Abstract

AlextNet은 ImageNet을 기반으로 학습된 모델입니다.
모델은 Test Data에서 최저 오류율 17.0%를 기록했고, 60million parameter와 650,000neurons를 갖습니다.
모델의 Feature Extractor에 layer수는 5개이고, MaxPooling도 있다고 합니다.
Fully Connected Layer에는 layer수는 3개이고, 1000개의 class들을 분류하는데 activation으로 softmax를 사용했습니다.
빨간색으로 밑줄 친 non-saturating neurons는 activation function으로 ReLu를 썼기 때문에 학습속도가 더 빨라졌다고 말하고 있습니다.
그리고 GPU를 활용해 Convolution연산을 했다고 하는데, 2개의 GPU로 Convolution연산을 합니다.
또한 Fully Connected Layer에 Parameter수가 많기 때문에 overfitting이 날 확률이 높아, dropout을 썻다고 합니다.
The Dataset
 Alexnet은 앞서 말씀드렸다시피 ImageNet을 기반으로 학습을 합니다. 1000개의 categories들로 이루어져있고 120만개의 훈련 데이터, 50,000개의 검증 데이터, 150,000개의 테스트 데이터를 통해 모델을 검증했다고 합니다.
Alexnet은 앞서 말씀드렸다시피 ImageNet을 기반으로 학습을 합니다. 1000개의 categories들로 이루어져있고 120만개의 훈련 데이터, 50,000개의 검증 데이터, 150,000개의 테스트 데이터를 통해 모델을 검증했다고 합니다.
ImagNet의 해상도는 모두 다르기 때문에 이미지의 크기를 256 * 256으로 다운샘플링 작업을 해주었습니다. 다운 샘플링을 하게 되면 이미지를 작게 하기 때문에 이미지 1개당 메모리를 차지 하는 양이 작아지고, 계산의 효율성이 증가합니다. 하지만 다운 샘플링 자체만으로 이미지의 픽셀 값을 줄이기 때문에 정보 손실을 유발합니다.
또한 Convolution net이 정해진 크기의 이미지만 받을 수 있기 때문에 다운 샘플링을 해주었습니다.
다운샘플링 하는 작업은 먼저 짧은 쪽을 먼저 256의 크기로 맞추고, 그 다음 256 * 256으로 이미지를 중심으로 crop하였다고 합니다.
이미지를 중심으로 crop하면 Invariance를 강화합니다.
객체 인식은 이미지내에 특정 객체나 패턴이 있을때 어느 위치에 있더라도 인식이 가능하게 하는 것이 목표입니다.
만약 Center Crop을 하면 Model은 객체나 패턴의 위치에 덜 민감해지기 때문에 모델의 일반화 능력을 향상시킬 수 있습니다. 일반화 능력은 모델이 추론을 수행하는 능력을 말합니다.
그리고 전처리 작업으로 훈련 데이터 셋에 평균값을 각 픽셀에 빼줌으로써 Normalization을 해주었다고 합니다.
이미지를 Normalization을 해준다면 이미지들은 작은 값 범위를 가지게 됩니다. 여기서 가중치를 갱신해주는 과정에서 Gradient값들의 크기도 상대적으로 작은 범위에서 일어나게 됩니다.
따라서, 정규화된 이미지를 사용하면 입력 데이터의 범위가 조정되어 가중치 값들이 더 일관된 범위에서 업데이트 되고, 학습속도도 더 빨라집니다.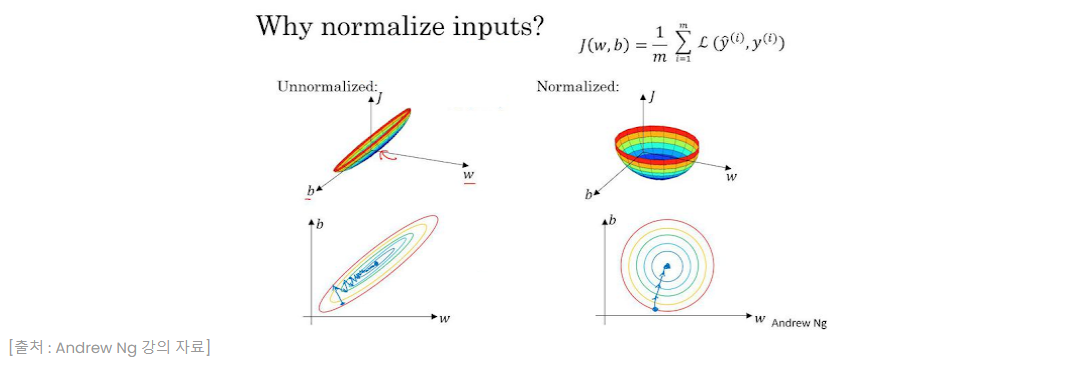
위 그래프에서 정규화 된 입력피처들의 손실함수가 더 빠르게 수렴하는 속도를 보이는것을 알 수 있습니다.
The Architecture
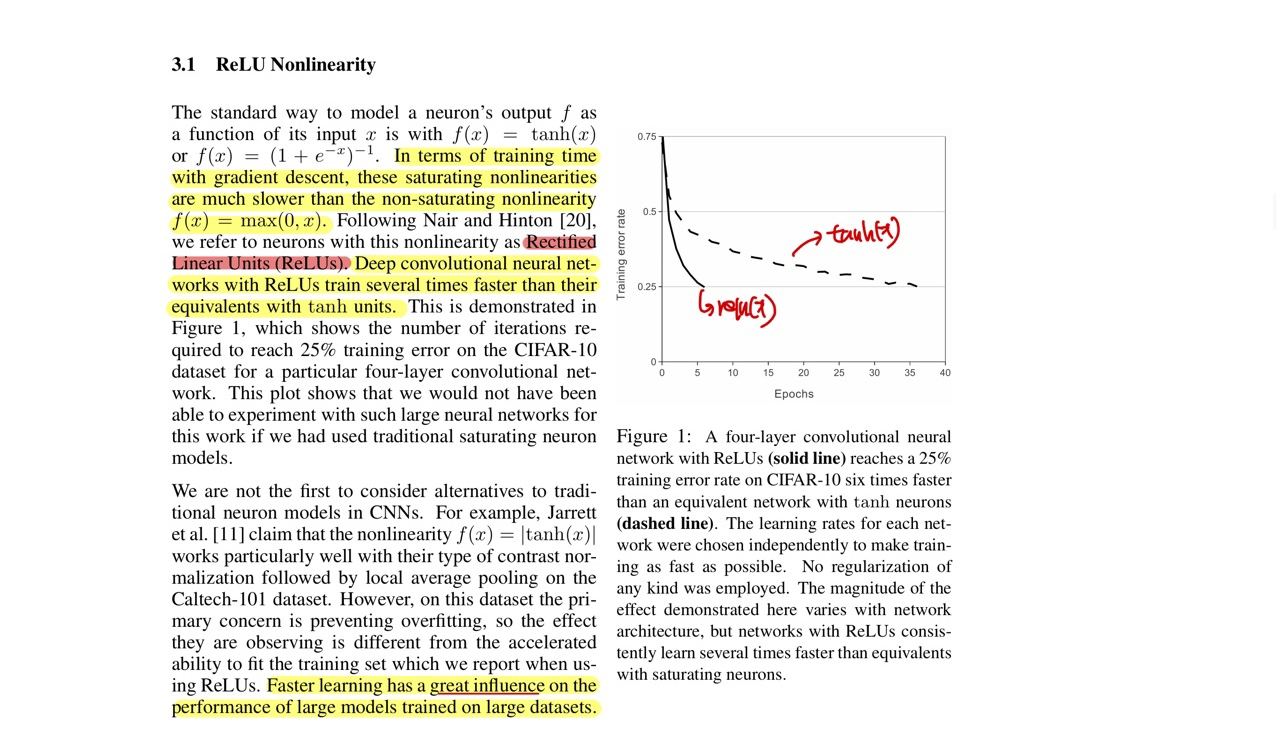
AlexNet은 ReLu 함수를 Activation Function으로 썻다고 합니다.
기존에 Sigmoid와 tanh함수를 쓰지 않고 ReLu를 쓰면서 tanh보다 몇 배는 더 빠르다는 결과가 있다고 합니다.
Figure 1에서 CIFAR-10이미지를 4개의 Convolution neural network로 학습하였더니 tanh보다 ReLu함수가 25%더 빠른 훈련속도를 보여주고 그 속도에 맞게 오류도 더 빠르게 감소한다는 것을 알 수 있습니다.(Learning Rate는 학습 속도가 가능한 빨리 수행할 수 있게끔, 값이 설정 되었다고 합니다.)
즉, 더 적은 Epoch로 Error Rate를 줄입니다.

training data의 개수가 너무 많아, GPU를 2개 썻다고 합니다. GPU를 병렬화하여 사용함으로써 읽고 쓰기가 동시에 가능해, 메모리에서 데이터를 불러오지 않아도 되었다고 합니다.
"The GPUs communicate only in certain layers"
이 의미는 3번째 layer의 커널이 2번째 layer의 모든 커널 맵에서 입력을 받는다는 의미입니다.
즉, GPU끼리 병렬화 하여 데이터를 학습하다, 특정한 layer에서만 서로 feature들을 공유한다는 의미입니다.
이러한 GPU의 병렬화 기법은 cross-validation(교차 검증)에는 문제가 있지만, 방대한 훈련 데이터를 학습하는데는 가능했다고 합니다.
Cross-validation이란, train 데이터를 train 데이터와 validation 데이터로 분리한뒤 validation 데이터로 사용해 학습 도중에 모델을 검증하는 방식입니다. validation 데이터는 가중치 업데이트에 영향을 주지 않습니다.(단, 학습에 참조하긴 합니다.)
또한, Error rate를 최대 1.2%까지 줄여주었고, 1개의 GPU를 사용하는것 보다 훈련 속도가 더 빨랐다고 합니다.

앞에서, Activation으로 tanh와 sigmoid는 saturating 하기 때문에 Normalization을 해주어야한다고 했다.
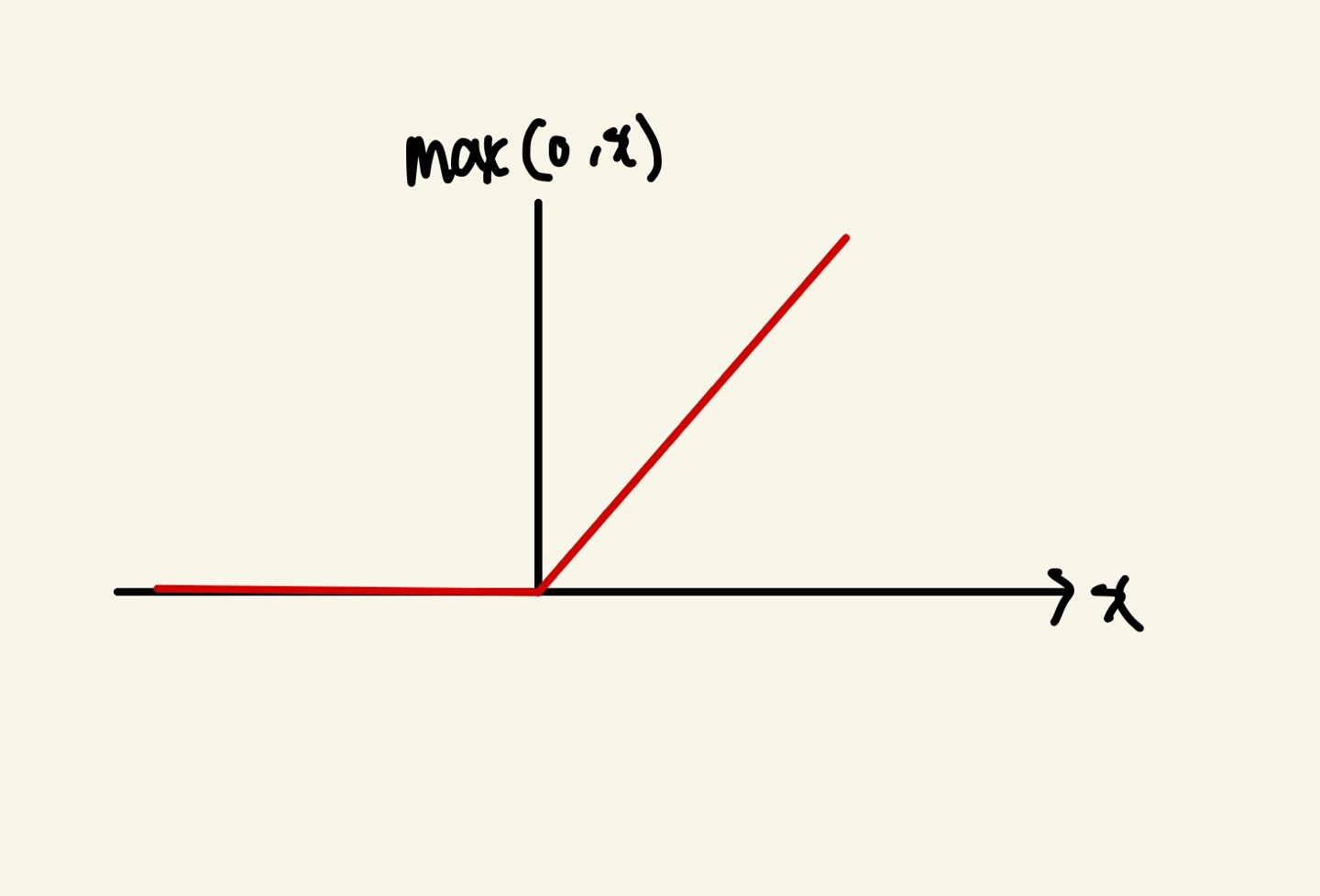
하지만 ReLu는 tanh와 sigmoid와는 이유가 다릅니다.
ReLu는 x값이 음수값이 아니면 x값 그대로의 함수값을 출력한다. 만약 이러한 Activation함수를 거친 output값을 다음 layer의 neuron input값으로 주었을때 x값이 상대적으로 큰 것이 다른 neuron의 중요도를 떨어뜨릴수 있다. 즉, 학습이 원활하게 잘 되지 않을수도 있다는 뜻이다.
앞선, 이미지를 정규화 해주는 이유랑 비슷하다고 생각하면 될것 같다.
LRN(Local Response Normalization)
Batch Normalization전에 나온 기법입니다. 현재는 한계가 지적되어, 잘 사용되지 않습니다.
LRN과 같은 local normalization을 적용하면 모델이 generalization을 하는데 도움이 된다고 설명합니다.
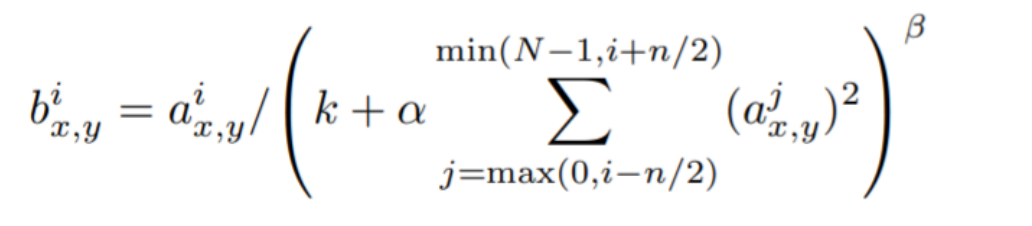
- b : LRN 결과
- a : (x,y)에 위치에 적용된 i번째 kernel의 output
- i : 현재 Filter
- n : 정규화의 범위를 결정하는 매개변수, 인접한 채널의 개수
- N : 총 Filter의 개수(Layer안의)
- K : 분모가 0으로 나누어지는 것을 방지하는 역할.
- alpha, beta : 정규화의 강도를 조절하는 값
K,n,alpha,beta는 hyperparameter이다.
n은 인접한 커널들의 값이기 때문에 매우 중요한값이다.(물론 다 중요하다)
이 식은 채널값의 크기가 클 수록 b값이 작아지고, 채널의값의 크기가 작을수록 b값이 커진다는것을 알 수 있다. 따라서 큰 값은 작게 만들면서 정규화를 진행시킨다.
이러한 것을 Lateral Inhibition을 언급하면서 설명하고 있다.
ReLu를 쓰고 LRN을 적용했고, K = 2, n = 5, a = , beta = 0.75로 설정했다고 한다.
LRN을 적용하면서 최고 1.4%의 Error Rate를 줄였다고 한다.
Later Inhibition이란 해석하면 '측면 언제' 라는 뜻인데, 요약하자면 강한 자극이 다른 약한 자극의 힘을 막는다는 뜻이다.
 헤르만 격자를 보면 회색의 점을 보려고 하면 잘 보이지 않지만, 정사각형의 검정색을 보면 회색의 점을 볼 수 있다. 따라서 강한 자극은 검정색, 약한 자극은 회색 이라고 볼 수 있다.
헤르만 격자를 보면 회색의 점을 보려고 하면 잘 보이지 않지만, 정사각형의 검정색을 보면 회색의 점을 볼 수 있다. 따라서 강한 자극은 검정색, 약한 자극은 회색 이라고 볼 수 있다.
 기존의 Pooling Layer는 Pooling size를 Stride의 크기와 똑같이 주어서 Pooling을 해주었지만, Pooling size를 Stride보다 작게 설정함으로써 overlapping Pooling을 해주었다고 한다. 이러한 방식으로 에러율은 0.4% 낮아지고, 오버피팅이 약간 더 잘 일어나지 않는다고 말하고 있다.
기존의 Pooling Layer는 Pooling size를 Stride의 크기와 똑같이 주어서 Pooling을 해주었지만, Pooling size를 Stride보다 작게 설정함으로써 overlapping Pooling을 해주었다고 한다. 이러한 방식으로 에러율은 0.4% 낮아지고, 오버피팅이 약간 더 잘 일어나지 않는다고 말하고 있다.
 AlexNet은 다항 로지스틱 회귀(Multinomial logistic regression)을 극대화 한다고 합니다.
AlexNet은 다항 로지스틱 회귀(Multinomial logistic regression)을 극대화 한다고 합니다.
Multinomial logistic regression
- 종속변수가 범주형(Categorical)이면서, 3개 이상의 범주형을 가질때를 말합니다.
- output layer에서 softmax함수를 써줍니다.(binary이면 sigmoid함수)
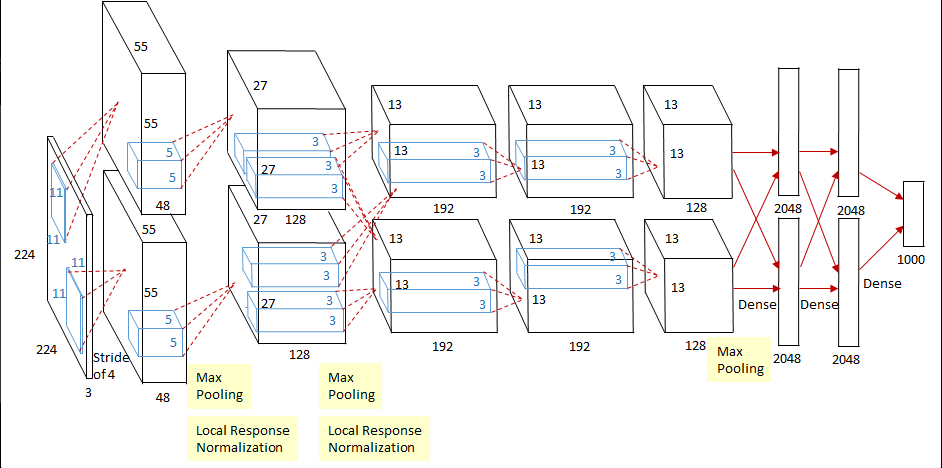
Feature Map에는 5개의 Conv Layer, Fully-connected Layer에는 3개의 layer가 있다고 합니다.
GPU
- GPU 1에서는 비교적 색상과 관련 없는 정보를 학습하고, GPU2에서는 색상과 관련된 정보를 학습하고 있네요. 이렇게 2개의 GPU는 독립적으로 학습되고 있습니다.
특정한 layer들만 GPU들끼리 communicate한다고 합니다.(2,4,5 layer만 서로 연결 되어있음)
Fully-Connected-Layer에서는 서로 다른 GPU끼리 서로 communicate합니다.
MaxPooling
- 1,2,5 Conv Layer에서 적용
LRN
- 1,2 Conv Layer에서 적용
전체 구조
여기에서 사진 참조
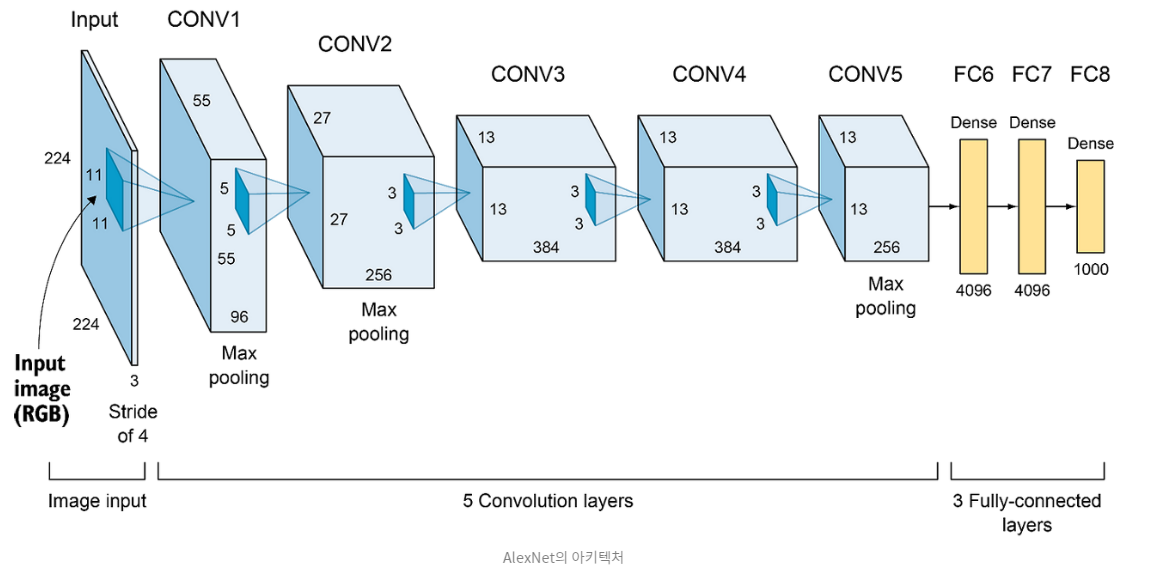
최근 Model과는 다르게 Conv4에서 Conv5로 가는데 오히려 Kernel의 개수를 줄여준 것을 볼 수 있습니다.
또한 처음 이미지에서 Kernel Size를 매우 크게주고, Stride의 크기가 현재 모델 대비 매우 크다는것을 알 수 있다.
Reducing Overfitting

Data Augmentation
Image Augmentation
image들을 Augmentation하는데 비교적 연산 횟수가 적다고 말합니다. 그렇기 때문에, 디스크에 따로 저장하지 않고 변환된 이미지를 학습할 수 있다고 합니다.
GPU에서 이전의 batch만큼의 image들이 학습하는 동안, CPU에서는 image들이 Augmentaion 되었다고 말합니다.
다운 샘플링했던 이미지들을 224 * 224로 이미지를 Random Crop + Horizontal reflection 하여 모델에 학습 데이터로 쓴다고 합니다.
테스트시에는, 5개의 224 * 224로 이미지를 Random Crop(중앙, 좌측 상단/하단, 우측 상단/하단) + Crop한 이미지들을 Horizontal reflection하여 Prediction을 수행합니다.
PCA
training set에 RGB값에 대해 PCA를 수행하여 각 training image에 평균이 0, 표준편차가 0.1인 가우시안 값에 비례하는 크기의 랜덤 변수와 이미지에서 발견된 주요 구성요소의 배수를 더한다고 합니다.
이러한 방법은 원본이미지에 대해 대략적으로 중요한 특성을 뽑아내고 조명의 세기와 색상의 변화에 대해 변하지 않으며, top-1의 Error rate를 1%넘게 낮춰주었다고 합니다.
Dropout
Hidden Layer의 output을 50%의 확률로 0으로 설정하여 forward pass와 backpropagation에 영향이 가질 않습니다. 그래서 input이 입력될때마다 새로운 architecture가 생성되지만, 모든 architecture는 weight를 공유한다고 합니다. 이러한 기술은 뉴런의 co-adaption(어떤 뉴런이 다른 특정 뉴런에 의존성향을 갖는)을 감소시킨다고 합니다.
co-adaption(상호적응)
network가 학습중, 어느 시점에 같은 layer의 2개 이상의 neuron이 입력 및 출력 강도가 같아지면, 아무리 학습이 진행되어도 그 neuron들은 같은 일을 수행하게 됩니다.
즉, neuron이 서로 중복이 되고, 결국에는 메모리 낭비로 이어집니다.
또한, 같은 layer에서 특정 neuron의 weight가 큰 값이 있다면, 큰 값의 weight의 영향이 커지므로, 다른 neuron의 학습 속도가 느려지거나 학습이 제대로 진행이 되지 못하는 경우가 있습니다.
Dropout은 이러한 co-adaption의 문제를 해결해줍니다.
dropout은 학습이 진행될때마다 전체적인 architecture가 바뀌기 때문에 co-adaption이 발생한 노드들이 분리될 수 있습니다.
Details of Learning

- Momentum 계수 : 0.9
- batch_size : 128(SGD)
- weight 초기화 : 평균 0, 분산 0.01인 가우시안 분포 사용
- bias 초기화 : Conv Layer 2,4,5 and FC Layer에서 1로 설정, 나머지는 0으로 설정
bias 초기화를 통해서 ReLu에 양수 값을 줄 수 있어서 초기 단계의 학습을 빨리 할 수 있었다고 합니다. - Learning Rate : 0.01
validation Error rate가 감소하지 않으면, Learning Rate를 10으로 나누어주었다고 합니다. 종료 직전까지 Learning Rate가 3회 감소되었다고 한다. - Epoch : 90
학습하는데 5 ~ 6일정도의 시간이 걸렸다고 합니다.
Code
여기 클릭하시면, github와 연동됩니다! 제가 구현한 코드입니다. 혹시라도 잘못된점이 있다면, 댓글 달아주시면 감사하겠습니다!!!
읽어주셔서 감사합니다 :)
