Prefix Truning, P-Tuning과 마찬가지로 'Prompt'에만 gradient를 흘려 PLM을 efficient하게 update하는 method를 제안한 paper.
Adapter계열 논문이라고 봐도 무방하나,들은 adapter 계열들은
에서 자체를 건드는 method이지만 Prompt tuning은 task마다 prompt를 update하기 때문에 를 update하는 method이라고 소개한다.
1. Introduction
PLM을 활용해 dowmnstream을 해결하는 방법은 크게 2가지가 있다.
- Fine-Tuning: model parameter 전체를 downstream에 맞게 update 시키는 것 > 본 논문에서는 Model Tuning이라고 명명
- Prompting: model parameter freeze한 후 task desecription과 demonstration으로 task를 푸는 것 (few-shot learning) > 본 논문에서는 Prompt Design이라고 명명
Prompting이 가지고 있는 장점이 명확하지만 가지고 있는 단점 또한 명확하다.
1. task description에 error prone하다.
2. demonstration들 수에 의해서 prompt의 효용성이 달려있다. (=zero shot이 여전히 좋지는 않음)
따라서 여전히 특정 task에 대한 성능은 Prompting이 (굉장히 큰 모델사이즈(175B GPT3)를 가지고 있음에도) Fine-tuning을 따라잡지 못하고 있다.
하지만 Prompt라는 것 자체가 text임으로 discrete하기 때문에 backpropagation으로 optimization할 수 있는 대상도 아니다.
이를 해결하기 위해 'Prefix-Tuning: Optimizing Continuous Prompts for Generation'라는 논문이 'prefix를 adapter 형식을 차용해 parameterized 했다면 본 논문은 보다 범용적인 'Prompt'를 parameterized했다고 보면 될 것 같다.
2. Prompt Tuning
Prompt Tuning 방법론은 굉장히 간단한다.
모델 parameter 는 freeze하고 prompt parameter 만을 모델에 추가한 후 update하는 것이다.
- Input :
- Prompt :
모델은 를 입력으로 받게 되고 를 maximize하게 training되면서 만을 update하는 형식이 된다.
논문에서 언급된 부분은 이게 끝이다. (결국 코드를 까봐야 한다,,)
Transformer구조에서 에 해당되는 부분이 굉장히 많은데 결론적으로 말하면 Prompt Tuning이 업데이트 하는 부분은 word embedding layer이다.
정리를 하면 PLM은 freeze한채로 특정 task에 대응되는 prompt word embedding layer를 각 task마다 fine tuning해서 쓰자!가 Prompt tuning의 주요 contribution이다. (실제로 T5-XXL를 정교하게 prompt tuning 하면 성능이 좋음)
Downstream task마다 Prompt Embedding을 Fine-tuning해야되는 것을 알았으니 이제 결정할 것은 Prompt Design이다.
- Prompt Embedding Intialization
- Random Initilziation
- PLM most common voab embedding에서 sampling하기
- downstream task의 class label의 string에 대응되는 embedding 가져오기 (prompt의 길이가 길 경우 2번째 방법에서 나머지 길이 채우기)
- Prompt의 길이
- P가 parameter 사이즈랑 직결됨으로 작게하면서도 성능이 좋게하는걸 목표로 했다고 함
(개인적으로는 LM에게 task specific한 정보를 줄 정도의 길이는 되어야하지 않을까라고는 생각합니다. 실제로 실험결과를 봐도 20token정도면 model size에 상관 없이 어느정도 안정적인 결과를 가져오는 것을 볼 수 있습니다)
Huggingface PEFT 구현
@dataclass
class PromptTuningConfig(PromptLearningConfig):
"""
This is the configuration class to store the configuration of a [`~peft.PromptEmbedding`].
Args:
prompt_tuning_init (Union[[`PromptTuningInit`], `str`]): The initialization of the prompt embedding.
prompt_tuning_init_text ( Optional[`str`]): The text to initialize the prompt embedding.
Only used if `prompt_tuning_init` is `TEXT`
tokenizer_name_or_path ( Optional[`str`]): The name or path of the tokenizer.
Only used if `prompt_tuning_init` is `TEXT`
"""
prompt_tuning_init: Union[PromptTuningInit, str] = field(
default=PromptTuningInit.RANDOM,
metadata={"help": "How to initialize the prompt tuning parameters"},
)
prompt_tuning_init_text: Optional[str] = field(
default=None,
metadata={
"help": "The text to use for prompt tuning initialization. Only used if prompt_tuning_init is `TEXT`"
},
)
tokenizer_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": "The tokenizer to use for prompt tuning initialization. Only used if prompt_tuning_init is `TEXT`"
},
)
def __post_init__(self):
self.peft_type = PeftType.huggingface에서는 prompt_tuning_init이 Prompt Embedding Intialization하는 방법이고
- prompt_tuning_init.RANDOM : random initialization
- prompt_tuning_init.TEXT: task instruction으로 구성된 PLM의 token vocab embedding으로 initialize하는 방법이다. (e.g., Predict if sentiment of this review is positive, negative or neutral"가 task instruction이면 tokenzier가 tokenize한 후 PLM embedding layer를 copy떠서 prompt encoder로 활용함)
downstream task의 class string representation 별로 embedding copy 떠오는 건 아쉽게도 huggingface도 구현이 쉽지 않았나 보다.
class PromptEmbedding(torch.nn.Module):
"""
The model to encode virtual tokens into prompt embeddings.
Args:
config ([`PromptTuningConfig`]): The configuration of the prompt embedding.
word_embeddings (`torch.nn.Module`): The word embeddings of the base transformer model.
**Attributes**:
**embedding** (`torch.nn.Embedding`) -- The embedding layer of the prompt embedding.
Example::
>>> from peft import PromptEmbedding, PromptTuningConfig >>> config = PromptTuningConfig(
peft_type="PROMPT_TUNING", task_type="SEQ_2_SEQ_LM", num_virtual_tokens=20, token_dim=768,
num_transformer_submodules=1, num_attention_heads=12, num_layers=12, prompt_tuning_init="TEXT",
prompt_tuning_init_text="Predict if sentiment of this review is positive, negative or neutral",
tokenizer_name_or_path="t5-base",
)
>>> # t5_model.shared is the word embeddings of the base model >>> prompt_embedding = PromptEmbedding(config,
t5_model.shared)
Input Shape: (batch_size, total_virtual_tokens)
Output Shape: (batch_size, total_virtual_tokens, token_dim)
"""
def __init__(self, config, word_embeddings):
super().__init__()
total_virtual_tokens = config.num_virtual_tokens * config.num_transformer_submodules
self.embedding = torch.nn.Embedding(total_virtual_tokens, config.token_dim)
if config.prompt_tuning_init == PromptTuningInit.TEXT:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(config.tokenizer_name_or_path)
init_text = config.prompt_tuning_init_text
init_token_ids = tokenizer(init_text)["input_ids"]
# Trim or iterate until num_text_tokens matches total_virtual_tokens
num_text_tokens = len(init_token_ids)
if num_text_tokens > total_virtual_tokens:
init_token_ids = init_token_ids[:total_virtual_tokens]
elif num_text_tokens < total_virtual_tokens:
num_reps = math.ceil(total_virtual_tokens / num_text_tokens)
init_token_ids = init_token_ids * num_reps
init_token_ids = init_token_ids[:total_virtual_tokens]
word_embedding_weights = word_embeddings(torch.LongTensor(init_token_ids)).detach().clone()
word_embedding_weights = word_embedding_weights.to(torch.float32)
self.embedding.weight = torch.nn.Parameter(word_embedding_weights)
def forward(self, indices):
# Just get embeddings
prompt_embeddings = self.embedding(indices)
return prompt_embeddings- num_virtual_tokens: 위에서 설명한 Prompt의 길이라고 보면 되겠다. prompt_tuning_init.RANDOM할 경우에는 이 길이만큼 embedding을 생성해주고, prompt_tuning_init.TEXT할 경우에는 task description만큼 그 길이만큼 truncation하거나 반복생성해서 입력으로 넣어준다.
PEFT main model code를 까보면 Model forwarding을 할때는 임의의 prompt token index를 arrange함수를 만들어줘서 (e.g.,[0,,,20]) 위에코드로 생성한 prompt embedding을 매번 forwarding 시켜준다고 보면 된다.
3. Unlearning Span Corruption
T5의 Pre-training MLM
- Input: Thank you 〈X〉 me to your party 〈Y〉 week
- Output: 〈X〉 for inviting 〈Y〉 last 〈Z〉
T5를 full fine-tuning하면 pre-train에서 본 sentinel의 영향으로부터 자유로울 수 있지만 prompt tuning은 제한적이기 때문에 3가지 unlearning span corruption 기법을 제안했다.
- Span corruption: unlearning하지 않고 prompt tuning
- Span corruption + Sentinel : Sentinel 붙혀서 prompt tuning
- LM Adaption: prefix주고 natural text continuation 생성하는 식으로 100K step LM화 allevation 시킴
4. Experimental Results
Main Results
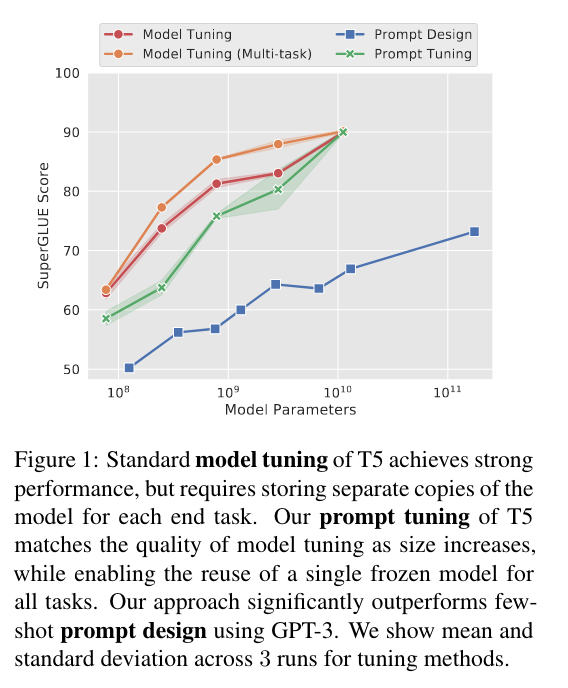
(model tuning = fine tuning (각 down stream task 마다 독립적으로 모델 fine tuning) / model tuning (multi-task) (1개 모델을 여러개 task에 대해서 multi-task fine-tuning) / Prompt Design = GPT3 / Prompt Tuning = 30,000 steps, learning rate =0.3 & batch size=32)
- T5-XXLarge까지 키우면 Prompt-Tuning만으로 Full fine-tuning 이길 수 있다.
Ablation Study
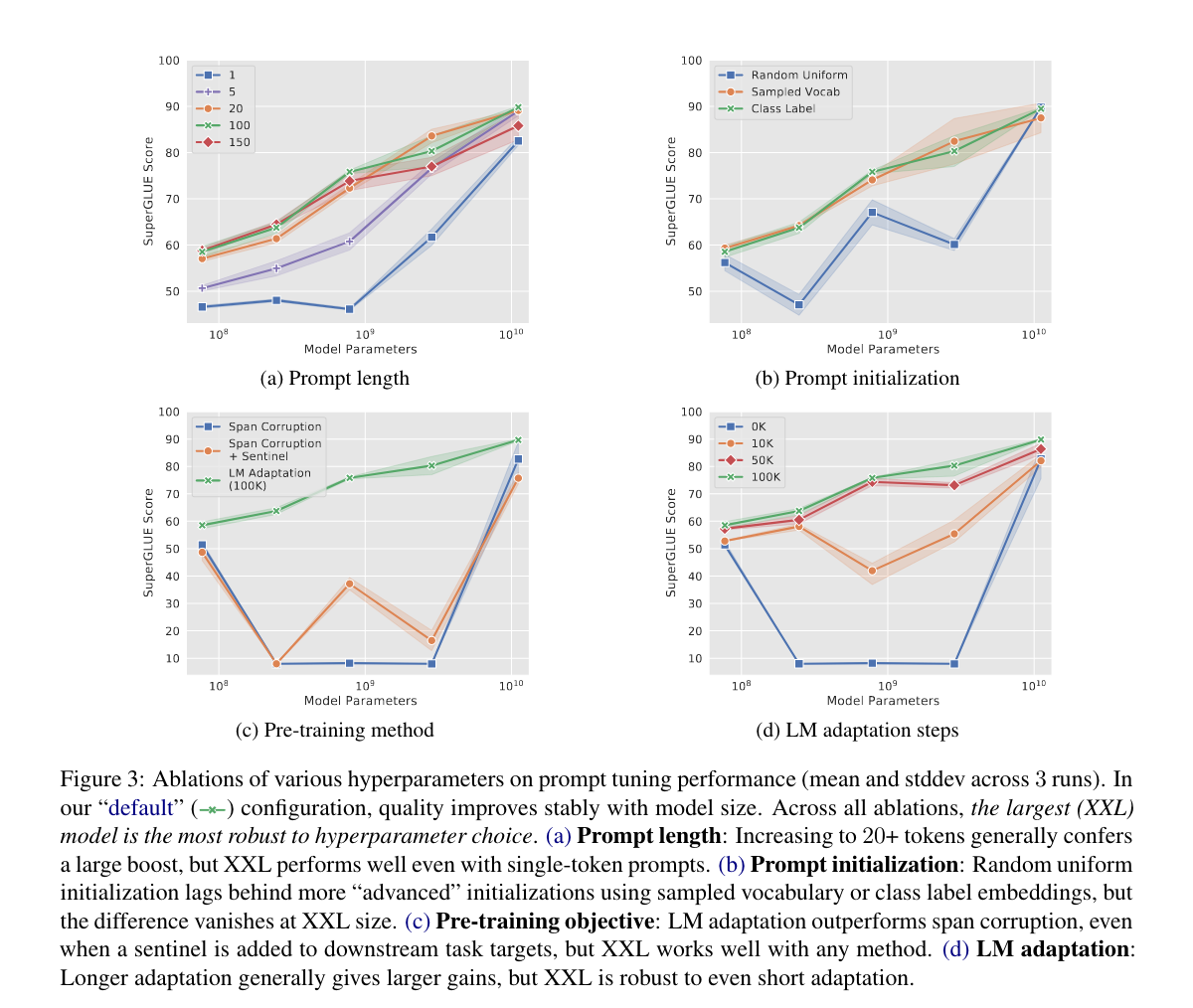
- Prompt Length
* XXL size는 1token prompt만 사용해도 충분하다- 일반적으로 20token prompt embedding이면 성능을 뽑아낼 수 있다.
- Prompt Initializtion
* XXL size 쓰지 않을꺼면 random initialize는 쓰지 말자 - Pre-training method
* XXL size 쓰지 않을꺼면 LM 100까지는 Lm adaptation을 해줘야 한다.- 100k step까지는 해줘야 small size모델에서 T5가 prompt tuning에서 안정적으로 성능을 뽑아낼 수 있다.
Resilinece to Domain shift
Prompt Embedding만 Tuning하는 것의 가장 큰 장점은 PLM weight 자체는 freeze 되어 있기 때문에 가 변형되지 않아 domain shift에 robust하다는 것이다.
이를 증명하기 위해 저자들은 QA와 Paraphrase detection task에서 Prompt Tuning이 Fine tuning보다 domian shift에 강건하다는 것을 보였다.
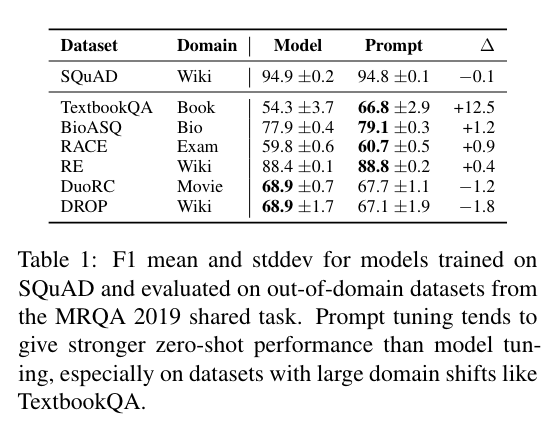
(SQuAD로 Tuning후에 out of domain MRQA dataset으로 evaluate)
- DROP <> wiki처럼 domain sharing 비율이 크지 않은 경우를 제외하면 prompt tuning이 domain shift에서 강건함
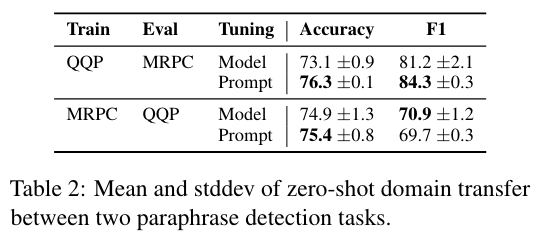
- paraphrase task에서도 비슷한 경향성을 보임
fine-tuning을 하긴 해야되는데 했을 때 발생하는 model weight distribution shift risk를 prompt에 전이시키는 것으로 보인다.
