FLAN은 'LM을 많은 데이터셋에 대해서 instruction 기반으로 finetuning하면 unseen task에 대해서 ZERO SHOT 성능을 향상시킬 수 있다.'를 실험적으로 보여준 논문이다.
Introduction
저자들은 GPT-3와 같은 LLM의 zero shot 성능이 좋지 않은 이유를 demonstration이 없는 환경에서 모델이 pretraining data와 유사하지 않은 prompt를 해석해야 했기 때문이라고 지적한다.
FLAN은 모델에게 올바른 'instruct'을 지속적으로 해석하도록 학습한다면 저자들은 unseen task 상황에서도 zero shot performance가 향상될 수 있음을 보여준다.
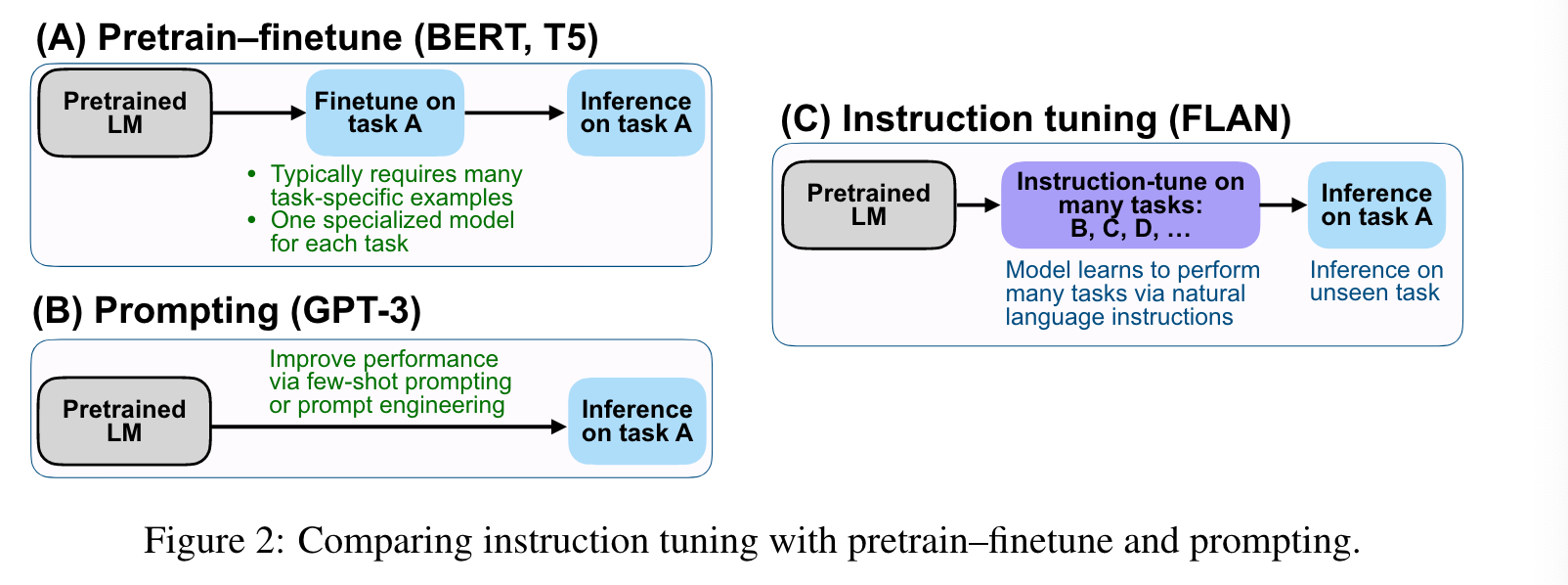
'intstruct tuning'은 'instruction' 형식으로 LM을 fine-tuning하는 것이다. 위의 그림에서 보는 것처럼 해당 method의 가장 큰 장점은 pre-training fine-tuning과 prompting의
이점을 동시에 누릴 수 있다는 점이다.
Google은 137B LaMDA에 'instruct tuning'을 했는데 결론적으로 175B GPT3에 비해서 zero shot 성능은 당연하고 일부 few shot에서도 좋은 성능을 보였다.
2. FLAN: INSTRUCTION TUNING IMPROVES ZERO-SHOT LEARNING
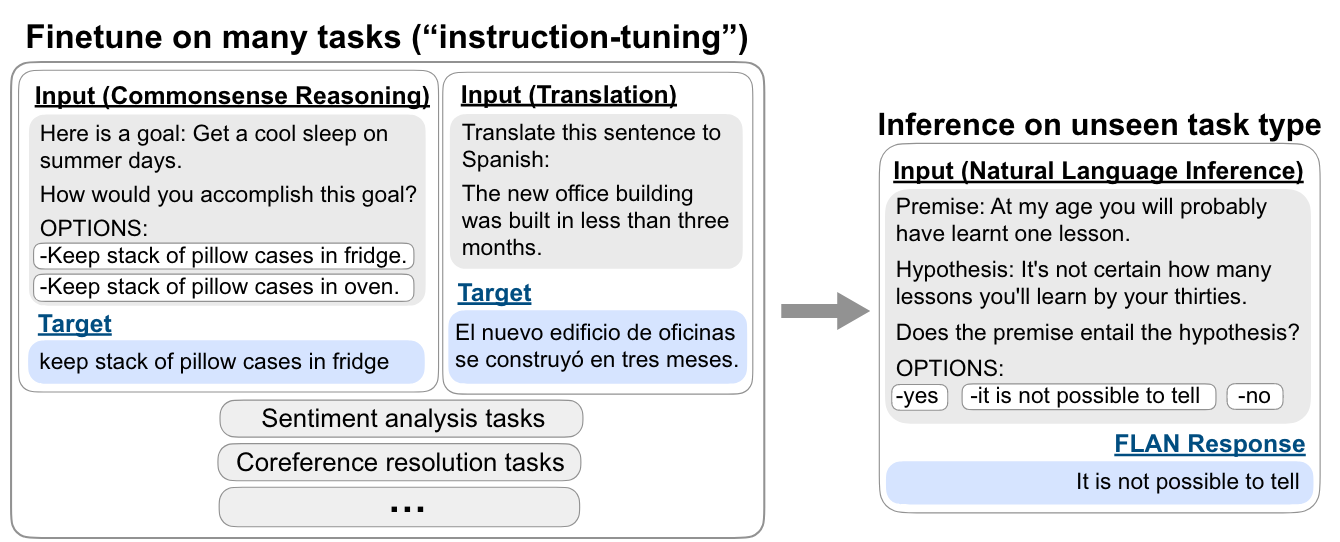
'instruct tuning'의 motivation'은 간단하다. 자연어 형식으로 LM을 supervised training한다면 unseen task에 대해서도 instruct 형식으로만 준다면 충분히 풀 수 있다는 것이다. (일종의 자연어 task protocol을 모델에게 심어주려는 행위)
- 저자들은 62개의 text datasets을 12개의 task cluster로 분류했다.
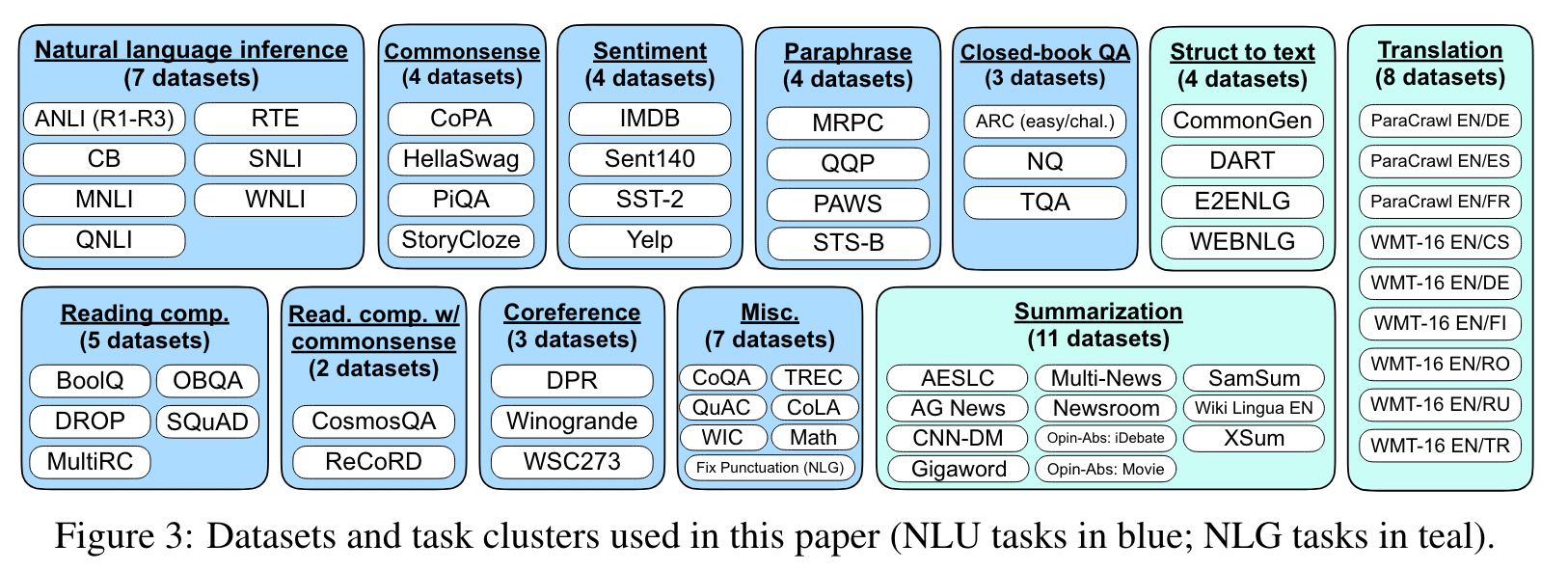
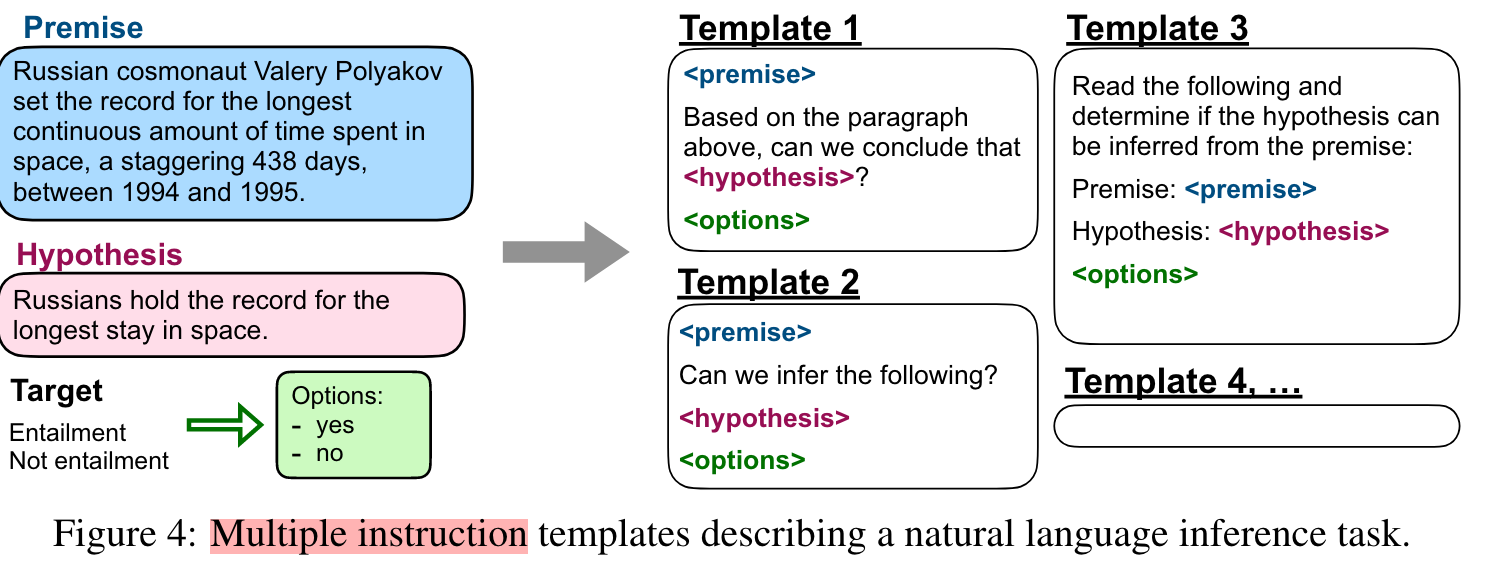
- dataset마다 다양성을 위해 10개의 templates을 적용해서 자연어 instruction을 만들었다.
-
Evaluation의 경우 굉장히 보수적으로 진행했다고 주장한다. 저자들의 말을 빌리면, 위의 dataset cluster 예시에서 read. comp. with commonsense cluster에 대해서 evaluation할 때 read. comp.과 commonsense reasoning instruct tuning에서 제외했다고 한다.
-
instruction 형식으로 모든 task를 해결할 경우 classification에서 문제가 생길 수 있다.
("yes" / "no" 경우 학습과정에서 LM이 정확히 저 두 토큰의 logit만 높힌다는 보장이 없다) 이를 해결하기 위해 GPT3에서는 "yes" / "no" 중 확률이 높은 대답을 예측값으로 활용했는데 보다 더 instruct의 활용을 극대화하기 위해 FLAN은 접미사+토큰 활용한 아래의 방법을 활용해 자연어 대답을 생성해 분류문제를 해결한다.
-
Pretraning Model은 LaMDA를 활용했다.
-
Training detail: dataset마다 크기를 맞춰주기 휘해 training size를 30k로 맞춰주었다. (input and target sequence lengths used in finetuning are 1024 and 256, respectively.)
3. Results
이전에 언급했던것처럼 evaluation은 held-out cluser들로 이루어졌다.
Baseline은 GPT-3 175B, GLaM 64B/64E, LaMDA-PT (LaMDA의 pre-training 버전으로 GPT3의 prompt 활용했다고 함)을 사용했다.
결과적으로 GPT-3 175B보다 zero-shot은 20/25개 few-shot은 10/25개 우위를 GLaM 64B보다 zero-shot은 13/19개 one-shot은 11/19개 우위에 있는 결과를 거두었다고 한다.
특히 instruction이 효과가 있었던 데이터셋은 'NLI, QA, translation, struct-to-text'었고 'commonsense reasoning and coreference resolution tasks that are formatted as finishing an incomplete sentence or paragraph'처럼 이미 language modeling로 형식화되어있는 task에서는 큰 효과가 없었다고 한다.
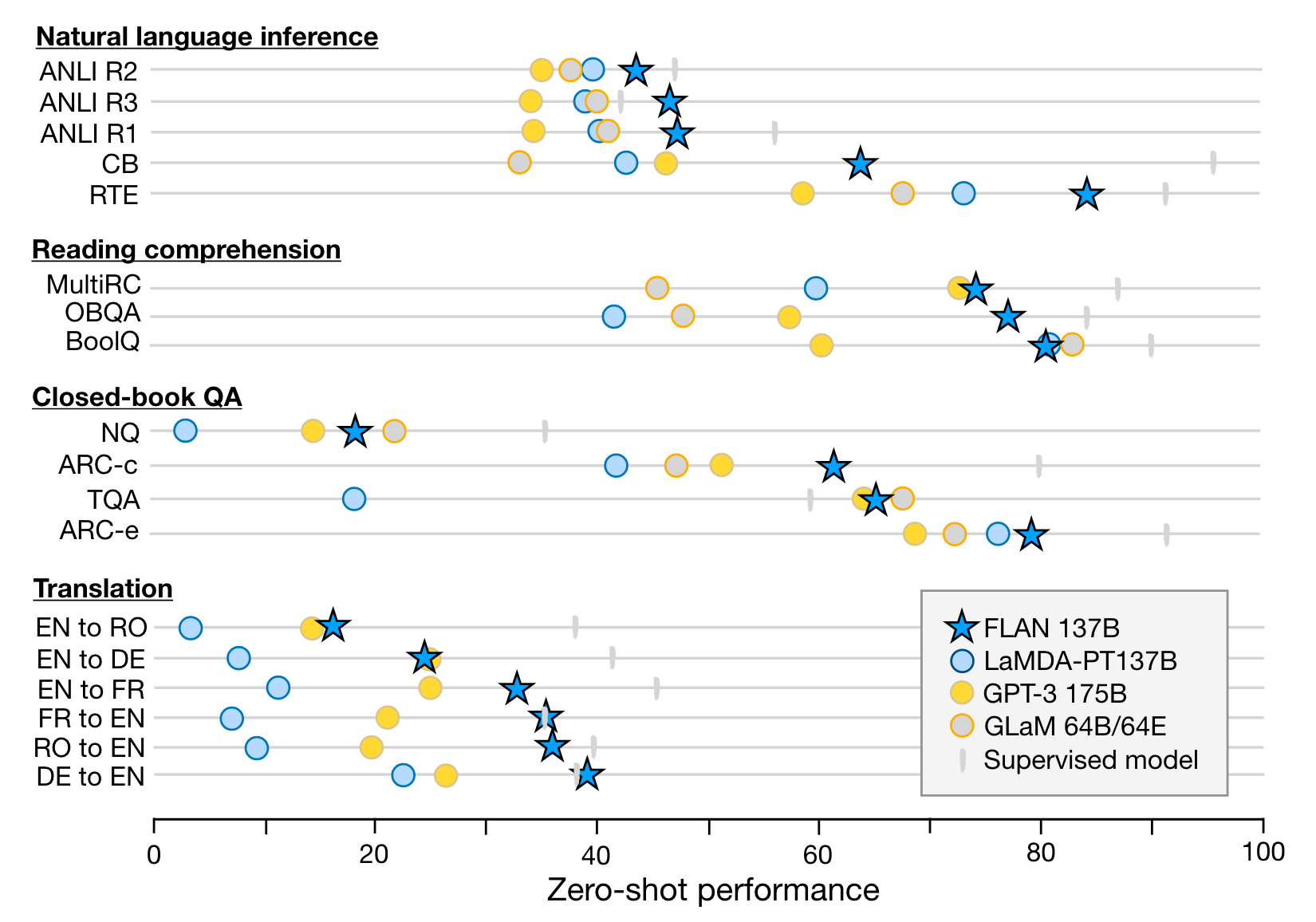
FLAN은 7개의 task (commonsense reasoning and coreference resolution tasks) 중 3개에서만 LaMDA-PT의 성능을 넘었다고 한다. 저자들은 그 이유가 pre-raining과 fine-tuning 목적함수가 redunant하게 overlap되는 부분이 많은게 성능에 도움이 되지 않는다고 주장한다.
4. ABLATION STUDIES & FURTHER ANALYSIS
4.1. NUMBER OF INSTRUCTION TUNING CLUSTERS
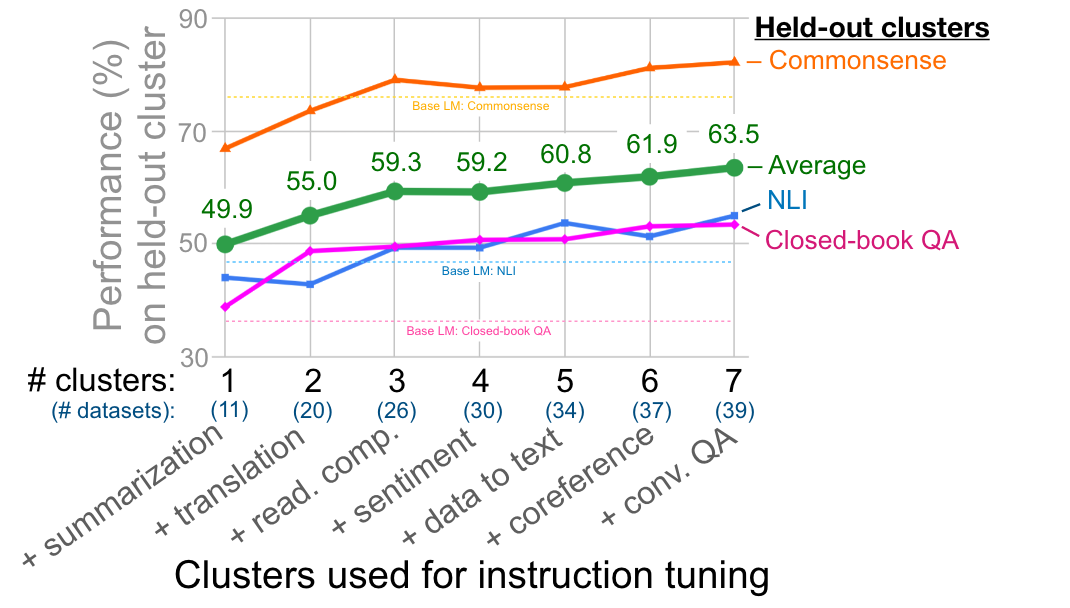
상호 베타적인 cluster로 instruct tuning 할수록 UNSEEN TASK에 대해서 ZERO SHOT 성능이 향상된다.
4.2 SCALING LAWS
이전과 동일하게 NLI, closed-book QA, and commonsense reasoning을 held out set으로 두고 scaling law에 대한 실험을 돌린 결과는 아래와 같다.
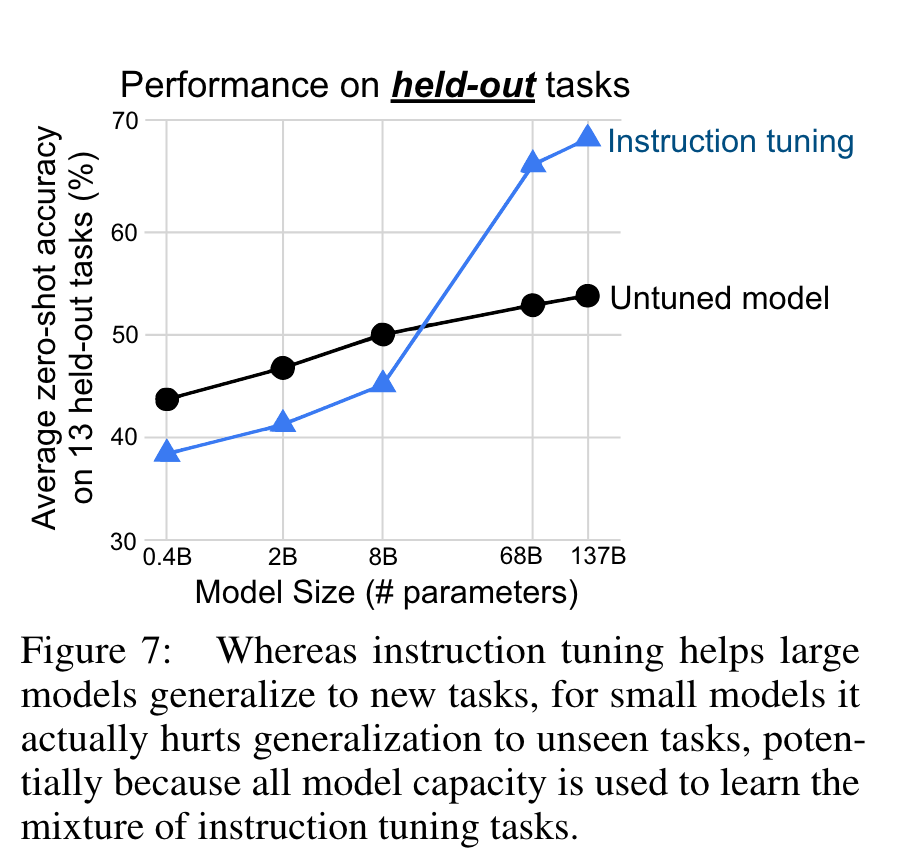
모델 사이즈가 8B이상 커져야 instruction tuning이 유효해지는데, 저자들은 이를 두고 ~40 task 이상의 instructions을 학습하기에 그 충분한 capacity가 필요하지 않았나라고 주장한다.
4.3 ROLE OF INSTRUCTIONS
저자들은 모델이 multi-task 학습능력이 아닌 instruct 해석능력 때문에 성능이 좋아진 것을 보여주기 위해 instruction을 제외한 실험도 보여주었다.
실험세팅은 2가지이다.
(1) no template setup (e.g., for translation the input would be “The dog runs.” and the output would be “Le chien court.”)
(2) dataset name setup (e.g., for translation to French, the input would be “[Translation: WMT’14 to French] The dog runs.”).

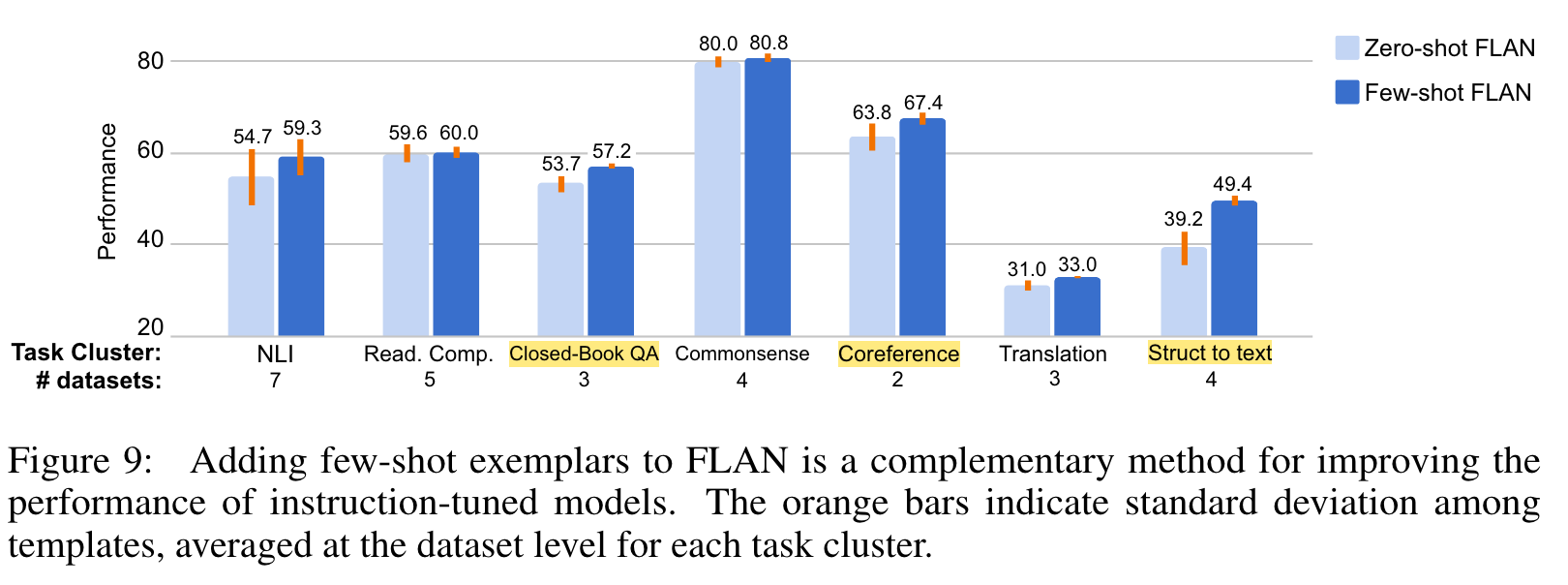
4.4 INSTRUCTIONS WITH FEW-SHOT EXEMPLARS
16개의 demonstration을 붙혀 few-shot setting에서의 실험을 돌렸는데 struct to text, translation, and closed-book QA처럼 large complex output space를 가진 task에서 성능이 향상되었고 few shot이 전반적으로 (당연히) std를 줄여주었다고 한다.
Google은 instruct learning을 통해 LM의 범용적인 활용도를 극대화하고 싶어하는 것 같다.
