Abstarct
YOLO는 R-CNN의 계열과 다르게, 기존 Multi-task문제를 1개의 regression으로 loss function을 재정의하여 Single-task로 해결하였습니다.
Img전체에 대해서 1개의 신경망이 1번의 Conv와 Fc layer로 Bbox와 class를 predict하게 되는 것이다.
사실, 논문의 제목에서 모든 것을 설명하고 있다.
You Only Look Once는 1개의 전체 이미지를 보는 횟수가 1번이며, 기존 region proposal과는 다르다.
Unified는 classification과 localization을 따로 두지 않고 단일화를 시켰다는 것을 의미한다.
Real-Time이라는 것은 속도에 대한 개선에 힘썻으며, yolo는 45fps가 나오며 layer를 줄인 fast yolo는 155fps가 나온다고 한다.
Introduction
object detectiond느 class와 location까지 predict해야하기 때문에 복잡한 과정을 거치게 된다.
기존의 DPM(Deformable parts model)은 sliding window 방식으로 object detectiond르 하는 모델이며, R-CNN은 region proposal로 object가 있을만한 위치를 추천해주고, 이를 다시 Bbox를 조정하여 IOU가 가장 높은 값인 Bbox를 추출하는 NMS를 하게 된다.
객체에 따른 Bbox의 score를 재산정 하기 위해서 post-processing을 하게 된다
R-CNN은 각각의 단계가 독립적으로 이루어지며 이를 multi-stage라고 하며 복잡한 과정을 거치게 된다.
YOLO는 이러한 과정을 1개의 문제로 보며, 회귀문제로 정의하였다고 한다. 이를 Loss function에서도 보겠지만 1개의 각각의 식이 회귀문제로 되어있음.
즉, Bbox의 위치, class 확률을 1개의 회귀문제로 정의하였다고 한다.

input img size는 448x448로 비교적 큰 size를 활용하며, 이는 efficientnet에서 증명하였던 이미지가 클수록 feature를 더 잘 뽑을 수 있는 것을 활용한듯 하다.
다음, 1개의 single conv를 inmage에 넣고, nms를 거쳐 최종적인 output이 나온다고 한다.
(너무 추상적이라 뒤에서 자세히 설명할 것임)
장점은 다음과 같다.
1. 복잡한 과정을 1개의 문제로 재정의하였기 때문에 매우 빠르다.
2. predict할 대, img 전체를 conv에 태우기 때문에 객체뿐만이 아닌 주변 정보도 학습하여 처리하게 된다.
Fast R-CNN은 주변 정보까지 처리하지 못하여 background error가 있다고 한다. yolo는 주변정보까지 학습하기 때문에 background error가 비교적 낮다고 전해진다.
3. 물체의 일반적인 부분을 학습한다.
4. 빠르게 object를 검출할 수 있지만, 정확도는 떨어진다.(사실 상 yolov1의 단점임) -> 이를 속도와 정확성의 trade off라고 한다.
Detection
Procedure
-
Img를 SxS grid로 나누고, 1개의 gid cell안에 object중심이 포함되면, 해당 grid cell이 object에 책임지고 탐지를 수행한다.(object 중심이라는 것을 잊지말아야함)
-
각 grid cell은 B개의 Bbox와 Confidence Score를 predict한다.
-
각 grid ceel은 c개의 class에 대한 conditional class probability를 계산한다.
위의 과정은 train stage에서 사용되는 것들임을 잊지말자!!
Unified Detection
Input img를 SxS grid로 나누게 되고, 각각의 grid cell에서 object의 중심이 되는 것이 있따면, 그의 cell이 해당 object를 검출하게 된다.
중심점이 있는 grid cell에서는 B개의 Bbox를 생성하고, Bbox의 confidence socre를 predict하게 된다.
Confidence Score
정의 : x (object가 있는 것만 Bbox가 있으므로 background는 IOU가 계산되지 않음)
grid cell에 아무것도 없으면 = 0, 그럼 x = 0
grid cell에 object가 있으면 = 1, 그럼 x = IOU(이 값이 1이라면 가장 ideal한 값임, 왜냐하면 Gt-Bbox와 Pd-Bbox가 완전히 겹치기 때문)
Bbox는 5개의 값인 x, y, w, h, confidence의 값으로 이루어져있음(vector로 되어있음)
(x,y) : Bbox 중심의 grid cell내 상대 위치이므로, 0~1사이의 값을 가지게 됌
(w,h) : Bbox의 상대 width와 height를 뜻함, 0~1사이의 값을 가짐
Conditional Class Probability
의 조건부확률이므로, object가 있고 해당하는 그 object가 해당 class일 확률을 의미한다.
grid cell안의 Bbox가 몇 개가 있든, 1개의 class에 대한 확률만을 구하게 된다.
Class-Specific Confidence Score
정의 : Conditional Class Probability x Confidence Score
x x 이므로, x이다.(조건부확률 정의알면 됌)
이에 대한 의미는 object를 탐지했고(Bbox가 있음 -> IOU가 있으니) 해당하는 class와 IOU가 얼마나 들어맞는지에 대한 의미이다.
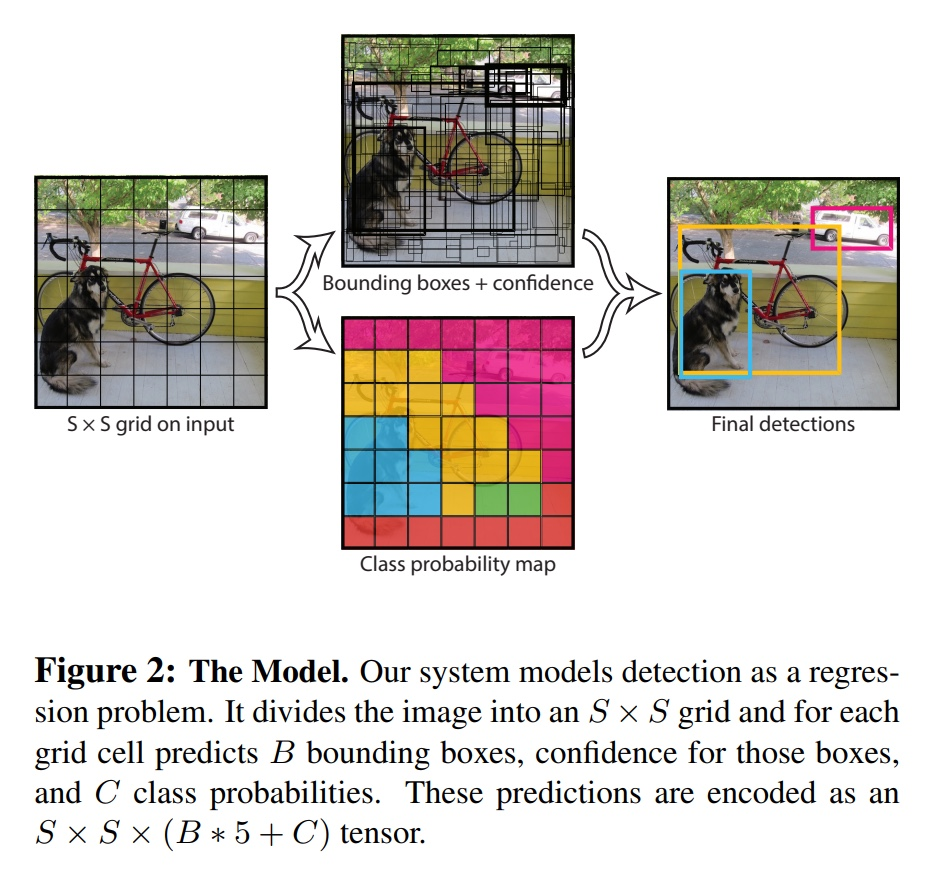
위의 그림이 이때까지 설명했던 것을 말해준다.
output은 SxSx(Bx5 + C) tensor형태이며, SxS는 grid의 개수, Bx5는 B는 bounding box의 개수이고 5는 Bbox의 좌표이다. 즉, (x,y,w,h,confidence)로 나타낸다. 그러므로 Bx5임.
C는 class의 개수이다.
Network Design
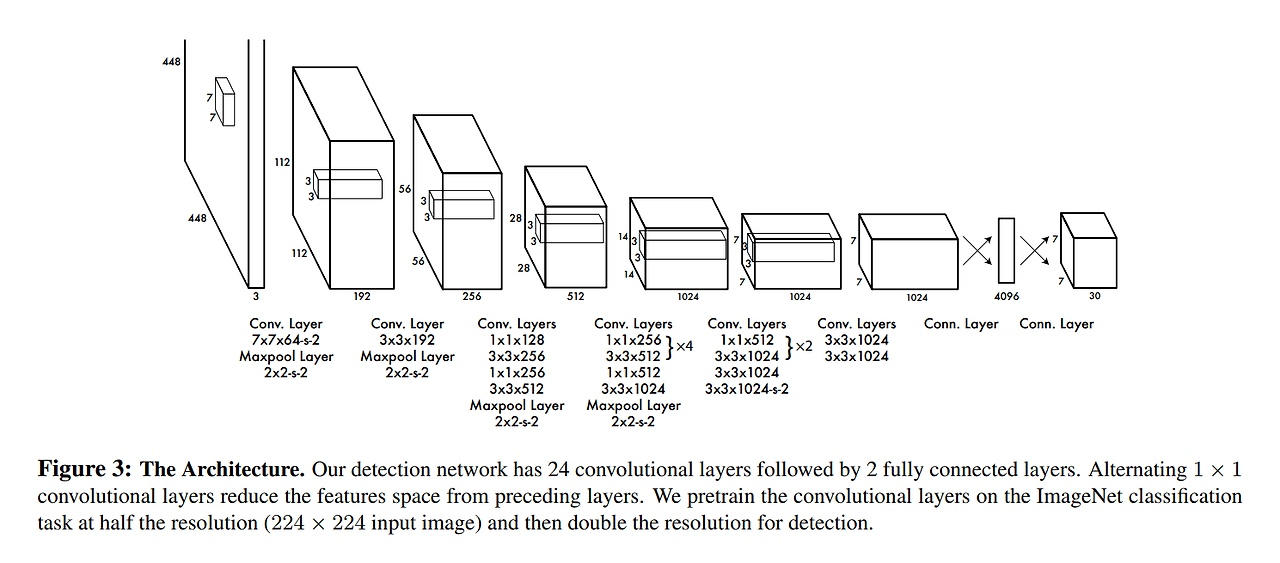
GoogleNet이며, 조금 더 fine tuning한 architecture이다.
24개의 conv layer와 2개의 fc layer가 있으며, 최종 output size는 7x7x30이라고 한다.
object detection을 하기 위해서는 img의 정보의 해상도가 높아야하며, 448x448의 크기로 img를 resize해주어야한다.
activation function으로는 ReLU가 아닌 Leaky ReLU를 썼으며, 마지막 layer는 linear activation function으로 입력값을 그대로 전달한 function을 썼다고 한다.
Leaky ReLU는 x값이 0보다 크면 1이고, 0보다 작거나 같으면 0.1x의 값을 가진다고 한다. (여기서 0.1은 hyperparameter이다. 사실상 a임)
Loss Function SSD
설명할게 많아서, Youtube에 제가 SSD에 대해서 자세하게 설명했으니, 참고해주시면 감사하겠습니다
33분이 아깝지 않습니다
