NVIDIA와 GPU
NVIDIA는 GPU만 팔지 않는다 — CPU 백엔드 개발자가 본 AI 인프라
본 글은 CPU 위주의 백엔드 서버를 만들어 본 경험은 있지만, GPU 프로그래밍이나 AI 인프라는 처음 접하는 독자를 대상으로 합니다. 복잡한 CUDA 코드는 다루지 않으며, NVIDIA가 파는 것이 하드웨어 관점에서 정확히 무엇인지 — 단일 칩에서 출발해 랙 단위 슈퍼컴퓨터, 그리고 실적표 해석까지 — 한 호흡에 정리합니다.
NVIDIA, 그리고 GPU
NVIDIA를 한 문장으로 정의하면 어떻게 될까요? "GPU 만드는 회사"라고 답하기 쉽습니다. 게임할 때 쓰는 그래픽카드, 그걸 데이터센터용으로 크게 만드는 회사 정도로요.
그런데 가장 최근 분기 실적표를 보면 어색한 부분이 있습니다.
Data Center Compute : $60.4B YoY +77%
Data Center Networking : $14.8B YoY +199%
Edge Computing : $6.4B YoY +29%GPU 회사가 네트워킹으로만 한 분기 14.8B 달러를 벌고, 그게 1년 만에 세 배가 되었습니다. 그래픽카드 회사라는 정의로는 설명이 안 되는 숫자입니다.
이 글은 이 위화감에서 출발합니다. 백엔드 개발자가 익숙한 CPU 멘탈 모델에서 출발해서, "GPU 한 장 → CPU↔GPU 통신 → 랙 안 묶기 → 랙 사이 묶기 → 실적표 재해석" 순서로 따라갑니다. 다 읽고 나면 NVIDIA가 왜 칩 회사가 아니라 랙 운영체제 + 인프라 회사가 되었는지가 보일 겁니다.
1장. GPU는 그래픽카드가 아니다
GPU의 실체: 거대한 병렬 가속기
"GPU"라는 이름은 Graphics Processing Unit의 약자입니다. 90년대~2000년대 초까지는 진짜로 그랬습니다. 모니터에 픽셀을 그리려고 만든 칩이었죠. 하지만 지금 NVIDIA가 데이터센터에 파는 칩은 그래픽과는 사실상 무관합니다.
그렇다면 정확히 무엇일까요?
GPU는 수만 개의 단순한 연산기와, 그것을 먹일 만큼 미친 대역폭의 메모리를 한 패키지에 묶은 데이터 병렬 가속기다.
세 부분으로 나눠 보겠습니다. 수만 개의 단순한 연산기(SIMT), 행렬 곱 전용 회로(Tensor Core), 그리고 그걸 굶기지 않을 메모리(HBM)입니다.
첫 번째 메커니즘: SIMT — 한 명령으로 32명을 동시에 굴린다
서버 개발자에게 "병렬"이라고 하면 보통 떠올리는 그림이 있습니다.
- 멀티코어 CPU 16개에 스레드 16개를 띄운다
- 각 스레드는 서로 다른 함수를 실행할 수 있다
- OS 스케줄러가 컨텍스트 스위칭으로 돌려가며 굴린다
이걸 MIMD(Multiple Instruction, Multiple Data)라고 부릅니다. 각 코어가 독립적으로 다른 일을 합니다. CPU의 병렬은 이 모델입니다.
GPU는 다릅니다. 같은 명령어를 수십~수만 개의 데이터에 한꺼번에 적용합니다. 이 모델을 NVIDIA는 SIMT (Single Instruction, Multiple Threads) 라고 부릅니다.
- 32개 스레드가 묶여 한 단위가 됩니다. 이 묶음을 Warp라고 부릅니다.
- 한 Warp 안의 32개 스레드는 항상 같은 명령어를 같은 사이클에 실행합니다.
- 단지 각 스레드가 보는 데이터(레지스터 값)는 다릅니다.
비유하자면 이렇습니다. CPU는 회사원 16명이 각자 다른 보고서를 쓰는 사무실입니다. GPU는 군대 제식훈련에 가깝습니다. "우향우!"라는 한 마디 명령으로 분대원 32명이 동시에 같은 동작을 하는데, 발을 디디는 위치(데이터)는 각자 다릅니다.
왜 이렇게 만들었을까요? 하나의 명령어 디코더로 32개 연산을 굴릴 수 있으면, 같은 트랜지스터 예산으로 훨씬 많은 연산을 욱여넣을 수 있기 때문입니다. CPU 코어 하나에 들어가는 분기 예측기·Out-of-Order 엔진·캐시 같은 "똑똑한 회로"의 비중을 다 빼버리고, 그 자리에 연산기를 더 박는 전략이죠.
대신 대가가 있습니다.
if분기에서 32개 스레드가 갈라지면(divergence), 양쪽 분기를 직렬로 다 돌고 각자 마스킹합니다. GPU는if를 싫어합니다.- 코어 하나하나가 멍청해서, 한 스레드 단위로 보면 CPU보다 훨씬 느립니다.
- 어차피 데이터가 비슷한 일을 시킬 게 아니라면 GPU에 들고 갈 이유가 없습니다.
행렬 곱, 컨볼루션, 어텐션 — 딥러닝 연산의 본체는 거의 다 "같은 명령을 다른 데이터에 적용"입니다. SIMT가 정확히 이걸 위해 만들어진 셈이고, 그래서 GPU와 딥러닝이 우연히 잘 맞아떨어진 게 아닙니다.
더 깊이 공부하고 싶다면?
Warp는 NVIDIA 용어이고, AMD에서는 Wavefront(64스레드)라고 부릅니다. SIMD와 SIMT의 차이도 알아두면 좋습니다. SIMD는 한 코어 내부 한 명령어가 벡터 레지스터 여러 lane에 적용되는 모델(AVX-512 등), SIMT는 그것을 스레드 추상화로 노출한 모델입니다.
- 검색 키워드:
CUDA Warp scheduling,Warp divergence,SIMD vs SIMT,NVIDIA SM Streaming Multiprocessor
두 번째 메커니즘: Tensor Core — 행렬 곱 전용 ASIC
SIMT만으로도 GPU는 충분히 빠릅니다. 그런데 2017년부터 NVIDIA는 GPU 안에 한 가지를 더 박아 넣기 시작합니다. Tensor Core라는 회로입니다.
이름이 거창하지만 하는 일은 단순합니다. 작은 행렬 두 개를 받아서 한 클럭 사이클 안에 곱한 다음 누적까지 해 줍니다. 보통 4×4 또는 8×8 단위입니다. CUDA Core(평범한 SIMT 연산기)로 같은 일을 시키려면 곱셈과 덧셈을 수십 번 돌려야 하는데, Tensor Core는 그 시퀀스 전체를 회로 한 번으로 끝냅니다.
이게 왜 중요할까요? 트랜스포머 모델의 본체 연산은 사실상 거대한 행렬 곱입니다. Attention의 Q×Kᵀ도, FFN의 W×x도, 임베딩 lookup도 모두 행렬 곱으로 환원됩니다. 모델 학습·추론 시간의 90% 이상이 행렬 곱에 들어갑니다.
그래서 NVIDIA가 매 세대마다 자랑하는 "OOO exaFLOPS" 같은 숫자는 거의 대부분 Tensor Core가 행렬 곱에서 내는 숫자입니다. CUDA Core가 내는 일반 부동소수점 성능과는 따로 노는 별개 지표입니다.
세대별로 Tensor Core가 다루는 정밀도가 다릅니다. 이 부분이 NVIDIA 칩 트렌드 중 가장 중요합니다.
| 세대 | 대표 칩 | 새로 추가된 정밀도 | 의미 |
|---|---|---|---|
| Volta | V100 (2017) | FP16 | 학습용 16비트 |
| Ampere | A100 (2020) | TF32, BF16 | 학습 안정성 + 속도 |
| Hopper | H100 (2022) | FP8 | 학습/추론 모두 8비트 |
| Blackwell | B200 (2024) | FP4 | 추론 4비트 |
| Blackwell Ultra | B300 (2025) | FP4 강화 + 더 큰 HBM | 추론 처리량 ↑ |
| Rubin | R100 (2026 H2) | FP4 + 차세대 메모리 | dual-die 패키지 |
여기서 트렌드는 명확합니다. 숫자를 점점 더 짧게 표현해서, 같은 시간에 더 많은 행렬 곱을 한다. FP32 → FP16 → FP8 → FP4로 내려갈 때마다 연산기당 트랜지스터가 줄고, 같은 칩에 더 많은 연산기를 박을 수 있고, 데이터를 옮기는 메모리 대역폭도 덜 듭니다. 모델 품질만 유지된다면 모두가 이득입니다. 딥러닝 연구자들이 매 세대마다 "FP4로 학습되나?"를 검증하는 이유가 이것입니다.
더 깊이 공부하고 싶다면?
Tensor Core는 단순히 "행렬 곱이 빠른 회로"가 아니라, 데이터를 어떻게 메모리에서 가져와서 연산기에 먹이고 결과를 다시 메모리에 쓰는가까지 포함하는 설계 단위입니다. WMMA API, MMA instruction, cuBLAS·cuDNN이 Tensor Core를 어떻게 활용하는지 보면 GPU 컴파일러의 세계가 열립니다.
- 검색 키워드:
Tensor Core WMMA,NVIDIA Transformer Engine,FP8 training,Microscaling FP4 MXFP4
세 번째 메커니즘: HBM — 미친 대역폭의 메모리
여기까지 보면 GPU는 그저 "연산기가 많은 칩"처럼 보일 수 있습니다. 그런데 진짜 비싼 부분, 그리고 NVIDIA가 SK하이닉스·삼성·마이크론에 매년 수십조 원을 갖다 바치는 부분은 따로 있습니다. 바로 메모리입니다.
CPU 백엔드 개발자가 알고 있는 DRAM(DDR5)은 한 채널 대역폭이 보통 50~70 GB/s 수준입니다. 듀얼 채널 / 쿼드 채널을 묶어도 200~400 GB/s 정도가 일반 서버의 한계입니다.
GPU 한 장이 쓰는 메모리는 단위가 다릅니다.
| 칩 | 메모리 종류 | 용량 | 대역폭 |
|---|---|---|---|
| H100 | HBM3 | 80 GB | 3.35 TB/s |
| H200 | HBM3e | 141 GB | 4.8 TB/s |
| B200 (Blackwell) | HBM3e | 192 GB | 8 TB/s |
| B300 (Blackwell Ultra) | HBM3e | 288 GB | 8 TB/s |
| R100 (Rubin) | HBM4 | ~288 GB | 13 TB/s 이상 |
서버 DRAM 대비 20~40배 빠릅니다. 왜 이렇게 만들었을까요?
답은 첫 번째 메커니즘으로 돌아갑니다. 수만 개의 연산기를 굶기지 않으려면 메모리가 그만큼 빨라야 합니다. 연산기는 1초에 페타플롭스 단위로 계산을 토해낼 수 있는데, 메모리가 데이터를 그 속도로 못 가져오면 연산기는 놀게 됩니다. 이걸 메모리 바운드(memory-bound) 라고 부르고, 트랜스포머 추론 같은 워크로드는 거의 항상 메모리 바운드입니다.
HBM(High Bandwidth Memory)이라는 이름은 그래서 붙었습니다. 평범한 DRAM 칩을 옆이 아니라 위로 8단~12단 쌓아서, GPU 다이 바로 옆에 인터포저(interposer)라는 실리콘 기판 위에 같이 박습니다. CPU↔DRAM처럼 메인보드 배선을 타고 신호를 보내는 게 아니라, 실리콘 위에서 수천 개 와이어로 직결합니다. 그래서 대역폭이 미친 수준으로 나옵니다.
대신 단점이 있습니다.
- 비쌉니다. Blackwell B200 한 장 가격의 상당 부분이 HBM 가격입니다. SK하이닉스가 갑자기 "AI 수혜주"가 된 이유입니다.
- 공급이 제한됩니다. HBM 적층 공정 자체가 어려워서, 메모리 회사가 일정 이상 못 찍어냅니다. NVIDIA 출하량의 진짜 병목은 GPU 다이가 아니라 HBM이라는 분석이 많이 나옵니다.
- 수리가 안 됩니다. GPU 다이와 HBM이 같은 패키지에 박혀 있어서, 하나가 죽으면 통째로 폐기됩니다.
더 깊이 공부하고 싶다면?
HBM은 표준이 JEDEC에서 정해집니다. HBM3 → HBM3e → HBM4로 가면서 채널 수, 적층 단수, 클럭이 계속 올라갑니다. CoWoS(Chip on Wafer on Substrate)라는 TSMC의 첨단 패키징 기술이 HBM과 GPU를 같은 인터포저에 붙이는 핵심 공정이고, 이 패키징 캐파가 NVIDIA 출하의 또 다른 병목입니다.
- 검색 키워드:
HBM3e stack,CoWoS packaging,roofline model memory-bound,Arithmetic Intensity
Deep Dive: tensor.cuda() 한 줄의 내부
세 메커니즘을 이제 한 줄의 코드로 묶어 봅시다.
import torch
x = torch.randn(1024, 1024) # CPU 위 텐서 (DDR5에 있음)
x = x.cuda() # ← 이 한 줄에서 무슨 일이 벌어지나?
y = x @ x # 행렬 곱x.cuda()는 단순히 "GPU 쓰겠습니다" 정도로 보이지만, 실제로는 여러 컴포넌트가 분업해서 다음 일을 합니다.
- PyTorch: 메모리 할당 요청 — PyTorch가 CUDA 런타임에게 "HBM 위에 1024×1024 float32 텐서 공간을 잡아 달라"고 요청합니다. CUDA 런타임은 자체 메모리 풀(caching allocator)에서 적당한 블록을 떼어줍니다. 매번
cudaMalloc을 부르지 않고 풀링하는 이유는 시스템콜이 워낙 비싸기 때문입니다. - CUDA Driver: 호스트 → 디바이스 복사 — DDR5에 있던 4MB짜리 데이터를 PCIe Gen5(보통 64 GB/s)를 통해 HBM으로 옮깁니다. 이게 그 유명한
cudaMemcpyHostToDevice입니다. 이 복사 자체가 비용이고, 그래서 한 번 GPU에 올린 데이터는 가능하면 거기서 다 처리하고 결과만 다시 받아오는 게 정석입니다. - GPU 하드웨어: 데이터 도착, 끝 — 복사가 끝나면 텐서는 HBM 위에 자리잡고, GPU 코어 입장에서는 "거기에 데이터가 있다"는 포인터만 알면 됩니다. 이 시점에서 CPU와 GPU의 메모리는 별개의 주소 공간입니다. 같은 변수
x라도 CPUx.data_ptr()과 GPUx.cuda().data_ptr()은 완전히 다른 주소를 가리킵니다. - 행렬 곱: SIMT + Tensor Core 동원 —
y = x @ x를 호출하면 PyTorch는 cuBLAS의cublasGemmEx같은 라이브러리 호출로 변환합니다. cuBLAS는 입력 크기에 맞춰 최적화된 CUDA 커널을 고르고, 그 커널은 행렬을 작은 타일로 쪼개 SM(Streaming Multiprocessor)에 할당하고, 각 SM은 Warp 단위로 Tensor Core를 호출해 16×16씩 곱한 뒤 결과를 HBM에 다시 씁니다.
CPU는 이 4번 과정에 참여하지 않습니다. 명령어를 큐에 던지고 끝납니다. GPU가 알아서 다 합니다. 이 비동기성 자체가 2장의 주제입니다.
이 한 줄을 따라가 보면, GPU가 단순히 "빠른 계산기"가 아니라 별도의 메모리 공간 + 별도의 명령 시스템 + 별도의 실행 모델을 가진 컴퓨터라는 게 보입니다. 사실상 같은 케이스 안에 들어 있는 두 번째 컴퓨터에 가깝습니다.
2장. CPU는 GPU에게 어떻게 명령하는가
여기까지 GPU 한 장이 무엇인지 봤습니다. 그런데 그 GPU가 "별개의 컴퓨터"라면, CPU와 GPU는 어떤 인터페이스로 대화할까요? 함수 호출처럼 동기적으로 움직일까요, 아니면 백엔드끼리 메시지 큐로 통신하듯 비동기일까요?
잘못된 멘탈 모델 부수기
GPU 처음 보는 개발자가 가장 흔히 갖는 잘못된 그림은 이렇습니다.
"CPU에서
tensor @ tensor호출 → 시스템콜 → GPU에게 일을 시킴 → 결과 받음 → 다음 줄로 진행"
이 그림은 거의 모든 단계가 틀렸습니다. 실제로는 시스템콜을 매번 거치지 않고(너무 비쌈), CPU는 결과를 기다리지 않고(블로킹하면 GPU 사용률이 폭락), 그 줄이 끝났다고 GPU 일이 끝난 것도 아닙니다(큐에 던졌을 뿐).
정확한 그림은 메시지 큐 기반 비동기 워커 시스템에 훨씬 가깝습니다.
첫 번째 메커니즘: 커맨드 큐와 비동기 링버퍼
CPU와 GPU 사이의 통신은 다음과 같이 일어납니다.
- CPU(앱/PyTorch)는 GPU가 실행할 명령(CUDA Kernel)과 그 인자(VRAM 주소들)를 패키징합니다.
- 이 패키지를 메인 메모리에 자리잡은 커맨드 큐(Command Queue, 또는 CUDA Stream)에 비동기로 던집니다. CPU는 거기서 더 기다리지 않고 다음 줄로 갑니다.
- GPU 내부의 하드웨어 스케줄러가 큐에서 명령을 꺼내(Fetch) 실행합니다. CPU는 이 과정에 끼지 않습니다.
- CPU가 진짜로 GPU 결과를 필요로 하는 시점에만 동기화(
cudaStreamSynchronize,tensor.cpu()등)를 합니다. 이때 비로소 둘이 만납니다.
이걸 백엔드 개발자 멘탈 모델로 옮기면 다음과 같습니다.
- 커맨드 큐 = Redis Queue / Kafka topic
- CPU = Producer — 작업 메시지를 쏟아붓고 끝
- GPU = Consumer worker pool — 큐에서 자기 속도로 꺼내 처리
- Stream = 메시지 큐의 파티션 — 같은 stream 안 명령은 순서 보장, 다른 stream끼리는 병렬 가능
- cudaStreamSynchronize = future.get() / blocking await — 결과가 필요할 때만 막힘
이 구조의 핵심은 CPU의 호출과 GPU의 실행이 시간 축에서 떨어져 있다는 것입니다. PyTorch 코드 100줄을 1초 만에 다 던졌어도, GPU는 그것을 30초에 걸쳐 자기 속도로 실행할 수 있고, CPU는 그동안 다른 일(다음 batch 전처리, 데이터 로드 등)을 합니다. 이게 잘 굴러가야 GPU 사용률 90%대가 나옵니다. 안 굴러가면 GPU가 데이터 기다리며 놀고, 사용률 30%에서 박힙니다.
더 깊이 공부하고 싶다면?
CUDA Stream은 단일 GPU 안에서 작업을 병렬화하는 핵심 추상입니다. 한 stream은 FIFO지만, 여러 stream을 만들면 H↔D copy와 kernel 실행이 동시에 일어날 수 있습니다(overlap).nsys같은 NVIDIA 프로파일러로 stream timeline을 보면 이 그림이 한눈에 들어옵니다.
- 검색 키워드:
CUDA Stream overlap,cudaEventRecord,cudaStreamSynchronize,Nsight Systems timeline
Deep Dive: 한 줄 더 — Ring Buffer와 Doorbell
위에서 "커맨드 큐에 명령을 던진다"라고만 했는데, 그 큐가 어디 사는 것이고 GPU가 그걸 어떻게 알아채는지 한 계층 더 들어가 보면 멘탈 모델이 한 번 더 깔끔해집니다.
처음 GPU를 만지는 개발자가 가장 자주 헷갈리는 지점은 "커널 코드 / 데이터 / 명령" 세 가지를 한 덩어리로 보는 것입니다. 사실 셋은 서로 다른 곳에 살고, 다른 경로로 GPU에 닿습니다.
| 항목 | 정체 | 사는 곳 | 누가 옮기나 |
|---|---|---|---|
| ① 커널 코드 | "행렬 곱하라"는 GPU 실행 바이너리 | HBM (시작 시 한 번만 업로드) | import torch 시점에 cuBLAS·cuDNN이 |
| ② 데이터 | 텐서, 가중치, 입력값 | HBM (.cuda()로 올림) | cudaMemcpyAsync (PCIe DMA) |
| ③ 명령(descriptor) | "커널 #42를 주소 0x...로 실행해" 같은 작은 패킷 | CPU DRAM의 ring buffer | CPU가 직접 쓰기 + doorbell |
y = x @ x 한 줄이 실행될 때, ①과 ②는 이미 HBM에 올라가 있고, 이 호출은 ③만 큐에 새로 적습니다. 그래서 매 호출의 핫 루프는 거의 비용이 없어요.
Ring Buffer의 물리 위치 — HBM이 아니라 CPU DRAM
커맨드 큐(ring buffer)는 보통 CPU DRAM의 한 페이지에 자리잡습니다. 단, OS가 그 페이지를 GPU도 PCIe로 읽을 수 있도록 매핑해 둡니다. CPU는 자기 메모리에 쓰는 것처럼 적고, GPU는 자기 메모리처럼 읽어가는 공유 메모리 영역입니다. HBM에 따로 복사하는 단계는 없습니다.
Doorbell — GPU를 깨우는 종
CPU가 ring buffer에 명령을 적은 뒤, 마지막에 GPU의 특수 레지스터(doorbell)에 한 바이트를 씁니다. 이 쓰기는 MMIO(Memory-Mapped I/O) — 일반 메모리 쓰기처럼 보이지만 사실은 PCIe를 타고 GPU 레지스터로 라우팅됩니다. syscall이 아니라 그냥 사용자 공간 메모리 쓰기라서 1마이크로초도 안 걸려요.
GPU 내부의 작은 컨트롤러(Command Processor)가 doorbell을 감지하고 ring buffer를 폴링해서 명령을 꺼냅니다. 한 가지 더 중요한 사실은 GPU에는 OS가 없다는 것. 그래서 "GPU가 syscall 하나?"라는 질문 자체가 성립하지 않습니다. GPU는 그냥 큐를 읽고 실행하는 거대한 기계입니다.
요약하면 핫 루프의 비용은 이 정도입니다.
- ring buffer에 100바이트짜리 descriptor 쓰기 (CPU DRAM)
- doorbell 레지스터에 1바이트 쓰기 (MMIO)
- 끝. CPU는 다음 줄로
더 깊이 공부하고 싶다면?
이 doorbell + ring buffer 패턴은 NVIDIA 고유가 아니라 모든 고성능 PCIe 디바이스의 표준입니다. NVMe SSD가 디스크 I/O 명령을 받을 때, 고성능 NIC이 패킷을 받을 때 같은 방식을 씁니다. 백엔드 개발자가 NVMe 멘탈 모델을 갖고 있으면 GPU 통신도 같은 그림으로 이해할 수 있어요.
- 검색 키워드:
MMIO doorbell,NVMe submission queue,CUDA user-mode driver (UMD),GPU Command Processor
두 번째 메커니즘: PCIe를 통한 데이터 이동
CPU↔GPU 사이의 물리 통로는 전통적으로 PCIe(Peripheral Component Interconnect Express) 입니다. PC 메인보드의 그래픽카드 슬롯이 그것이고, 데이터센터 서버에서도 마찬가지입니다.
세대별 대역폭은 다음과 같습니다.
| 세대 | x16 슬롯 한 방향 | 양방향 |
|---|---|---|
| PCIe Gen3 | 16 GB/s | 32 GB/s |
| PCIe Gen4 | 32 GB/s | 64 GB/s |
| PCIe Gen5 (현행) | 64 GB/s | 128 GB/s |
| PCIe Gen6 (등장 중) | 128 GB/s | 256 GB/s |
이게 충분히 빨라 보이지만, GPU 내부 HBM 대역폭(8 TB/s)에 비하면 60~100배 느립니다. 즉 CPU에서 GPU로 데이터를 옮기는 과정은 항상 GPU 자체 연산보다 훨씬 느린 병목이고, 그래서 "한 번 올린 데이터는 가능한 오래 GPU에 두라"가 GPU 프로그래밍의 첫 번째 규칙이 됩니다.
이 병목이 워낙 거대해서, NVIDIA는 PCIe를 우회하는 자체 통로를 만들기 시작했습니다. 그게 NVLink 계열입니다.
세 번째 메커니즘: NVLink-C2C — CPU와 GPU를 한 NUMA 노드처럼
2023년 Grace Hopper(GH200)부터, 그리고 현재 양산 중인 Grace Blackwell(GB200)에서, NVIDIA는 CPU와 GPU를 같은 패키지에 박고 둘 사이를 PCIe가 아닌 자체 인터커넥트로 직결하기 시작했습니다. 이게 NVLink-C2C(Chip-to-Chip) 입니다.
스펙은 PCIe Gen5의 7배입니다.
| 통로 | 양방향 대역폭 |
|---|---|
| PCIe Gen5 x16 | 128 GB/s |
| NVLink-C2C | 900 GB/s |
이 차이는 단순한 속도 차이가 아니라 소프트웨어가 보는 메모리 모델 자체를 바꿉니다. 멀티소켓 서버 경험이 있다면 NUMA(Non-Uniform Memory Access)를 들어봤을 텐데, NUMA는 "CPU 소켓이 두 개 있을 때 각자 자기 메모리를 갖고 있지만 서로의 메모리도 좀 느리게 접근할 수 있는 구조"입니다. NVLink-C2C는 그 NUMA를 CPU와 GPU 사이에 만들어 줍니다.
즉 Grace Hopper/Blackwell 시스템에서 GPU는 자기 HBM뿐 아니라 옆에 붙은 Grace CPU의 LPDDR5X 메모리(480GB 이상)도 마치 "조금 느린 자기 메모리"처럼 접근합니다. 반대로 CPU도 GPU HBM에 직접 포인터로 접근 가능합니다. 메인보드 PCIe 슬롯 너머의 별개 컴퓨터가 아니라, 같은 NUMA 도메인의 다른 소켓처럼 보이는 겁니다.
본인이 처음 본 GH200 슈퍼칩 다이어그램이 정확히 이 구조입니다.
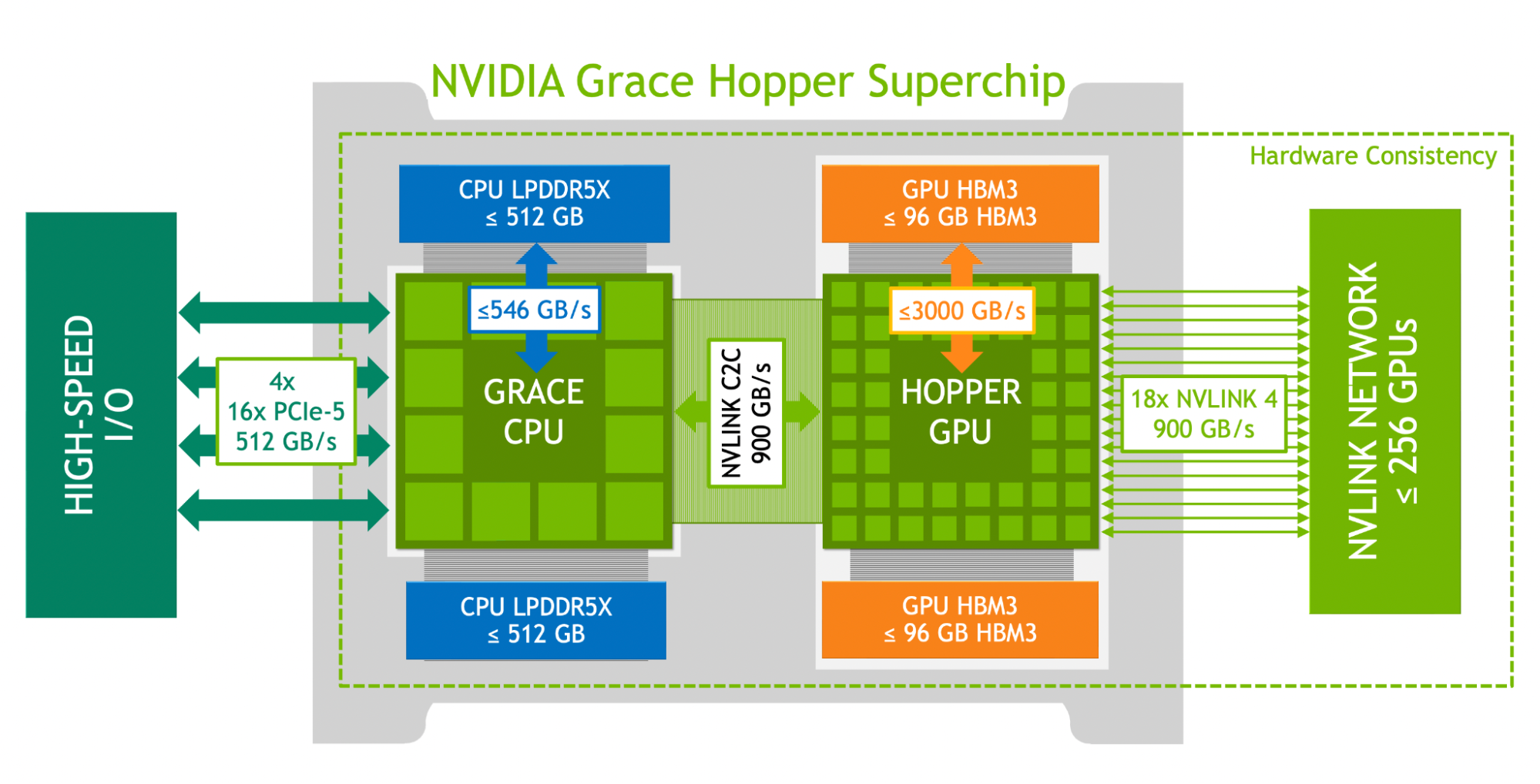
- CPU(Grace) ↔ LPDDR5X 546 GB/s
- GPU(Hopper) ↔ HBM3 3 TB/s
- CPU ↔ GPU(NVLink-C2C) 900 GB/s
- CPU ↔ 외부 I/O(PCIe Gen5 x16 ×4) 512 GB/s
- GPU ↔ 다른 GPU(NVLink 4) 900 GB/s ×18
핵심은 NVLink-C2C 900 GB/s가 다른 모든 통로 중 가장 굵다는 것이 아니라, CPU와 GPU를 같은 메모리 공간으로 묶기에 충분히 빠르다는 것입니다.
더 깊이 공부하고 싶다면?
Grace CPU는 x86이 아니라 Arm Neoverse V2 기반 72코어 칩입니다. NVIDIA가 Arm을 인수하려다 실패했지만, 결국 자체 Arm CPU는 만들어 냈고, 그게 데이터센터 GPU 옆에 박혀 PCIe 종속에서 탈출한 핵심입니다. AMD는 비슷한 시도로 MI300A에서 Zen4 CPU + CDNA3 GPU를 한 패키지에 박았습니다.
- 검색 키워드:
NVLink-C2C protocol,Grace CPU Neoverse V2,MI300A APU,Coherent memory CXL
네 번째 메커니즘: CUDA Unified Memory — "그냥 포인터로 써라"
NVLink-C2C가 하드웨어 통로라면, CUDA Unified Memory는 그 위에 얹는 소프트웨어 추상입니다.
전통적으로 GPU 프로그래밍은 다음과 같습니다.
float *h_data = malloc(size); // CPU 메모리
float *d_data;
cudaMalloc(&d_data, size); // GPU 메모리
cudaMemcpy(d_data, h_data, size, ...); // 복사 (수동)
kernel<<<...>>>(d_data); // GPU 일 시킴
cudaMemcpy(h_data, d_data, size, ...); // 결과 복사 (수동)CPU 포인터와 GPU 포인터를 별도로 관리하고, 명시적으로 복사를 호출해야 합니다. 백엔드 개발자가 분산 캐시 쓰는 느낌과 비슷합니다.
Unified Memory는 이걸 다음으로 줄입니다.
float *data;
cudaMallocManaged(&data, size); // CPU/GPU 공통 포인터
data[0] = 3.14; // CPU가 씀
kernel<<<...>>>(data); // GPU가 같은 포인터로 읽음
cudaDeviceSynchronize();
printf("%f\n", data[0]); // CPU가 결과 읽음같은 포인터가 CPU에서도 GPU에서도 유효합니다. 마치 하나의 메모리 공간을 공유하는 것처럼 보입니다.
내부적으로는 CUDA 드라이버가 페이지 단위로 데이터를 자동으로 옮겨다닙니다. CPU가 그 페이지에 접근하면 GPU에 있던 페이지가 CPU 쪽으로 마이그레이션되고, 반대도 마찬가지입니다. 우리가 익숙한 OS 가상 메모리 페이지 폴트와 비슷한 메커니즘을, CPU와 GPU 사이에서 굴리는 셈이죠.
다만 자동이라고 공짜는 아닙니다. 페이지를 잘못 이동시키면 핑퐁(ping-pong)이 일어나고, 그게 PCIe라면 성능이 폭망합니다. 그래서 NVLink-C2C가 들어온 Grace Hopper/Blackwell에서 Unified Memory가 진짜로 쓸 만해졌다고 평가받습니다. 통로가 7배 굵어졌으니 페이지 마이그레이션 비용이 그만큼 싸졌기 때문입니다.
Deep Dive: 같은 PyTorch 코드, 세 가지 하드웨어
x = torch.randn(N).cuda()같은 한 줄을 세 가지 하드웨어에서 돌릴 때 어떤 일이 일어나는지 비교해 봅시다.
(A) 일반 데스크탑/서버 (PCIe로 연결된 GPU)
CPU DRAM → PCIe(64 GB/s) → HBM. 큰 데이터일수록 PCIe가 병목. DataLoader에 pin_memory=True 옵션을 주는 이유는, 페이지가 swap out되지 않도록 pin해서 PCIe DMA 전송을 최대 속도로 끌어내기 위함입니다.
(B) DGX H100 같은 PCIe 기반 데이터센터 시스템
위와 동일하지만 CPU는 보통 듀얼 소켓 Xeon/EPYC이고, GPU도 8장. CPU↔GPU 통신은 여전히 PCIe Gen5. GPU↔GPU는 NVLink(아래 3장 참조) 라는 점이 다를 뿐, CPU↔GPU 경로는 동일합니다.
(C) Grace Hopper / Grace Blackwell (NVLink-C2C 직결)
CPU LPDDR5X ←NVLink-C2C(900 GB/s)→ GPU HBM. 같은 한 줄이지만 통로가 14배 굵습니다. 대용량 임베딩처럼 HBM에 다 안 들어가는 데이터를 CPU LPDDR5X(최대 480GB)에 두고 GPU가 직접 읽어쓰는 패턴이 비로소 실용적이 됩니다. 추천 시스템이나 매우 큰 임베딩 테이블을 가진 모델이 이 구조의 직접 수혜자입니다.
이 차이가 곧 NVIDIA가 단품 GPU에서 CPU+GPU 통합 슈퍼칩으로 사업 모델을 옮겨가는 이유 중 하나입니다. 같은 GPU라도 옆에 Grace CPU가 붙어 있으면 처리할 수 있는 워크로드의 폭이 다릅니다.
3장. 한 대의 서버는 더 이상 한 대가 아니다 — 랙 단위 Scale-Up
GPU 한 장의 구조와 그것이 CPU와 어떻게 통신하는지를 봤습니다. 이제 다음 의문이 남습니다. 수십·수백·수천 장의 GPU를 어떻게 한 모델 학습/추론에 묶어 쓰는가?
이 질문에 대한 답은 두 갈래입니다.
- Scale-Up (랙 안): GPU 여러 장을 같은 박스/같은 랙에 넣고, 한 대처럼 동작하게 만든다.
- Scale-Out (랙 사이): 여러 랙을 외부 네트워크로 묶어, 모델 학습을 분산한다.
3장은 Scale-Up, 4장은 Scale-Out을 다룹니다. 이 구분이 NVIDIA 실적표를 이해하는 데도 결정적입니다.
첫 번째 메커니즘: NVLink — GPU 간 직결 통로
CPU↔GPU에 NVLink-C2C가 있다면, GPU↔GPU에는 NVLink(그냥 NVLink) 가 있습니다. 한 패키지 안이 아니라 같은 박스 안 다른 GPU 카드 사이를 PCIe 우회로 직결합니다.
세대별 GPU 1장당 NVLink 양방향 대역폭은 다음과 같습니다.
| 세대 | GPU당 NVLink 대역폭 (양방향) |
|---|---|
| NVLink 3 (Ampere, A100) | 600 GB/s |
| NVLink 4 (Hopper, H100) | 900 GB/s |
| NVLink 5 (Blackwell, B200) | 1.8 TB/s |
| NVLink 6 (Rubin) | 3.6 TB/s 예정 |
같은 박스 안 GPU 8장을 묶을 때, NVLink는 평균 PCIe보다 14배(NVLink 5 기준) 빠릅니다. 그래서 모델 병렬화(Tensor Parallelism, Pipeline Parallelism)가 가능해집니다.
두 번째 메커니즘: HGX 보드 — GPU 8장이 한 메인보드처럼
NVIDIA가 데이터센터에 파는 GPU는 단품으로 잘 안 나옵니다. HGX 보드라는 형태로 묶어 팝니다.
- HGX H100: GPU 8장이 한 보드 위에 박혀 있고, 그 사이를 NVLink 4세대로 풀 메시 직결
- HGX B200: GPU 8장이 NVLink 5세대로 풀 메시 직결
이 보드 한 장이 곧 우리가 흔히 말하는 "DGX/HGX 서버 1대"의 본체 핵심이고, AWS·GCP·Azure에서 빌리는 8GPU 인스턴스의 실체이기도 합니다. 보드 한 장에서 GPU↔GPU 통신은 매우 빠르지만, 8장이 한계입니다.
문제는 LLM이 8장 GPU 메모리에 안 들어가기 시작하면서부터입니다. GPT-4 급, 그리고 그 이상의 모델은 한 모델을 80~200장의 GPU에 쪼개야 합니다. 그러면 보드를 넘어가는 통신이 필요해지고, 이 지점에서 NVLink Switch와 NVL 랙 시스템이 등장합니다.
세 번째 메커니즘: NVLink Switch와 NVL72 — 한 랙이 곧 한 GPU 도메인
NVLink Switch는 백엔드 개발자가 익숙한 네트워크 스위치를 GPU 전용으로 만든 칩입니다. 여러 GPU의 NVLink 포트를 받아서 그들 사이를 풀 메시로 연결합니다.
현행 주력 시스템 GB200 NVL72는 다음과 같이 생겼습니다.
- 18개의 1U 컴퓨트 트레이 (각 트레이당 Grace CPU 2개 + Blackwell GPU 4개)
- 9개의 NVLink Switch 트레이
- 한 랙 총합: Grace CPU 36개 + Blackwell GPU 72개
- 총 메모리: HBM3e 13.4 TB (통합 GPU 메모리)
- FP4 연산 성능: 1.44 exaFLOPS (희소성 포함)
- 랙 내 GPU↔GPU NVLink 총 대역폭: 130 TB/s
- 무게 1.36톤, 전력 120kW, 액체 냉각
여기서 핵심은 "72장의 GPU가 모두 NVLink Switch를 통해 한 도메인으로 묶인다"는 것입니다. 어떤 GPU에서 어떤 GPU로도 1.8 TB/s 통로로 직접 통신 가능합니다. 소프트웨어 입장에서는 "GPU 72장이 곧 한 거대한 가상 GPU" 처럼 동작합니다.
CPU 백엔드 개발자 비유로 옮기면, 72개 머신을 RDMA 네트워크로 묶은 클러스터가 아니라 NUMA 노드 72개짜리 한 대의 거대한 SMP 서버에 가깝습니다.
랙 한 대 가격은 약 300만~400만 달러로 알려져 있고, 액체 냉각·전력 인프라까지 같이 설계해서 팝니다. 부동산처럼 "랙 한 대"가 거래 단위입니다.
NVIDIA 공식 페이지: GB200 NVL72
더 깊이 공부하고 싶다면?
NVL72의 백플레인을 사진으로 보면 그야말로 구리 케이블이 5,000가닥 정도 깔린 광경입니다. 광케이블이 아니라 구리를 쓰는 이유는, 짧은 거리에서 광-전 변환 손실보다 구리 직결이 효율적이기 때문이고, NVIDIA가 직접 이 케이블 설계도 합니다. 즉 NVIDIA는 칩 뿐 아니라 케이블 어셈블리까지 파는 회사가 되었습니다.
- 검색 키워드:
NVL72 copper backplane,NVLink Switch chip,Rack-scale GPU domain,NVSwitch fabric
네 번째 메커니즘: 한 도메인 크기가 왜 중요한가
NVIDIA가 NVL72에 이렇게 돈을 들이는 이유는 무엇일까요? GPU 72장을 그냥 외부 네트워크로 묶으면 안 되나요?
답은 LLM 워크로드의 통신 패턴에 있습니다.
- LLM 추론의 KV cache: 트랜스포머는 매 토큰마다 이전 토큰들의 Key/Value를 캐싱해 둡니다. 모델이 커지고 컨텍스트 길이가 길어질수록 이 KV cache가 거대해집니다(수십 GB~수백 GB). 이게 한 NVLink 도메인 안에 다 들어가야 토큰당 latency가 안 무너집니다.
- MoE(Mixture of Experts): 최신 LLM의 절반 이상이 MoE 구조입니다. 토큰마다 256개 전문가 중 8개를 골라서 라우팅하는데, 이 라우팅 통신이 NVLink 도메인을 넘어가면 추론 throughput이 폭락합니다.
- Tensor Parallelism: 한 행렬 곱을 여러 GPU에 쪼개는 분산 학습 기법. 매 layer마다 GPU 사이에 결과를 교환해야 하므로, 통신 대역폭이 곧 학습 속도입니다.
요약하면 "한 NVLink 도메인 = 모델 한 덩어리가 빠르게 들어갈 수 있는 단일 메모리 풀" 입니다. 도메인이 클수록 더 큰 모델을 빠르게 돌릴 수 있고, 도메인 경계를 넘는 순간 속도가 한 자릿수 떨어집니다.
H100 시대의 NVLink 도메인은 8장(HGX 보드 한 장)이었습니다. NVL72에서 그게 72장으로 9배 커진 것이 Blackwell 세대의 핵심 가치 명제입니다.
다섯 번째 메커니즘: 로드맵 — NVL144, NVL576, 그리고 그 이후
NVIDIA가 발표한 차세대 로드맵은 NVLink 도메인을 계속 키우는 방향입니다.
| 세대 | 랙 시스템 | NVLink 도메인 패키지 | 랙당 다이 | 출시 |
|---|---|---|---|---|
| Hopper | GH200 NVL32 | 32 | 32 | 2023~ |
| Blackwell | GB200 NVL72 | 72 | 144 (dual-die) | 2024 양산 |
| Blackwell Ultra | GB300 NVL72 | 72 | 144 (dual-die) | 2025 |
| Rubin | Vera Rubin NVL144 | 144 | 288 (dual-die) | 2026 H2 |
| Rubin Ultra | NVL576 | 576 | 1,152 (dual-die) | 2027 H2 |
| Feynman | (미정) | TBD | TBD | 2028+ |
NVL 뒤의 숫자는 한 NVLink 도메인에 묶이는 GPU 패키지(소켓) 수를 가리킵니다. 다이 수가 아닙니다.
- Blackwell부터 GPU 한 패키지에 다이 2장이 붙는 dual-die 패키지입니다. 한 패키지 안에서 두 다이는 NV-HBI(약 10 TB/s)로 직결되어, 소프트웨어가 볼 땐 한 장의 GPU로 보입니다. 그래서 NVL72는 패키지 72개 = 다이 144개.
- NVL72 → NVL144 → NVL576 으로 가면서 NVIDIA는 한 NVLink 도메인에 묶는 물리 패키지 수 자체를 2~8배씩 다이렉트 스케일업하고 있습니다. 마케팅 숫자 트릭이 아니라 실제로 도메인 크기가 커지는 중입니다.
- Rubin Ultra의 NVL576은 한 랙당 GPU 패키지 576개(다이 1,152개). 직관적으로 떠올렸던 "랙 한 대에 칩 몇 백 개"가 이 세대에서 맞아 들어갑니다.
이 로드맵의 의미는 단순합니다. NVIDIA는 NVLink 도메인을 매 세대마다 2~8배씩 키우는 회사가 되었습니다. 그리고 그 키우는 작업의 절반은 GPU 자체가 아니라 NVLink Switch, 케이블, 전력·냉각 시스템입니다. 이게 바로 다음 4장의 주제, 그리고 실적표 Networking 폭증의 핵심입니다.
4장. 네트워크가 곧 컴퓨터다 — 랙 사이 Scale-Out
NVL72 한 랙은 거대하지만, GPT-5급 모델 학습에는 그것도 부족합니다. 실제 AI 데이터센터는 NVL72 랙을 수십~수백 대 묶어 운영합니다. 그 묶음을 NVIDIA는 DGX SuperPOD라고 부르고, 더 큰 단위는 그냥 "AI Factory"라고 부릅니다.
이 단계에서 등장하는 게 실적표에서 본 Networking 세그먼트의 본체입니다.
첫 번째 메커니즘: 대역폭의 절벽
먼저 숫자를 직관적으로 잡아 봅시다.
| 통신 구간 | 양방향 대역폭 (GPU당) | 비유 |
|---|---|---|
| GPU 내부 HBM ↔ 연산기 | 8 TB/s | CPU L1 캐시 |
| 같은 랙 안 GPU ↔ GPU (NVLink 5) | 1.8 TB/s | CPU L2/L3 캐시 |
| 랙 간 (InfiniBand NDR/Spectrum-X) | 50~100 GB/s | 메인 DRAM |
| 외부 인터넷 / 데이터센터 외 | ~1 GB/s | 디스크 |
같은 랙 안과 랙 사이의 대역폭 차이가 18~36배 납니다. 통신 거리가 미터 단위로 길어지는 것만으로 한 자릿수 이상 떨어지는 거죠. 이게 "Scale-Up 도메인 안에 워크로드를 가둬야 한다"는 원칙이 나오는 이유입니다.
그렇다고 모델 학습을 한 랙에 가두기는 불가능합니다. 학습 워크로드는 어차피 여러 랙으로 펴야 하고, 그러면 이 50~100 GB/s 통로를 통한 분산 학습 통신이 학습 속도를 결정합니다.
두 번째 메커니즘: RDMA와 GPUDirect — CPU 우회
랙 사이 통신의 첫 번째 핵심은 GPU 메모리에서 다른 랙의 GPU 메모리로 데이터를 옮길 때, CPU를 거치지 않는다는 것입니다.
전통적인 TCP/IP 통신은 다음 경로를 거칩니다.
GPU A의 HBM → CPU A의 DRAM → NIC A → 네트워크 → NIC B → CPU B의 DRAM → GPU B의 HBM각 단계마다 메모리 복사가 일어나고, CPU 인터럽트 처리가 들어갑니다. 100GbE 네트워크라도 실효 대역폭은 절반 이하로 떨어지고, latency도 ms 단위가 됩니다.
RDMA (Remote Direct Memory Access) 는 이 경로를 단축합니다.
GPU A의 HBM → NIC A → 네트워크 → NIC B → GPU B의 HBMCPU와 메인메모리를 우회합니다. 이걸 GPU 메모리까지 적용한 것이 GPUDirect RDMA이고, 현대 AI 클러스터의 기본 통신 메커니즘입니다.
백엔드 개발자 비유로 옮기면, gRPC over TCP가 아니라 사용자 공간 zero-copy + DMA로 직결되는 메시지 패싱입니다. CPU는 통신 setup에만 끼고, 실제 데이터 이동은 NIC ASIC이 다 합니다.
이 RDMA를 지원하는 NIC 칩셋 시장의 1위가 Mellanox였고, NVIDIA가 2020년에 70억 달러에 인수했습니다. 그 결과가 지금 NVIDIA의 ConnectX·BlueField 시리즈 NIC, 그리고 InfiniBand·Spectrum-X 스위치입니다. Mellanox 인수가 NVIDIA의 진짜 게임체인저였다는 평가가 지금 와서 보면 명확합니다.
세 번째 메커니즘: All-Reduce — 분산 학습의 본체 통신
분산 학습에서 가장 자주 일어나는 통신은 All-Reduce입니다. 무엇인가 하면:
- GPU 각각이 자기 데이터로 gradient 계산을 합니다 (각 GPU 결과는 다 다름).
- 모든 GPU가 자기 gradient를 다른 모든 GPU에게 알리고, 합산한 결과를 다 같이 받아야 합니다.
- 그래야 다음 step에서 모든 GPU가 동일한 모델 파라미터 업데이트를 수행할 수 있습니다.
이걸 N개 GPU에 대해 naive하게 하면 통신량이 O(N²)으로 폭발합니다. NCCL(NVIDIA Collective Communications Library)이 똑똑한 토폴로지(ring, tree, double binary tree)를 골라서 O(N) 수준으로 줄입니다.
PyTorch에서 dist.all_reduce(tensor) 한 줄을 호출하면, 그 아래에서 NCCL이 현재 클러스터 토폴로지를 분석(NVLink 도메인, IB 도메인, 다단 스위치)하고, 적합한 알고리즘을 선택하고, GPUDirect RDMA로 각 GPU 사이 데이터를 송수신하고, 완료 시 callback으로 통보합니다.
이 작업이 한 step당 수천 번 일어납니다. 그래서 NCCL이 사실상 분산 학습의 진짜 OS이고, NVIDIA가 NCCL 코드를 직접 관리하는 이유입니다.
네 번째 메커니즘: InfiniBand vs Spectrum-X — 두 가지 무손실 네트워크
NVIDIA는 데이터센터 GPU 간 네트워크로 두 가지를 제공합니다.
- InfiniBand (Quantum 시리즈) — 슈퍼컴퓨터 전통의 무손실 네트워크. AI 학습 클러스터의 기본. 현행 NDR 세대는 400Gb/s, XDR 800Gb/s가 등장 중.
- Spectrum-X (이더넷) — 일반 데이터센터 표준 이더넷 위에 NVIDIA의 ASIC과 NIC을 얹어, AI 워크로드 전용으로 튜닝한 무손실 이더넷.
두 가지 다 핵심 가치는 무손실(lossless) 입니다. 일반 이더넷은 폭주하면 패킷을 버리고, TCP가 재전송하는 모델인데, AI 학습에서는 한 패킷이 늦으면 GPU 수백 장이 그 동기화를 기다리며 같이 놀게 됩니다. 그래서 하드웨어 단에서 패킷이 절대 안 버려지는 네트워크가 필요합니다.
NVIDIA의 Spectrum-X가 이 무손실을 이더넷 위에서 달성하는 방식이 흥미롭습니다.
- Adaptive Routing — 스위치 ASIC이 실시간으로 폭주 지점을 감지해 패킷 경로를 우회시킴.
- Congestion Control — NIC이 송신 속도를 자동 조절해서 스위치 큐가 꽉 차지 않게 함.
- Performance Isolation — 한 워크로드가 다른 워크로드의 통신을 방해하지 않도록 격리.
이 모든 게 ASIC 하드웨어에서 실시간으로 일어납니다. 일반 이더넷 스위치라면 운영체제/펌웨어 소프트웨어에서 처리하는 일을, NVIDIA는 칩에 박은 것입니다.
다섯 번째 메커니즘: SHARP — 네트워크가 연산까지 한다
여기서 한 발 더 나아간 게 SHARP (Scalable Hierarchical Aggregation and Reduction Protocol) 입니다.
위에서 본 All-Reduce를 다시 봅시다. N개 GPU가 각자 가진 텐서를 합산하는 작업입니다. 전통적으로는 GPU끼리 직접 데이터를 주고받으며 합산했습니다.
SHARP는 다음과 같이 바꿉니다.
- GPU들이 각자의 텐서를 InfiniBand 스위치에 보냅니다.
- 스위치 ASIC 안에 있는 reduction 회로가 그 텐서들을 받으면서 실시간으로 합산합니다.
- 합산 결과만 GPU에게 보냅니다.
즉 네트워크 스위치가 곧 연산 가속기 역할을 합니다. GPU는 자기 텐서만 보내고 결과만 받으면 됩니다. 통신량이 절반 이하로 줄고, 동기화 시간이 짧아집니다.
이 기능을 가능하게 하는 SHARP는 InfiniBand 표준 위에서 NVIDIA가 정의한 확장이고, Spectrum-X에도 적용되고 있습니다. "스위치가 단순 패킷 포워더가 아니라 연산기"라는 발상이 NVIDIA의 네트워킹 사업이 단순 백본 회사가 아닌 이유입니다.
더 깊이 공부하고 싶다면?
SHARP는 reduction 외에도 broadcast, barrier 같은 다른 집합 통신 연산도 가속합니다. MPI(Message Passing Interface)를 알면 친숙한 개념이고, MPI를 GPU에 맞게 재해석한 게 NCCL + SHARP의 조합이라고 볼 수 있습니다.
- 검색 키워드:
NCCL collective,SHARP In-Network Computing,Quantum InfiniBand switch,Spectrum-X Ethernet AI fabric
Deep Dive: 왜 Mellanox를 70억 달러에 샀나
2020년 NVIDIA의 Mellanox 인수는 당시에는 "왜 GPU 회사가 NIC 회사를 사지?"라는 평가가 많았습니다. 지금 와서 보면 명확합니다.
- GPU를 데이터센터 단위로 묶으려면 무손실 RDMA 네트워크가 필수.
- 그걸 만들 수 있는 회사가 사실상 Mellanox뿐이었음.
- GPU와 네트워크 칩을 같은 회사가 같이 만들면, NCCL·NVLink·NIC·스위치를 수직 통합해서 경쟁사가 따라오기 어려운 성능을 낼 수 있음.
- 부가적으로 NIC에 ARM 코어를 박은 DPU(BlueField) 가 등장. DPU는 호스트 CPU 일을 일부 떠안아서 가상화·보안·스토리지 처리를 NIC에서 함. 이게 또 별도 사업이 됨.
결과적으로 NVIDIA의 매출 구조가 이렇게 바뀝니다.
- 칩 한 장 팔던 회사 → 랙 한 대를 파는 회사
- 랙 한 대에는 GPU만 들어가는 게 아니라 NVLink Switch 9개 + InfiniBand/Spectrum-X 스위치 + NIC 수십 장 + DPU + 케이블 5000가닥이 같이 들어감
- 모두 NVIDIA 마진 안에 있음
이게 실적표의 "Networking +199% YoY"의 본질입니다. GPU 출하가 늘면 자동으로 네트워킹 매출이 따라오는 구조를 만들어 놓은 거죠.
5장. 다시 실적표 — 세그먼트를 엔지니어 시선으로 재해석
여기까지 메커니즘을 이해하고 나면, 처음에 본 실적표가 완전히 다르게 읽힙니다.
Data Center Compute : $60.4B YoY +77%
Data Center Networking : $14.8B YoY +199%
Edge Computing : $6.4B YoY +29%세그먼트별로 정리해 보겠습니다.
Data Center Compute = "GPU + Grace CPU 칩 자체"
- Blackwell B200/B300, 다음 세대 Rubin 등 GPU 다이의 칩값
- Grace CPU의 칩값
- HBM 비용 포함 (NVIDIA가 사서 패키지에 박아 파는 구조)
- 즉 우리가 흔히 "엔비디아 칩 매출"이라고 부르는 것
가장 익숙한 부분이지만, 사실 이게 가장 단순한 부분입니다. 매 분기 새 칩을 더 많이 팔면 매출이 늘어납니다. +77% YoY는 Blackwell 양산이 본격화되면서 일어난 일이고, Rubin이 H2 2026에 나오면 또 한 번 점프가 예상됩니다.
Data Center Networking = "랙 안과 사이를 잇는 모든 것"
이게 본 글의 핵심 통찰입니다. Networking 매출의 구성:
- NVLink Switch 칩 (랙 안 GPU 간 연결) — NVL72 한 랙에 9개씩
- NVLink 케이블 어셈블리 — 한 랙에 약 5000가닥의 구리 케이블
- InfiniBand Quantum 스위치 (랙 간 연결, 무손실)
- Spectrum-X 이더넷 스위치 (랙 간 연결, 이더넷 진영용 대안)
- ConnectX NIC, BlueField DPU (서버 측 네트워크 카드)
+199% YoY는 이게 GPU 출하의 종속 변수이기 때문에 GPU보다 더 가파르게 따라옵니다. GB200 NVL72 한 랙이 팔리면:
- GPU 72장 → Compute 매출
- NVLink Switch 9개 + 케이블 + InfiniBand 스위치/NIC → Networking 매출 (랙 한 대당 0.5~0.7M$ 추정)
그리고 한 랙만 파는 게 아니라 DGX SuperPOD(8랙) 단위로 팔리면, 랙 사이를 잇는 InfiniBand 스위치가 추가됩니다. 즉 클라이언트가 큰 클러스터를 살수록 Networking 비중이 누적적으로 커집니다.
이게 NVIDIA가 단순 "GPU 출하 사이클"이 아니라 "AI Factory 인프라 사이클" 에 있는 이유입니다.
Edge Computing = "데이터센터 바깥의 NVIDIA 칩"
NVIDIA가 FY2027 Q1(2026년 5월 발표) 부터 리포팅 구조를 개편하면서 새로 분리한 세그먼트로, 데이터센터가 아닌 곳에서 굴러가는 NVIDIA 칩들을 묶습니다.
- Jetson 시리즈 — 임베디드 GPU 모듈. 드론·로봇·산업 카메라·자율주행 prototype.
- DRIVE 시리즈 — 자율주행 자동차용 SoC. Mercedes·BYD·Toyota 등이 채택.
- Isaac / GR00T — 로봇 학습/추론 플랫폼. Humanoid 로봇 기업들이 NVIDIA 칩 위에서 정책 학습.
- Omniverse 산업용 엣지 — 공장·물류센터에서 디지털 트윈 + 실시간 추론.
+29% YoY는 데이터센터에 비하면 작아 보이지만, 절대 규모 6.4B는 결코 작지 않고, 무엇보다 AI가 클라우드에서 물리 세계로 흘러내려가는 다음 단계의 출발점입니다. 본인이 본 그림이 GH200(데이터센터)이었다면, Edge Computing 쪽은 Jetson Thor(로봇), DRIVE Thor(자동차) 같은 별도 칩 라인업입니다.
한눈에 정리
graph LR
Customer[고객사<br/>OpenAI · Meta · Tesla · 자동차사] --> AIFactory[AI Factory<br/>데이터센터]
Customer --> EdgeProducts[Edge 제품<br/>로봇 · 자동차 · 공장]
AIFactory --> Compute[Data Center Compute<br/>GPU + Grace CPU 칩]
AIFactory --> Networking[Data Center Networking<br/>NVLink Switch + IB/Spectrum-X<br/>NIC/DPU + 케이블]
EdgeProducts --> Edge[Edge Computing<br/>Jetson + DRIVE + Isaac/Omniverse]
Compute -.->|랙 단위 판매로 자동 결합| Networking핵심은 Compute와 Networking이 강하게 결합되어 있다는 것입니다. 고객이 GB200 랙 한 대를 사면 두 세그먼트가 자동으로 같이 매출에 잡힙니다. 이게 NVIDIA의 진짜 비즈니스 모델이고, AMD·Intel이 단품 GPU만 팔아서 따라잡기 어려운 구조적 해자입니다.
결론: 백엔드 개발자가 가져갈 4가지 멘탈 모델
긴 글이었습니다. 처음에 가졌던 의문 — "GPU는 어떻게 돌아가나? CPU와는 어떻게 통신하나? 수많은 GPU를 어떻게 엮나? Networking은 왜 돈을 그렇게 버나?" — 에 답하는 과정에서 본 메커니즘을, 멘탈 모델 네 개로 압축합니다.
1. GPU = 별도의 메모리 공간을 가진 비동기 데이터 병렬 가속기
CPU 프로그래밍에서 "다른 코어"는 같은 메모리를 공유합니다. GPU는 같은 메인보드의 다른 컴퓨터입니다. 별도 메모리, 별도 명령 시스템, 별도 실행 모델. CPU와 GPU 사이는 메시지 큐 기반 비동기 통신으로 움직입니다. PyTorch 한 줄이 GPU를 직접 실행시키지 않고, 큐에 명령을 던지고 끝납니다. 이 모델을 머릿속에 박아두면 GPU 디버깅과 최적화의 7할이 풀립니다.
2. 모든 레이어에서 대역폭이 한 자릿수씩 떨어진다
GPU 내부 HBM: 8 TB/s
같은 랙 내 NVLink: 1.8 TB/s (4.4배 ↓)
랙 사이 InfiniBand: 50-100 GB/s (18-36배 ↓)
외부 인터넷: 1 GB/s (50-100배 ↓)CPU 캐시 계층(L1→L2→L3→DRAM)이 한 자릿수씩 느려지는 것과 같은 구조가, GPU 컴퓨팅에서는 칩→랙→랙 사이→데이터센터 사이로 확장된 형태로 존재합니다. 워크로드를 최대한 빠른 레이어에 가두는 것이 모든 분산 학습 최적화의 본질입니다.
3. NVLink 도메인 = 가상의 거대한 단일 GPU
같은 NVL72 랙 안 72장 GPU는 소프트웨어 입장에서 "한 대의 거대 GPU"처럼 보입니다. 메모리 13.4 TB, 연산 1.44 exaFLOPS짜리 GPU 한 장이 가상으로 존재하는 셈입니다. 이 도메인이 클수록 더 큰 모델을 더 빠르게 돌릴 수 있고, 매 세대마다 NVIDIA가 이 도메인을 키우는 게 칩 회사가 아닌 시스템 회사로의 진화입니다.
- Hopper 시대: 8장 (HGX 보드)
- Blackwell 시대: 72장 (NVL72)
- Rubin Ultra 시대 (2027): 576장 (NVL576)
직관적으로 떠올린 "랙 한 대에 칩 몇 백 개"는 2027년부터 진짜가 됩니다.
4. NVIDIA는 칩이 아니라 "랙 운영체제 + 인프라"를 판다
처음에 본 실적표를 다시 봅시다. Compute 60.4B + Networking 14.8B + Edge 6.4B. 이 세 숫자가 따로 노는 게 아니라, 랙이라는 하나의 상품 안에 묶여 있습니다. GB200 NVL72 한 랙을 팔면 Compute(GPU 72장)와 Networking(스위치·NIC·케이블)이 같이 매출로 잡힙니다. NVIDIA는 GPU 회사가 아니라 랙 단위로 데이터센터를 통째로 설계해 파는 회사가 되었고, 그래서 Mellanox(네트워크), Run:ai(스케줄러), 그리고 NCCL 같은 소프트웨어 스택을 다 수직 통합한 것입니다.
이 통찰이 투자 관점에서도, 엔지니어 관점에서도 NVIDIA를 정확히 이해하는 출발점입니다.
- 투자 관점에서는 "GPU 출하 사이클"이 아니라 "AI Factory 인프라 사이클"이라는 더 큰 곡선을 봐야 합니다.
- 엔지니어 관점에서는 "다음 모델이 어디까지 커질 수 있는가"가 GPU 다이가 아니라 NVLink 도메인 크기·메모리 용량·랙 전력에 달려 있다는 점을 봐야 합니다.
처음에 막혔던 "엣지 컴퓨팅? 컴퓨팅 네트워크?"라는 의문에 이제 한 줄로 답할 수 있습니다.
- Compute: 칩 자체. GPU와 Grace CPU.
- Networking: 랙 안과 랙 사이를 잇는 모든 것. NVLink Switch, InfiniBand, Spectrum-X, NIC, DPU, 케이블. GPU 출하의 종속 변수라 더 가파르게 큼.
- Edge Computing: 데이터센터 밖. Jetson(임베디드), DRIVE(자동차), Isaac/GR00T(로봇).
그리고 그 모든 게 NVLink-C2C·NVLink·InfiniBand·RDMA·SHARP라는 수직 통합된 통신 스택 위에서 굴러갑니다. NVIDIA가 칩 회사라는 정의로는 더 이상 설명되지 않는 이유입니다.
참고자료
- NVIDIA Grace Hopper Superchip Architecture — Grace + Hopper + NVLink-C2C 백서
- GB200 NVL72 | NVIDIA — 현행 주력 랙 시스템
- Inside the NVIDIA Vera Rubin Platform — Rubin 세대 공식 소개
- NVIDIA Vera Rubin: 600kW Racks by 2027 — Introl Blog — Rubin Ultra NVL576 분석
- NVIDIA CUDA Programming Guide — SIMT Architecture
- NCCL: NVIDIA Collective Communications Library — 분산 학습 통신 표준
- NVIDIA Spectrum-X Platform — 이더넷 진영 AI 네트워크
- Mellanox SHARP In-Network Computing — 스위치 내 reduction
- NVIDIA Investor Relations — SEC Filings — FY2027 Q1 CFO Commentary (2026년 5월 발표) 포함. 이번 분기부터 Data Center + Edge Computing 체제로 세그먼트 개편
