Abstract
SPP-net과 Fast R-CNN에서 사용하는 region proposal방법은 detection 과정에서 bottleneck의 computation 문제가 있었지만, 그대로 detection과정에서는 running time을 줄인 것은 맞습니다.
하지만, 이 bottleneck을 없애기 위하여 Faster R-CNN은 RPN의 방법을 제안하였으며, 이는 위에서 말한 bottleneck을 해결하였습니다.(cost-free라고 나와있네요)
여기서 bottleneck은 가장 실행시간이 느리게 만드는 요소, 즉 알고리즘입니다.
RPN을 사용함으로써 object bounds(Bbox)와 object scores(classification scores)를 동시에 predict하게 되었습니다.
이는 기존에 존재하던 Fast R-CNN과 RPN을 병합하여 single network를 만들었으며 RPN이 "attention"의 mechanism과 같다고 말하네요. 아무튼 attention이 제일 중요한 것 같습니다.
Introduction
Abstract에서도 말했지만, Fast R-CNN은 region proposal단계에서 bottleneck현상이 있습니다. 사실, 이 bottleneck의 현상만 빼게 되면 성능이 빠르기는 합니다.
이는, 기본적으로 GPU를 사용하게 되지만, region proposal단계에서는 cpu를 사용하기 때문에 그렇다고 합니다.
Faster R-CNN은 Conv연산을 통하여 region proposal하는 알고리즘을 통해 computation연산이 거의 들지 않았다고 합니다. 이는 RPN method를 말하는 것이며, img당 10ms(0.01초)의 inference를 보여준다고 합니다.
RPN은 대략적인 Bbox를 찾아주게 되고 동시에 object의 존재 여부를 score로 표현해준다고 하는데 이는 classification의 score를 말하는 것 같습니다.
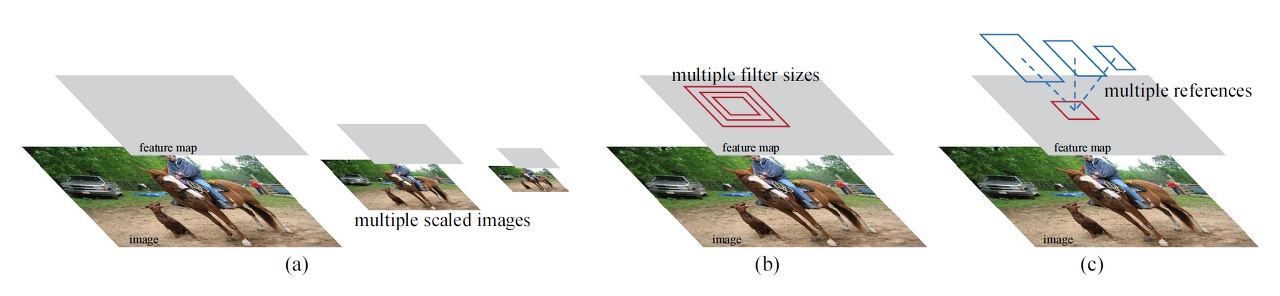
위에서 c가 RPN method를 의미하며 다양한 scale과 가로/세로 비율을 갖는 box로 anchor box를 효과적으로 예측하도록 설계되었습니다.
이에 따라 단일 scale의 img(1개의 img)만을 사용하기 때문에, 속도가 매우 빠르게 됩니다.
실험결과 RPN이 selective search보다 정확도가 높았으며 GPU측면에서도 frame별 처리 속도가 높았다고 합니다.
Related Work
Faster R-CNN 이전의 region proposal한 방법은 pixel을 grouping하는 selective search나 sliding window를 사용하는 edgebox가 있는데, region proposal은 CPU에서 사용하며, GPU에서 object detection을 한다고 합니다.
이를 통해 우리가 알 수 있는 것은, 독립적인 모듈이라는 것을 알 수 있습니다.
R-CNN에서는 Bbox를 regression을 통해 미세하게 위치 조정을 하지만, 별도로 수행하기 때문에 selective search나 Bbox 성능을 결정한다고 과언이 아닙니다.
Architecture
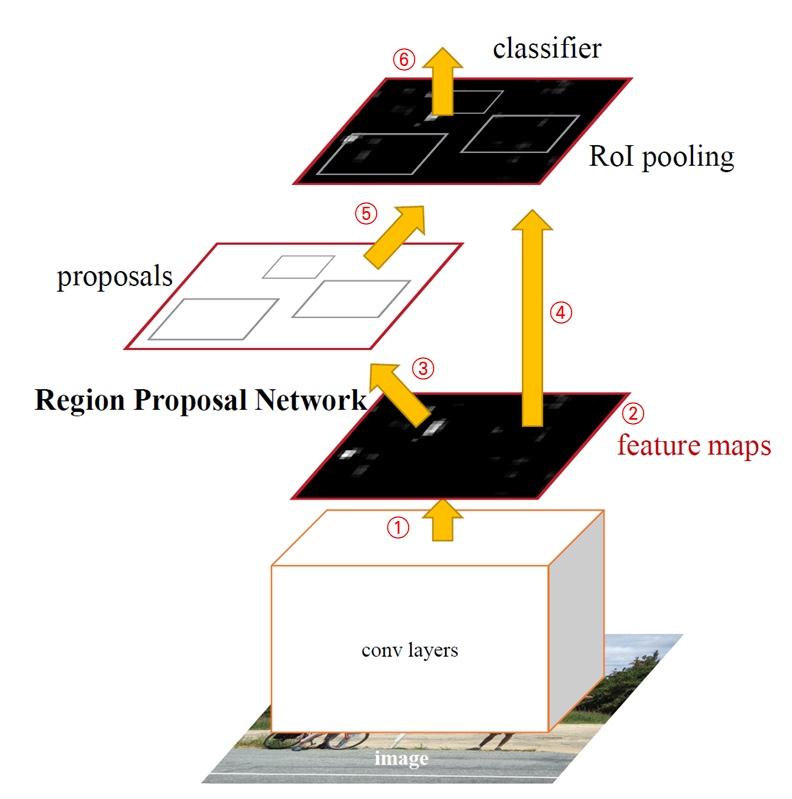
-
Conv Layer를 통해서 전체 img에 conv연산을 한다.
-
Conv Layer를 지나고, feature map이 생기는데 이는 RPN과 Classifier에 전달한다. (feature map을 공유해서 사용하게 되고, classifier는 fast R-CNN과 같다.)
-
RPN은 region proposal을 시행한다.
-
Region proposal의 결과를, roi pooling하게 된다.
-
feature map과 boundary box를 활용해 object detection을 수행하게 된다.
RPN이 ojbect가 어디에 있을지, feature map과 region proposal Bbox를 활용해 object detection을 수행하게 된다.
Anchors
각 sliding window 위치마다 최대로 예측할 수 있는 boundary box의 개수는 k개입니다. Bbox의 개수가 k개이기 때문에, coordinate position의 값은 4k개가 되며, cls layer는 2k개의 socre를 가지게 됩니다.
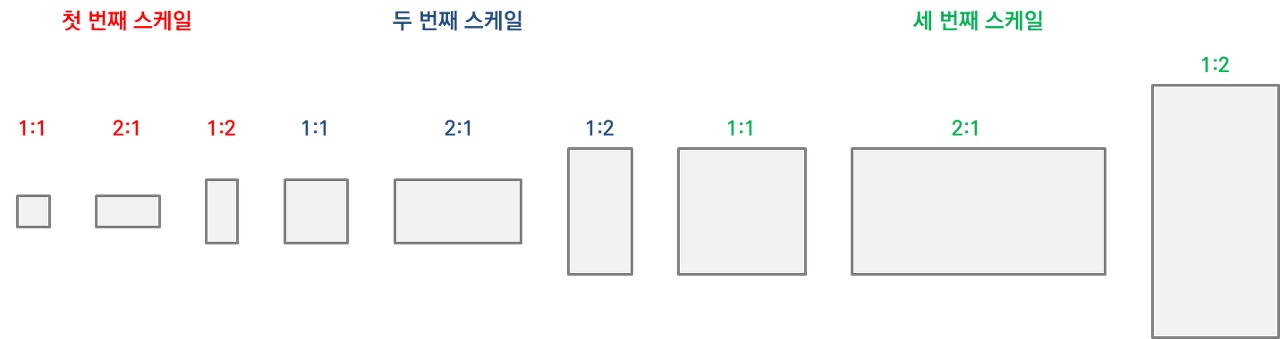
RPN에서 사용하는 Bbox를 Anchor box라고 합니다.
위의 그림은 k=9이며, socre이 3개 ratio가 3개입니다. feature map의 size가 wxh라면, anchor box의 개수는 wxhxk개가 됩니다.
즉, anchor box는 input img에 대해서 object가 있을 법한 곳에 설정한 box이며, 특정 영역을 포괄하는 box에 object가 있는지 없는지를 network를 통해 판단하게 됩니다.

위의 그림을 통해 설명하자면, grid를 3x3으로 나누었으며, object의 middle point에 2개의 object가 있다고 해봅시다. 그렇다면 grid cell마다 object가 있는지 없는지에 대한 여부를 알 수 있습니다.
y는 label을 이야기하는 것이며, 는 object가 있다/없다, b는 Bbox의 정보, 는 classification의 index를 의미합니다.
anchor box가 9개이면, y의 labeling의 vector가 더 길어지겠네요,,
anchor box가 많아지면 많아질수록 detection을 더 잘할 수 있게되는 것을 직관적으로 알게됨을 알 수 있습니다.
Loss Function
RPN을 훈련하기 위해 Anchor Box마다 binary classification을 수행하게 됩니다.
2가지를 positive label로 사용하게 되며, gt box와 iou가 가장 큰 anchor와 gt box와 iou가 0.7이 넘는 anchor로 쓰게 됩니다.
만약 후자가 없다면 전자를 쓰는 것이 일반적이긴 합니다.
IOU가 0.3미만이면, negative label이며, 0.3~0.7이면 훈련에서 제외됩니다.

-
i : Anchor Box Index
-
: Anchor box가 object일 확률
-
: Anchor box안에 object일 확률 0 / 1
-
: predict Bbox 4가지
-
: Label Bbox 4가지
-
cls / reg 모두 normalize 진행
-
Λ : cls와 reg의 balance를 위한 parameter
