
이번 포스팅은 학기 중 진행했던 딥러닝 프로그래밍 프로젝트의 일부를 담고 있습니다.
프로젝트 개요
지난 학기 <딥러닝프로그래밍> 과목의 기말 프로젝트는 포켓몬 데이터셋을 활용하여 딥러닝과 관련된 자유로운 주제로 연구를 진행하는 것이었습니다. 포켓몬 데이터셋은 1세대 포켓몬 149종에 대한 이미지 데이터셋이었으며, 각 포켓몬당 적게는 40장, 많게는 300장 가량의 이미지가 포함되었습니다. 아래 이미지는 데이터셋의 일부입니다.
이미지 데이터를 사용하여 딥러닝 기술을 적용해야 했기 때문에, 저희 팀에서 첫 번째로 나온 의견은 1) 포켓몬 분류 모델과 2) 포켓몬 생성 모델이었습니다. ResNet, Inception 등을 사용하여 포켓몬을 정확히 분류하는 모델을 구축하거나, DCGAN 등을 사용하여 포켓몬 이미지를 생성하는 모델을 생각해 보았습니다.
그러던 중, 포켓몬별 이미지를 확인할 때 다음과 같은 이미지들을 찾아낼 수 있었습니다.


위 이미지 2장은 <Charmander: 파이리> 폴더에 저장된 이미지입니다. 파이리 클래스에 속하는 이미지임에도 불구하고, 꼬부기, 피카츄, 이상해씨 등 다른 포켓몬들이 이미지에 포함되어 있었습니다. 이러한 현상은 파이리 클래스에서만 발생한 것이 아닌, 다른 포켓몬에서도 발생하였습니다.
전체 데이터셋에 속한 이미지가 10,000장 정도가 되었기 때문에 일일히 중복되거나 잘못된 이미지를 찾아 수정하기에는 어려웠고, 이렇게 잘못된 데이터셋을 기반으로 모델을 학습시키기엔 좋은 성능을 얻기 어려울 듯하여 분류 및 생성 모델 구현은 고려하지 않았습니다.
저희 팀은 데이터셋에 존재하는 이미지 중, 다른 레이블의 포켓몬이 중복되어 나타나는 문제 자체에 집중하였고, 이러한 문제를 해결하기 위하여 Self Extraction 알고리즘을 고안하였습니다.
알고리즘의 목표는 이미지 내 다양한 객체에서, 해당 레이블에 속하는 객체만을 찾아내 새로 이미지를 생성하는 것이었습니다. 위의 두 이미지로 예를 들면, 두 이미지를 입력하였을 때 아래의 결과가 출력되는 것입니다.

전체 데이터셋에 알고리즘을 적용한다면, 결과적으로 더욱 품질이 좋고 정확한 훈련 데이터셋을 얻을 수 있을 것이라 기대하였습니다.
프로젝트의 간단한 개요 설명은 여기까지 하도록 하고, 구현하고자 한 Self Extraction 알고리즘에 대해 더 자세히 알아보겠습니다.
Self Extraction
Self Extraction 알고리즘은 단일 이미지 내 여러 객체가 있어 분류 작업에 어려움이 있을 때, 이미지의 분할 중 분류 작업에 가장 적절한 분할을 제시하는 알고리즘입니다.
위의 첫 번째 이미지(파이리와 꼬부기)를 예로 들면, Self Extraction 알고리즘의 목표는 이런 이미지의 분할 중 예측 레이블이 ‘파이리’가 되며, 그때의 예측 확률이 가장 높아지는 이미지의 분할을 찾는 것입니다.
Self Extraction 알고리즘의 기본 개념은 전체 이미지를 크기의 격자로 나눈 뒤, 일정한 크기(, 와 은 양의 정수)의 분할을 여러 개 추출하여 추출한 부분을 모델에 입력하는 것입니다.
예를 들어 레이블이 '피카츄'인 이미지를 크기의 격자로 나눈 것은 다음과 같습니다.

크기의 분할을 추출하는 방법은 합성곱 연산에서 커널을 입력 이미지에 슬라이딩하는 것과 같이 진행됩니다. 따라서 이미지의 분할을 추출하는 과정을 “슬라이딩 연산”이라 명명하였습니다.
슬라이딩 연산의 예시는 다음과 같습니다. 정사각형의 전체 이미지를 크기의 격자로 나눴을 때 격자 한 칸의 가로(또는 세로) 길이를 이라 하겠습니다.
이미지의 좌측 상단을 이미지의 원점 ()이라고 생각하면, {왼쪽 상단 점 (), 오른쪽 하단 점 ()}로 이루어진 사각형의 분할을 추출한 뒤에는 {(, 0), ()}으로 이루어진 분할, 그다음에는 {(), ()}로 이루어진 분할을 추출하는 것입니다. 이러한 과정을 그림으로 나타내면 아래와 같습니다. 아래 예시는 일 때의 경우입니다.
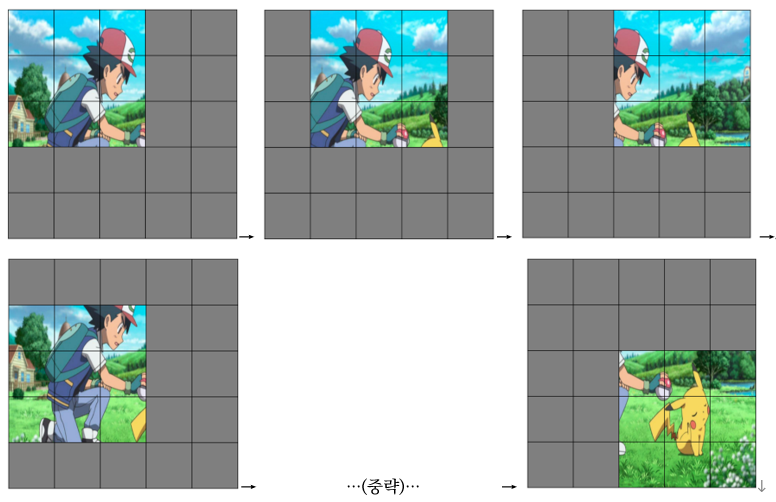
전체 이미지 격자와 추출되는 분할이 모두 와 같이 같은 크기를 가지므로, 이러한 슬라이딩 연산은 번 진행하게 됩니다.
슬라이딩 연산 후, {}, {}, {}, {}, {} 등으로 이루어진 분할을 추가로 추출하여 최종적으로 개의 분할을 추출하게 됩니다. 추가로 추출한 분할들은 다음과 같습니다.


이렇게 추출된 모든 분할을 CNN 모델에 입력한 후, 각 분할에 대한 점수를 확인하여 전체 이미지보다 예측 확률이 높은 분할을 새로운 훈련 이미지 데이터로 사용합니다. 추출된 분할을 평가할 CNN 모델이 필요하기 때문에, 전이 학습을 사용하여 ResNet, VGGNet 등 CNN 모델을 사전에 훈련하였습니다(원본 데이터셋으로 훈련).
위의 예시에서는 정사각형의 이미지를 가정하였지만, 실제로 이미지의 가로/세로 길이가 같지 않아도 됩니다. 이미지가 직사각형의 형태일 경우, 격자 한 칸의 가로/세로 길이는 달라지겠지만 전체 이미지를 크기의 격자로 나누는 것은 동일하기에 이후 슬라이딩 연산은 동일하게 진행할 수 있습니다.
단일 이미지 내 여러 객체가 있는 경우, R-CNN, Yolo와 같은 방법으로 객체를 검출하여 검출된 부분을 잘라내는 방법을 생각할 수 있습니다. 하지만 주어진 포켓몬 이미지 데이터셋과 같이, 데이터셋에 바운딩 박스가 그려져 있지 않은 경우에는 객체 검출을 위한 모델을 훈련할 수 없습니다.
또한 Yolo 모델을 포켓몬 이미지에 적용했을 때, 모델의 confidence threshold 값을 여러 번 조정해 봐도 포켓몬이 객체로 인식되지 않아 Yolo 모델을 사용한 객체 인식을 사용할 수 없음을 실험적으로 확인하였습니다.
다음으로 실제 코드 구현을 확인해 보겠습니다.
전이 학습
전이 학습을 사용하여 CNN 모델을 훈련합니다. 이 모델은 전체 이미지 및 분할된 이미지를 입력받아 어떤 레이블인지 추론합니다. Inception, ResNet, EfficientNet 등 어떤 모델을 사용해도 상관없으나, 여기서는 간단히 keras의 VGG16을 사용하였습니다.
import pandas as pd
import numpy as np
import zipfile
import shutil
import os
from keras import models, layers
from keras.preprocessing.image import ImageDataGenerator
from keras.applications import VGG16
# Data Import
# 포켓몬 데이터는 구글 드라이브에 저장
# .zip 파일 압축 해제
zip_file = zipfile.ZipFile('/content/drive/MyDrive/Pokemon_1stGen.zip', 'r')
extract_dir = 'train'
zip_file.extractall(extract_dir)
# 테스트 데이터셋 생성
os.mkdir('test')
dir = 'train'
dst = 'test'
for pokemon in os.listdir('train'):
pokemon_path = os.path.join(dir, pokemon)
os.mkdir(os.path.join(dst, pokemon))
test_pokemon_path = os.path.join(dst, pokemon)
# 처음 20장을 테스트 데이터로 사용
for file in os.listdir(pokemon_path)[:20]:
file_path = os.path.join(pokemon_path, file)
shutil.move(file_path, test_pokemon_path)# Preprocessing
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory('train',
target_size=(150, 150),
batch_size=100,
class_mode='categorical')
test_generator = test_datagen.flow_from_directory('test',
target_size=(150, 150),
batch_size=100,
class_mode='categorical')출력
Found 6655 images belonging to 149 classes.
Found 2966 images belonging to 149 classes.
# Model: VGG16
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(149, activation='softmax'))
# conv_base 동결
conv_base.trainable = False
model.compile(loss='categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(train_generator,
steps_per_epoch=67,
epochs=30,
validation_data=test_generator,
validation_steps=30)
# 모델 저장
model.save('test.h5') 간단한 방법으로 CNN 모델을 훈련하였습니다. VGG 외의 다른 모델을 사용해도 되고, 데이터 증강 / 가중치 동결 방법 / 추가 Dense layer 등 다양한 부분을 수정하여 성능이 더 좋은 모델을 훈련시킬 수 있으나 이번 프로젝트의 목표는 최고의 성능을 가지는 모델을 구현하는 것이 아니기 때문에 간단히 넘어가겠습니다.
알고리즘 구현
다음은 Self Extraction 알고리즘의 구현 부분입니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import zipfile
import shutil
import os
from PIL import Image, ImageOps
from keras.models import load_model
from keras.preprocessing.image import ImageDataGenerator
from keras import layers, models
# 경고메세지 끄기
import warnings
warnings.filterwarnings(action='ignore')
zip_file = zipfile.ZipFile('/content/drive/MyDrive/Pokemon_1stGen.zip', 'r')
extract_dir = 'train'
zip_file.extractall(extract_dir)
# 사전 훈련된 모델
model = load_model('/content/drive/MyDrive/test.h5')
model.summary()출력
Model: "sequential_7"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 4, 4, 512) 14714688
flatten_7 (Flatten) (None, 8192) 0
dense_17 (Dense) (None, 256) 2097408
dropout_7 (Dropout) (None, 256) 0
dense_18 (Dense) (None, 149) 38293
=================================================================
Total params: 16,850,389
Trainable params: 2,135,701
Non-trainable params: 14,714,688
_________________________________________________________________여러 함수를 미리 정의합니다.
# 폴더 내 모든 이미지 파일 확인
def load_image_from_directory(path):
files = []
all_file = sorted(os.listdir(path))
for file in all_file:
if file.endswith('ipynb_checkpoints'):
continue
files.append(os.path.join(path, file))
return files# 폴더 내 모든 이미지 출력
def show_image_from_directory(dir):
# 이미지를 작게 조정하는 함수
def resize_image(image_path, size):
with Image.open(image_path) as image:
image.thumbnail(size)
# 배경을 흰색으로 설정
image_with_white_bg = ImageOps.pad(image.convert("RGBA"), size, color=(255, 255, 255))
return image_with_white_bg
# 폴더 내의 모든 이미지 파일 경로 가져오기
folder_path = dir
image_files = sorted([file for file in os.listdir(folder_path) if file.endswith((".png", ".jpg", ".jpeg"))])
# 작게 조정된 이미지를 저장할 임시 이미지
num_images = len(image_files)
num_images_per_row = 10
num_rows = (num_images + num_images_per_row - 1) // num_images_per_row
temp_image_width = num_images_per_row * 100
temp_image_height = num_rows * 100
temp_image = Image.new("RGB", (temp_image_width, temp_image_height), color=(255, 255, 255))
# 폴더 내의 각 이미지를 작게 조정하여 임시 이미지에 추가
x_offset = 0
y_offset = 0
for index, image_file in enumerate(image_files):
image_path = os.path.join(folder_path, image_file)
image = resize_image(image_path, (100, 100)) # 이미지를 100x100 크기로 작게 조정
temp_image.paste(image, (x_offset, y_offset))
x_offset += 100
if (index + 1) % num_images_per_row == 0:
x_offset = 0
y_offset += 100
# 작게 조정된 이미지 출력
temp_image.show()# CNN 모델을 이용하여 입력 이미지에 대한 예측 수행
# Keras 모델에 사용
def model_predict(model, img, class_labels):
img = img.resize((150, 150))
img = np.asarray(img)
img = img / 255.0
img = np.expand_dims(img, axis=0)
pred = model.predict(img, verbose=0)
return class_labels[np.argmax(pred)], np.max(pred)
# 슬라이딩 연산
# 전체 이미지에 대한 분할된 부분 공간 이미지 도출
# grid_size: N, kernel_size: K
def calc_sliding(img, grid_size, kernel_size, grid_width, grid_height):
n_iter = grid_size - kernel_size + 1
img_crops = []
for i in range(n_iter):
for j in range(n_iter):
img_crop = img.crop((grid_width * j, grid_height * i,
kernel_size * grid_width + j * grid_width, kernel_size * grid_height + i * grid_height))
img_crops.append(img_crop)
for i in range(n_iter):
img_crop = img.crop((grid_width * i, 0,
kernel_size * grid_width + i * grid_width, grid_size * grid_height))
img_crops.append(img_crop)
for i in range(n_iter):
img_crop = img.crop((0, i * grid_height,
grid_size * grid_width, kernel_size * grid_height + i * grid_height))
img_crops.append(img_crop)
return img_crops Self Extraction 알고리즘을 구현합니다.
def Self_Extraction(model, path, class_name, grid_size=9, kernel_size=5, remove_original=True, verbose=True):
'''
Parameter
---------------
model: 사전 훈련된 CNN 모델
path: 한 종류의 포켓몬 데이터가 저장된 경로
class_name: 하나의 포켓몬 이름(레이블)
grid_size: 전체 이미지를 구분하는 격자의 크기. grid_size=5이면 전체 이미지를 5x5로 분할. 홀수만 입력
kernel_size: 슬라이딩 연산을 적용할 kernel의 크기. kernel_size=3이면 3x3 크기의 커널을 슬라이딩 하여 계산. 홀수만 입력
remove_original: 분할 이미지가 더 높은 확률일 경우 원본 이미지 삭제 여부
verbose: 진행 상황 표시 여부
Output
------------
Self Extraction 적용을 마친 디렉터리
'''
# 훈련 데이터셋의 전체 포켓몬 레이블
class_labels = sorted(os.listdir('train'))
# 하나의 포켓몬에 대한 디렉터리 저장
# files에는 path 안의 모든 이미지 파일명이 저장됨
files = load_image_from_directory(path)
if ((kernel_size % 2 != 1) or (grid_size %2 != 1)):
print('kernel_size, grid_size는 홀수만 입력')
return
i=0
for file in files:
# 전체 이미지에 대한 예측 수행
img = Image.open(file).convert('RGB')
# 폴더 내 이미지가 아닌 경우 예외 처리
try:
entire_class, entire_score = model_predict(model, img, class_labels)
except TypeError:
continue
i += 1
if verbose:
print('%d번째 이미지' %i)
print('전체 이미지에 대한 예측: ', entire_class, entire_score)
'''
# 전체 이미지 자체가 0.95 이상의 score를 가진다면 슬라이딩 연산을 수행하지 않음
# 아래 예시에서 이 부분은 사용하지 않았습니다
if ((entire_class == class_name) and (entire_score >= 0.95)):
print('Pass')
print()
continue
'''
sub_classes = []
sub_scores = []
# 그리드 한 칸의 너비, 높이 계산
grid_w = img.size[0] // grid_size
grid_h = img.size[1] // grid_size
# 전체 이미지 분할 모음 img_crops 계산
img_crops = calc_sliding(img, grid_size, kernel_size, grid_w, grid_h)
# 원본 이미지를 정사각형 형태로 resize한 img_square에도 sliding 연산 수행
if img.size[0] > img.size[1]:
img_square = img.resize((img.size[0], img.size[0]))
img_crops_square = calc_sliding(img_square, grid_size, kernel_size, grid_w, grid_w)
else:
img_square = img.resize((img.size[1], img.size[1]))
img_crops_square = calc_sliding(img_square, grid_size, kernel_size, grid_h, grid_h)
img_crops.extend(img_crops_square)
# 전체 crop에 대한 예측 수행
for crop in img_crops:
sub_class, sub_score = model_predict(model, crop, class_labels)
sub_classes.append(sub_class)
sub_scores.append(sub_score)
# 올바른 레이블로 예측된 crop 중 가장 높은 점수와 그때의 인덱스 확인
sub_classes = pd.Series(sub_classes)
sub_scores = pd.Series(sub_scores)
# 모든 crop에서 올바른 레이블 예측을 못한 경우 예외처리
try:
max_sub_score = np.max(sub_scores[sub_classes == class_name])
max_sub_score_index = sub_scores[sub_scores==max_sub_score].index[0]
except IndexError:
if verbose:
print('올바른 부분 이미지 부재')
print()
continue
if verbose:
print('부분 이미지에 대한 최고 예측: ', class_name, max_sub_score)
# 전체 이미지에 대해 올바른 예측을 한 경우
if entire_class == class_name:
# crop의 점수가 전체 이미지의 점수보다 높다면
if max_sub_score > entire_score:
# 새로운 이미지 저장
new_img = img_crops[max_sub_score_index]
new_img.save(file[:-4] + '_new' + '.jpg')
if verbose:
print('새 이미지 생성')
print()
# 기존 이미지 제거
if remove_original:
os.remove(file)
else:
if verbose:
print()
# 전체 이미지에 대해 올바른 예측을 못한 경우
elif entire_class != class_name:
new_img = img_crops[max_sub_score_index]
new_img.save(file[:-4] + '_new' + '.jpg')
if verbose:
print('새 이미지 생성')
print()
# 기존 이미지 제거
if remove_original:
os.remove(file)
print('--- Self Extraction Done ---')알고리즘 적용 결과
구현한 함수를 바탕으로, 간단한 예시를 확인해 보겠습니다. 실험용 파이리 이미지 10장을 불러와 확인합니다.
# 실험용 파이리 사진 10장
shutil.copytree("/content/drive/MyDrive/charmander_test", "charmander_test")출력
charmander_test
show_image_from_directory('/content/charmander_test')출력

파이리 이미지 10장 속에는 파이리만 포함된 이미지도, 파이리 외의 다른 포켓몬이 포함된 이미지도 존재합니다.
Self_Extraction 함수를 charmander_test에 적용합니다.
Self_Extraction(model, '/content/charmander_test', 'Charmander')출력
1번째 이미지
전체 이미지에 대한 예측: Charmander 0.99999523
부분 이미지에 대한 최고 예측: Charmander 0.9999801
2번째 이미지
전체 이미지에 대한 예측: Charmander 0.99999774
부분 이미지에 대한 최고 예측: Charmander 0.9999988
새 이미지 생성
3번째 이미지
전체 이미지에 대한 예측: Charmander 0.9999237
부분 이미지에 대한 최고 예측: Charmander 0.99631125
4번째 이미지
전체 이미지에 대한 예측: Charmander 0.999385
부분 이미지에 대한 최고 예측: Charmander 0.9999527
새 이미지 생성
5번째 이미지
전체 이미지에 대한 예측: Charmander 0.62162733
부분 이미지에 대한 최고 예측: Charmander 0.9946866
새 이미지 생성
6번째 이미지
전체 이미지에 대한 예측: Squirtle 0.8798504
부분 이미지에 대한 최고 예측: Charmander 0.9970149
새 이미지 생성
7번째 이미지
전체 이미지에 대한 예측: Bulbasaur 0.5880406
부분 이미지에 대한 최고 예측: Charmander 0.52601576
새 이미지 생성
8번째 이미지
전체 이미지에 대한 예측: Charmander 0.9999765
부분 이미지에 대한 최고 예측: Charmander 0.9999496
9번째 이미지
전체 이미지에 대한 예측: Charmander 0.9993905
부분 이미지에 대한 최고 예측: Charmander 0.9991079
10번째 이미지
전체 이미지에 대한 예측: Squirtle 0.59565103
부분 이미지에 대한 최고 예측: Charmander 0.9839934
새 이미지 생성
--- Self Extraction Done ---알고리즘 실행 결과는 다음과 같습니다.
show_image_from_directory('/content/charmander_test')출력

알고리즘 1회 실행 결과, 파이리 외의 다른 포켓몬이 포함된 이미지에서 파이리 부분이 어느정도 추출되었음을 확인할 수 있습니다. 알고리즘을 추가로 수행하며 이미지들이 어떻게 변하는지 확인합니다.
Self_Extraction(model, '/content/charmander_test', 'Charmander', verbose=False)
show_image_from_directory('/content/charmander_test')출력
--- Self Extraction Done ---

Self_Extraction(model, '/content/charmander_test', 'Charmander', verbose=False)
show_image_from_directory('/content/charmander_test')출력
--- Self Extraction Done ---

총 세 번의 실행 결과, 7번째 이미지를 제외하고 이미지가 모두 파이리로 수렴한 것을 확인할 수 있습니다.
마무리
지금까지 단일 이미지 내 여러 객체가 존재하는 문제를 해결하기 위한 Self Extraction 알고리즘에 대해 알아보았습니다.
코드 구현에 부족한 부분이 있어 알고리즘 실행 속도 등 개선할 부분이 보이지만, 10장의 파이리 이미지 예시를 보았을 때 파이리 객체에 이미지가 적절히 수렴됨을 확인할 수 있었습니다. 하이퍼파라미터 grid_size, kernel_size를 적절히 조절한다면 더 좋은 수렴 결과를 얻을 수도 있습니다.
알고리즘 실행 결과 수렴된 이미지의 범위를 객체에 대한 바운딩 박스로 생각할 수도 있습니다. 사람의 손으로 직접 라벨링 한 데이터보다는 정확도가 떨어지겠지만, 사람의 수작업이 아닌 자동화된 방법으로 객체의 영역을 탐지할 수 있습니다.
단일 이미지에 여러 객체가 존재하는 것은 비단 포켓몬 데이터셋의 문제만은 아닙니다. 현실 이미지 속에는 다양한 객체가 존재하며, 특정 객체를 찾아 분리하는 과정은 컴퓨터 비전을 위한 데이터셋을 준비하는 데 상당한 어려움을 야기합니다.
이러한 문제를 해결함으로 딥러닝 모델을 위한 품질이 더 좋은 데이터셋 생성에 기여하고, 향상된 데이터셋을 바탕으로 딥러닝 모델의 성능 향상에 기여하길 바랍니다.
