
구글 드라이브에 저장된 이미지 데이터셋을 Colab에서 읽어 CNN 모델을 훈련하는 코드입니다.
데이터셋에는 가위, 바위, 보 모양의 손 이미지가 각각 964개씩 저장되어 있습니다. CNN 모델을 훈련하여 테스트 데이터셋에서 1.0의 정확도를 얻는 것이 목표입니다.
다음번에도 쉽게 사용할 수 있도록 포스팅합니다.
data 압축 해제
데이터는 구글 드라이브의 data 폴더에 저장된 상황입니다. zipfile 라이브러리를 사용하여 압축을 해제합니다.
import zipfile
zip_file = zipfile.ZipFile('/content/drive/MyDrive/data.zip', 'r')
extract_dir = 'data'
zip_file.extractall(extract_dir)이 코드를 실행하면 Colab의 파일에 압축 해제된 데이터셋이 생성됩니다.
데이터셋 생성
다음으로 데이터셋을 분할합니다. data 폴더 아래의 rock, scissors, paper 폴더들을 train/rock, val/rock, test/rock 등으로 훈련/검증/테스트용 데이터셋으로 분할합니다.
전체 데이터셋의 20%를 테스트 데이터셋으로 사용할 것입니다.
964 * 2 / 10출력
192.8
192개의 이미지를 테스트 데이터로 사용하고, 700개의 이미지를 훈련 데이터, 72개의 이미지를 검증 데이터로 사용합니다.
import os
train_dir = 'train'
os.mkdir(train_dir)
val_dir = 'val'
os.mkdir(val_dir)
test_dir = 'test'
os.mkdir(test_dir)
# 훈련 데이터셋
train_rock_dir = os.path.join(train_dir, 'rock')
os.mkdir(train_rock_dir)
train_scissors_dir = os.path.join(train_dir, 'scissors')
os.mkdir(train_scissors_dir)
train_paper_dir = os.path.join(train_dir, 'paper')
os.mkdir(train_paper_dir)
# 검증 데이터셋
val_rock_dir = os.path.join(val_dir, 'rock')
os.mkdir(val_rock_dir)
val_scissors_dir = os.path.join(val_dir, 'scissors')
os.mkdir(val_scissors_dir)
val_paper_dir = os.path.join(val_dir, 'paper')
os.mkdir(val_paper_dir)
# 테스트 데이터셋
test_rock_dir = os.path.join(test_dir, 'rock')
os.mkdir(test_rock_dir)
test_scissors_dir = os.path.join(test_dir, 'scissors')
os.mkdir(test_scissors_dir)
test_paper_dir = os.path.join(test_dir, 'paper')
os.mkdir(test_paper_dir)import random
import shutil
# rock
original_folder_path = '/content/data/rock'
all_files = os.listdir(original_folder_path)
# 데이터를 한 차례 셔플
random.shuffle(all_files)
destination_folder_path = '/content/train/rock'
# 훈련 데이터셋은 700개의 샘플
for file_name in all_files[:700]:
file_path = os.path.join(original_folder_path, file_name)
shutil.move(file_path, destination_folder_path)
destination_folder_path = '/content/val/rock'
# 검증 데이터셋은 72개의 샘플
for file_name in all_files[700:772]:
file_path = os.path.join(original_folder_path, file_name)
shutil.move(file_path, destination_folder_path)
destination_folder_path = '/content/test/rock'
# 테스트 데이터셋은 나머지 샘플
for file_name in all_files[772:]:
file_path = os.path.join(original_folder_path, file_name)
shutil.move(file_path, destination_folder_path)
# scissors
original_folder_path = '/content/data/scissors'
all_files = os.listdir(original_folder_path)
# 데이터를 한 차례 셔플
random.shuffle(all_files)
destination_folder_path = '/content/train/scissors'
# 훈련 데이터셋은 700개의 샘플
for file_name in all_files[:700]:
file_path = os.path.join(original_folder_path, file_name)
shutil.move(file_path, destination_folder_path)
destination_folder_path = '/content/val/scissors'
# 검증 데이터셋은 72개의 샘플
for file_name in all_files[700:772]:
file_path = os.path.join(original_folder_path, file_name)
shutil.move(file_path, destination_folder_path)
destination_folder_path = '/content/test/scissors'
# 테스트 데이터셋은 나머지 샘플
for file_name in all_files[772:]:
file_path = os.path.join(original_folder_path, file_name)
shutil.move(file_path, destination_folder_path)
# paper
original_folder_path = '/content/data/paper'
all_files = os.listdir(original_folder_path)
# 데이터를 한 차례 셔플
random.shuffle(all_files)
destination_folder_path = '/content/train/paper'
# 훈련 데이터셋은 700개의 샘플
for file_name in all_files[:700]:
file_path = os.path.join(original_folder_path, file_name)
shutil.move(file_path, destination_folder_path)
destination_folder_path = '/content/val/paper'
# 검증 데이터셋은 72개의 샘플
for file_name in all_files[700:772]:
file_path = os.path.join(original_folder_path, file_name)
shutil.move(file_path, destination_folder_path)
destination_folder_path = '/content/test/paper'
# 테스트 데이터셋은 나머지 샘플
for file_name in all_files[772:]:
file_path = os.path.join(original_folder_path, file_name)
shutil.move(file_path, destination_folder_path) print('훈련용 rock 이미지 전체 개수:', len(os.listdir('/content/train/rock')))
print('검증용 rock 이미지 전체 개수:', len(os.listdir('/content/val/rock')))
print('테스트용 rock 이미지 전체 개수:', len(os.listdir('/content/test/rock')))
print()
print('훈련용 scissors 이미지 전체 개수:', len(os.listdir('/content/train/scissors')))
print('검증용 scissors 이미지 전체 개수:', len(os.listdir('/content/val/scissors')))
print('테스트용 scissors 이미지 전체 개수:', len(os.listdir('/content/test/scissors')))
print()
print('훈련용 paper 이미지 전체 개수:', len(os.listdir('/content/train/paper')))
print('검증용 paper 이미지 전체 개수:', len(os.listdir('/content/val/paper')))
print('테스트용 paper 이미지 전체 개수:', len(os.listdir('/content/test/paper')))출력
훈련용 rock 이미지 전체 개수: 700
검증용 rock 이미지 전체 개수: 72
테스트용 rock 이미지 전체 개수: 192
훈련용 scissors 이미지 전체 개수: 700
검증용 scissors 이미지 전체 개수: 72
테스트용 scissors 이미지 전체 개수: 192
훈련용 paper 이미지 전체 개수: 700
검증용 paper 이미지 전체 개수: 72
테스트용 paper 이미지 전체 개수: 192
모델 구성
Conv2D, MaxPooling2D, Flatten, Dense layer를 사용하여 합성곱 모델을 구성합니다.
케라스를 사용합니다.
from tensorflow.keras import layers
from tensorflow.keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy',
metrics=['accuracy'])데이터 전처리 및 모델 훈련
케라스의 ImageDataGenerator를 사용하여 데이터를 전처리하고 모델을 훈련합니다.
가위, 바위, 보 세 개의 target이 있으므로 class_mode를 'categorical'로 설정합니다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 스케일 조정
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=12,
class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(
val_dir,
target_size=(150, 150),
batch_size=12,
class_mode='categorical')출력
Found 2100 images belonging to 3 classes.
Found 216 images belonging to 3 classes.
아래 fit_generator 코드를 실행하면 UserWarning 경고가 출력됩니다(아래에서는 지웠습니다). Model.fit 메서드를 사용하면 해결되는 경고입니다.
history = model.fit_generator(train_generator,
steps_per_epoch=175,
epochs=10,
validation_data=validation_generator,
validation_steps=18)출력
Epoch 1/10
175/175 [==============================] - 5s 23ms/step - loss: 0.4776 - accuracy: 0.7895 - val_loss: 0.1345 - val_accuracy: 0.9444
Epoch 2/10
175/175 [==============================] - 4s 24ms/step - loss: 0.0455 - accuracy: 0.9848 - val_loss: 0.0047 - val_accuracy: 1.0000
Epoch 3/10
175/175 [==============================] - 3s 19ms/step - loss: 3.6942e-04 - accuracy: 1.0000 - val_loss: 9.2299e-06 - val_accuracy: 1.0000
Epoch 4/10
175/175 [==============================] - 3s 18ms/step - loss: 5.5246e-06 - accuracy: 1.0000 - val_loss: 3.1992e-06 - val_accuracy: 1.0000
Epoch 5/10
175/175 [==============================] - 4s 25ms/step - loss: 1.3237e-06 - accuracy: 1.0000 - val_loss: 1.3874e-06 - val_accuracy: 1.0000
Epoch 6/10
175/175 [==============================] - 4s 22ms/step - loss: 6.9398e-07 - accuracy: 1.0000 - val_loss: 9.5642e-07 - val_accuracy: 1.0000
Epoch 7/10
175/175 [==============================] - 4s 24ms/step - loss: 5.3300e-07 - accuracy: 1.0000 - val_loss: 7.6492e-07 - val_accuracy: 1.0000
Epoch 8/10
175/175 [==============================] - 5s 29ms/step - loss: 4.0785e-07 - accuracy: 1.0000 - val_loss: 5.9990e-07 - val_accuracy: 1.0000
Epoch 9/10
175/175 [==============================] - 3s 18ms/step - loss: 3.5398e-07 - accuracy: 1.0000 - val_loss: 5.0884e-07 - val_accuracy: 1.0000
Epoch 10/10
175/175 [==============================] - 4s 25ms/step - loss: 3.1374e-07 - accuracy: 1.0000 - val_loss: 4.4317e-07 - val_accuracy: 1.0000
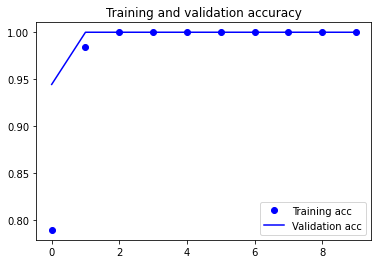
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
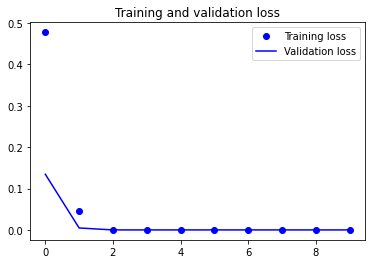
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()출력
테스트 데이터 예측
테스트 데이터셋을 예측해 보겠습니다.
마찬가지로 아래 코드를 실행하면 UserWarning 경고가 출력됩니다(아래에서는 지웠습니다). Model.evaluate를 사용하면 해결되는 경고입니다.
test_generator = test_datagen.flow_from_directory(test_dir,
target_size=(150, 150),
batch_size=12,
class_mode='categorical')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=48)
print('test acc:', test_acc)출력
Found 576 images belonging to 3 classes.
test acc: 1.0
테스트 데이터셋에서 1.0의 정확도를 얻었습니다.
