공하면, strptr에 NULL이 아닌 값을 리턴
- 변환 결과가 len보다 크면, inet_ntop()는 NULL을 리턴하고, errno를 ENOSPC로 설정한다.
- family에 부적절한 값이 입력되면, inet_ntop()는 NULL을 리턴하고, errno를 EAFNOSUPPORT로 설정한다.
len에 일반적으로 사용되는 상수
#include <netinet/in.h>
#define INET_ADDRSTRLEN 16 // for IPv4 dotted-decimal
#define INET6_ADDRSTRLEN 46 // for IPv6 hex string
시스템에 아직 IPv6지원이 포함되어있지 않더라도 다음 형식 호출하여 사용할 수 있다
```c
foo.sin_addr.s_addr = inet_addr(cp);
inet_pton(AF_INET, cp, &foo.sin_addr);
char str[INET_ADDRSTRLEN];
ptr = inet_ntoa(AD_INET, &foo.sin_addr, str, sizeof(str));Pv4만을 지원하는 간단한 inet_pton() 구현내용
int inet_pton(int family, const char *strptr, void *addrptr)
{
if (family == AF_INET) {
struct in_addr in_val;
if (inet_aton(strptr, &in_val)) {
memcpy(addrptr, &in_val, sizeof(struct in_addr));
return (1);
}
return (0);
}
errno = EAFNOSUPPORT;
return (-1);
}IPv4만을 지원하는 간단한 inet_ntop() 구현내용
const char *inet_ntop(int family, const void *addrptr, char *strptr, size_t len)
{
const u_char *p = (const u_char *) addrptr;
if (family == AF_INET) {
char temp[INET_ADDRSTRLEN];
snprintf(temp, sizeof(temp), "%d.%d.%d.%d", p[0], p[1], p[2], p[3]);
if(strlen(temp) >= len) {
errno = ENOSPC;
return (NULL);
}
strcpy(strptr, temp);
return (strptr);
}
errno = EAFNOSUPPORT;
return (NULL);
}sock_ntop and Related Functions
inet_ntop 문제점
호출자가 바이너리 주소에 대한 포인터를 전달해야 한다는 것
이 주소는 일반적으로 소켓 주소 구조에 포함되며 호출자는 구조 및 주소 패밀리의 형식을 알아야 한다.
즉, 사용하려면 다음 형식의 코드를 작성해야 함
//IPv4
struct sockaddr_in addr;
inet_ntop(AF_INET, &addr.sin_addr, str, sizeof(str));
//IPv6
struct sockaddr_in6 addr6;
inet_ntop(AF_INET6, &addr6.sin6_addr, str, sizeof(str));sock_ntop:
char *sock_ntop(const struct sockaddr *sa, socklent_t salen);- sock_ntop()는 소켓 주소 구조체와 그 크기를 Argument로 넘겨받아서, 프로토콜에 맞는 표현 형식을 리턴(즉, 사용자가 해당 소켓 주소 구조체의 프로토콜을 몰라도 된다)
char *sock_ntop(const struct sockaddr *sa, socklen_t salen){
char portstr[8];
static char str[128]; /* Unix domain is largest */
switch (sa->sa_family) {
case AF_INET:{
struct sockaddr_in *sin = (struct sockaddr_in *) sa;
if (inet_ntop(AF_INET, &sin->sin_addr, str, sizeof(str)) == NULL)
return (NULL);
if (ntohs(sin->sin_port) != 0) {
snprintf(portstr, sizeof(portstr), ":%d",
ntohs(sin->sin_port));
strcat(str, portstr);
}
return (str);
}
sock_bind_wild: 와일드카드 주소와 임시 포트를 소켓에 바인딩
sock_cmp_addr: 두 소켓 주소 구조의 주소 부분을 비교
sock_cmp_port: 두 소켓 주소 구조 의 포트 번호를 비교
sock_get_port: 포트 번호만 반환
sock_ntop_host: 소켓 주소 구조의 호스트 부분만 표시 형식(포트 번호가 아님)으로 변환
sock_set_addr: 소켓 주소 구조의 주소 부분만 ptr 이 가리키는 값으로 설정
sock_set_port: 소켓 주소 구조의 포트 번호만 설정
sock_set_wild: 소켓 주소 구조의 주소 부분을 와일드카드로 설정
readn, writen, and readline Functions
일반적인 파일 IO와는 달리 TCP 소켓과 같은 스트림 소켓에 read 시스템콜이나 write 시스템콜을 이용하여 IO를 수행하는것은 왠만하면 금지되어 있다. 커널에서 소켓에 대해 입출력을 수행할때, 버퍼의 크기가 제한되어 있기 때문이다. read 시스템콜, write 시스템콜을 이용하여 IO를 수행했을때, 이만큼 IO를 해달라고 커널에 요청한 수에 비해 실제로 IO를 수행한 바이트의 수(이는 read, write 함수의 결과로 반환된다.) 가 적을 수 있으며, 이는 에러를 의미하는 것이 아니다. 따라서, IO를 완전하게 끝내기 위해서, IO를 수행하다가 남은 나머지 부분을 처리할때까지 다시 read, write 를 수행하도록 해야할 것이다.
실제로 유닉스 일부 버전에서는 4096 바이트가 넘도록 파이프를 통해 write 를 수행하는 행위를 금지하고 있다.
#include "unp.h"
ssize_t readn(int filedes, void *buff, size_t nbytes);
ssize_t writen(int filedes, const void *buff, size_t nbytes);
ssize_t readline(int filedes, void *buff, size_t maxlen);
return: 읽거나 쓴 바이트 수, 실패 -1write
- fd File Descriptor에 n Bytes만큼 데이터를 쓰는 함수이다.
- writen()은 write()를 이용하여 count만큼의 출력이 보장된 함수이다.
ssize_t writen(int fd, const void *vptr, size_t n){
size_t nleft;
ssize_t nwritten;
const char *ptr;
ptr = vptr;
nleft = n;
while (nleft > 0) {
if ( (nwritten = write(fd, ptr, nleft)) <= 0) {
if (nwritten < 0 && errno == EINTR)
nwritten = 0; /* and call write() again */
else
return(-1); /* error */
}
nleft -= nwritten;
ptr += nwritten;
}
return(n);
}read
- fd File Descriptor로부터 n Bytes만큼을 읽어들이는 함수이다.
- 읽어들일 데이터의 크기가 크면, 한 번의 read() 호출로 부족할 수 있기 때문에, read()를 Loop내에 위치시키고, read()의 리턴값이 0이하이면 Loop를 종료시킨다.
ssize_t readn(int fd, void *vptr, size_t n){
size_t nleft;
ssize_t nread;
char *ptr;
ptr = vptr;
nleft = n;
while (nleft > 0) {
if ( (nread = read(fd, ptr, nleft)) < 0) {
if (errno == EINTR) // EINTR : Error Interrupt
nread = 0; /* and call read() again */
// read()에서 Blocked되어 있다가, Signal 발생을 통보받으면 nread값을 0으로 초기화하여 다시 read를 호출함
else
return(-1);
} else if (nread == 0)
break; /* EOF */
nleft -= nread; //얼마나 더 읽어들여야하는지 남은 바이트 수를 갱신
ptr += nread; //읽어들인 수만큼 포인터 저진시킴
}
return(n - nleft); /* return >= 0 */
}readline
- readline()은 newline문자('\n')까지, 한 문장씩 읽어들이는 함수이다.
- 소켓 read()시에, 한 문장씩 읽어들이는 것은 위험하기 때문에 권장되지 않는다.
ssize_t readline(int fd, void *vptr, size_t maxlen){
ssize_t n, rc;
char c, *ptr;
ptr = vptr;
for (n = 1; n < maxlen; n++) {
again:
if ( rc = read(fd, &c, 1)) == 1 ) {
*ptr++ = c;
if (c == '\n') //새 줄 저장, fgets()처럼
break;
} else if (rc == 0) {
if (n - 1)
return (0); //EOF
} else {
if (errno == EINTR)
goto again;
return (-1); //error
}
}
*ptr = 0; //null은 fgets()처럼 종료
return (n);
} -
이 세가지 함수는 EINTR(signal)을 찾고 오류가 발생하면 계속 읽기 또는 쓰기를 수행합니다 호출자가 readn 또는 writen을 다시 호출하도록 하는 대신 여기에서 오류를 처리합니다.
이 세 함수의 목적은 호출자가 짧은 수를 처리해야하는 것을 방지하는 것이기 때문입니다. -
readline 함수는 데이터의 모든 바이트에 대해 시스템의 읽기 함수를 한번 호출한다.
이것은 매우 비효율적이며 느리다. -
우리가 하고싶은 것은 가능한 많은 데이터를 얻기 위해 read를 호출하여 데이터를 버퍼링한 다음 버퍼를 한번에 1바이트씩 확인하는 것
-
stdio 버퍼링보다 자체 버퍼링을 사용하는 더 빠른 버전의 readline함수
다른점
readline은 stdio의 버퍼로 읽음
readline 새 함수는 read 대신 my_read()를 이용하여 MAXLINE bytes만큼 한번에 읽고 한번에 반환한다.
static ssize_t my_read(int fd, char *ptr){
static int read_cnt = 0;
static char *read_ptr;
static char read_buf[MAXLINE];
//만약 read_cnt 가 0과 같거나 보다 작으면
if (read_cnt <= 0) {
again:
//read 반환값: 성공시 읽은 데이터 byte수, 실패시 -1, 다 읽으면 eof
if ((read_cnt = read(fd, read_buf, sizeof(read_buf))) < 0) {
//만약 signal을 받으면
if (errno == EINTR)
//again에서 다시 시작
goto again;
return (-1);
} else if (read_cnt == 0) //read_cnt가 0(즉, 파일 다 읽으면)
return (0);
//포인터에 read_buf 저장
read_ptr = read_buf;
}
//읽은 만큼 read_cnt 감소
read_cnt--;
//읽은 만큼 ptr 포인터 증가
*ptr = *read_ptr++;
return (1);
}
ssize_t
readline(int fd, void *vptr, size_t maxlen){
ssize_t n, rc;
char c, *ptr;
ptr = vptr;
for (n = 1; n < maxlen; n++) {
if ((rc = my_read(fd, &c)) == 1) {
*ptr++ = c;
if (c == '\n')
break; /* newline is stored, like fgets() */
} else if (rc == 0) {
*ptr = 0;
return (n - 1); /* EOF, n - 1 bytes were read */
} else
return (-1); /* error, errno set by read() */
}
*ptr = 0; /* null terminate like fgets() */
return (n);
}2–21 내부 함수 my_read 는 한 번에 최대 MAXLINE 문자를 읽은 다음 한 번에 하나씩 반환합니다.
29 readline 함수 자체에 대한 유일한 변경 사항 은 read 대신 my_read 를 호출하는 것입니다 .
42–48 새로운 함수인 readlinebuf 는 내부 버퍼 상태를 노출하여 호출자가 단일 라인을 넘어 더 많은 데이터가 수신되었는지 확인할 수 있도록 합니다.
불행히도 readline.c 의 정적 변수를 사용하여 연속적인 호출에서 상태 정보를 유지하면 함수가 재진입 하거나 스레드로부터 안전 하지 않습니다 . 이에 대해서는 11.18절과 26.5절에서 논의할 것입니다. 우리는 그림 26.11 의 스레드별 데이터를 사용하여 스레드로부터 안전한 버전을 개발할 것 입니다.
isfdtype Function
filedescriptor가 fdtype 유형의 파일을 참조하는지 여부를 테스트
int isfdtype(int fd, int fdtype);S_IFSOCK으로 소켓인지 아닌지 확인
https://www.informit.com/articles/article.aspx?p=169505&seqNum=9
