1. Introduction
- Open-ended text generation은 prompt가 주어졌을때, 유창하고 일관성 있는 대답을 하는 것을 목적으로 한다.
- 하지만 likelihood가 가장 높은 sequence를 찾는 decoding은 짧고 반복적이며 유창하지 않은 문장을 생성하는 경향이 있으며, 크기가 작은 LM일수록 그 경향이 더 뚜렷하다.

- 이를 해결하기 위해 저자들은 위의 그림에서 보이는것처럼 크기가 큰 Expert LM의 Token 분포에서 크기가 작은 Amateur LM의 Token 분포를 빼주는 Contrastive Decoding을 제시해, 비교적 유창한 생서잉 가능한 Expert LM에서 Amateur LM의 경향성을 제거하는 방법론을 제시한다. (예시에서 Expert LM과 Amateur LM 모두 앞의 Honolulu와 Hawaii에 영햐을 받아 next token prediction에서 두 토큰에 높은 확률값을 부여했으나 contrastive decoding을 통해 상쇄되는 것을 확인할 수 있다)
- 제안하는 방법론은 (1) 추가적인 학습이 필요없는 방법론이며 (2) contrastive decoding하는 LM간의 크기 차이가 커질수록 그 효과가 극대화된다고 한다.
2. Problem Statement
- 문제상황은 우리가 아는 일반적인 LM setting인 n개의 token을 가진 input이 주어질 경우 m개의 token을 가진 문장을 생성하는 상황이다.
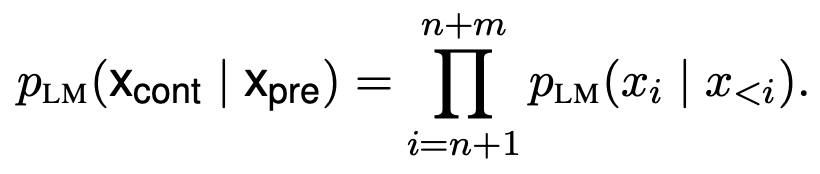
- baseline decoding strategy는 아래와 같다.
- Nucleas Sampling : 상위 p% 누적분포에서 sampling
- Top-K Sampling : 상위 K개의 token에서 sampling
- Greedy : 매 time-step마다 max liklihood token select
- Beam Search : Most probable sequence search의 대안으로 나온 greedy search
3 Contrastive Decoding
3.1 Intuition
- Reptition, Topic Drift, Self Contradiction과 같은 LM failure은 크기가 작은LM일 수록 더 높은 confidence level을 가지고 이를 생성하는 경향이 있다.
- 따라서 Expert LM에서 위와 같은 Amateur LM의 경향성을 제거하면 Decoding 성능을 향상시킬 수 있다.
- 하지만 위의 방법론이 적용되기 위해서는 Amateur LM의 생성 능력이 Expert LM의 생성 능력과 흐름은 비슷해야한다. 만약, Amateur LM이 아무말이나 생성하면 Expert LM에서 관련 경향성을 제거해도 성능 향상을 기대할 수 없다.
- 또한 Amateur LM이 항상 잘못된 Token을 생성하는 것이 아니기 때문에 이를 보정하는 수식도 필요하다.
3.2 Method
방법론은 매우 간단하다.
- 매 time step 마다 plausible token set 에 속해 있는 token들에 대해서 Expert LM과 Amateur LM의 log likelihood값의 차이를 구해주어 CD-Score라는 term으로 표기를 하고 beam search를 적용하였다.

- plausible token set 은 nucleas sampling과 유사하게 Expert LM내 확률값이 낮은 token의 영향력을 제거하기 위해 만들어준 집합이며, 는 0.1로 설정하였다.
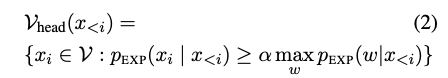
3.3 : Adpative Plausibility Constraint
저자들은 plausible token set 를 추가한 이유를 2개의 근거를 들어서 설명하고 있다.
-
False Positive 제거 : Expert LM에서 낮은 확률 값을 부여받은 token이 contrastive decoding에서 rewarding받을 가능성 제거 (ex. Expert LM에서 낮은 확률값 - bias로 인해 Amateur LM에서 더 낮은 값)
-
False Negative 제거 : Expert LM과 Amateur에서 모두 굉장히 높은 확률값은 그대로 활용하도록 (ex. uni + ##corn에서 ##corn에 대해서 Expert LM, Amateur LM ahen 0.99를 부여할 경우, ##corn만이 선택됨)
3.4 Choice of Amateur
제기하는 프레임워크의 핵심은 적절한 Amateur LM 선택을 통한 Expert LM내에서의 경향성 제거이며 저자들이 고려한 기준으 3가지이다.
- Scale : LM의 크기가 작을 수록 LM failure 확률이 높다. (GPT2끼리 비교한다면 GPT2-XL - GPT2-SMALL식으로 Expert와 Amateur 선정)
- Temepature : 를 활용해 Amateur LM의 Token dist 분포 조정
- Context Window : Contrastive Decoding 효과를 극대화하기 위해 Amatuer의 context-window (prompt size)를 Expert LM에 비해서 적게 두었다고 한다.
4. Interpretation
저자들은 아래의 2가지 관점을 기준으로 목적함수에 대한 해석을 제시한다.
4.1 Distinguishability
저자들은 본인들의 식이 PMI Score를 최대화하는 것이라고 합니다.
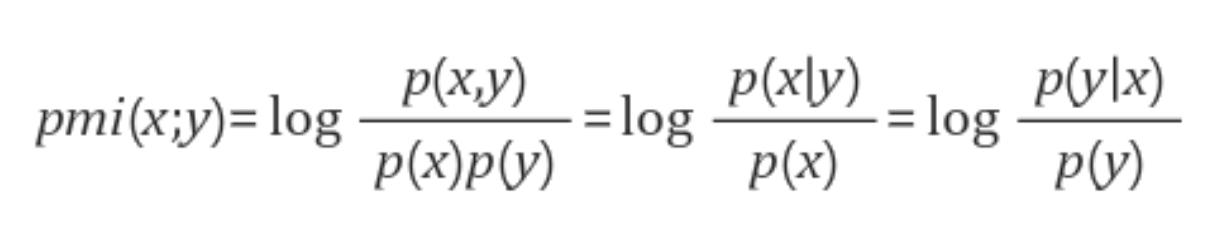
웨에 보이는 것처럼 PMI Score는 두 사건이 독립이면 0의 값을 가지지만, p(x) 대비 p(x|y)이 커지면 높아지게 되어 두 사건의 관련성이 높을수록 해당 점수는 높아진다.
저자들은 본인들의 목적함수를 아래와 같은 PMI 식으로 표현한다.
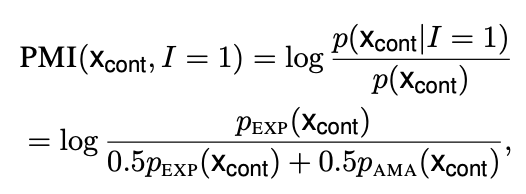
Expert LM에 의해 생성될 경우 이라고 하면 위의 PMI식처럼 표현이 되며 Expert LM은 동일하면서 Amateur LM term의 값이 작아질수록 해당 값은 커지게 된다.
따라서 목적함수의 값을 극대화하는 것은 두 모델 사이의 결과값의 차이를 극대화하는 것과 동일하다.
4.2 Pragmatic Communication
Pragmatic Communication이란 사회적 상황에서 적절한 의사 소통을 사용하는 것으로 무엇을 말할지, 어떻게 말할지, 언제 말할지 아는 것이다. 즉 화자는 높은 퀄리티의 언어를 청자에게 정보력 있게 전달해야한다.
저자들은 본인들의 목적함수가
1. Expert Prob에 더 높은 가중치를 줌으로 유창하고 유의미한 정보를 전달하고
2. Amateur Prob에 더 낮은 가중치를 줌으로 정보성이 덜한 정보를 제거한다고 주장한다.
5. Experimental Setup
사용한 open-ended text geneneration 데이터셋은 다음과 같다.
- Wikinews
- Wikipedia
- Story Domains
각 데이터셋의 passage token 개수가 160개 이하이면 활용하지 않았고, 첫 32 words를 prompt token으로 뒤의 256 token들을 생성하도록 하였다.
Automatic Evaluation는 다음과 같다.

Human Evaluation은 Fluency와 Prompt랑 생성한 문장이랑의 통일성을 보는 Coherence를 가지고 측정하였다.
Baselines Decoding 방법론들은 아래와 같다.
- Nucleus Sampling
- Top-K Sampling
- Typical Decoding
- Greedy Decoding (EXPERT LM only)
- SimCTG
Contrastive Decoding을 위한 Expert - Amateur Pair는 다음과 같다.
- GPT-2 XL (1.5b) vs GPT-2 small (100m)
- OPT (6.7b) vs OPT (125m)
- OPT (13b) vs OPT (125m)
Experimental Results
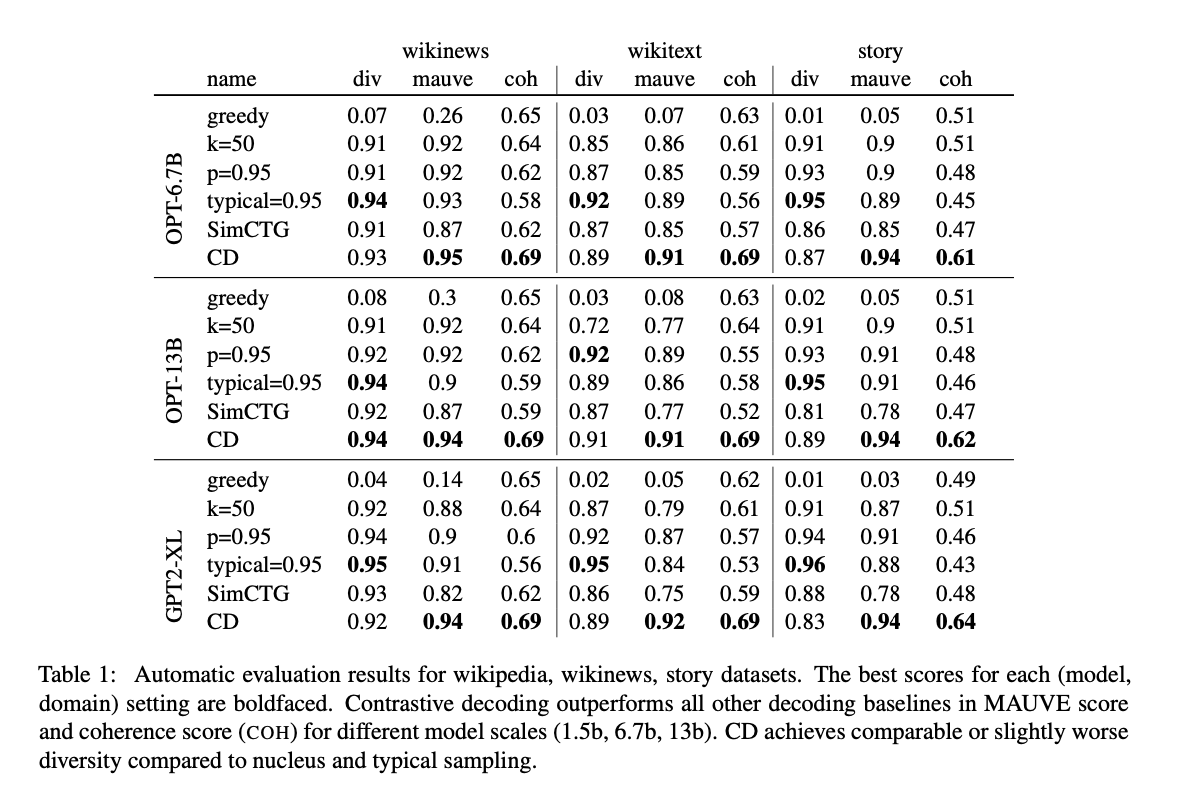
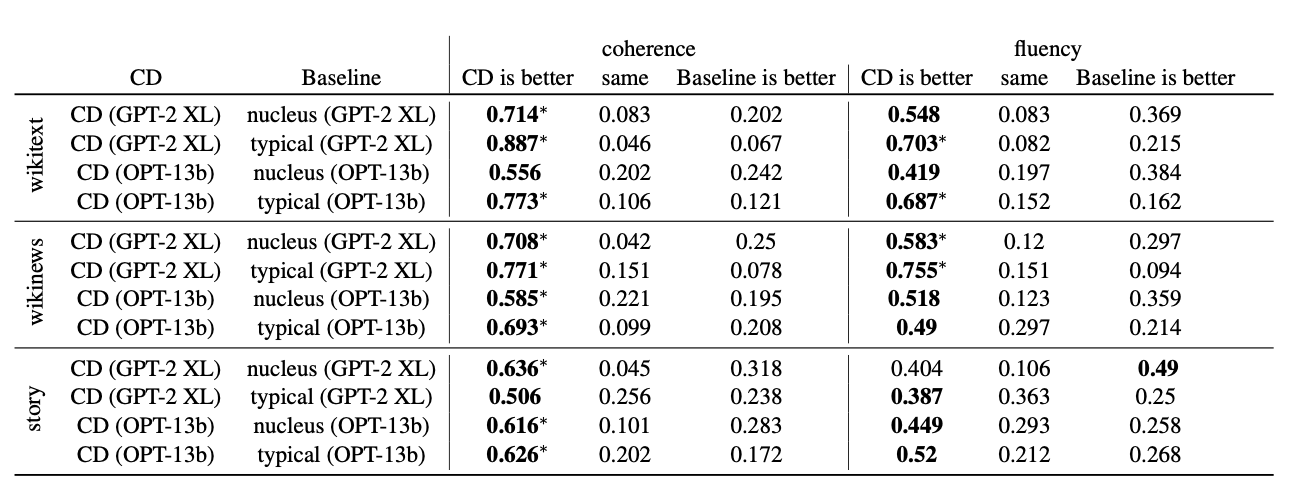
실험결과 Diversity를 제외한 모든 지표에서 Contrastive Decoding이 좋은 성능 보였습니다. 특히 Model Scale이 커질수록 Nucleus Sampling과 Contrastive Decoding의 차이가 줄어든다고 한다.
Ablation Study
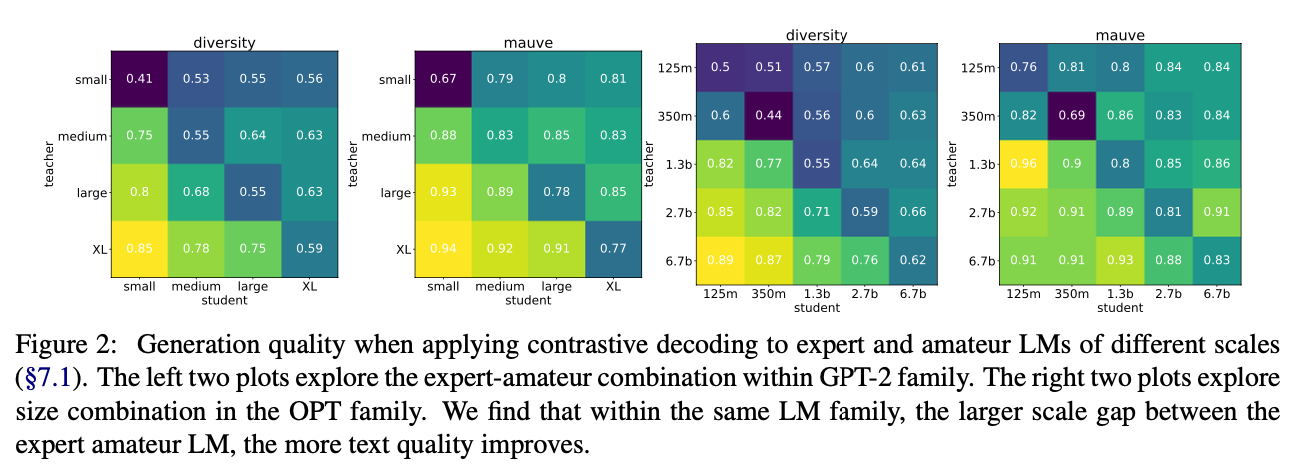
Ablation Study에 따르면 Expert와 Amateur 사이의 크기가 크면 클수록 contrastive decoding의 성능이 향상되며, tri-gram LM같이 Expert LM의 경향성을 따라가지 못하는 성능이 낮은 LM을 Amateur로 쓸 경우 contrastive decoding의 효용성을 활용할 수 없다고 한다.
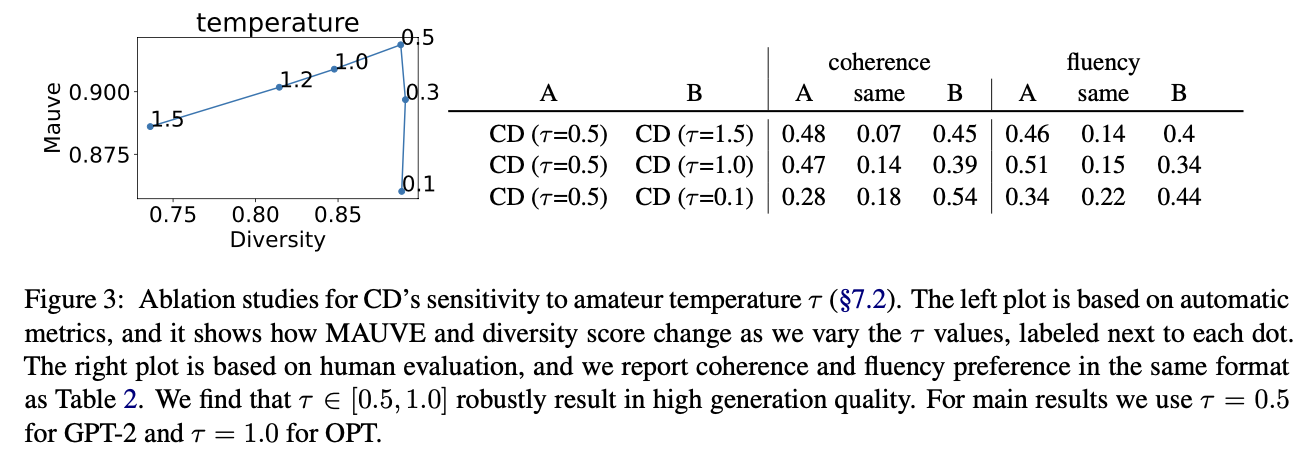
또한 에 대한 ablation test도 진행했는데, 가 0.5-1.5 사이에 있을 수록 Amateur LM이 spike한 distribution을 가지게 되면서 contrastive decoding의 성능을 극대화할 수 있다고 한다.
