
정수 배열 [1, 2, 3, 1, 3, 1]에서 중복된 요소를 찾아보는 문제가 있다고 하자. 지금은 코딩 인터뷰를 보는 것이 아니고 그냥 두번이상 나타난 유저를 찾는 것처럼 단순한 문제를 푼다고 생각을 해보자.
실제 이와 같은 문제를 정수 배열이 아닌 객체 배열에서 풀고자 한다면, tag로 중복된 객체를 찾을 수 있을 것이다.
val dupes: Map<Int, List<Widget>> =
widgets.groupBy(Widget::tag)
.filterValues { it.size > 1 }이런 방식을 정수 배열에 적용을 해본다면, identity function을 활용하여 각 정수에 해당하는 키를 생성할 수 있을것이다.
val dupes: Set<Int> =
ints.groupBy { it }
.filterValues { it.size > 1 }
.keys이와 같이 구현한다면, 답은 [1, 3]이 나올 것이다.
그래서...이정도면 충분하다고 생각한가? 그렇긴 하다, 하지만 이건 모기잡는데 집에 수류탄 날리는 것과 같은 느낌이 든다...그렇지 않나?
Attempt 1
우선 첫번째 시도는 연산 중간 과정에서 의미없는 map 자료구조를 제거하고 현재 리스트에서 해당 리스트로 만들어진 set을 빼는 것이다. 이렇게 구현을 한다면 리스트에서 중복된 요소를 제거한 unique한 원소들로 구성한 자료구조를 빼는 것이기에 중복된 요소들의 집합만 결과로 남을 것이다.
val dupes: List<Int> =
ints.toList() - ints.toSet()하지만 이를 실제로 실행해본다면..?
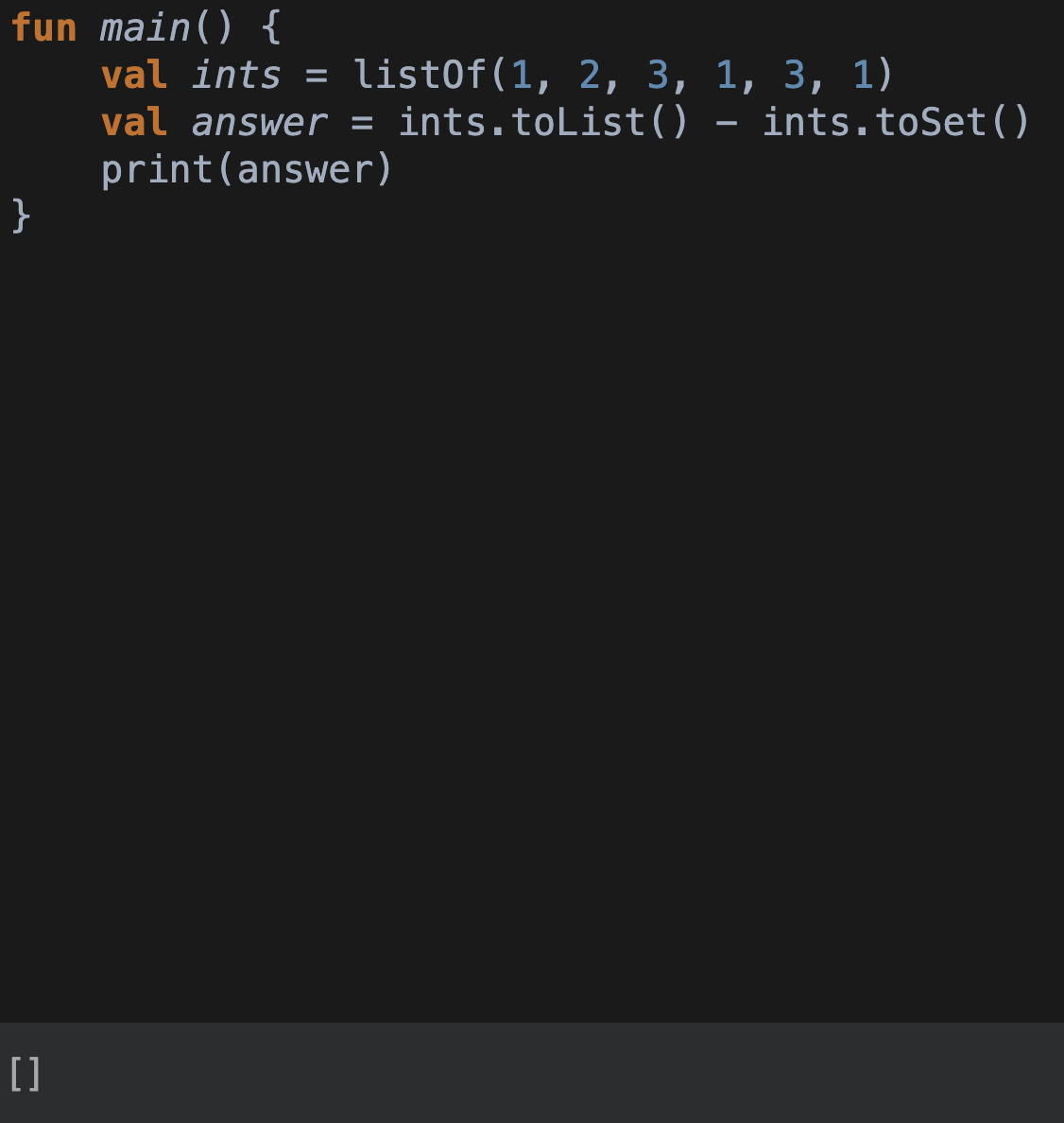
어머나
항상 빈 리스트가 출력될 것이다.
오...왜?
Kotlin에서 minus 연산자는 "후행 자료구조에 포함된 요소를 제외한 원래 자료구조가 가진 모든 요소가 포함된 리스트를 반환한다"로 정의한다. 따라서 집합에 있는 각 요소는 이미 원래 자료구조에 포함이 되어있기에 빈 리스트가 출력되는 것이다.
minus라는 단순한 함수명 뒤에 동작하는 이런 자료구조의 기작은 꽤나 놀라울 따름이다.
Attempt 2
위와 같이 실패를 하고 MutableList.removeAll함수를 사용을 해보기로 하였다. MutableList.remove함수는 조건에 만족하는 자료구조 내 첫 요소를 제거한다, 즉 removeAll 함수를 사용한다면 set 내의 요소들이 순회를 하면서 list내의 값이 같은 요소 중 첫번째 요소를 제거할 것이다. 즉 중복된 요소들만 결과값으로 남게 될것이다.
val dupes: List<Int> =
ints.toMutableList()
.apply { removeAll(ints.toSet()) }하지만 이 역시,
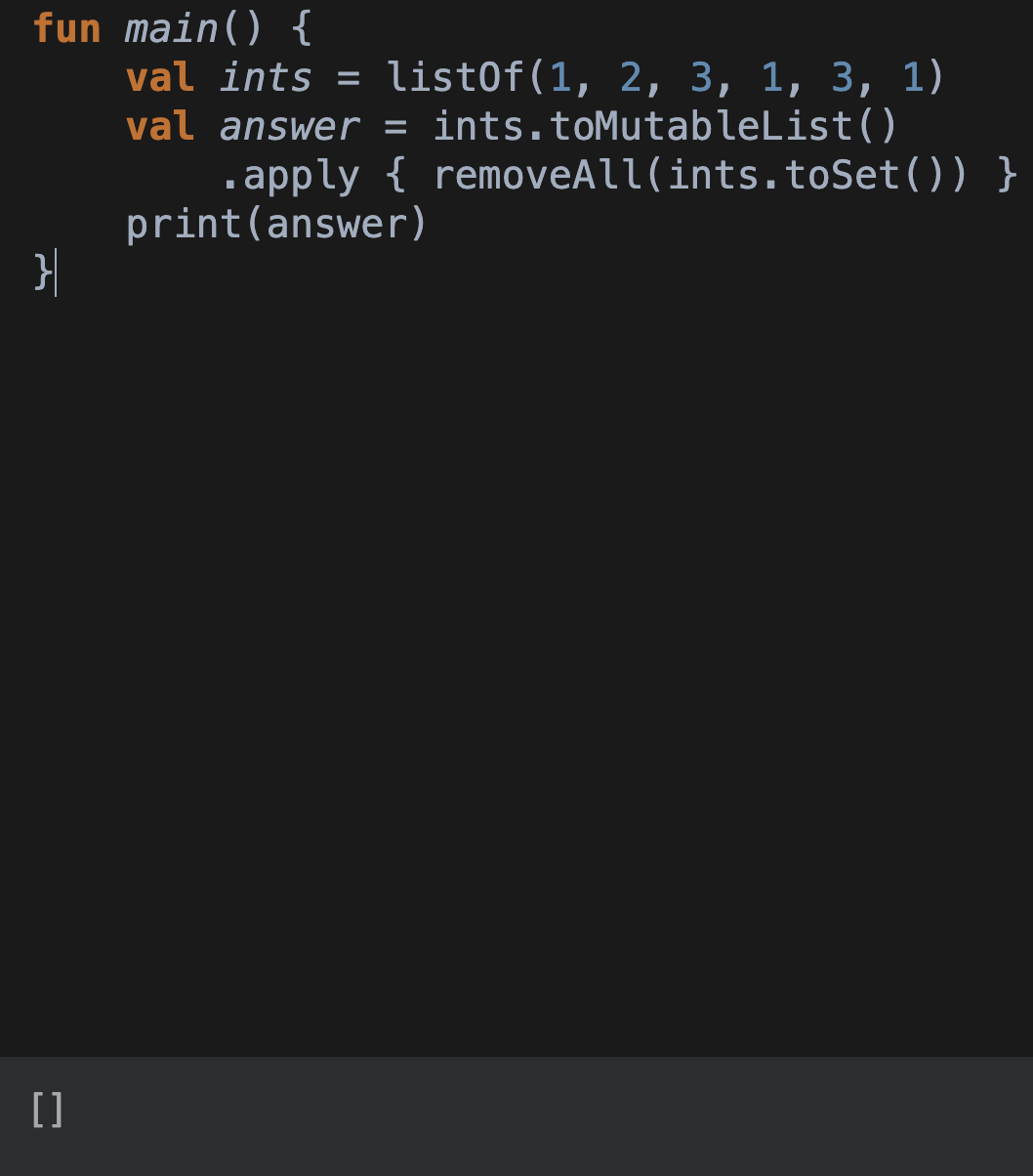
이런...또 예상된 결괏값이 아니다. MutableList.remove는 조건에 맞는 요소들 중 첫 번째 항목만 제거한다. 하지만, MutableList.removeAll은 후행 자료구조에 있는 각 요소의 원래 자료구조 내 모든 항목을 제거한다.
뭐 사실 이건 코틀린만의 설계 이상이라기 보단, Java에서부터 비롯된 것이기에 코틀린이 이상하다고 생각할 필요까진 없을 것 같다.
Attempt 3
이제 MutableList.remove를 사용해보자
val dupes: List<Int> =
ints.toMutableList()
.apply { ints.toSet().forEach(::remove) }이제 진짜 [1, 3, 1]이 출력된다! 이제 중복된 요소들의 set만 원한다면 마지막에 toSet()처리만 해주면 된다.
val dupes: Set<Int> =
ints.toMutableList()
.apply { ints.toSet().forEach(::remove) }
.toSet()뭐 코드상으로는 그렇게 훌륭해보이지는 않다. 실제로도 그렇게 효율적이지도 못하긴 한다(그렇게 신경쓰일정도도 아니긴 하지만). 지금 이렇게 풀어본 이유는 똑똑하지만 잘못된 접근 방식(toList() - toSet())으로부터 지금 이 풀이로 접근하게 될때까지 리팩터링해야 했기 때문이다.
Attempt 4
이번에는 아예 접근자체를 재설정을 해볼것이다. 기초가 되는 아이디어는
이전에 본 값이 있는지에 따라서 원소들을
partition할 수 있다
는 것이다.
Set은 값을 추적할 수 있고, MutableSet.add 함수는 Set이 add 연산에 의해 변했는지를 리턴 값(Boolean)으로 알려준다.
val dupes: Set<Int> =
HashSet<Int>()
.run { ints.partition(::add) }
.second
.toSet()이는 [1, 3]을 반환한다. 코드는 굉장히 지저분해보인다. 왜냐면 코드를 쭉 읽다보면 도대체 어느 부분에서 어떻게 값을 분별하겠다는 것인지 한번에 눈에 안들어오기 때문이다.
partition을 사용하는 것은 내가 처음으로 생각했을 때 떠올린 직관이고, 이것보다 훨씬 더 훌륭한 해법이 존재한다. 바로 여러분들이 이미 익히 들어오고 사용해봤을만한 filter 함수이다.
Attempt 5
filter를 사용해서 위의 코드를 리팩터링 해보자.
val dupes: Set<Int> =
ints.filterNot(HashSet<Int>()::add)
.toSet()이 역시 [1, 3]을 반환하지만 이전 코드와 비교했을때 가독성이 굉장히 향상되었다는 것을 볼 수 있다.
아래의 코드는 위와 동일하다.
val seen = HashSet<Int>()
val dupes: Set<Int> =
ints.filterNot(seen::add)
.toSet()아래의 코드에 비해 위의 코드(HashSet의 인라인화)의 장점은 HashSet 변수의 이름을 신경써도 되지 않아도 된다는 것이다.
Attempt 5.1
마지막으로 코틀린의 확장함수 중에서 To로 끝나는 함수는 최종적으로 어떤 자료구조로 반환해줄 것인지까지 지정해줄 수 있는 것이다. 여기서 우리는 filterNotTo라는 함수도 활용해볼 수 있을 것이다.
val dupes: Set<Int> =
ints.filterNotTo(HashSet(), HashSet<Int>()::add)Benchmarks
아래는 위의 연산을 실제로 실행할 때 성능 측정 결과이다. 그렇게 중요하다고 생각하진 않지만 한번 보도록 하자.
Benchmark Score Error Units
---------------------------------------------- --------- ------ -----
IntDupes.map 94.015 ± 0.469 ns/op
IntDupes.map:·gc.alloc.rate.norm 776.000 ± 0.001 B/op
IntDupes.mutableListRemove 155.744 ± 17.829 ns/op
IntDupes.mutableListRemove:·gc.alloc.rate.norm 560.000 ± 0.001 B/op
IntDupes.partition 135.693 ± 18.976 ns/op
IntDupes.partition:·gc.alloc.rate.norm 544.000 ± 0.001 B/op
IntDupes.filterNot 97.748 ± 1.055 ns/op
IntDupes.filterNot:·gc.alloc.rate.norm 504.000 ± 0.001 B/op
IntDupes.filterNotTo 39.904 ± 0.331 ns/op
IntDupes.filterNotTo:·gc.alloc.rate.norm 432.000 ± 0.001 B/op이리로 보나, 저리로 보나 filterNotTO가 훨씬 빠르고 더 적은 메모리 공간을 할당받은 것을 알 수 있다.
원문
