Motivation
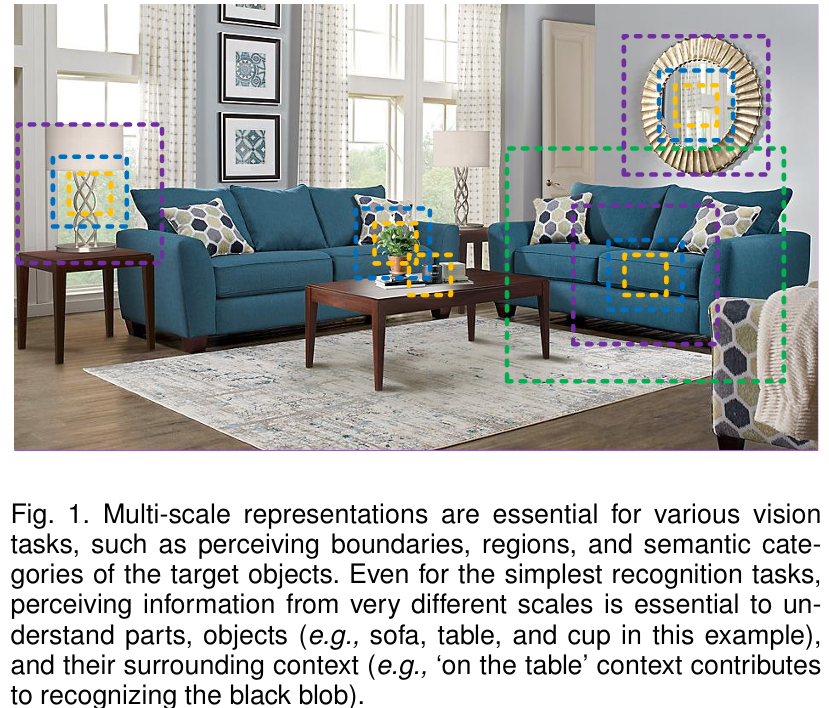
- Object는 image에서 각기 다른 size를 가짐
- Essential contextual information는 object를 recognition하는데 중요함
- 따라서 Multi-scale을 가지는게 매우 중요함
Architecture
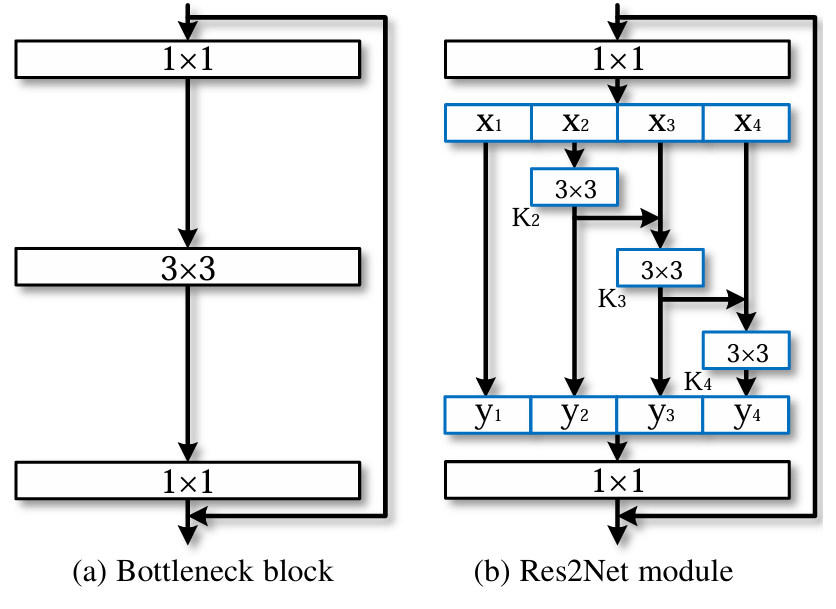
- 기존 bottleneck구조는 더 높은 수준의 receptive field를 가지는 방법 중에 1개였음
- 저자는 이를 computational complexity는 그대로 유지하되, each layer에서 더 풍부한 receptive-field를 얻고자 연구함
따라서 pipeline은 다음과 같음
-
Res2Net block에 들어가기전에 1x1 conv로 input을 태움
-
이후, hyperparameter 's'를 input channel에 나눔
-
예를 들어 만약 input channel이 64이고, 사용자가 s를 4로 설정했으면 는 각 channel수가 이므로 16을 가짐
-
이후, 을 제외한 나머지는 라는 3x3 conv를 태워버림, 여기서 주의할 점은 기존의 bottleneck과 complexity를 같게하기 위해 은 을 적용 안함
-
따라서, 라면 에서 보이는 것과 같이 에서만 이전 i의 값의 정보를 summation하여 multi-scale granularity를 이룰 수 있음
-
각 3x3 conv를 태우는 것은 multi-scale을 사용하여 더 넓은 receptive field를 가지고 갈 수 있는 것임
따라서, 논문에 나와있는 수식은 다음과 같음.
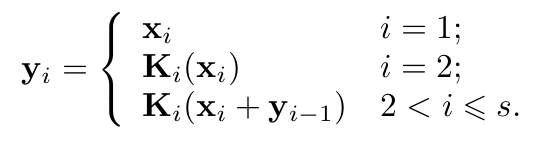
이때, s값이 클수록 multi-scale을 가지고 갈 수 있지만 complexity는 올라가니 주의해야하며 'hierarchical residual like connection'로 논문에서 언급함

할거면 똑바로 하고 아님 말자