들어가며
파이썬을 공부하며 헷갈렸던 iloc 슬라이싱 방법과 drop의 parameter 개념을 포함해, column과 row를 제거하는 방법들을 정리하고자 한다.
이하 내용은 라이브세션 강의 내용 및 이 글을 참고했다.
import pandas as pd
df = pd.read_csv('customer_details.csv').drop() 메서드
단일 행/열 삭제
drop 메서드를 통해 원하는 행or열을 제거할 수 있다
이 때 axis=0이라면 row의 인덱스 기준, axis=1이면 컬럼명을 기준으로 한다.
inplace는 원본 테이블의 수정 여부를 나타낸다. True라면 df.drop을 했을 때 화면 출력에 더해 df에 들어있는 테이블 자체를 직접 수정한다
default값은 axis=0, inplace=False이다
# 컬럼명 'Category'를 삭제
df.drop('Category', axis=1, inplace=False)
# df.drop(columns = ['Category'])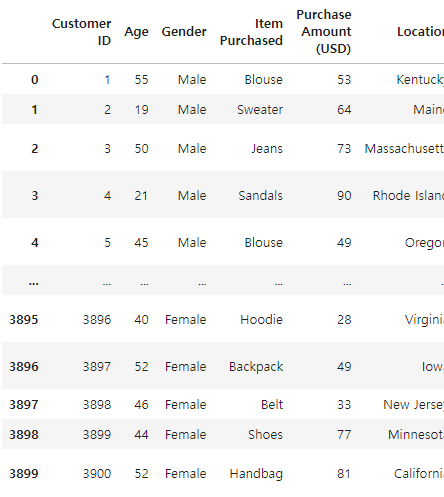
# 4번째 row를 삭제
df.drop(4, axis=0, inplace=False)
# df.drop(4)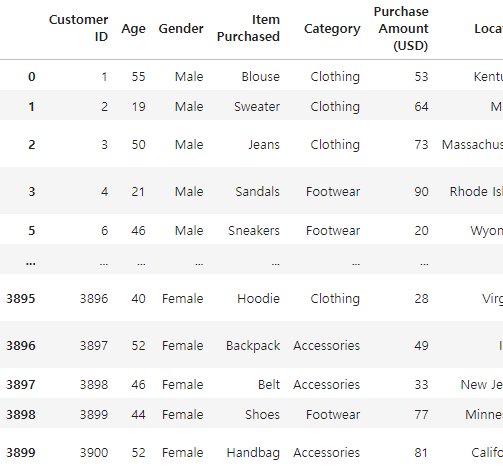
복수 행/열 삭제
여러 행/열을 삭제할 때는
행=> [컬럼명1, 컬럼명2]
열=> [n:m]
으로 할 수 있다
# 컬럼명 'Category'와 'Gender'를 삭제
df.drop(['Category', 'Gender'], axis=1)
# df.drop(columns = ['Category', 'Gender'])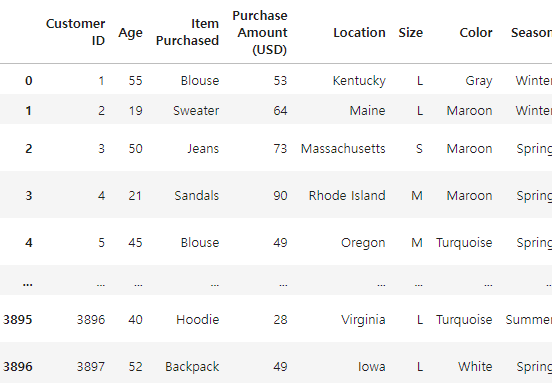
# 3 ~ 5번째 row 삭제
df.drop([3, 4, 5])
# df.drop([3, 4, 5])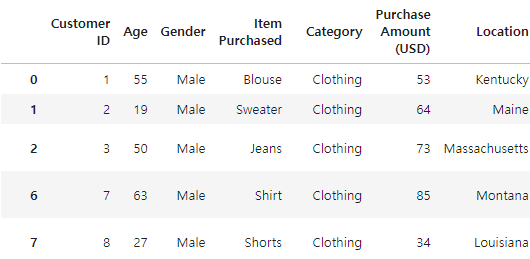
iloc, loc를 이용한 삭제
loc는 location, iloc는 index location을 의미한다
이름 그대로, loc는 행 또는 열의 이름을 선택해서 슬라이싱할 수 있으며, iloc는 행/열의 인덱스로 슬라이싱이 가능하다
iloc를 이용
행 또는 열의 인덱스를 사용하여 부분 조회 및 삭제가 가능하다
# 1~10 row에서 인덱스 4인 컬럼만 조회
df.iloc[1:10,4]
# 0번째 column을 삭제하고 나머지만 남긴다.
df.iloc[:, 1:]
# 1번째 컬럼인 Customer ID가 삭제되었다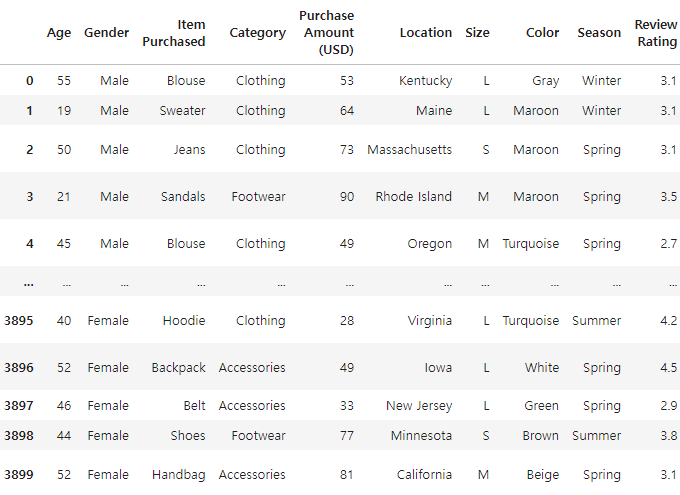
# 0번째, 1번째 column 삭제 뒤 나머지만 남기기.
df.iloc[:, 2:]
# Customer ID에 이어 Age까지 삭제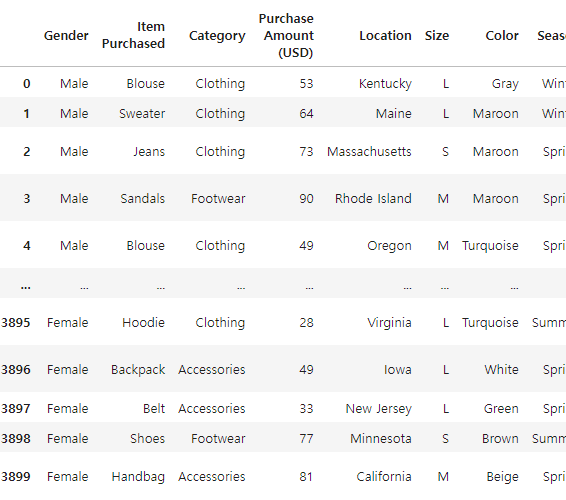
# row는 일반 슬라이싱이 default이기에 iloc없이도 바로 인덱스 슬라이싱이 가능하다
# 0번째 행을 삭제하고 나머지 추출
df[1:]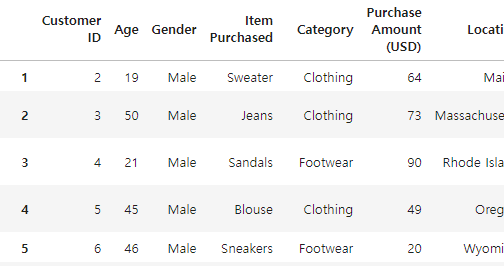
# 0, 1번째 행 삭제하고 나머지 추출
df.iloc[2:] 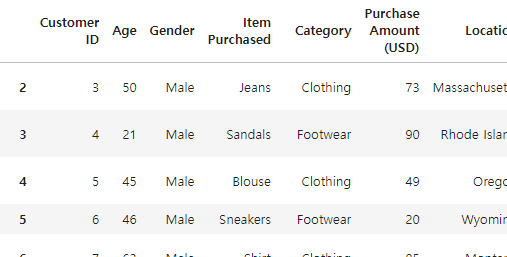
loc를 이용
인덱스가 아니라 행 또는 열의 이름을 선택해서 부분 조회 및 삭제가 가능하다
* 단, loc에서는 인덱스가 아니라는 점을 유의해야 한다. 그렇기에 슬라이싱을 할 때 마지막 행 또는 열을 '포함한다'
# 'Age' 컬럼부터 끝까지 추출
df.loc[:, 'Age':]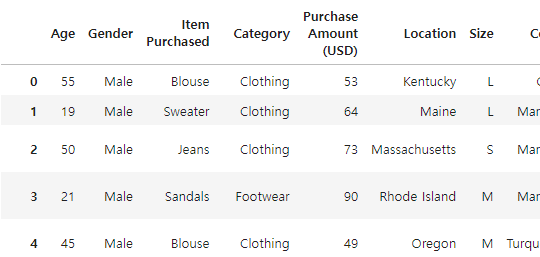
df.loc[2:7]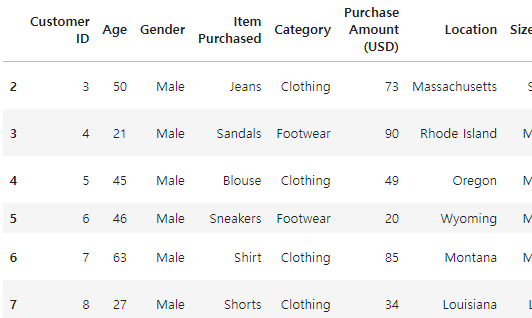
# 'Customer ID' 컬럼부터 'Category' 컬럼까지 1~5번 행을 추출
df.loc[1:5, 'Customer ID':'Category']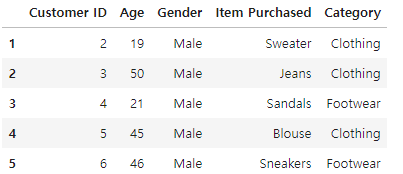
del 사용
del을 사용하는 경우 원본 테이블에서 아예 삭제하는 방식임
del df['Category']
df
어제보다 오늘 더