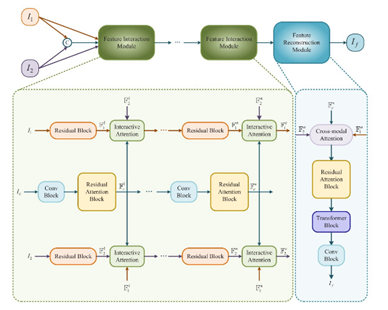
Overview Framework
-
FIM(Feature Interaction Module)은 unique, common feature를 동시에 뽑기 위함으로 설계 되었음
-
는 source image branch이며 RAM, ITA로 구성되어 있음
-
RAM는 feature extractor, ITA는 complementary feature extractor 역할임
-
는 를 concatenate한 것으로 common feature를 extraction할 수 있음
-
Homogeneous feature는 residual/conv block에서, Heterogeneous feature는 ITA에서 extraction한다.
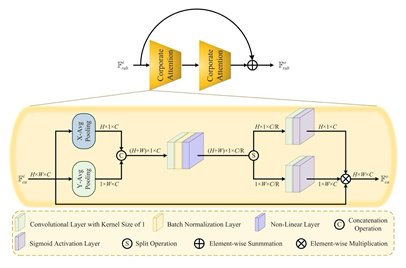
RAB(Residual Attention Block)
-
이는 attention block으로 horizontal, vertical 기준으로 GAP을 통해 spatial attention을 적용하는데, 이를 bidirectional pooling이라고 함
-
이 module에서 개인적으로 의문이 드는 것은, bidirectional pooling을 하고 concatenate을 해주었는데 각 unique direction의 feature을 얻기 위해 concat이 아닌 independent하게 1x1 conv operation을 적용해주는 것이 맞다고 생각이 들었음
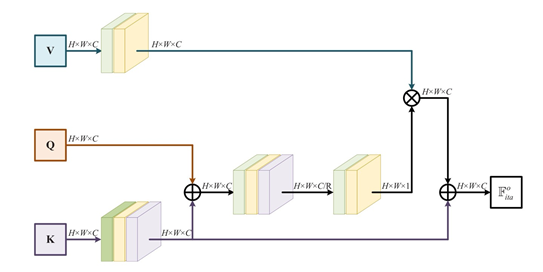
ITA(Interactive Attention)
-
이는 dynamically contextual information을 추출하기 위함으로, self-attention과 유사한 구조임
-
이는 가 각각 있으므로 기준으로 설명하면 다음과 같음
-
K는 에서 conv연산을 통해 encoding하여 가 output임
-
Q는 F_2^i로 I_2에서 RB의 output인데, Q에 왜 conv연산이 없는 이유를 생각해보았는데 이는 F_1^i를 기준으로 attention을 적용해야하기 때문임
-
만약 Q에다가 똑같이 conv연산을 해주게 되면, 모델 input이 가 의미가 없어지게 되며 K가 1단계 더 깊은 layer를 쌓아 중요도를 높이는 것이 맞음
-
따라서 Q와 를 element-wise summation하게 되면 Q보다는 에 더 중요한 정보가 있게되어 FIM구조가 유지될 수 있으며 2개의 conv가 지나면 가 output임
-
V는 로 의 common feature를 최대한 유지하기 위해 1x1 conv연산을 해줌으로써 가 output임
-
따라서 ITA의 최종 output은 로 각 source image의 unique, common feature를 얻을 수 있음
-
에서 로 weight map을 만드는 것이 더 옳바른 방향인 것으로 보임
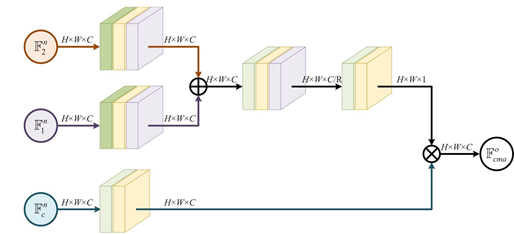
Cross-modal Attention
-
은 자신의 feature를 더 많이 가지고 있으며, 동시에 의 정보도 첨가되어 있음
-
ITA와 다른점은 attention map을 구할 때 에 똑같이 conv를 쌓아 중요도를 서로 같게 해주었다는 것으로 complementary information을 뽑아낼 수 있으나, ITA를 적용하는 과정에서 서로 다른 modality를 comprehensive information의 가중치를 곱해주어 redundant information이 남아있을 수 밖에 없음
- 즉, 이 같은 중요도를 갖는다고 하여 동일한 conv block 적용 후 summation하면 redundant information이 있을 수 밖에 없음, 그래서 은 common feature로 redundant information만을 가져감, 그렇다면 이를 각각 multiply하게 되면 redundant information을 제거할 수 있다고 논문에 나와있는데, 이는 잘못된 표현임
Inference

- TNO Dataset으로 pre-trained model로 inference해보았는데, fusion result에서 complementary information이 매우 부족하다는 것을 알 수 있으며, ITA 및 CMA의 한계점을 확인할 수 있음
