
Intro
일정관리 및 계획의 중요성
Spring Boot 프로젝트를 통한 애플리케이션 개발에 대한 공부를 하다가 클라우드를 접하게 되니 배워야할 CS 지식의 양이 더욱 많아 진 것 같다.
얘를 들어 개발 트렌드가 꾸준히 바뀌면서 MSA가 등장하였고 그에 따라 애플리케이션을 작은 단위로 쪼개지는 것을 권장하는 시대가 왔는데 이 MSA라는 내용 안에서 알고 배우고 이해해야 할 것이 너무나도 많게 느껴졌다.
한정된 시간에 많은 내용들을 병행하여 공부해야 한다는 것이 큰 압박감으로 다가왔지만 조급하게 그저 되는대로 넘어가는 것이 아니라 하나라도 확실히 짚고 넘어가기로 각오하게되었다.
이 때, 학습계획의 중요성을 다시 한번 알게되었고, 나의 일정을 관리한다는 것이 얼마나 대단한 것인지 느끼게되었다. 그래서 한 주간의 큰 범주의 계획을 세우고 그 안에서 일 단위의 세부적인 계획을 세우려고 하니 꽤나 시간이 오래 걸렸다.
이전에는 즉흥적으로 공부하고 개발하는 일정으로 인해 제대로 된 성과가 없었다. 그러나 앞으로는 계획한 일정을 실행만 한다면 정해진 산출물은 무조건 나오기 때문에 오히려 단순해졌다.
개발할 때도 그렇고 매사에 계획을 세우고 계획대로 실행한다면 그에 따른 계획에 없던 플러스요인을 추가로 실행할 수도 있을 거라는 기대도 하게 되었다. 앞으로 계획을 잘 세우고 게획을 잘 실천할 수 있도록 일정 관리를 소홀히 하면 안되겠다고 다짐했다.
Day - 66
AWS VPC(Virtual Private Cloud)에 대해서
AWS에서 EC2 인스턴스를 생성할 때 VPC를 반드시 설정하라고 하는데, 그떄마다 기본적으로 사용할 수 있는 default VPC를 이용했었지, VPC를 사용할 생각은 하지 못했었다. 이번에 AWS VPC를 배우게 되면서 VPC를 직접 만들기도 하고 VPC 내부에 EC2 인스턴스를 생성해보기도 하였다. 그런데 아직 VPC가 무엇인지 잘 이해가 되질 않아 VPC에 대해서 알아보려고 한다.
VPC는 Virtual Private Cloud의 줄임말로, 일종의 독립적인 가상의 네트워크 공간이라고 보면 된다. 자체 데이터 센터에서 운영하는 기존 네트워크와 아주 유사한 가상 네트워크이다. VPC를 이용하면 직접 원하는대로 IP 주소 범위 선택, 서브넷 생성, 라우팅 테이블 및 네트워크 게이트웨이 구성 등 가상 네트워크 환경을 구성할 수 있다. 즉, VPC는 AWS에서 사용할 수 있는 나만의 개인 네트워크라고 볼 수 있다.
AWS VPC 문서를 살펴보면 VPC는 AWS 클라우드에서 다른 가상 네트워크와 논리적으로 분리되어 있으며, VPC의 IP 주소 범위를 지정하고 서브넷과 게이트웨이를 추가하고 보안 그룹을 연결할 수 있다고 한다.
여기서 서브넷이란 무엇일까? 서브넷은 VPC의 IP 주소 범위이다. EC2 인스턴스와 같은 AWS 리소스를 서브넷으로 실행할 수 있고, 서브넷을 인터넷, 다른 VPC 및 자체 데이터 센터에 연결하고 라우팅 테이블을 사용하여 서브넷으로/서브넷에서 트래픽을 라우팅할 수 있다.
VPC는 AWS에서는 각각의 Region마다 하나씩 설정할 수 있고, RFC1918이라는 사설 IP 대역 기준을 지키도록 권장하고 있다. 또한 IP주소는 연결 불가능한 네트워크와 중복되지 않으며 최초 연결 이후 수정이 불가하다는 특징이 있다.
VPC에서 사용하는 사설 IP 대역은 아래와 같다.
- 10.0.0.0/8: 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0/12: 172.16.0.0 ~ 172.31.255.255
- 192.168.0.0/16: 192.168.0.0 ~ 192.168.255.255
VPC의 구성요소 및 구체적인 특징에 대해서는 공식문서나 다른 분들의 글에서 충분히 찾아 쓸 수 있으니 VPC가 무엇인지 정도만 알아두고 조금씩 공부해나가려고 한다.
Day - 67
Spring Boot Application 시작 시에 관련된 테이블을 Create하는 것이 맞을까? 아니면 별도의 DDL문을 직접 만들어 관리하는 것이 맞을까?
앞서 공부한대로 ddl-auto 옵션을 create, create-drop, update 등으로 두고 사용한다면 데이터를 유실할 수 있어 위험하다. ddl-auto 옵션이 위험한 이유는 14번째 회고록의 내용을 참고하자.
여튼 ddl-auto 옵션을 이용한 테이블 생성은 하지 않기로 하였으니, Spring Boot Project에서 설계한 Entity와 매핑되는 테이블 DDL 구문을 설계을 별도로 설계하여 사용하도록 하자.
Spring Security에서 Deprecated된 Websecurityconfigureradapter는 어떻게 대체할까?
사이드 프로젝트를 진행하면서 Spring Security를 설정하여 사용자 관련 로그인 처리를 진행하던 중 WebSecurityConfigurerAdapter가 Deprecated 되었다는 것을 알게 되었다.
WebSecurityConfigurerAdapter 클래스란?
WebSecurityConfigurerAdapter 클래스는 웹 애플리케이션의 보안을 구성하기 위해서 Spring Security에서 제공하는 클래스이다. WebSecurityConfigurerAdapter는 다양한 기본 보안 구성을 제공하는 추상 클래스이며, 이를 확장하여 사용자 정의 보안 구성을 제공할 수 있다. 양식 기반 인증을 설정하고, 보호되는 URL 패턴을 구성하고, 권한 부여 규칙을 정의하는 등의 역할을 수행한다.
하지만 Spring Security 5.3 버전 이후부터 Deprecated 되어 사용하지 않도록 하고 있으며, 대신에 WebSecurityConfigurer 인터페이스를 사용하거나 상속하지 않은채 모두 빈으로 등록하여 사용하는 방법들을 권장하고 있다.
스프링 시큐리티에서 WebSecurityConfigurerAdapter를 대체하기 위해 권장되는 접근 방식은 WebSecurityConfigurer 인터페이스를 사용하는 것이라는데, WebSecurityConfigurer 인터페이스는 더 이상 사용되지 않는 WebSecurityConfigurerAdapter 클래스에 비해 웹 애플리케이션에 대한 보안을 구성하는 더 유연하고 포괄적인 방법을 제공한다.
하지만 사용자 계정을 데이터베이스에 저장하지 않고 메모리에서 관리하기 위해 경우에 따라 InMemoryUserDetailsManager 빈을 등록하여 사용해야 할 수도 있다. 예를 들어 사용자 수가 적고 재시작 시에도 사용자 데이터를 유지할 필요가 없는 경우 InMemoryUserDetailsManager를 사용하여 사용자 계정을 메모리에 저장할 수 있다.
InMemoryUserDetailsManager는 UserDetailsManager 인터페이스의 구현체이다. 사용자 인증 및 권한 부여 정보를 위한 인메모리 저장소를 제공한다.
WebSecurityConfigurer 인터페이스란?
WebSecurityConfigurer 인터페이스는 Spring Security에서 웹 애플리케이션의 보안을 구성하는 여러 방법을 제공하는 인터페이스입니다. 이 인터페이스는 앞서 말했던 WebSecurityConfigurerAdapter 클래스를 대체하기 위해 도입되었다.
WebSecurityConfigurer 인터페이스는 configure(HttpSecurity http) 및 configure(WebSecurity web)의 두 가지 메서드를 정의한다.
configure(HttpSecurity http) 메서드는 권한 부여 규칙 및 인증 메커니즘을 구성하는 데 사용되며, configure(WebSecurity web) 메서드는 URL 패턴 및 전역 보안 설정을 구성하는 데 사용된다.
chatGPT에게 WebSecurityConfigurer를 사용하는 예시를 부탁해보았다.
@Configuration
@EnableWebSecurity
public class SecurityConfig implements WebSecurityConfigurer {
@Override
public void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.anyRequest().authenticated()
.and()
.formLogin();
}
@Override
public void configure(WebSecurity web) throws Exception {
web
.ignoring()
.antMatchers("/resources/**");
}
}위 코드와 같이 WebSecurityConfigurerAdapter를 사용하지 않고 WebSecurityConfigurer 인터페이스를 구현하여 필요한 메서드를 재정의하는 샘플 코드를 볼 수 있었다.
Spring Security를 사용하면서 사용하는 Spring Boot 프로젝트의 버전과 관련하여 호환되는 기능들을 유심히 살펴보고 사용해야 함을 몸소 알게 되었다.
Day - 68
@Builder 어노테이션이 붙은 생성자에서 기본 키를 가지는 필드를 포함시켜도 될까?
@Id, @GeneratedValue 어노테이션이 붙은 기본 키를 가지는 필드의 경우 데이터베이스에서 자동으로 생성해주게 된다.
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;스프링에서는 위와 같이 id라는 필드에 @Id, @GeneratedValue 어노테이션을 붙여서 기본 키로 사용할 필드임을 명시한다.
이 때, @GeneratedValue 어노테이션에 GenerationType.IDENTITY)이라는 속성을 부여한다면 기본 키 생성전략을 연동한 데이터베이스에 위임하게 되어 별도로 id 필드의 값을 설정하지 않고 삽입하여도 데이터베이스에서 자동으로 생성해주는 것이다.
이러한 id와 같은 필드는 보통 Entity 클래스의 속성으로써 작성된다.
User.java
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private String email;
@Builder
public User(String name, String email) {
this.name = name;
this.email = email;
}
}User라는 엔티티 클래스를 보면 id라는 기본 키를 가지는 필드와 name, email 이라는 필드를 가지고 있다. 그리고 @Builder 어노테이션을 활용해 생성자를 명시하였다.
생성자에 id 필드가 포함되지 않은 이유는 앞에서 살펴보았듯이 기본 키 전략을 데이터베이스에게 위임하기로 설정되었기 때문이다. 만약 생성자에서 id 필드를 포함시킨다면 이후 생성자를 통해 실수로라도 id 필드의 값을 설정할 수 있게 되어 예기치 못한 예외가 발생할 수 있다.
그래서 기본 키는 항상 데이터베이스에서 관리할 수 있도록 해야 하기 때문에 생성자에서는 일반적으로 기본 키를 가지는 필드를 포함시키지 않도록 하는 것이 원칙이라고 볼 수 있다.
생성자에 기본 키 필드가 포함되어야 할 경우
그런데 연관관계가 맺어진 필드일 경우라면 어떨까?
예를 들어 User(사용자)와 Board(게시글), 그리고 Comment(댓글)이라는 Entity들이 있고 Comment 엔티티 클래스에는 Member와 Board 객체를 속성으로 가지고 있다.
이 때, 3번 게시글에 lango 라는 사용자가 댓글을 작성하는 요청이 있다고 가졍했을 때, Comment 객체를 만들 때 3번이라는 Board 게시글을 주입시켜서 만들어야 한다. 이 때 아래와 같이 Board Entity의 생성자에는 기본 키 필드가 포함되어 버린다.
Board board = Board.builder()
.boardId(dto.getBoardId()) // 생성자에 기본 키 필드가 포함되어 버림.
.build();결국 3번 게시글(Board)에 Comment(댓글)을 삽입해야 하기 때문에 Comment의 Board 속성에는 Board의 생성자에서 기본 키를 포함하여 생성한 Board를 주입해야 한다는 딜레마적인 상황이 발생한 것이다.
Comment comment = Comment.builder()
.board(board)
// 이하 생략3번 게시글이라는 정보를 가져와서 Board 객체를 만들 때 기본 키 값을 가져와서 만든다고 한다면 앞에서 살펴보았던 생성자에 기본 키 필드를 포함시키지 말자라는 룰을 어기는 셈이다. 이를 어떻게 해결할 수 있을까?
인스턴스를 만들 때 DB에서 검색하기
첫번째로 떠오른 대안은 객체의 인스턴스를 만들 때 생성자를 통해 만드는 것이 아닌 기존의 데이터를 가져와서 매핑하는 방법이다!
Optional<Board> board = boardRepository.findById(dto.getBoardId());위와 같이 JPA에서 제공하는 기본 메소드를 통해 기존에 존재하는 데이터를 가져와서 매핑하면 된다.
그러면 내가 의도한대로 Board의 기본 키 필드를 생성자에 포함시키지 않고도 특정 Board 객체를 가져올 수 있게 되는 것이다.
Optional<Board> board = boardRepository.findById(dto.getBoardId());
Comment comment = Comment.builder()
// 생략
.board(board.get())
.build();어떤 방식을 사용하든지 사용자의 몫이다.
이와 같은 이슈에 대해서 많은 문서를 찾아보고 chatGPT한테도 열심히 질문 세례를 퍼부어서 어느 정도 데이터를 취합할 수 있었다.
사실 앞서 본 것처럼 Board Entity에 @AllArgsConstructor 어노테이션을 붙이고, Comment를 삽입할 때 기본 키 필드로 생성하여 주입하여도 큰 문제는 없을 것으로 보인다.
다만, 현재 프로젝트에는 기본 키 생성전략을 GenerationType.IDENTITY 라고 정하여 데이터베이스에서 생성되도록 위임하였다. 그래서 기본 키 필드를 생성자에 포함시키는 것은 바람직하지 않다고 알고 있었고 이 원칙을 지키기 위해 해당 이슈를 다루게 된 것이다.
결국 어떤 접근 방식이 특정 사용 사례에 가장 적합한지 결정하는 것은 사용자의 몫이라는 것을 알게되었다.
해당 이슈는 혼자 결정할 사항이 아닌 것 같아 팀원들에게 이슈 공유 후 피드백을 받아 결정한 정책으로 적용할 예정이다.
Day - 69
ubuntu에서 Docker 파일 시스템과 유사한 파일 시스템 격리 환경을 구성하기
오늘부터 카카오 클라우드 플랫폼셀 리더님이 오셔서 특강을 진행한다. 클라우드와 클라우드 네이티브, 그리고 더 나아가 컨테이너란 무엇인지에 대해서 다루어 주셨고 수업 중 진행했던 실습을 진행하며 몰랐던 부분에 대해서 복습해보려 한다.
chroot라는 명령어를 이용하여 ubuntu 서버에서 Docker 컨테이너와 유사한 환경을 만들어보는 실습을 진행하였다. 실습은 Ubuntu 20.04 LTS 환경에서 debootstrap 패키지 설치한 후 진행하였다.
debootstrap 패키지는 초기 파일 시스템을 동적으로 구성하면서 추가적인 커스텀 패키지를 설치하는 등의 작업을 진행할 수 있는 패키지이다.
chroot 명령어란 무엇일까?
chroot는 change root의 약어로, 직역하면 root를 변경한다는 뜻이다. 단순히 root 계정을 변경하는 것이 아니라 Linux의 최상위 디렉토리, 즉 root(/) 디렉토리의 위치를 변경해주는 명령어라고 한다.
chroot는 1979년 Version 7 Unix에서 시스템콜로 처음 구현된 기능으로 벌써 40년이나 된 기능이라고 한다.
chroot 명령어의 경우 리눅스에 기본으로 설치가 되어 있기에 별도의 설치가 필요없다.
$ chroot --version
chroot (GNU coreutils) 8.30
Copyright (C) 2018 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <https://gnu.org/licenses/gpl.html>.
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.물론 간혹 설치가 안되어 있는 경우도 있을텐데 coreutils 패키지를 설치하면 chroot 명령어를 사용할 수 있다.
chroot 사용하기
chroot 명령어를 작성하는 형식을 보기 위해 chroot --help 명령어로 확인해보면 chroot의 형식은 다음과 같다.
Usage: chroot [OPTION] NEWROOT [COMMAND [ARG]...]chroot 뒤에 root 디렉터리로 사용할 디렉토리를 작성하고, 그 뒤에 앞엑서 지정한 디렉토리를 기반으로 실행할 애플리케이션의 경로를 작성하면 된다. 이 때, chroot는 root 권한을 필요로 하는 것을 참고하자.
이번 실습에서는 /var/chroot라는 디렉토리를 만들고 해당 디렉토리를 chroot를 통한 루트 파일 시스템으로 사용해보자.
$ sudo chroot /var/chroot /bin/bashchroot 환경에서 필요한 파일 시스템들을 마운트한 후 chroot 환경으로 들어가서 디렉토리 구조를 살펴보자.
/var/chroot/
├── bin -> usr/bin
├── boot
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── srv
├── sys
├── tmp
├── usr
└── var/var/chroot 디렉토리 내에 ubuntu의 루트 디렉토리와 동일한 파일들이 존재하는 것을 확인할 수 있다. 그리고 chroot 환경에서 파일 시스템 여부를 확인하기 위해 테스트로 a.txt 라는 파일을 생성하고 확인해보자.
touch a.txt
ls -alchroot 환경 안에서 a.txt 라는 파일이 정상적으로 존재함을 확인했다면 chroot에서 벗어나 호스트 서버 단에서 a.txt 파일의 여부를 확인해보자.
ls -al /var/chroot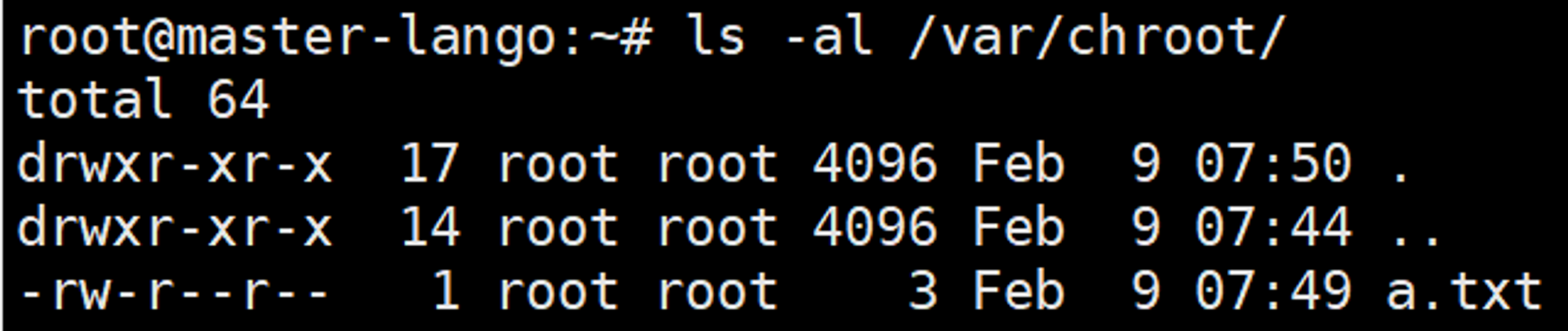
다음과 같이 chroot 환경 내에서 만든 파일을 호스트 단에서도 확인할 수 있었다.
이번 실습에서는 chroot 명령을 이용해서 Docker 컨테이너와 유사한 파일 시스템 환경을 만들어 보았다. 물론 실제 Docker 컨테이너와 동일한 수준은 아니지만 컨테이너의 파일 시스템 원리를 간단하게 알아 볼 수 있었던 것 같다.
Day - 70
Docekr 컨테이너를 통해 파일시스템 가상화 격리 여부를 확인하기
앞서 chroot를 통해서 Docker 환경과 유사한 격리 구조를 살펴볼 수 있었다. 이어서 Docker 환경을 통해서 파일 시스템의 격리 구조를 살펴보는 실습을 진행하였다.
그런데 Docker의 파일 시스템을 통해 어떤 결과가 나오는지 정도만 알고 있지, Docker의 파일 시스템 구조가 어떻게 구성되었는지는 전혀 모르고 있어서 이번 기회에 공부해보려 한다.
Docker의 파일시스템은?
Docker의 파일 시스템은 Union File System(UFS) 기술을 사용하는데, 이 기술을 통해, 레이어를 결합하여 하나의 파일 시스템처럼 보이게 할 수 있다. 이렇게 결합된 파일 시스템을 "Merged File System"이라고 부른다.
Union File System(UFS)의 종류
LowerDir
유니온 파일 시스템의 하위 계층으로, 컨테이너의 읽기 전용 이미지 파일 시스템을 포함한다. 또한, 이 계층은 컨테이너의 기본 파일 시스템을 제공하며 이미지에 정의된 모든 파일과 디렉터리를 포함한다.
UpperDir
유니온 파일 시스템의 상위 계층으로, LowerDir 위에 읽기-쓰기 계층으로 마운트된다. 이 계층은 파일 시스템에 파일을 쓸 수 있는 기능을 제공하며 일반적으로 컨테이너가 파일 시스템에 변경한 내용을 저장하는 데 사용된다.
MergedDir
LowerDir과 UpperDir의 통합된 보기이며 컨테이너에 표시되는 파일 시스템이다. 읽기 전용 이미지 파일 시스템과 호스트에서 제공하는 읽기-쓰기 파일 시스템을 결합하여 컨테이너에 단일 통합 파일 시스템을 제공한다. 컨테이너에서 파일 시스템에 대한 모든 변경 사항은 UpperDir에 기록되며, 이러한 변경 사항은 MergedDir에서 볼 수 있다.
간단히 세 계층 구조를 정리하자면 LowerDir는 컨테이너의 기본 이미지 원본이 포함된 파일 시스템을 제공하고, UpperDir는 컨테이너를 실행 한 후의 변경점, 즉 파일시스템에 대한 쓰기기능을 제공하며, MergedDir는 LowerDir, UpperDir을 모두 합친 통합 보기 기능을 제공한다고 볼 수 있다.
이와 같이 Docker 컨테이너에서 파일시스템의 가상화 및 격리 구조는 UFS 계층 구조를 살펴보면 되는데, 결국 MergedDir 계층은 컨테이너 파일시스템의 실체라고 볼 수 있다.
실습하기
위에서 살펴본 Docker 컨테이너의 파일 시스템 구조를 살펴보기 위해 간단하게 Docker 컨테이너를 실행하여 파일을 만들어보자.
먼저 우분투 이미지로 도커 컨테이너를 실행하여 컨테이너 내부로 접속해보자.
docker run -it ubuntu bash컨테이너가 정상적으로 생성되고 실행되어 내부로 접속되었다면 테스트해볼 파일을 하나 생성하자.
touch a.txt파일을 생성했다면 exit 명령어로 컨테이너를 종료하고 호스트에서 생성한 a.txt 파일의 여부를 MergedDir에서 확인해보자.
먼저 MergedDir의 경로를 알려면 앞서 종료한 우분투 컨테이너의 상세정보를 확인해야 한다. 이는 docker inspect 명령어를 통해 쉽게 찾을 수 있다.
docker inpect [컨테이너 ID] | grep DIrgrep한 결과로 LowerDir, UpperDir, MergedDir의 경로를 확인할 수 있을 것이다. MergedDir 디렉토리에 a.txt 파일이 있는지 확인해보자.
ls -al /var/lib/docker/overlay2/[해당 컨테이너 경로]/merged그런데 merged 디렉토리를 찾을 수 없었고, upperDir인 diff 디렉토리에만 a.txt 파일이 존재함을 확인할 수 있었다.

MergedDir는 LowerDir과 UpperDir의 병합본을 가지기 때문에 컨테이너를 실행하고 a.txt 파일을 만들었다면 upperDir에만 존재하는 것이 아니라 MergedDir에도 존재해야 한다.
그런데 왜 MergedDir에는 해당 파일도 없고 MergedDir 디렉토리 조차 없는 것일까?
궁금해서 요즘 애용하고 있는 chatGPT에게 도움을 받았다.

그리고 이 문제의 원인을 찾아낼 수 있었는데, 그 것은 바로 Docker 컨테이너를 종료했다는 것이다.
UFS에서 UpperDir은 컨테이너에서 변경한 모든 사항을 저장하며 MergedDir는 UpperDir와 LowerDir를 합친 결과를 나타낸다. 그런데, 컨테이너가 종료되면 컨테이너에서의 모든 변경사항은 삭제된다. 즉 MergedDir에 변경점이 삭제되기 때문에 a.txt 파일이 존재하지 않을 수 있다는 것이다.
그래서 이를 확인하기 위해 컨테이너를 실행한 후a.txt 파일을 생성한 뒤 컨테이너를 종료하지 않고 새로운 세션에서 컨테이너 파일 시스템의 MergedDir를 살펴보니 신기하게도 merged 디렉토리 안에 a.txt 파일을 확인할 수 있었다.
이번 실습을 통해 Docker 컨테이너의 파일시스템 격리여부를 알아볼 수 있었고, UFS의 LowerDir, UpperDir, MergedDir 계층 구조를 통해서 컨테이너의 실행 여부가 이와 같은 파일시스템에 어떤 영향을 주는지 어느 정도 알 수 있었다.
Final..
클라우드에 대해 많은 지식과 기술적 내용을 배우면서 클라우드 및 네트워크 CS 지식의 필요성을 느끼게 되었다. 더군다나 쿠버네티스의 계층 구조에 대해서도 머릿속으로 윤곽이 잡히지 않아 강사님에게 몰랐거나 이해가 안되는 내용에 대한 질문을 많이 드린것 같다. 물론 개떡같은 질문에 찰떡같은 대답으로 이해시켜주셨다.
현재는 소프트웨어 애플리케이션 백엔드 개발에 힘을 많이 쏟고 있지만 내가 만든 애플리케이션을 클라우드 위에서 다양한 조건을 통해 동작시키기 위해선 클라우드를 잘 알아야겠다는 생각을 자주 하게된다.
지금 클라우드 스터디가 필요한 부분은 CI/CD 파이프라인을 구축하여 통합테스트 및 배포에 대한 공부가 필요하고, 쿠버네티스의 전반적인 이해도를 상승시켜야 한다.
클라우드 교육기간동안 애플리케이션 개발뿐만 아니라 클라우드 및 클라우드 서비스에 대한 이해도를 높이도록 노력하자!
혹여 잘못된 내용이 있다면 지적해주시면 정정하도록 하겠습니다.게시물과 관련된 소스코드는 Github Repository에서 확인할 수 있습니다.
참고자료 출처
