A Simple Contrastive Learning Objective for Alleviating Neural Text Degeneration
nlp-paper-review
Introduction
Open-AI의 GPT3와 같은 모델들은 좋은 성능을 보이지만, 자연어 생성이라는 task 측면에서는 여전히 제한적인 성능을 보이고 있다.
그 이유는 LM의 목적함수가 training data의 true distribution과 model prediction이 완벽하게 일치하지 않으면 값이 커지는 cross entropy loss로 설계되어 있기 때문이다.
이에 따라 cross entropy를 최소화하도록 훈련된 LM들은 text degeneration problem에 노출되는데, token, phrase, sentence 단위의 중복 생성이 그 대표적인 현상이다. (대화나 요약 task에 fine-tuning한 후 실제 생성결과를 뜯어보면 이러한 현상을 빈번히 찾아볼 수 있다.)
본 눈문은 이러한 text degeneration problem을 해결하기 위한 방법론을 제시하기에 앞서 LM이 생성하는 단어를 3가지로 구분해 정리한다.
- Positive token (Label Token)
- Negative token (Incorrectly repeating Token, 이전 context에 존재했던 token)
- Irrelevant token (All other Token)
기존의 cross entropy가 non-label로 취급하는 token을 negative token과 irrelevant token으로 구분해서 정의한다고 보면 된다. Negative token의 경우 사실상 생성하는 t번째 token이전의 m개의 token들인데, 이는 LM이 같은 단어, 구, 문장을 계속해서 생성하는 경향을 없애기 위해 이렇게 정의한 것 같다. Irrelevant token은 말그대로 target token과 관련 없는 token들이다.
Backgrounds
제안하는 Contrastive token learning은 Cross Entropy와 Unlikelihood Training에 기반을 두고 있는데, 각 방법론을 비교하는 그림은 아래와 같다.
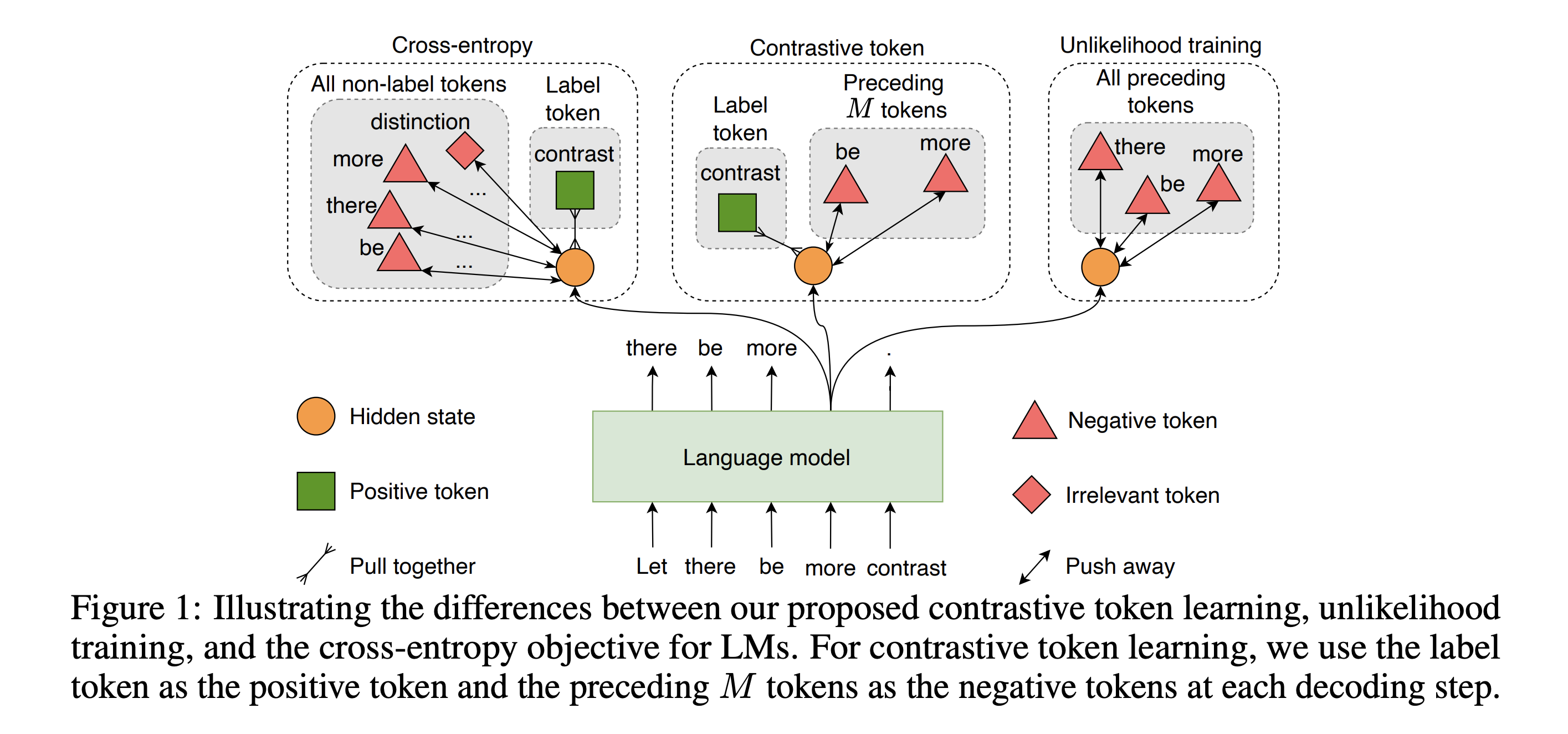
Cross Entropy
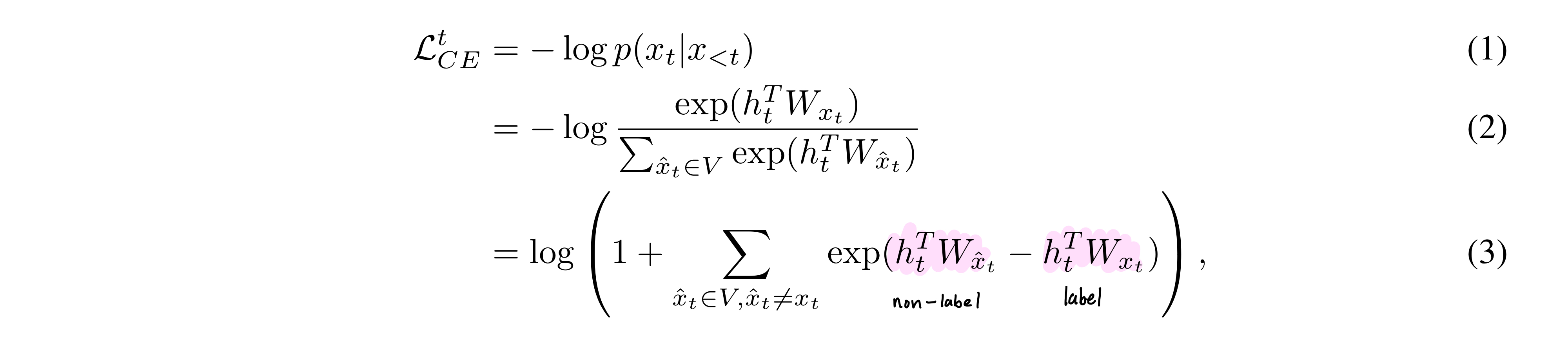
위와 같은 cross entropy 식은 (1) > (3)으로 변형될 수 있는데, cross entropy가 label token과 다른 모든 non-label token를 효율적으로 contrast하면서 학습되도록 설계되었음을 의미한다.
Unlikelihood Training
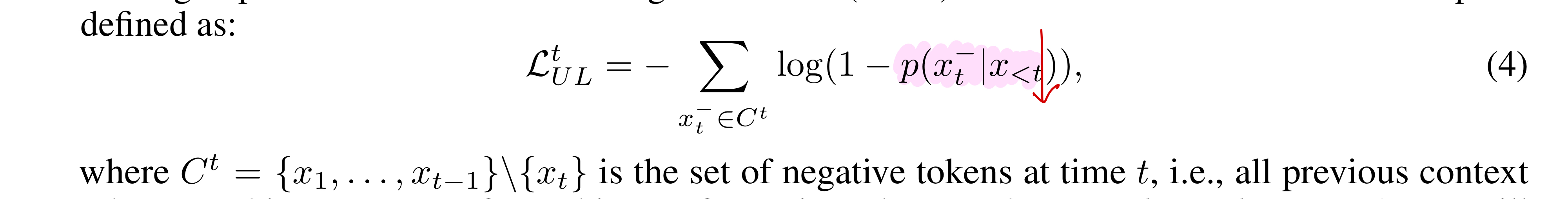
cross entropy의 repetition 문제를 해결하기 위해 2020년에 unlikelihood training이라는 방법론이 개발되었다. 이 방법론은 위의 수식에서 보이는 것처럼 negative token들에 대한 likelihood를 낮추는 식으로 설계된 후 가중합 형식으로 기존 CE에 더해져서 활용되었다. (위의 식은 t번째 이전의 모든 token들을 negative token이라고 치부했는데, 이를 보정하기 위해 원논문에서 t번째 이전의 k개의 token들을 prefix 형태로 negative token들로 취급하는 sequence-level unlikelihood objective 방법론을 제안했다.)
Discussions
위의 CE와 UT는 Repetition 문제를 완전히 해결하기에는 한계가 있다.
CT는 negative token과 irrelevant token을 동일하게 penalize한다는 점에서 제한적이다. 이는 실제 generate 시에 repetition 문제를 해결하기 어렵게 만든다. (따라서 negative token를 irrelavant token보다 더 hard하게 penalize해야 한다.)
UT는 (1) 한 negative token을 penalize하는 정도가 다른 negative token에 의해 결정되기 때문에 (negative token을 penalize하는데 있어서) 제한적이며 (2) 식 자체가 irrlevant token의 likelihood를 의도치 않게 높히도록 설계 되었다는 한계를 지니고 있다. (gradient analysis 참조)
Method
Contrastive token learning & Negative Token Selction
CE와 UT의 장점만을 가져오기 위해 저자들은 contrastive learning 기법을 차용했는데, 구체적인 내용은 다음과 같다.
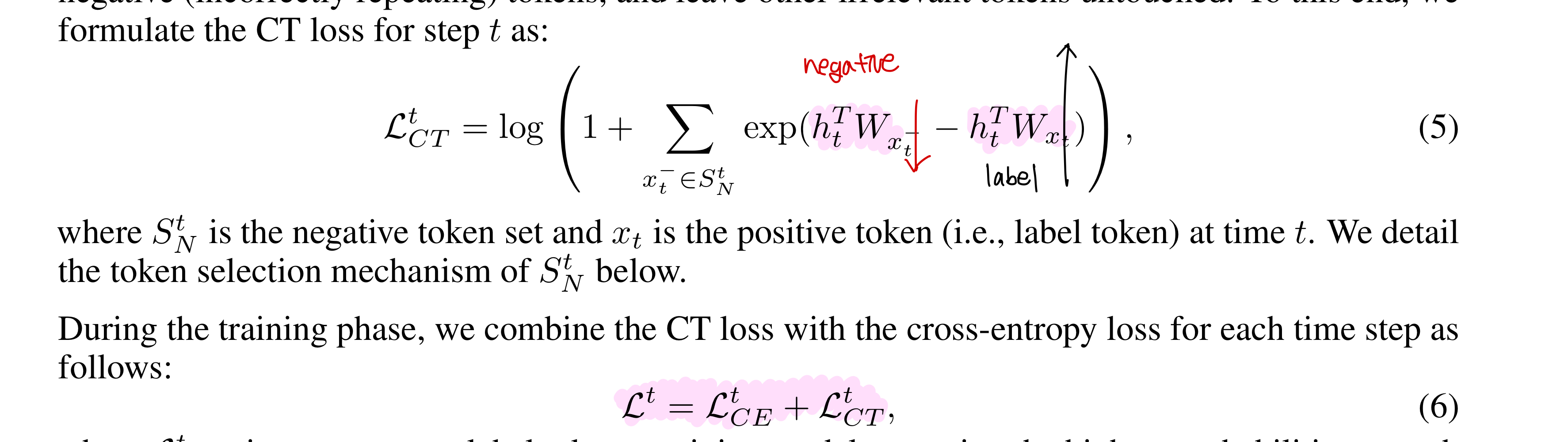
Unlikelihood learning과 달리 contrastive token learning은 매 time step마다 positive (i.e., label) token과 negative token과의 distance를 넓힐 수 있는 loss term을 추가하고 이를 CE와 더해 최종 loss식을 완성하였다. 저자들이 제안한 contrastive token learing 식은 irrelavant token에 영향을 주지 않기 때문에 기존 CE와 결합했을 시에 negative token들에만 더 강한 penalty를 줄 수 있다는 장점이 있다.
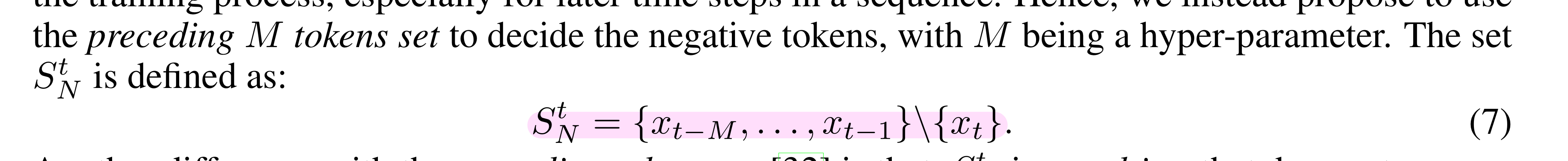
UT 저자들이 제안했던것처럼, 문장이 길어질수록 선행하는 모든 token을 negative token으로 활용하는 것은 noise를 증가시키기 때문에 앞의 M개의 token만을 매 time step의 negative token으로 설정하였다.
Gradient Analysis
저자들은 왜 contrastive token learning이 효과적으로 negative token의 likelihood를 낮출 수 있는지를 gradient analysis를 통해 분석하였다.
!! 분석하기에 앞서 헷갈리지 않게 기억할 것 !!
Minimize하는 Loss Function에 대한 Logit의 Gradient가 음수 : 해당 Logit의 한 단위 증가는 Loss 값을 감소시킨다
Cross Entropy

CE의 경우 positive token은 loss를 개선 (감소), irrelevant & negative token은 Loss를 억압한다.
Unlikelihood Training

UE의 경우 negative token은 loss를 개선시키는 것이 다른 negative token ()의 영향에 달려있다.

또한 위에서 보이는 것처럼 irrelevant token들은 loss를 감소시키면 안되는데 감소시키는 방향으로 gradient가 설정되어 있다.
Contrastive Token Learning

하지만 보이는 것처럼 contrastive token learning은 positive token (loss 감소)과 negative token(loss 증가)이 둘다 적절한 방향으로의 gradient를 가지고 있음을 알 수 있다.
Experimental Setup
Baselines
(i) The vanilla cross-entropy (CE) objective
(ii) decoding-based methods: banning 3-grams, top-k sampling, nucleus sampling, and contrastive search (SimCTG-CS);
and
(iii) learning-based methods: unlikelihood training, SimCTG, and noise-contrastive estimation
Model
GPT2-Small Fine-tuning
Dataset
Wikitext-103 (50K steps with 3K warm-up steps)
Evaluation Metrics
(i) ppl (ppl : 512 token | ppl-s : 50 tokens)
(ii) generative repetition (the number of repeated n-grams divided by the total number of generated n-grams in each sequence)
(iii) diversity (distinct 1-gram rates (dist-1) and unique 1-gram counts (uniq-1))
Evaluation Results
(논문에 decoding-based에 어떤 learning으로 fine-tuning 했는지 명확하게 나와있지 않아서 답답...)
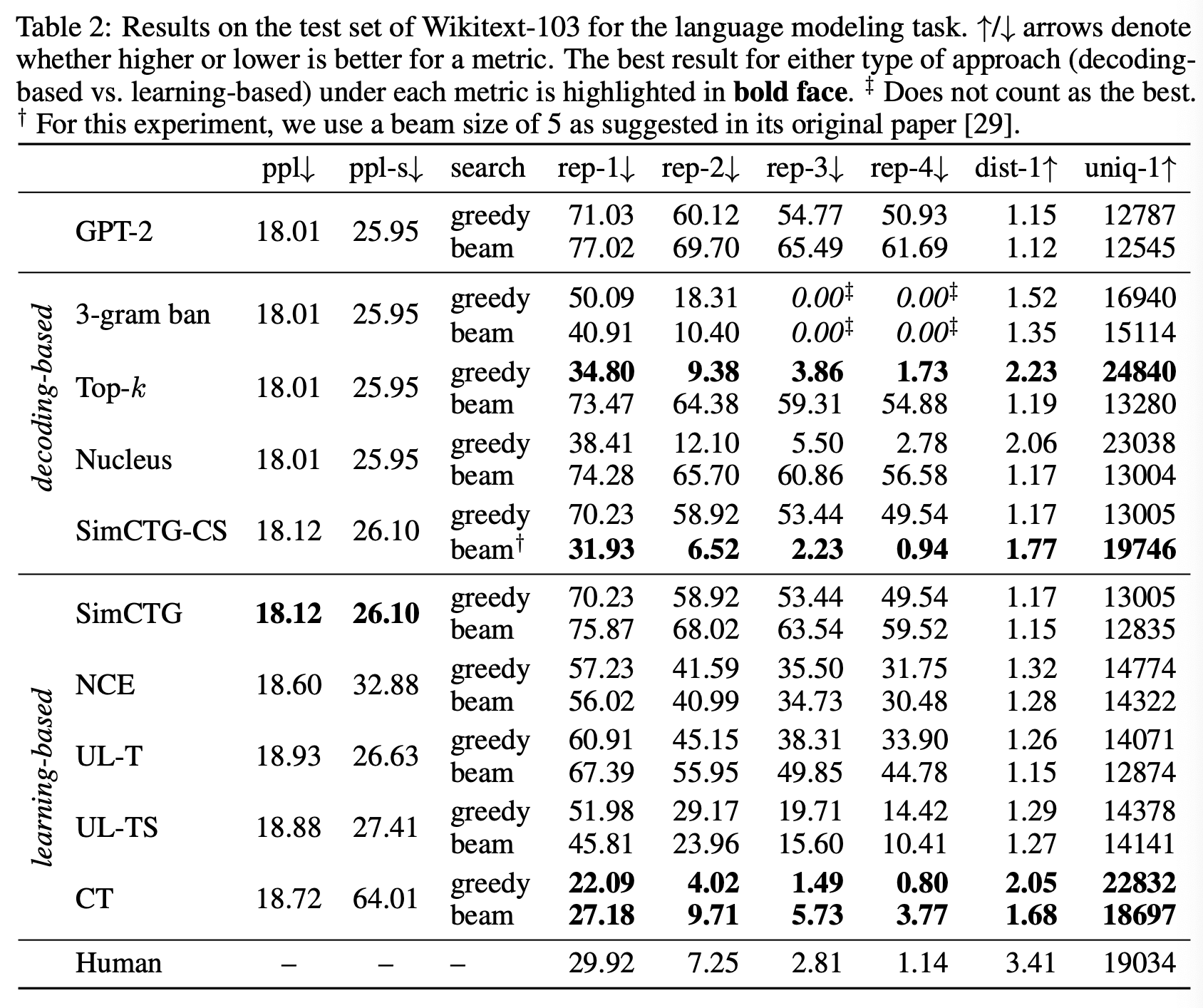
- CT compared to learning-based approaches
다른 learning method와 비교했을 시에 repetition rate가 개선되었음을 알 수 있다. 특히 NCE와 비교했을 때 CT는 positive token과 negative token이 직접적으로 상호작용하도록 (=contrast) 목적함수가 설계되어 있는데, 이게 repetition rate와 diversity 개선에 도움이 되었다고 주장한다. (아래 식을 보면 NCE는 CT와 달리 positive token과 negative token이 loss내에서 직접적으로 상호작용 X & gradient에 영향을 주는 방향은 같음)


- CT compared to learning-based approaches
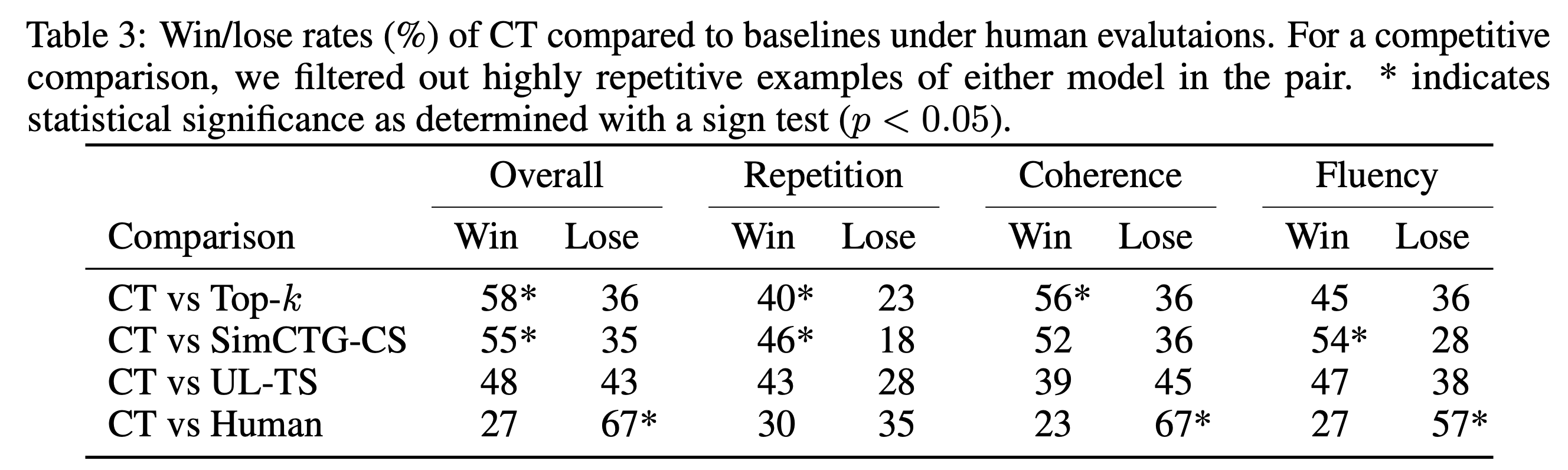
SimCTG-CS는 inference 단계에서 매 time step마다 previous token와의 거리를 (contrastive search) 고려해 새로운 token들을 생성하기 때문에 reptition rate가 개선되지만, 아래의 표에서 보이는 것처럼 coherence와 fluency 측면에서는 좋지 못한 성능을 보인다고 한다. (decoding 기법이 heuristic한 특성을 강화할수록 LM이 자연스러운 문장을 생성할 능력이 떨어진다.)
- Visualization analysis of the generation probability
각 방법론마다 inference시에 각 time step마다 positive, negative token에 얼만큼의 확률값을 부여하는 지를 시각화를 통해 비교하였다.
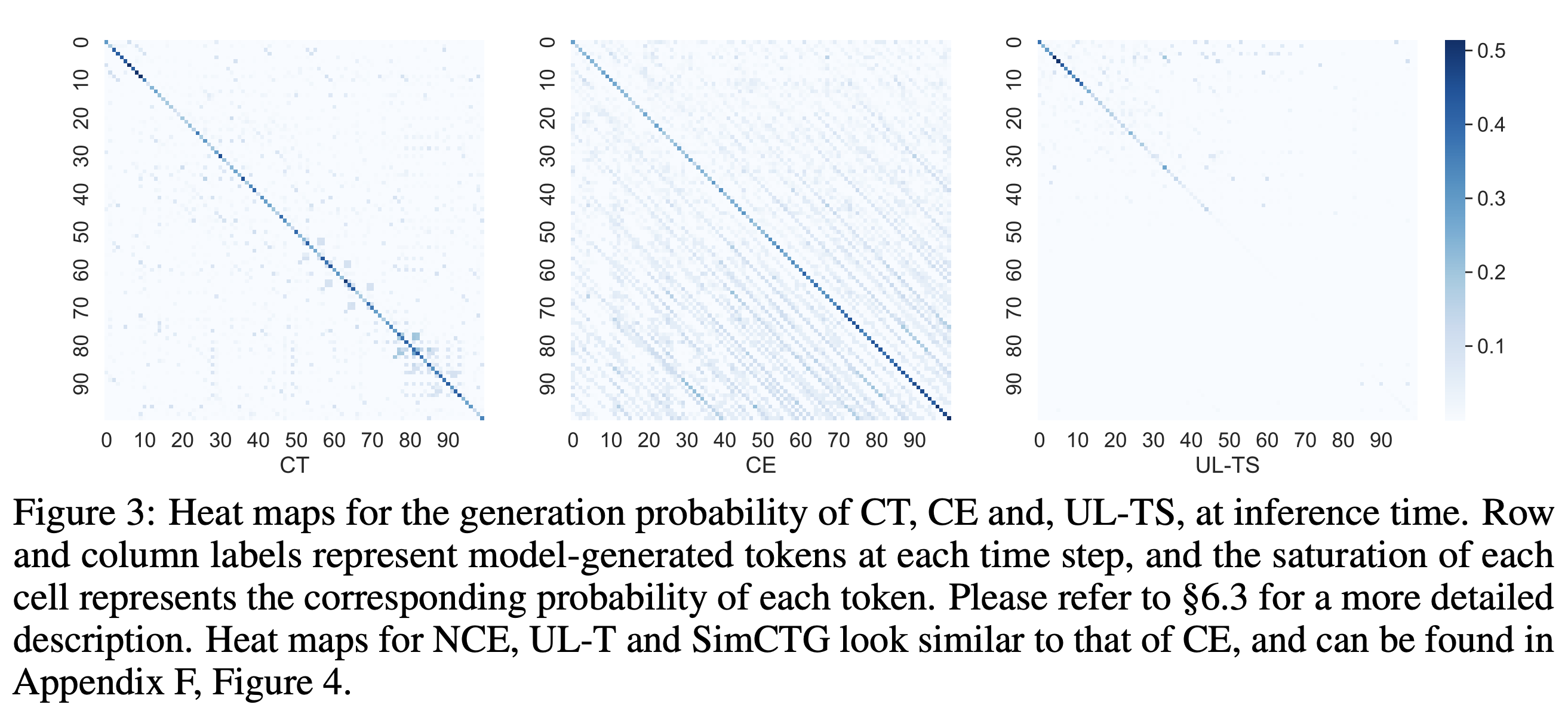
row & col은 time step을 의미하며, 색의 진하기는 확률을 의미한다. CE의 경우 주대각선 이외의 줄무늬도 많이 관측되는데 이는 reptition이 관측될 확률이 그만큼 높다는 것을 의미한다. 또한, 하단부로 갈수록 색이 진해지는 것을 확인할 수 있는데, 이는 생성의 후반부에 갈수록 앞쪽 context에 대한 의존성이 강화되면서 reptition bias가 심화되는 것을 관측할 수 있다. UL-TS는 time step이 조금만 길어져도 positive token에 대한 예측조차 불확실해진다는 것을 알 수 있다.
