2.2 The Big Picture
맨 왼쪽 tcp dump는 BPF(BSD Packet Filter)이나 DLPI(Data Link Provider Interface)을 이용해서 datalink layer로 직접 통신
IPv4
- 32bit address
- Provide packet delivery service for TCP, UDP, SCTP, ICMP, IGMP
IPv6
- 128bit address
- Provide packet delivery service for TCP, UDP, SCTP, ICMPv6
TCP(Transmission Control Protocol)
- Reliable Connection Oriented (신뢰성 있는 연결 기반)
- Full-duplex (양방향)
- acknowledgment / timeout / retransmission 이런 디테일 챙김
- Use Ipv4 / IPv6
UDP(User Datagram Protocol)
- Connectionless
- 목적지까지의 전송을 보장하지 않음
- Use IPv4 / IPv6
SCTP
- Reliable Connection Oriented (신뢰성 있는 연결 기반)
- Full-duplex (양방향)
- association 이라는 SCTP에서 Multihoming을 위한 연결 검증 작업함
Multihoming
호스트 또는 컴퓨터 네트워크를 둘 이상의 네트워크에 연결하는 방법
이는 안정성이나 성능을 높이기 위해 수행할 수 있음 - Use IPv4 / IPv6 (그렇지만 같은 association끼리 같은 걸 써야 한다)
ICMP (Internet Control Message Protocol)
- 패킷 전송이 실패시 error 알림, 힌트 제공
- Control between Routers and Hosts
IGMP (Internet Group Management Protocol)
- used wuth Multicasting
Multicasting
한번의 송신으로 메시지나 정보를 목표한 여러 컴퓨터에 동시에 전송하는 것 - Optional with IPv4
ARP (Address Resolution Protocol)
- IPv4주소를 하드웨어 주소로 맵핑(Ethernet address처럼)
- 일반적으로 Ethernet, token ring, FDDI 같은 Broadcast network에서 사용된다
Ethernet
CSMA/CD 프로토콜을 사용하는 통신
CSMA/CD
통신하고자 하는 컴퓨터가 네트워크를 살펴봐서 아무도 통신을 하고 있지 않으면 네트워크에 통신이 발생되면 carrier이 발생되고 이것이 감지되면 누군가 데이터를 나 말고 전달했다는 사실을 알게됨)
무조건 자신의 데이터를 실어서 보내고 잘 도착했는지 확인해보는 방식, 그래서 동시에 두 개 이상의 컴퓨터에서 데이터를 실어보내려고 하면 충돌 발생(충돌 탐지: collision detection)
token ring
네트워킹 방식 중 하나
이더넷처럼 자기가 보내고 싶을 때 다른 장비에서 전송하고 있지 않다면 막 보내는 방식이 아니라 , 오직 토큰을 가진 PC에서만 네트워크에 데이터를 실어 보낼 수 있는 방식 - point-to-point 방식에서는 필요없다.
점대점
네트워크에 있어 물리적으로는 중개 장치를 통과하지 않고 한 지점에서 다른 지점으로 직접가는 채널을 말함 논리적으로는 두 장비간의 통신
이 방식은 한개의 터미널이 하나의 회선망으로 커뮤터에 연결되어있기 때문애 비경제적
RARP (Reverse Address Resolution Protocol)
- ARP와 반대로, Hardware address를 IPv4 address로 매핑한다.
- 가끔 Diskless Node(하드 디스크, 플로피 드라이브, CD-ROM 같은 보통 사용하는 부팅 장치가 없는 PC. Diskless Node는 네트워크를 통해 부팅하며, 저장공간을 로컬 하드 디스크처럼 제공하는 서버가 필요)
ICMPv6 (Internet Control Message Protocol version 6)
- ICMPv4, IGMP, ARP를 기능을 결합한다.
BPF (BSD Packet Filter)
- Datalink layer에 접근할 수 있도록 해 주는 Interface
DLPI (DataLink Provider Interface)
- Datalink layer에 접근할 수 있도록 해 주는 Interface
- 일반적으로 SVR4와 함께 사용된다.
2.3 UDP
- Connectionless
- 에러를 발견하거나 패킷이 드랍되도 TCP처럼 자동으로 재전송되지 않는다.
- UDP Datagram은 Length를 가진다.
- TCP와 다르게 message boundary가 없다.
- 같은 소켓으로 다양한 datagram 패킷 받을 수 있다.
Message Boundary(데이터 경계)
TCP는 데이터 경계가 존재하지 않아서 패킷 전송 시 나눠서 받을 수도 있다.
UDP는 데이터 경계가 존재하기 때문에, 패킷 전송 시 전송한 횟수만큼 받는다.
2.4 TCP
-
connection 기반으로 데이터를 교환
-
Reliable
-
승인(acknowledgement)이 오지 않으면 자동으로 데이터를 재전송하고, 기다린다.
보통 4~10분간(구현에 따라 다름) 몇 번의 데이터 재전송을 해도 응답이 없다면 포기한다. -
다른 endpoint로부터의 데이터를 receive할 거라는 보장을 하지 않는다. 그저 가능하다면 데이터를 전달하는 것이다. 데이터를 받을 수 없다면 그 정보를 알려 준다.
-
그래서 TCP는 100% 신뢰성 있는 프로토콜을 보장하는 것이 아니다.
-
Round-Trip Time(RTT : 승인이 얼마나 오래 걸리는지에 대한 시간 => 패킷 주고받는 시간)을 추정하는 알고리즘을 사용한다.
만약 LAN을 통한 RTT는 밀리초 단위 시간이 걸린다면, WAN에서는 초 단위로 걸릴 수 있다.
네트워크 트래픽에 의해 영향을 받기 때문에, TCP는 지속적으로 RTT 체크를 한다. -
TCP는 모든 데이터의 연속성을 보장하며 전송한다. 실제로 TCP는 내부적으로 Sequence 번호를 가지고 있다.
예를 들어, TCP 소켓에 2048bytes를 2번의 segment로 전송했다고 가정하면, 1번째에 1 ~ 1024, 2번째에 1025 ~ 2048까지 번호를 저장한다. -
만약 수신자 측에서 segment가 꼬이면, sequence number를 토대로 2개의 세그먼트를 재배열한다.
- 즉, TCP는 보낼 때 데이터를 sequence number와 함께 순서대로 보내지만, 사실 receive하는 쪽은 순서와 상관없이 받을 수도 있다.
그래서 내부적으로 sequence number를 확인하여 재배치하는 작업을 한다.
또, TCP가 어떤 peer(네트워크 과부하 혹은 다른 오류로 인해 새그먼트가 분실되었다 생각하고 재전송된)로부터 중복된 데이터를 receive했을 때에도, TCP는 sequence number를 토대로 중복됨을 감지해 낸 후, 중복된 데이터를 파기한다.
- Flow Control을 제공한다. 한 번에 peer로부터 데이터를 몇 byte를 받는지 알 수 있다. 이걸 window라 하는데, 현재 receive buffer에서 수용 가능한 양을 의미한다. 송신 측에 receive buffer를 overflow시킬 수 없도록 해 주는 것을 보장한다.
데이터가 송신 측으로부터 수신되면 window의 size는 감소한다. 하지만 버퍼에서 데이터를 읽을 때, 다시 window size가 늘어난다. buffer에 데이터가 꽉 차서 window size가 0일 때가 있는데, 이렇게 되면 buffer에서 데이터를 읽을 때까지 기다리게 된다.
UDP
- Sequence number나 ACK, RTT estimation(추정), timeout(아까 TCP에서 4~10분 얘기했던 거), ReTransmission을 일체 제공하지 않는다.
- UDP Datagram은 sequence number가 없기 때문에, 중복된 데이터를 받을 때도 있다.
- 데이터 순서(배치)가 꼬일 수 있다. UDP로 프로그램을 개발한다면, 위의 상황을 잘 고려해서 개발해야 한다.
- Flow Control를 제공하지 않는다.
TCP는 Full-duplex(양방향) 통신이다. 이 말은 즉 TCP는 sequence number / window size 같은 상태 정보를 항상 추적하고 있어야 한다는 뜻이다.
2.5 TCP Connection Establishment and Termination
Three-Way Handshake
-
서버는 들어오는 새 연결을 Accept할 준비를 한다. (socket, bind, listen 호출)
- bind
소켓을 생성했으니, 이제 각 소켓에 IP주소와 포트를 할당 - listen
여러 클라이언트 요청을 대기시킬 수신 대기열 - connect
클라이언트는 connect 함수를 통해 서버에 연결 요청을 한다.
connect에 필요한 건 sockfd, 소켓 지정 번호와 serv_addr, 서버의 ip주소 포트 정보등이다. - accept
수신 대기열에 있는 클라이언트의 연결 요청을 확인
- bind
-
connect를 호출하여 open한다. Client는 SYN(synchronize segment : 서버에게 보낼 data의 sequence number)를 보낸다.
일반적으로 SYN과 함께 전송되는 데이터는 없다. 그저 IP Header / TCP Header / 여러가지 TCP 옵션들에 대한 정보가 포함된다. -
서버는 클라이언트의 SYN에 응답하여 ACK를 보낸다. 또한, 보낼 데이터의 sequence number를 포함한 SYN을 보낸다. 이걸 하나의 segment에 담아 보낸다.
-
마지막으로, 클라이언트는 서버의 SYN에 응답하여 ACK를 보낸다.
TCP header
- Source Port: Source port number
- Destination Port: Destination port number
- Sequence Number: 송신자가 보내는 데이터의 시작 바이트 숫자
- Acknowledgment Number: 송신자에게서 받은 데이터 바이트의 + 1
- Data Offset (Header length): 4byte 단위로 표시함. 일반적으로 option이 없는경우 20byte.
ex) 20byte 일 경우 4byte 단위로 표시되니 header length 는 5가 들어감. (5 4bytes == 20 bytes)
4bit 최대 값은 15(2진수 1111)이므로 15 4 byte =>최대 60byte- TCP flags
URG : Urgent pointer 가 정상인지 체크하고 urgent pointer를 찾습니다.
ACK : ack number filed를 확인합니다. 첫번째 SYN 일때는 ACK 필드도 셋팅됩니다.
PSH : 송신자가 해당 데이터가 가장 먼저 소비되기를 원하는 필드를 의미합니다.
RST : 송신자가 공식적인 종료절차 없이 종료하길 원할때 사용합니다.
비정상적인 세션 연결 끊기에 사용합니다.
SYN : 커넥션 초기에 사용되는 필드입니다. 처음에 seq가 임의 생성되어 보내집니다.
이 값을 base로 이후 데이터를 전송할때마다 사이즈만큼 증가됩니다.
FIN : TCP 가 연결 끊기를 원할때 사용됩니다.- Window size: 수신가능한 Receive window size 버퍼의 사이즈
- Checksum: 이 세그먼트가 정상인걸 증명하는 필드

TCP Options
-
MSS: 한 패킷으로 전송할 수 있는 최대 크기
이 옵션을 사용하면, SYN에 Maximum Segment Size를 포함시킨다.
송신자는 Maximum of Segment size로 수신자 측의 MSS값을 사용한다.
SYN은 Connection에서 주고받는 패킷이다. 처음 통신을 시작할 때, 서로에게 서로가 Receive할 수 있는 segment size를 알려주기 위함이다. -
Window Scale Option: 수신측 TCP의 수신가능한 버퍼사이즈
TCP에서 window의 최대 크기는 65535(16bit)byte이다. TCP Header에 해당하는 field가 16bit를 차지하고 있기 때문이다.
긴 지연 시간을 가지는 경로는 가능한 최대 처리량을 늘리기 위해 더 큰 window가 필요하다.
이 옵션은 TCP Header의 window가 0-14bit만큼 확장되어야 함을 명시한다. 제공되는 최대 window 크기는 거의 1GB정도 된다. (65535 * 2^14)
이 옵션을 사용하려면 각 단말기 사이의 통신이므로 서로가 지원해야 한다. SO_RCVBUF socket option으로 이를 확인할 수 있다. -
Timestamp Option
timestamp option을 통해서 보다 정확한 RTT값을 얻어낼 수 있다.
송신자는 패킷을 보낼 때 자신의 timestamp를 TS value에 기록하고 수신자는 TS value의 값을 복사하여 TS echo replyt field에 복사합니다.
그래서 오리지날 송신자는 현재 timestamp와 TS echo reply field의 timestamp의 차이를 계산하여 RTT 측정
TCP Connection Termination
연결을 시작할 때는 three segments를 가지지만, 연결을 종료할 때는 four segments가 필요
- Client에서 active close를 호출하면 FIN segment를 보낸다. 데이터 전송을 끝내겠다는 뜻이다.
- Server에서 FIN segment를 받으면 그에 따른 ACK를 보내고, receive queue의 맨 마지막에 'Receipt of the FIN(더 이상 데이터를 Receive하지 않겠다는 뜻)'을 전달한다.
- 그 후, receive queue가 비워진 후에 passive close가 호출되고, FIN을 전송한다.
- Client는 마지막 FIN을 받고 그에 해당하는 ACK를 전송한다.
2번과 3번에서 ACK와 FIN은 하나의 segment로 구성될 수 있다.
TCP state Transition Diagram
Watching the Packets
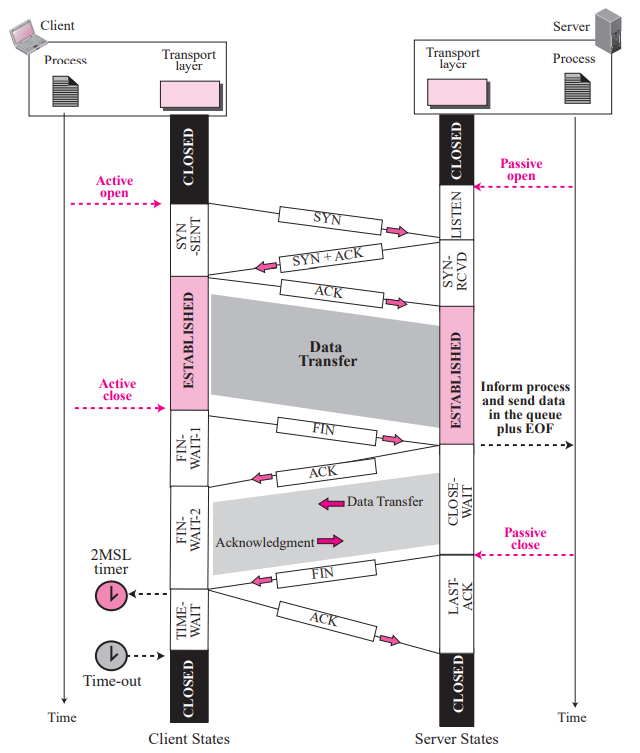
왼쪽의 클라이언트가 SYN을 보내고 서버에게서 SYN + ACK을 받을 때 까지의 기간을 SYN-SENT라고 한다.
SYN + ACK을 받고 나면 클라이언트는 ACK을 보내는데, ACK을 보내고 난 후 부터를 ESTABLISHED (연결완료 상태)라고 한다.
서버의 경우 클라이언트로부터 첫 SYN을 받기 위해 연결을 준비하는 상태를 LISTEN이라고 한다. 클라이언트로 부터 SYN을 받으면 SYN + ACK을 보내고, 클라이언트로부터 ACK이 올 때까지 기다리는 상태를 SYN-RCVD 상태라고 하고, ACK이 들어오면 ESTABLISHED(연결) 상태가 된다.
서로가 ESTABLISHED 상태가 되어야한 한쪽이 데이터를 보내는 것에 대해서 주고받을 수 있다.
연결이 된 (ESTABLISHED)상태에서 클라이언트가 FIN을 보낸다.(보통은 클라이언트가 먼저 연결종료 요청을 보내는 것이 일반적임) 클라이언트가 보낸 FIN에 대한 ACK이 오기 전까지의 상태를 FIN-WAIT-1이라고 한다. 서버에게서 ACK을 받으면 FIN-WAIT-2가 되고 서버로부터 데이터를 받다가 서버의 FIN을 받으면 그에 대한 ACK을 보내고 클라이언트는 TIME-WAIT상태가 된다.
위 그림에서 2MSL 이란 Maximum Segment Lifetime이다. 이는 1MSL당 대략 (30s~1m)정도인데 2MSL이므로 대략 1m~2m 정보를 timer로 대기하다가 시간이 만료되면 CLOSED 상태가 된다.
서버의 경우 클라이언트에게 FIN이 오면 AKC을 보내고 CLOSE-WAIT 상태가 된다. 서버에서 보낸 FIN에 대해서 ACK이 올 때 까지를 LAST-ACK 이라고 한다.
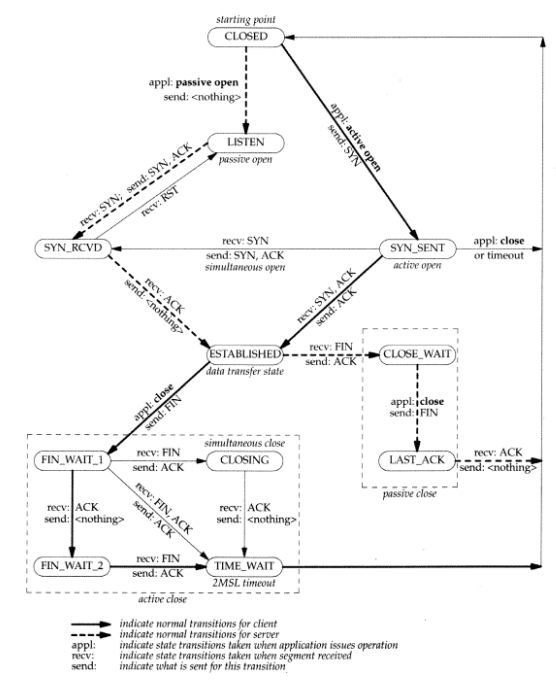
- client 연결(실선) CLOSED에서 실선으로 이어지는 Active open/SYN은 말 그대로 활동을 시작하기 위해서 SYN을 보내는 것을 말한다. 클라이언트가 SYN을 보내고 SYN + ACK이 올 때까지의 상태를 위에서 SYN-SENT라고 한다고 했었다. SYN-SENT 상태에서 SYN + ACK이 도착하면 그에 대한 ACK을 보낸다. 그러면 클라이언트는 ESTABLISHED(연결) 상태로 들어간다.
- server 연결(점선)
서버는 Passive open 즉 수동적으로 오픈하여 LISTEN상태에서 대기한다.
LISTEN 상태에서 SYN이 오면 LISTEN상태가 끝나고 SYN + ACK을 보내준다. 그리고 상태는 SYN-RCVD 상태로 변경된다.
SYN-RCVD 상태에서 클라이언트에게 ACK이 올 때까지 기다리다가 ACK이 오게되면 ESTABLISHED 상태로 들어간다.
이번에는 연결 상태에서 종료로 가는 과정을 보자.
- client 종료
클라이언트가 먼저 Close함수를 통해 FIN을 보내준다. 클라이언트는 FIN-WAIT-1 상태가 된다.
서버에서는 FIN + ACK이 올 수도 있고(컬러선) ACK만 올 수도 있다.(흑색 실선)
ACK만 온경우 클라이언트는 FIN-WAIT-2 상태가 되고 서버의 FIN을 기다린다.
서버에게서 FIN이 오면 ACK을 보내어 TIME-WAIT상태로 바뀐다.
만약 FIN + ACK이 온 경우에는 FIN-WAIT-1에서 ACK을 보내고 바로 TIME-WAIT상태가 된다.
위에서 TIME-WAIT 상태가 되면 2MSL만큼(대략1~2분)을 timer로 대기한다고 하였다. 대기 후 CLOSED 상태로 들어간다.
- server 종료
서버는 ESTABLISHED 상태에서 클라이언트에게서 FIN이 오면, ACK을 보내주고 CLOSE-WAIT상태로 변경한다.
클라이언트의 종료 과정에서 보았듯 서버가 FIN + ACK을 보내는 경우도 있는데, 이는 ACK을 보낸 시점으로부터 FIN을 보내는 간격이 상당히 짧을 경우에 그렇게 된다.
서버가 CLOSE-WAIT상태에서 Close 함수를 호출하면 FIN이 전송된다. FIN이 전송되면 클라이언트로부터 마지막 ACK을 기다리는데 이 상태가 LAST ACK상태이다.
LAST ACK상태에서 ACK을 받으면 CLOSED 상태가 된다.
CLOSED상태는 무엇인가
클라이언트와 서버는 각각 데이터를 주고받기 위한 버퍼를 Sending / Receiving 두 개씩 가지고 있다.
CLOSED 상태는 이 버퍼들을 각자 다 운영체제에 반납하여 없애버린 상태를 말한다.
TIME_WAIT State
TCP 구현해야한다면 MSL(Maximum Segment Lifetime)값을 반드시 세팅해주어야한다.
MSL
IP Datagram이 Network에 존재할 수 있는 최대 시간
📌TIME_WAIT State의 지속 시간이 MSL의 2배인 이유
Client에서는 일단 마지막 ACK를 서버로 전송한 후, 2MSL 시간 동안 TIME_WAIT State를 유지하고, Socket을 Close시킨다.
2MSL시간 동안 TIME_WAIT State를 유지하는 이유는, Server는 Client에게 FIN을 보내면서 MSL 시간동안 Client의 ACK를 기다리게 된다.
MSL은 최고로 늦게 전송되는 시간이기도 하다. 패킷의 유효기간이기 때문에.
-
ACK가 MSL 시간 안에 Server로 전송이 되었다 -> 완벽하게 Close된 상태이다.
-
MSL 시간이 되었는데도 ACK를 Server에서 받지 못했다 -> Server는 다시 Client에게 FIN을 보낸다.
그러면서 다시 MSL시간을 기다린다. 이 때 Client는 자신의 마지막 ACK에 대한 약간의 책임을 지는 것이다.
Client에서 이 FIN을 받으려면 Client는 애초부터 자신이 보낸 ACK 패킷의 MSL 시간과, 이 ACK를 받지 못한 Server로부터 전송되는 FIN 패킷에 대한 MSL시간을 더해서 2MSL을 유지하는 것이다.
거듭 말하지만, Client가 마지막 ACK를 보냈을 때, Server로부터 응답이 온다면 Client가 보낸 ACK가 손실되었다는 뜻이다.
- 이 과정을 거치고도 Server에서 ACK를 못 받게 되면, Server에서는 Client를 Error로 판단하고, 이제부터 같은 IP로부터의 Connection이 들어온다면 RST(TCP Segment의 다른 형식)로 응답한다.
TIME_WAIT 상태에는 두 가지 이유가 있다.
- 신뢰할 수 있는 종료를 위한 TCP의 양방향 연결 구현
- Client에서 Server로 보내는 마지막 ACK가 손실된다.
- Server에서는 MSL시간 동안 기다린 후에도 ACK가 오지 않는다면, FIN을 재전송한다. 이 때, Client는 마지막 ACK를 보내기 위해 TIME_WAIT State를 유지한다.
- 만약 Client가 보낸 ACK를 또 받지 못한다면, TIME_WAIT State를 끝내게 된다(2MSL 시간이 지나서), Server는 이제부터 같은 IP로부터의 Connection이 들어온다면 RST(TCP Segment의 다른 형식)로 응답한다. Server는 이제부터 이 사건을 Error로 인식한다.
- TCP가 양쪽 Data-Flow의 Connection Terminate(Full-Duflex-Close)에 필요한 모든 작업을 완벽히 수행한다면, TCP는 반드시 이 4개의 segment 손실을 다뤄야한다.
- Client에서 Server로 보내는 마지막 ACK가 손실된다.
- 네트워크에서 이전 중복 세그먼트를 만료합니다.
A(12.106.32.254::1500) 와 B(206.168.112.219::21)가 Connection되어 있는 상태라 가정한다.
- Connection이 Close된다. (양 측이 TIME_WAIT 상태가 됨)
- 잠시 후 A와 B를 다시 같은 IP/Port로 Connect시킨다.
- 이것을 Incarnation이라 부른다.
- TCP는 일정 시간 지난 후 다시 생성된 Connection(Incarnation)에서 이전 연결에서 Close되면서 잔류하던 Old Duplicates를 정상적인 패킷으로 인식하지 않아야 한다.
이것을 해결하기 위해 TCP는 TIME_WAIT State 상태인 Connection에서, Incarnation을 허용하지 않는다.
- Connection이 Close된다. (양 측이 TIME_WAIT 상태가 됨)
Port Numbers
UDP, TCP는 모두 16비트 정수 포트 번호를 사용하여 프로세스를 구분
- well-known ports: 0~1023, IANA가 관리
가능하면 TCP와 UDP 모두에 대해 동일한 포트가 지정된 서비스에 할당됩니다.
예를 들어, 포트 80은 웹 서버에 할당되며, 두 프로토콜 모두 현재 모든 구현체가 TCP만 사용하더라도 이벤트가 발생합니다. - registered ports: 1024~49151, IANA가 관리하지 않지만 등록해준다.
- dynamic or private ports: 49152~65535
IANA
인터넷 할당번호 관리기관의 약자로 IP주소, 최상위 도메인 등을 관리하는 단체
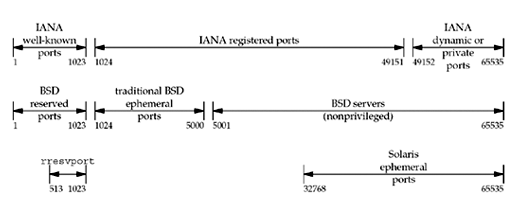
-
Unix에서 예약된 포트 는 1024보다 작은 포트입니다. 이러한 포트는 적절한 권한이 있는 프로세스에 의해서만 소켓에 할당될 수 있습니다. 모든 IANA well-known ports는 예약된 포트입니다. 이 포트를 할당하는 서버는 시작할 때 수퍼유저 권한이 있어야 합니다.
-
역사적으로 버클리에서 파생된 구현(4.3BSD부터 시작)은 1024–5000 범위의 임시 포트 를 할당했습니다. 많은 최신 시스템에서는 IANA에서 정의한 임시 범위 또는 더 큰 범위를 사용하여 더 많은 임시 포트를 제공하기 위해 임시 포트를 다르게 할당합니다.
Socket Pair
socket pair: TCP 연결의 두 끝점인 local IP address, local TCP port, foreign IP address, foreign TCP port를 정의하는 4개의 튜플입니다.
socket pair은 네트워크의 모든 TCP 연결을 고유하게 식별합니다.
socket: 각 엔드포인트를 식별하는 두 개의 값(IP 주소 및 포트 번호).
TCP port Numbers and Concurrent Servers
메인 서버 루프가 각각의 새로운 연결을 처리하기 위해 자식을 생성하는 동시 서버에서 자식이 긴 요청을 처리하는 동안 잘 알려진 포트 번호를 계속 사용하면 어떻게 될까요?
전형적인 순서
먼저, 서버는 IP 주소가 12.106.32.254 및 192.168.42.1인 멀티홈인 freebsd 호스트에서 시작되고 서버는 잘 알려진 포트 번호를 사용하여 수동 열기를 수행합니다. 이제 그림 2.11 에서 볼 수 있는 클라이언트 요청을 기다리고 있습니다.
{:21, :*} 표기법을 사용 하여 서버의 소켓 쌍을 나타냄
서버는 포트 21의 모든 로컬 인터페이스(첫 번째 별표)에 대한 연결 요청을 기다림
외부 IP 주소와 외부 포트는 지정되지 않으며 *:* 로 표시
우리는 이것을 listening socket 이라고 함
로컬 IP 주소를 별표로 지정할 때 와일드카드 문자라고 합니다. 서버가 실행 중인 호스트가 멀티홈인 경우(이 예에서와 같이) 서버는 하나의 특정 로컬 인터페이스에 도착하는 들어오는 연결만 수락하도록 지정할 수 있습니다. 이것은 서버에 대한 하나 또는 모든 선택입니다. 서버는 여러 주소 목록을 지정할 수 없습니다. 와일드카드 로컬 주소는 "임의" 선택입니다. 그림 1.9 에서는 bind 를 호출하기 전에 소켓 주소 구조의 IP 주소를 INADDR_ANY 로 설정하여 와일드카드 주소를 지정했습니다 .
(클라이언트 아래에 소켓 쌍이 표시됨)
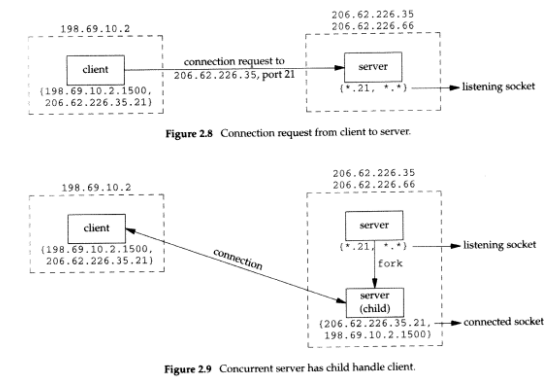
server가 client의 연결을 수신하고 수락하면
자식이 클라이언트를 처리할 수 있도록 자체 복사본을 만듬
이 시점에서 우리는 listening socket과 서버 호스트의 connected socket을 구별해야 합니다.
connected socket은 listening socket과 동일한 로컬 포트(21)를 사용
또한 멀티홈 서버에서 연결이 설정되면 connected socket에 대한 local address가 채워집니다.
다음 단계에서는 클라이언트 호스트의 다른 클라이언트 프로세스가 동일한 서버와의 연결을 요청한다고 가정합니다.
클라이언트 호스트의 TCP 코드는 새 클라이언트 소켓에 사용되지 않은 임시 포트 번호(예: 1501)를 할당합니다. 이것은 밑에 그림에 표시된 시나리오를 제공합니다.
서버에서 두 연결은 구별됩니다. 첫 번째 연결의 소켓 쌍은 두 번째 연결의 소켓 쌍과 다릅니다. 클라이언트의 TCP가 두 번째 연결(1501)에 사용되지 않는 포트를 선택하기 때문입니다.
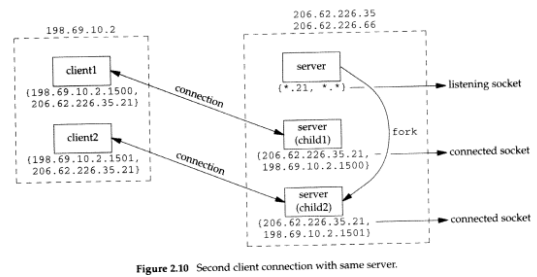
이 예에서 TCP는 대상 포트 번호만 보고 들어오는 세그먼트를 역다중화할 수 없습니다. TCP는 소켓 쌍의 4가지 요소를 모두 확인하여 도착하는 세그먼트를 수신하는 엔드포인트를 결정해야 합니다.
위 그림에는 동일한 로컬 포트(21)를 가진 3개의 소켓이 있습니다.
세그먼트가 12.106.32.254 포트 21로 향하는 206.168.112.219 포트 1500에서 도착하면 첫 번째 자식에게 전달됩니다. 12.106.32.254 포트 21로 향하는 206.168.112.219 포트 1501에서 세그먼트가 도착하면 두 번째 자식에게 전달됩니다. 포트 21로 향하는 다른 모든 TCP 세그먼트는 수신 대기 소켓이 있는 원래 서버로 전달됩니다.
Buffer Sizes and Limitations
특정한 limit들은 IP datagram에 영향을 준다.
payload: 사용에 있어서 전송되는 데이터
전송의 근본적인 목적이 되는 데이터의 일부분으로 그 데이터와 함께 전송되는 헤더와 메타데이터와 같은 데이터는 제외함
단편화(Fragmentation)(세분화(Segmentation))
MTU 보다 큰 데이터그램은 전송이 불가능 하기 때문에 MTU 보다 작은 크기로 만들어 주는 과정
단편화 과정을 가지고 주체는 송신자, 라우터 모두 가능하다.
단편화를 거쳐서 수신지 까지 도착하게 되면 수신자가 재조립(Reassembly)을 과정을 거치게 된다.
재조립(Reassembly)
최종 수신지에 도착한 데이터그램 단편들을 수신자가 보낸 데이터그램으로 다시 조립하는 과정
특정한 limit들은 IP datagram 크기에 영향을 준다. 이러한 limit들에 대한 설명을 하고 그 다음에 application에서 전송되는 data에 어떻게 영향을 주는지에 대해 알아보도록 하자.
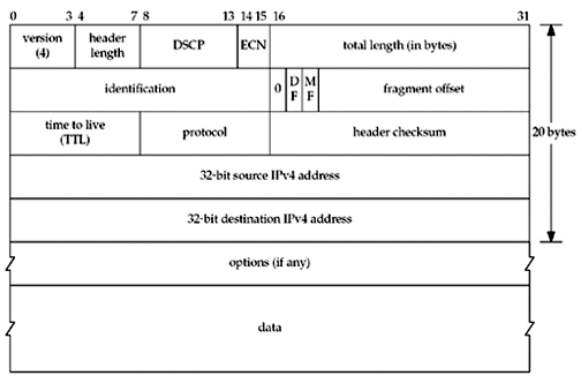
1> IPv4 datagram의 최고 크기는 IPv4 헤더까지 합쳐서 65,535 바이트이다. 아래 그림 1의 total length 필드 때문에 길이가 65,535바이트 인 것이다.
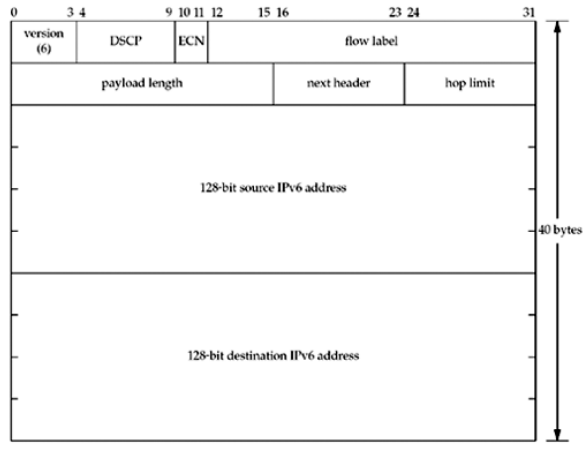
2> IPv6 datagram의 최고 크기는 40바이트의 IPv6 헤더까지 합쳐서 65,575 바이트이다. 이 길이는 아래 그림 2의 16-bit의 payload length때문에 그렇다. IPv6의 payload length 필드는 IPv6의 헤더 크기를 포함하지 않는 반면, IPv4 total length는 헤더 사이즈까지 포함한다.
IPv6는 jumbo payload 옵션을 가지고 있는데, 이것은 payload length 필드를 32-bit로 확장해주지만 65,535이상의 최대 전송 단위(maximum transmission unit / MTU)를 제공해주는 datalink에서만 지원한다. (이러한 옵션은 내재된 MTU가 없는 HIPPI같은 host-to-host interconnect를 위해 존재한다.)
3> 많은 네트워크들은 하드웨어에 따른 MTU를 가지고 있다. 예를들어 Ethernet의 MTU는 1,500 바이트이다. Point-to-Point Protocol(PPP)를 사용하는 point-to-point link와 같은 다른 datalink들은 설정가능한 MTU를 가지고 있다. SLIP link는 보통 1,006 또는 296 바이트의 MTU를 사용한다.
IPv4에서 최소 MTU는 68바이트이다. 이러한 크기의 MTU는 최고 사이즈의 IPv4 헤더(20바이트의 고정헤더, 30바이트의 옵션)와 최소 사이즈의 fragment(이 fragment의 offset은 8바이트 단위이다.)를 포함할 수 있도록 해준다. IPv6의 최소 MTU는 1,280 바이트이다. IPv6는 더 작은 MTU를 이용해 link를 작동할 수 있지만, link가 최소 1,280바이트의 MTU를 가지고 있는 것처럼 보이게 하는 link-specific 분해(fragmentation)과 재조립(reassembly)를 요구한다.
여기서 한가지 주목할 점은 이전 포스트에서 말한 MSS(maximum segment size)를 MTU와 연관지을 수 있다. 전송할 수 있는 사용자 데이터의 최대 크기인 MSS는 MTU의 크기에 영향을 받는다. Ethernet과 같이 MTU가 1,500바이트이면, MSS = MTU(1500) - IP헤더(20) - TCP헤더(20) = 1460바이트이다.
4> 두 호스트간의 연결에서 전송중에 지나는 여러 네트워크 중에서 가장 작은 MTU를 경로 MTU(path MTU) 라고 부른다.(즉, 양단간의 경로에서 지나는 서로다른 MTU를 갖는 여러 네트워크 중 최소값) 요즘은 Ethernet의 MTU(1500바이트)가 보통 path MTU이다. 두 호스트 사이의 연결에서 각 방향의 path MTU가 서로 같을 필요는 없다. 왜냐하면 Internet에서 routing은 보통 비대칭(asymmetric)이기 때문이다. 이 말은 호스트 A, B가 있다고 가정할 때, A로부터 B로의 route는 B로부터 A로의 route와 달라도 된다는 말이다.
5> 인터페이스 바깥으로 IP datagram이 나갈 때, 만약 이 datagram이 link의 MTU를 초과한다면 fragmentation 이 IPv4와 IPv6에 의해 일어난다. 이렇게 나눠진 fragment들은 보통 최종 목적지에 도착할 때까지 재조립(reassembly)되지 않는다. IPv4에서는 호스트가 자신이 만든 데이터그램을 fragmentation하기도 하고, 전송되는 도중 라우터가 fragmentation 하기도 하지만, IPv6에서는 오직 호스트만 fragmentation를 수행한다.
IPv6 라우터로 분류된 라우터도 fragmentation을 수행한다. 그러나 오직 자신이 만든 datagram에 대해서만 수행한다. 라우터가 IPv6 datagram을 생성할 때는 마치 호스트처럼 작동한다. 예를들어, 대부분의 라우터들은 Telnet protocol을 지원하고, 이 프로토콜은 관리자에 의해 라우터 환경설정을 위해 사용된다. 이러한 IP datagram들은 라우터가 만든 라우터 Telnet 서버에 의해 생성된다.
그림 1을 보면 IPv4헤더에는 IPv4 fragmentation을 다루는 필드들이 존재함을 알 수 있는데, 그림 2를 보면 IPv6헤더에는 이러한 필드들이 없다. fragmentation은 규칙이라기 보다는 예외이기 때문에, IPv6는 fragmentation의 정보에 대한 option header를 포함한다.
라우터같이 작동하는 방화벽들은 패킷 내용을 검사하기 위해 분해된 패킷들을 재조립 할수도 있다. 이러한 방법은 방화벽이 추가적인 비용(complexity cost)으로 특정한 공격들을 막도록 해준다. 또한 이 방법은 네트워크로 진행하는 유일한 경로의 일부가 돼야하는데, 불필요한 중복을 줄이기 위한 것이다.
6> 만약 그림 1에서 IPv4헤더에 DF(don't fragment)라고 표시된 필드가 설정되면, 이 datagram은 호스트나 라우터에 의해 절대 분해돼서는 안된다고 명시하는 것이다. 송신 link의 MTU를 초과하고 DF bit가 설정된 IPv4 datagram을 수신한 라우터는 아래 그림 3의 "분해가 필요하지만 DF bit가 설정돼있어 목적지에 도달할 수 없다"("destination unreachable, fragmentation needed but DF bit set")는 ICMPv4 에러 메시지를 생성한다.
IPv6 라우터들은 fragmentation을 수행하지 않기 때문에 모든 IPv6 datagram에는 DF bit가 함축되어있다. IPv6 라우터가 송신 link의 MTU를 초과하는 datagram을 송신하면, 라우터는 아래 그림 4의 "패킷이 너무 크다"("packet too big")는 ICMPv6 에러 메시지를 생성한다.
IPv4 DF bit와 IPv6의 함축된 DF는 경로 MTU 탐색(path MTU discovery, IPv4에서는 RFC 1191 [Mogul and Deering 1990], IPv6에서는 RFC1981 [McCann, Deering, and Mogul 1996])를 위해 사용될 수 있다. 예를들어, TCP는 이 탐색을 IPv4에서 사용하고, DF bit가 설정된 모든 datagram에게 보낸다. 중간에 라우터가 "destination unreachable, fragmentation needed but DF bit set"의 ICMP 에러를 보내면, TCP는 datagram마다 보내는 데이터의 양을 줄이고 재전송한다. path MTU discovery는 IPv4에서는 옵션이고, 모든 IPv6에서는 path MTU discovery를 지원하며 최소 MTU를 이용해 송신한다.
요새 Internet에서는 path MTU discovery는 문제가 많다. 그 이유는 많은 방화벽들이 fragmentation이 필요하다는 메시지를 포함한 모든 ICMP 메시지를 삭제했기 때문이다. 그래서 TCP는 자신이 보내는 메시지 크기를 줄여야 한다는 신호를 받지 못한다. 그래서 요즘에는 IETF에서 ICMP 에러에 의존하지 않기 위해, path MTU discovery를 대체하기 위한 방법을 정의하는 노력을 하고있다.
7> IPv4와 IPv6는 어떤 구현이든 지원해야하는 최소 datagram size를 minimum reassembly buffer size라고 정의한다. IPv4에서는 576바이트이고 IPv6에서는 1,500바이트이다. 예를들어 IPv4에서 우리는 목적지에서 577바이트의 datagram을 받을 수 있는지 없는지를 알 수 없다. 그러므로 많은 UDP/IPv4 어플리케이션은 이 사이즈를 넘는 IP datagram의 생성을 제한한다.
UDP는 fragmentation을 피하기 위해서 minimum reassembly buffer size보다 작은 데이터그램을 전송한다. TCP의 경우 fragmentation을 피하기 위해 path MTU discovery를 사용하는데 UDP는 이러한 처리가 없기 때문이다. 참고로 fragmentation은 TCP에서 많은 양의 재전송을 요구할 수 있으므로 피하는 것이 좋다. UDP도 마찬가지로 라우팅 처리의 효율을 위해서 피하는 것이 좋다.
8> TCP는 peer에게 전송 시 한 segment마다 담을 수 있는 최대 TCP데이터의 양인 maximum segment size(MSS)를 가지고 있다. 아래 그림 5를 보면 TCP가 연결 수립 시 SYN에 MSS를 담아서 보내는 것을 볼 수 있다.
MSS의 목표는 fragmentation을 피하기 위해, 재조립 버퍼 크기(reassembly buffer size)의 실제 값을 peer에게 알려주는 것이다. MSS는 보통 MTU - 고정 IP헤더 - 고정 TCP헤더로 정해진다. IPv4를 사용하는 Ethernet에선 MSS는 1,460이 될 것이고 IPv6에서는 1,440이 될 것이다. (IPv6의 헤더는 IPv4것보다 20바이트 크다)
TCP의 MSS 옵션의 MSS 값은 최대 65,535의 16비트 필드이다. 이크기는 IPv4 데이터그램에서 TCP data의 최대크기는 65,495(65,535에서 IPv4헤더 20바이트와 TCP헤더 20바이트 뺀 것)이기 때문에 IPv4에서는 충분하다. 그러나 IPv6의 jumbo payload 옵션에선 다른 기술이 사용된다. (RFC 2675 [Borman, Deering, and Hinden 1999]) 첫번째로 IPv6 데이터그램에서 jumbo payload 옵션 없이 TCP data의 최대 크기는 65,515(65,535에서 20바이트의 TCP 헤더 뺀 것)바이트이다. 그러므로 MSS 값이 65,535바이트라는 것은 "infinity"를 지칭하는 특별한 경우로 여겨진다. 이 값은 jumbo payload 옵션이 사용되는 경우에만 사용되며, 65,535를 초과하는 MTU를 요구한다. 만약 TCP가 jumbo payload 옵션을 사용하고 65,535의 MSS를 peer로부터 받는다면, peer가 보내는 데이터그램 크기의 한계는 interface MTU일 뿐이다. 만약 이것이 너무 큰것으로 나타난다면(즉, 경로에 더 작은 MTU를 가진 링크가 존재한다면), path MTU discovery가 더 작은 값을 결정한다.
9> SCTP는 모든 peer의 주소에 대해서 가장 작은 path MTU를 찾아서, 그것을 기준으로 fragmentation point를 유지한다. 이 가장 작은 MTU 크기는 큰 user message들을 작은 조각들로 나누어, 하나의 IP datagram에 담아서 보낼 수 있도록 하기위해 사용된다. SCTP_MAXSEG 소켓 옵션은 이 값에 영향을 줄 수 있으며, user가 더 작은 fragmentation point를 요청할 수 있도록 해준다.
TCP output
다음 그림은 애플리케이션이 TCP 소켓에 쓸 때 어떤 일이 발생하는지 보여줍니다.
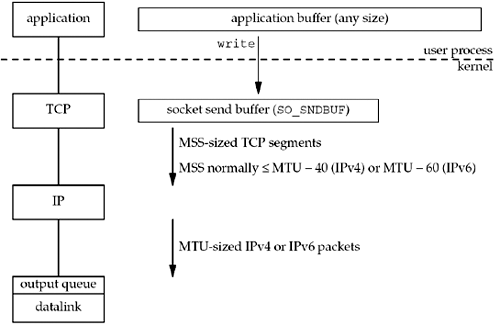
SO_SNDBUF: 모든 TCP 소켓에는 전송 버퍼가 있으며 socket 옵션을 사용하여 이 버퍼의 크기를 변경할 수 있음
1. 응용 프로그램이 write를 호출하면 커널은 응용 프로그램 버퍼의 모든 데이터를 소켓 전송 버퍼로 복사
소켓 버퍼에 모든 응용 프로그램의 데이터에 대한 공간이 충분하지 않으면 프로세스가 절전 모드로 전환
이것은 blocking 소켓의 일반적인 기본값을 가정합니다.
- 커널은 write응용 프로그램 버퍼의 마지막 바이트가 소켓 전송 버퍼에 복사될 때까지 반환되지 않음
따라서 쓰기에서 TCP 소켓으로의 성공적인 반환은 애플리케이션 버퍼를 재사용할 수 있음을 알려줍니다.
peer TCP가 데이터를 수신했거나 peer 애플리케이션이 데이터를 수신했음을 알려주지 않습니다.
- 네트워크에서는 동등하거나 비슷한 성능을 가진 컴퓨터들을 peer로 간주하고 이들이 1:1 대응을 이루며 연결된 것을 p2p라고함
-
TCP는 소켓 송신 버퍼의 데이터를 가져와 peer TCP로 보냅니다. peer TCP는 데이터를 승인해야 하며 ACK가 peer로부터 도착하면 TCP가 소켓 전송 버퍼에서 승인된 데이터를 버릴 수 있음. TCP는 peer가 승인할 때까지 데이터 복사본을 유지해야함
-
TCP는 데이터를 MSS 크기 이하의 청크로 IP에 전송하고 TCP 헤더를 각 세그먼트 앞에 추가합니다. 여기서 MSS는 피어가 발표한 값이고 피어가 MSS 옵션을 보내지 않은 경우 536입니다.
-
IP는 헤더를 추가하고 대상 IP 주소에 대한 라우팅 테이블을 검색하고 datagram을 적절한 data link로 전달합니다.
IP는 datagram을 datalink로 전달하기 전에 단편화를 수행할 수 있지만 MSS 옵션의 한 가지 목표는 단편화를 방지하는 것이며 최신 구현에서도 경로 MTU 검색을 사용합니다. 각 datalink에는 출력 대기열이 있으며 이 대기열이 가득 차면 패킷이 폐기되고 프로토콜 스택에 오류가 반환됩니다
UDP output
다음 그림은 애플리케이션이 UDP 소켓에 데이터를 쓸 때 어떤 일이 발생하는지 보여줍니다.
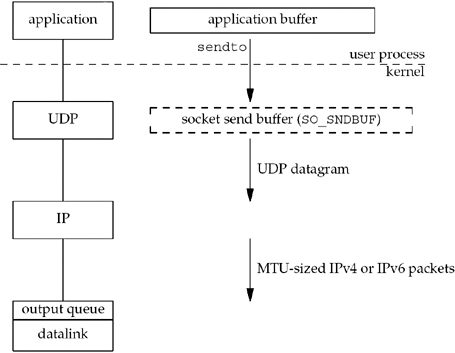
UDP 소켓에는 응용 프로그램 데이터의 복사본을 유지할 필요가 없기 때문에 소켓 보내기 버퍼가 없습니다.
이것은 전송 버퍼 크기(소켓 옵션으로 변경할 수 SO_SNDBUF있음)를 갖지만 소켓에 쓸 수 있는 최대 크기의 UDP 데이터그램의 상한선일 뿐
응용 프로그램이 소켓 보내기 버퍼 크기보다 큰 데이터그램을 쓰는 경우 EMSGSIZE반환
UDP는 단순히 8바이트 헤더를 추가하고 datagram을 IP로 전달합니다.
IP는 라우팅 기능을 수행하여 나가는 인터페이스를 결정한 다음 datagram을 datalink 출력 대기열에 추가하거나(MTU 내에 맞는 경우) datagram을 단편화하고 각 조각을 datalink 출력 대기열에 추가합니다
UDP 응용 프로그램이 큰 datagram을 보내는 경우 TCP보다 단편화 가능성이 훨씬 더 높습니다.
