들어가며
어제 새롭게 pandas 라이브러리에 대해 배웠지만, 아직 생소한 개념이라 10min-pandas를 통해 구문들을 직접 쳐보면서 익혀보고 있다.
아래는 그 내용 개괄 정리
Pandas와 DataFrame
pandas
python에서는 이미 앞서 다른 사람들이 만들어놓은 readymade func들을 가져와서 사용할 수 있다.
이러한 함수들을 모아놓은 것이 라이브러리
데이터 분석에 있어서 가장 유명한 라이브러리 중 가장 유명한 것 중 하나가 바로 pandas이다.
csv, html, json, 다양한 확장자/포맷의 데이터들을 DataFrame으로 만들어주는 마법의 라이브러리
라이브러리는 아래와 같이 최상단에서 import를 해주어야 한다.
as 뒤 얼라이어싱은 원하는대로 적어도 되지만, 통상적으로 pd로 자주 쓰는 듯 하다
import pandas as pddataframe
계속 언급하고 있는 dataframe이란, 파이썬에서 사용하는 데이터 포맷이다.
행과 열의 테이블 형태의 데이터 구조로, 통계와 머신러닝 모델에서 가장 기본이 된다.
파일 불러오기
원한다면 직접 데이터프레임을 만들 수도 있지만, 여기서는 이미 작성된 데이터를 불러오는 것으로 하겠다.
read_xxx
import pandas as pd
file_address = '{파일 디렉토리}'
df = pd.read_csv(file_address)
df2 = pd.read_excel(file_address2)위와 같은 방식으로 불러온 데이터프레임을 'df'라는 변수에 넣었다.
이후 df.(메서드) 형태로 복잡한 함수나 알고리즘 없이 원하는 결과를 얻어낼 수 있다.
파일 저장하기
# CSV 파일
import pandas as pd
data = {
'Name': ['John', 'Emily', 'Michael'],
'Age': [30, 25, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
excel_file_path = '(파일 경로)/(파일명).csv'
df.to_csv(excel_file_path, index = False)
# index : 틀 고정 행/열의 존재 유무
print("csv 파일이 생성되었습니다.")# Excel 파일
import pandas as pd
data = {
'Name': ['John', 'Emily', 'Michael'],
'Age': [30, 25, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
excel_file_path = '(파일 경로)/(파일명).xlsx'
df.to_excel(excel_file_path, index = False)
print("Excel 파일이 생성되었습니다.")테이블(데이터) 확인하기
테이블을 출력하는 방법은 크게 3가지가 있다.
1. 테이블을 담은 변수명으로 테이블 1개 출력
2. display() 함수를 사용해 n개 테이블 출력
3. head(), tail() 함수를 사용해 상단/하단 5개 출력
# 그냥 테이블명으로 호출
# 테이블 1개만 호출할 때 사용 가능
df
# display 함수 사용
display(df)
# 여러 테이블 동시에 호출 가능
# display(df, df2, df3)
# 처음 5줄만 출력
df.head()
# 마지막 5줄만 출력
df.tail()
테이블 정보 관련
테이블 행 길이 (가로) 확인
len(df)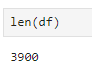
테이블의 행/열 개수
df.shape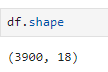
테이블 내 컬럼 타입 확인
df.dtypes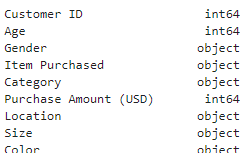
컬럼 타입 변환
df['Previous Purchases'] = df['Previous Purchases'].astype(str)
df['Previous Purchases'].dtype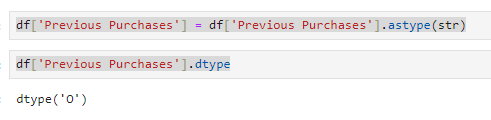
int64 -> object로 변경되었음
테이블 내 컬럼 확인
df.columns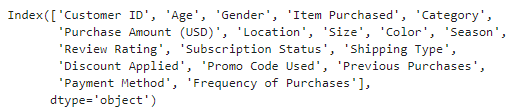
df.columns = ['고객 ID', '나이', '성별', ...]
같은 식으로 컬럼명을 변경할 수 있다.
또는
df = df.rename(columns = {'Customer ID': '고객 ID', 'Age': '나이', ...})
같은 방식으로도 컬럼명 변경이 가능하다
테이블 내 값들 배열 형태 확인
df.values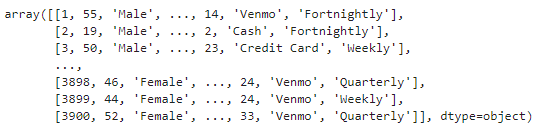
테이블 기본 구조 개괄
df.info()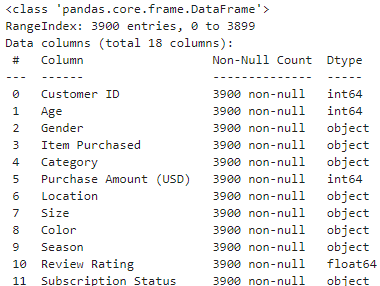
전체 행 개수, 평균, 표준편차, 최소최대, 사분위
df.describe()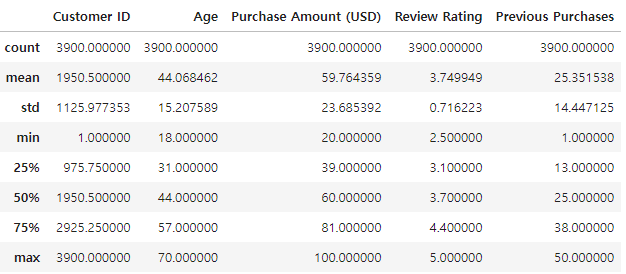
컬럼별 결측치 여부 (각각 값에 대해, 한 눈에)
# 개별 값
df.isnull()
#df.isna()
# 한 눈에
df.isnull().sum()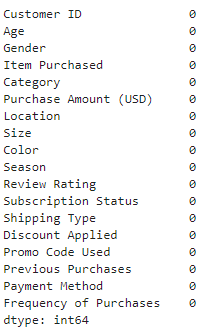
# 'Category' 컬럼에 NaN값이 있는 데이터 행(row)만 가져오기
df[df['Category'].isna()]
NaN이 없기 때문에 출력되는 값이 없는 상황
컬럼 가져오기
컬럼명이 'Category'라면,
# 속성을 사용
df.Category# [] 연산자 사용
df['Category']# iloc 사용
df.iloc[:, 4]
# , 앞은 가져올 row의 인덱스 / 뒤는 가져올 컬럼의 인덱스
# :에 숫자를 입력한다면 range와 마찬가지로 start_num은 그 숫자부터, end_num은 +1을 해줘야 한다
df.iloc[1:10,4]
# 4번 컬럼의 1번 ~ 9(+1)번 row를 불러오겠다
컬럼 버리기/삭제하기
https://velog.io/@langceo/Python-DataFrameby-pandas-column-row-삭제-방법
위의 글에 따로 나누어 정리했다.
조건에 부합하는 데이터 가져오기
1) 조건을 만족하는 행은 그대로, 만족하지 않는 행은 NaN으로 반환
df.where(df['Category']=='Footwear')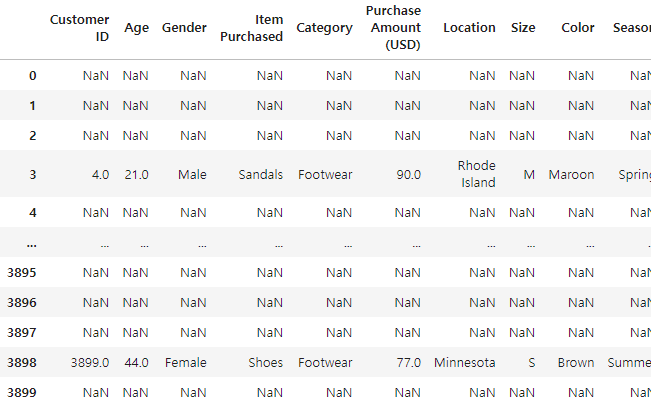
2) 조건을 만족하는 데이터만 슬라이싱
&는 모든 조건이 참이 되어야 True, |는 한 가지 조건만 참이 되어도 True
loc를 활용하는 방식
df.loc[df['size'] > 3, 'tip':'smoker']
조건을 .isin() 메서드로 거는 방식
아래 예시는 size가 (1, 2)에 있다면 True가 되어 반환하는 방식
df.loc[df['size'].isin([1, 2])]
복수 조건을 걸 때도 다 [] 안에 넣어주면 된다.
다만 이 때 코드를 깔끔하게 쓰기 위해서 변수를 활용할 수 있다.
cond1 = df['size'] >=3
cond2 = df['tip'] < 2
df[cond1 & cond2]
이를 확장하면, mask를 사용하는 방식이 있다 (컬럼명이 반드시 mask일 필요는 없음)
mask = ((df['Category'] == 'Footwear') & (df['Purchase Amount (USD)'] >= 80))
df[mask]
mask = ((df['Category'] == 'Footwear') | (df['Purchase Amount (USD)'] >= 90))
df[mask]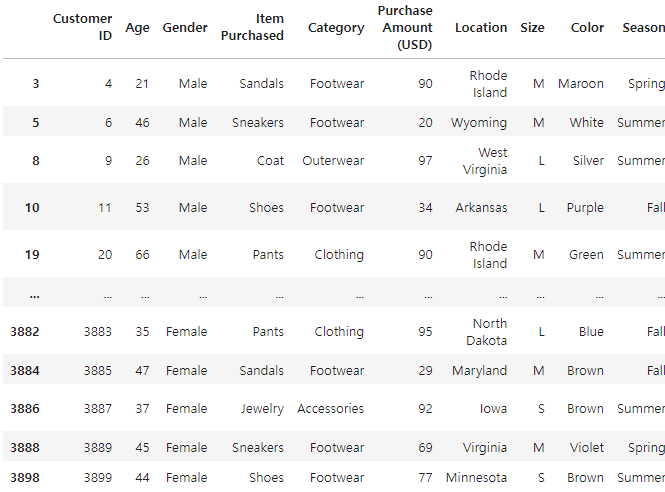
3) 불리언 슬라이싱
df[조건문] 형태로 [] 안에 조건을 적으면 그 조건이 True인 값들만 가져온다
단일 조건
아래 예시의 경우 df['sex']=='Male'이라는 조건을 만족하는 값들에 대해
이걸 다시 df에 넣어서, 그 값들이 있는 경우만을 가져오는 방식이다
df[df['sex']=='Male']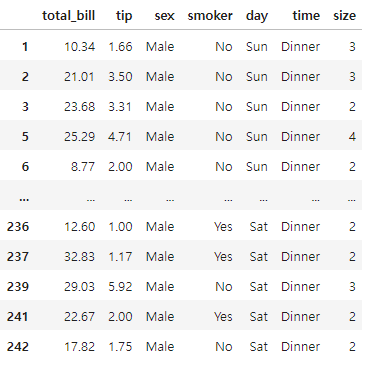
복수 조건
df[(df['sex']=='Male') & (df['smoker'] == 'Yes')]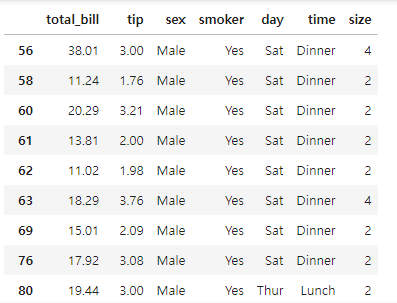
데이터 그루핑
단일 기준
groupby 메서드를 사용해 SQL의 집계함수를 재현할 수 있다.
df.groupby('Category')['Customer ID'].count()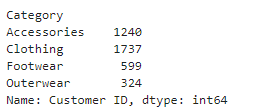
df.groupby('Category')['Purchase Amount (USD)'].sum()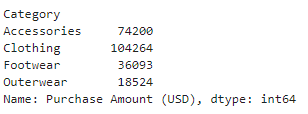
이때 만약 .count(), .sum(), .mean() 등 집계함수를 안 쓰고 df.groupby('Category')['Customer ID']만 작성한다면 object가 형성되었다는 것을 알리는 안내만 뜬다.
복수 기준
이 메서드에서 뿐 아니라 pandas를 하면서 공통적인 포인트인데,
1개 컬럼은 시리즈로 인식이 가능하지만, 2개 이상이 되면 반드시 데이터프레임(테이블 형태)로만 인식할 수 있다.
그래서 []로 컬럼들을 한 번 더 묶어주어야 한다.
df.groupby(['Category','Location'])['Customer ID'].count()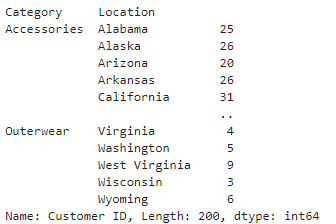
count()와 unique()
df.groupby('Category')['Location'].count()
.unique()는 중복을 제거해준다
df.groupby('Category')['Location'].unique()
번외. unique()에 count()를 하면 단순히 groupby 기준에 대해 count()를 진행한다. 그룹별로 개별 count()를 구해주는 게 아니다.
df.groupby('Category')['Location'].unique().count()
그 외
줄바꿈 \
줄바꿈은 \를 통해 할 수 있다
df[(df['sex']=='Male') \
& (df['smoker'] == 'Yes')](참고)
