
Intro
좋은 팀 환경을 꾸리고 가꾸는 것은?
파이널 프로젝트를 진행하면서 팀 리드의 역할을 수행하던 중 팀원들에게 부탁하는 것을 꺼려하는 나의 모습을 발견하게 되었다.
팀 프로젝트의 진도를 빼려면 코어 타임 외에도 각자의 노력이 필요한 상황이 자주 있을 텐데, 은연중에 아직 기획 단계이니까..., 아직 설계 전이니까..., 내가 다 알고 있으니 내가 하는게 편하지... 라는 생각을 가졌던 것 같다.
이런 생각이 들자마자 아차! 싶었다. 내가 뭐라도 되는 사람도 아니고, 현업 개발자도 아닐 뿐더러 같은 입장의 교육생일 뿐인데.. 자만하고 마음대로 판단했던 것일까?
이 때, XL8 프론트엔드 팀 리드이신 배휘동님의 글을 보고 훌륭한 팀들은 가지는 특징에 무엇들이 있는지 살펴보았다. 팀 리더십, 상호 성과 모니터링, 백업 행동, 적응 능력, 팀 지향 태도라는 5가지 역량을 통해 팀 구성원 서로서로가 시너지를 낼 수 있다는 내용이 인상이 깊었다.
결국 팀 구성원 모두가 서로에게 동기를 부여하는 방식으로 각자의 개인 목표뿐만 아니라 팀 목표를 이루는 데 큰 영향을 줄 수 있다는 것이다.
사실 프로젝트를 시작한지는 얼마 되지 않았지만, 어떻게 하면 좋은 프로젝트, 좋은 결과물, 좋은 코드를 개발할 수 있는지에 집중했었지, 협업 동료들의 생각이나 목표에 대해서는 진중하게 귀기울이지 못했다.
앞으로 프로젝트를 진행하면서 임할 자세를 고쳐 먹기로 하였다. 바로 겸손한 자세를 갖추고, 팀원들의 수준과 상태를 명확하게 파악하고, 지속적으로 피드백을 주고받도록 말이다.
Week 18
카카오 클라우드 스쿨 18주차 81~85일까지의 공부하고 고민했던 흔적들을 기록하였습니다.
Jenkins Container에서 Github Repository의 manifest file push하기
Jenkins 컨테이너를 통해 CI 작업을 진행하고 CD를 위해 k8s manifest 파일이 존재하는 Github 저장소로 SSH를 통해 Deployment Object 파일을 수정하여 Push 하도록 Jenkinsfile을 구성하였다.
의도한대로 파이프라인에서 k8s manifest 저장소로 push할 때 manifest 파일을 수정한 후 push될 줄 알았지만, push 내역에 manifest 파일이 포함되지 않아 CD 작업이 이루어지지 않았다.
그래서 Jenkins의 빌드 로그를 살펴보니 변경된 내역이 전혀 없다고 출력되었다.
Jenkins Build Log - fail
+ sed -i s@startdreamteam/spring-test:.*@startdreamteam/spring-test:17@g deploy/deploy.yml
[Pipeline] sh
+ git add deploy/deploy.yml
[Pipeline] sh
+ git commit -m fix:startdreamteam/spring-test 17 image versioning
On branch main
nothing to commit, working tree clean
Post stage
[Pipeline] echo
Container Deploy failuredeploy/deploy.yml 파일이 변경내역에 없다는 것은 sed 명령을 통한 파일 수정이 이루어지지 않은 것인지, 아니면 다른 이유에선지를 정확하게 알 수 없었다.
내가 작성한 Jenkinsfile은 다음과 같다.
stage('k8s manifest file update') {
steps {
git credentialsId: githubCredential,
url: k8sGitHttpAddress,
branch: 'main'
sh "git config --global user.email ${gitEmail}"
sh "git config --global user.name ${gitName}"
sh "sed -i 's@${dockerHubRegistry}:.*@${dockerHubRegistry}:${currentBuild.number}@g' deploy/deploy.yml"
sh "git add deploy/deploy.yml"
sh "git commit -m 'fix:${dockerHubRegistry} ${currentBuild.number} image versioning'"
sh "git branch -M main"
sh "git remote remove origin"
sh "git remote add origin ${k8sGitSshAddress}"
sh "git push -u origin main"
}
post {
failure {
echo 'Container Deploy failure'
}
success {
echo 'Container Deploy success'
}
}
}Jenkinsfile에서 sed -i 명령을 통해 deploy/deploy.yml 파일을 수정하고 git add deploy/deploy.yml 구문을 통해 변경내역을 git stage에 올렸을 것이라 생각했지만 그러지 못한 것이다.
manifest 파일에 실행 권한을 부여하기
찾아보니 git은 파일 내용이 수정되었더라도 실행 권한이 변경된 파일만을 추적한다고 한다. 결국 파일에 대한 실행권한이 없다면 파일 내용이 변경되어도 변경내역에 반영할 수 없다는 것이다.
그래서 deploy/deploy.yml 파일에 실행 권한을 추가하는 chmod +x 명령어를 실행하면, 해당 파일의 실행 권한이 변경되므로 git에서 이 파일이 수정된 것으로 인식하지 않을까 생각하게 되었다.
Jenkinsfile에 deploy/deploy.yml 파일에 실행권한을 추가하는 구문을 추가하였다.
stage('k8s manifest file update') {
steps {
...
sh "sed -i 's@${dockerHubRegistry}:.*@${dockerHubRegistry}:${currentBuild.number}@g' deploy/deploy.yml"
sh "chmod +x deploy/deploy.yml"
sh "git add deploy/deploy.yml"
...
}그러고 다시 Jenkins에서 빌드를 실행하니 정상적으로 push가 됨을 알 수 있었다.
Jenkins Build Log - success
+ sed -i s@startdreamteam/spring-test:.*@startdreamteam/spring-test:19@g deploy/deploy.yml
[Pipeline] sh
+ chmod +x deploy/deploy.yml
[Pipeline] sh
+ git add deploy/deploy.yml
[Pipeline] sh
+ git status
On branch main
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: deploy/deploy.yml
[Pipeline] sh
+ git commit -m fix:startdreamteam/spring-test 19 image versioning
[main b85528c] fix:startdreamteam/spring-test 19 image versioning
1 file changed, 1 insertion(+), 1 deletion(-)
[Pipeline] sh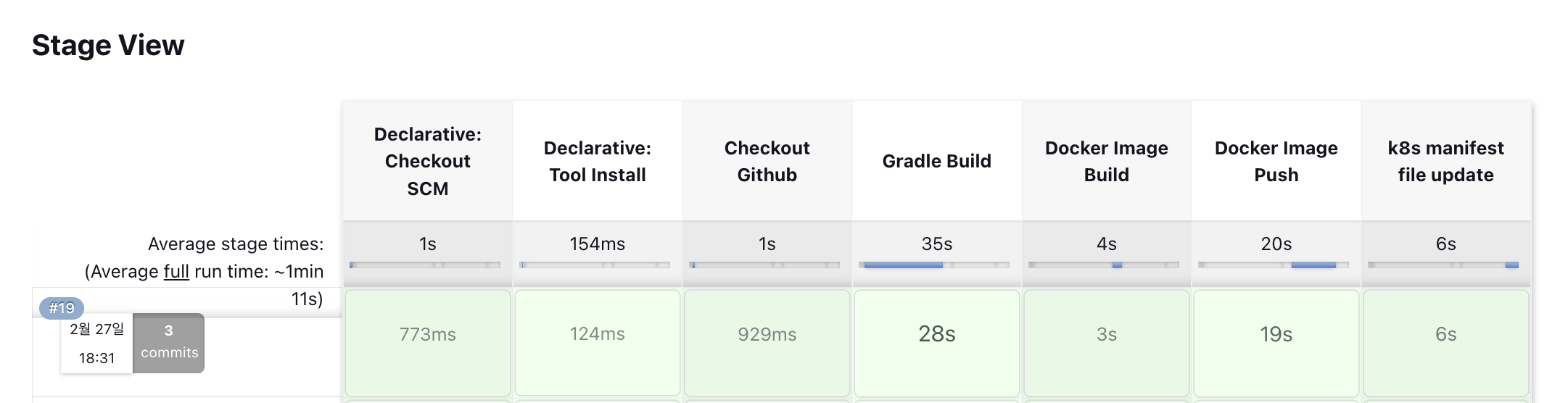
위와 같이 Jenkins에서의 파이프라인 내역이 모두 성공하여 k8s manifest 저장소로의 git push까지 정상적으로 이루어짐을 확인할 수 있었다.
EKS Cluster의 Deployment를 외부로 서비스하기 위한 Service 설정하기
EKS에서 Deployment를 외부로 서비스하기 위해서는 Kubernetes Service가 필요하다.
물론 Service 없이 Deployment의 Pod에 직접 접근할 수는 있다. Deployment에서 생성된 파드는 EKS 클러스터의 내부 IP 주소를 가지고 있기 때문에 이 IP 주소를 가지고 클러스터 내부에서는 접근이 가능하다. 하지만, 클러스터 외부에서는 접근할 수 없다.
따라서, 클러스터 외부에서 Deployment의 파드에 접근하려면, AWS Elastic Load Balancer 또는 Ingress와 같은 로드 밸런싱 서비스를 사용하여 클러스터 내부 IP 주소와 로드 밸런서를 연결해야 한다.
결국 이를 위해서는 Kubernetes에서 Service 리소스를 사용해야 한다.
Kubernates에서 Service가 하는 역할은?
Service는 파드의 클러스터 내부 IP 주소와 로드 밸런서를 연결하고, 로드 밸런서를 통해 외부 트래픽을 분산시켜준다. 이를 통해 우리는 외부에서 클러스터 내부의 파드로 안전하게 접근할 수 있게 되는 것이다.
그래서 Service를 사용한다면, 외부에서 Deployment의 파드에 직접 접근하는 것보다 더욱 안전하고 효율적으로 접근을 할 수 있다.
여기서 Deployment란 Kubernetes에서 애플리케이션을 배포하고 업데이트하는 데 사용되는 리소스이다. Deployment는 파드(Pod)를 실행하고 관리하며, 파드 실행에 실패할 경우 파드를 자동으로 복구시킨다.
Service의 유형에는 무엇이 있나?
Service는 노출(Named)된 서비스에 대한 접근을 제공하며, 파드를 실행하고 있는 Kubernetes 클러스터 내부와 외부 모두에서 사용할 수 있다.
이 때, Service를 외부로 서비스할 수 있는 방법은 다음과 같은 것들이 있다.
-
ClusterIP: 기본적으로 사용되는 Service 유형이며, 파드가 클러스터 내에서만 접근할 수 있도록 제한한다.
-
NodePort: 클러스터 외부에서 접근 가능한 포트를 노출한다. NodePort Service를 사용하면, 로드 밸런서 없이 클러스터 외부에서 파드에 직접 접근할 수 있다.
-
LoadBalancer: 클라우드 업체에서 제공하는 로드 밸런서를 생성하고, 해당 로드 밸런서의 IP 주소를 할당해준다. 로드 밸런서를 사용한다면 클러스터 외부에서 파드에 접근할 수 있다.
-
ExternalName: 외부 서비스를 Kubernetes 내부에서 참조할 수 있도록 DNS 이름을 매핑한다. 그러면 해당 Service는 클러스터 외부 리소스에 대한 연결을 허용하게 된다.
-
Headless: Headless 유형의 Service는 클러스터 내부에서 파드를 직접 접근할 수 있도록 허용하며, 클러스터 내부 DNS 서버에서 직접 파드 IP 주소를 반환한다.
이외에도, Ingress와 같은 리소스를 사용하여 더 복잡한 로드 밸런싱 구성을 만들 수 있다.
따라서, EKS 클러스터에서 Deployment를 외부로 서비스하기 위해서는 해당 Deployment에 대한 Service를 만들어야 한다. 해당 Service를 통해 외부에서 접근할 수 있도록 설정하고, 로드 밸런서 등을 구성하여 필요한 트래픽을 분산시킬 수 있다.
Service의 유형을 로드밸런서로 사용한다면?
Deployment를 로드밸런서 타입의 Service로 사용했을 때 어떤 장점이 있을까? 이를 확장성, 안정성, 효율성, 유연성, 보안성 측면에서 살펴보려 한다.
-
확장성: 로드 밸런서를 사용하면 다수의 파드 인스턴스를 실행하고, 자동으로 로드 밸런싱을 수행할 수 있다. 이를 통해, 서비스의 확장성을 높일 수 있다. -
안정성: 로드 밸런서는 다수의 파드 인스턴스 사이에서 트래픽을 분산시키고, 각 인스턴스의 상태를 모니터링할 수 있다. 이를 통해, 단일 파드 인스턴스의 장애가 전체 서비스에 영향을 미치지 않도록 보장할 수 있다. -
효율성: 로드 밸런서는 트래픽을 처리하는 데 있어서 최적화된 알고리즘을 사용하여 처리 속도를 높일 수 있다. -
유연성: 로드 밸런서는 다양한 프로토콜과 포트를 지원하며, 다양한 유형의 클라이언트 요청을 처리할 수 있다. -
보안성: 로드 밸런서는 보안 기능을 제공하여 악성 트래픽을 필터링하고, SSL 인증서 등의 보안 기능을 제공한다.
EKS Cluster에서 Service 적용하기
앞서 Service의 유형들에 대해서 살펴보았는데, 로드밸런서 타입으로 Service를 올리는 실습을 간단하게 진행해보려고 한다.
실습 환경의 경우 AWS EC2 인스턴스에 EKS Cluster가 구축되어 있고 Argo를 통해 Cluster 환경 변경여부를 감지하여 배포하도록 설정해놓은 상태이다.
또한, EKS Cluster에는 이전에 만들었던 Deployment가 올라가있다. Argo의 App을 살펴보면 test-deploy라는 이름으로 Deployment가 운영되고 있다.

이제, Deployment를 외부로 서비스하기 위한 Service 매니페스트를 작성하자.
service.yml
apiVersion: v1
kind: Service
metadata:
name: test-svc
spec:
selector:
app: spring
ports:
- name: http
protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
k8s manifest 파일들이 존재하는 저장소에 service.yml 파일을 생성하면 Argo에서 자동으로 deloy 디렉토리의 변경점을 감지하여 Deployment를 외부로 서비스할 service를 반영하게 된다.
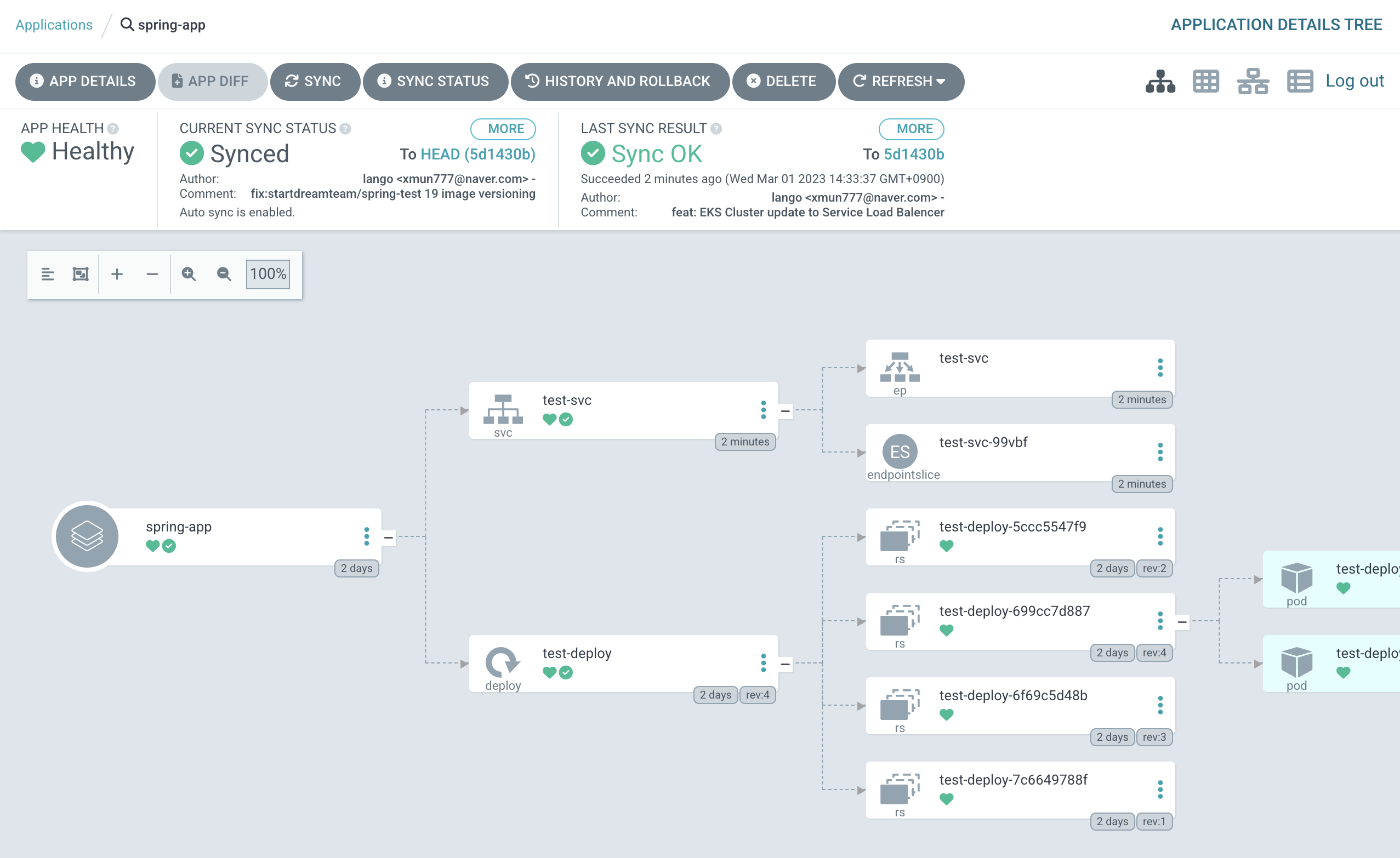
Argo의 연동된 App 화면을 보면 test-deploy 위의 test-svc가 새로 추가된 것을 볼 수 있다.
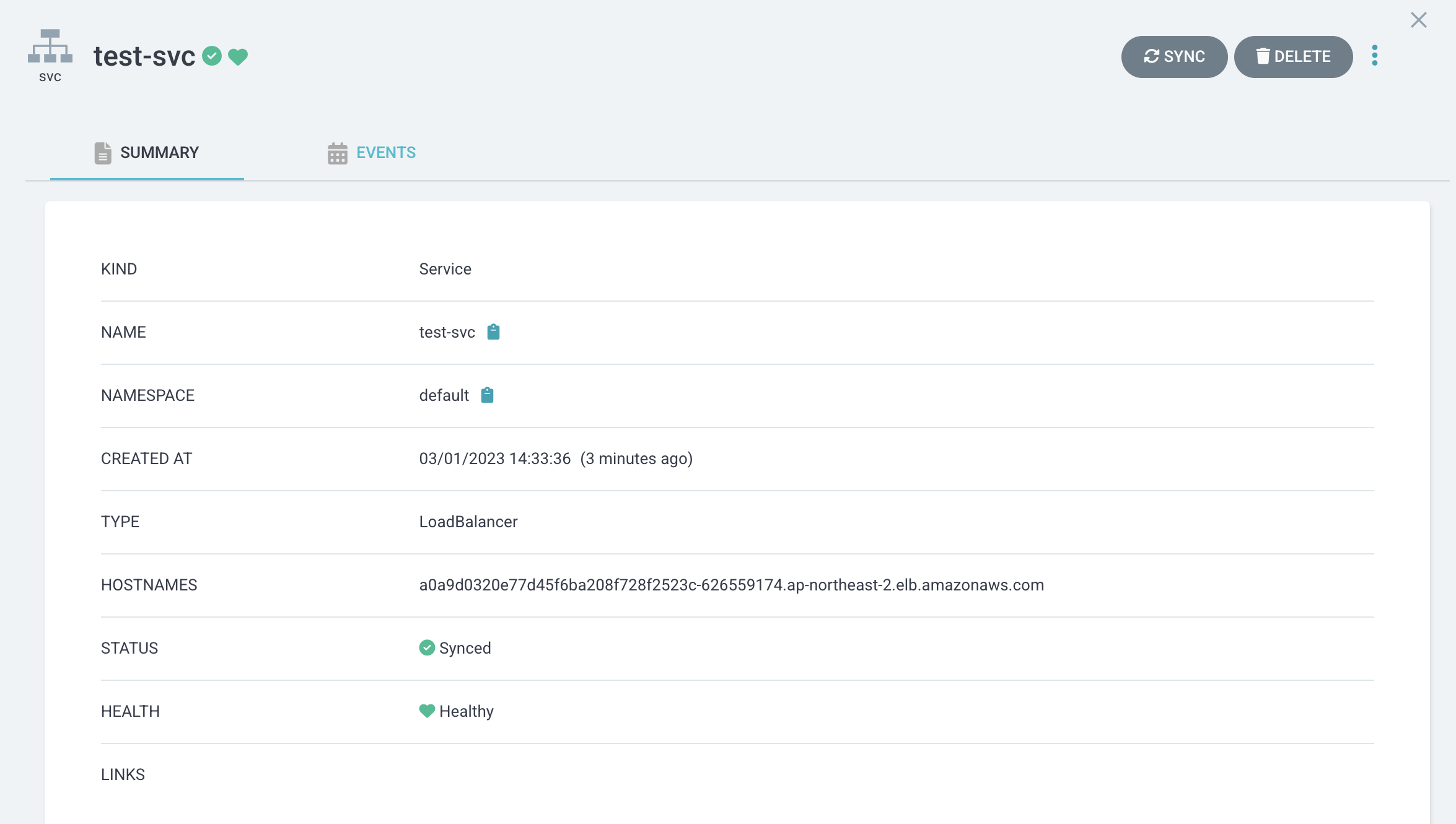
test-svc가 정상적으로 반영되고 나면 Deployment의 Pod들을 외부에서 접속할 수 있는 로드밸런서가 생성되고, 로드밸런서의 DNS Name을 통해 접속할 수 있다.
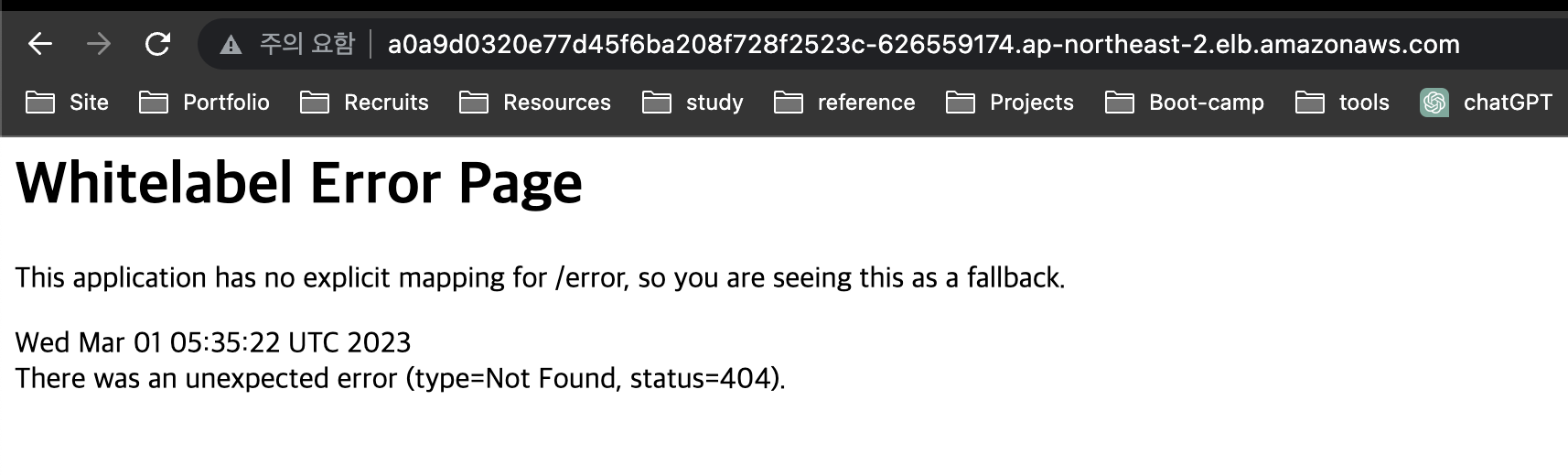
해당 로드밸런서의 DNS로 접속하니 테스트로 배포한 스프링 애플리케이션이 실행되고 있음을 확인할 수 있었다.
AWS에서의 로드밸런서 생성여부 이미지도 준비했어야 했는데 미처 준비를 못하였다. argoCD 및 로드밸런서 DNS 접속 여부 정도의 캡처 이미지만 첨부함을 양해 바란다.
AWS 과금의 부담 때문에 실습 이후 바로 EKS Cluster와 EC2 인스턴스를 삭제하였다.
AWS의 EKS를 도입하면서..
프로젝트에 EKS를 도입하게 되면서 궁금했던 몇 가지 내용에 대해서 정리해보려 한다.
EKS(Elastic Kubernetes Servic)란?
먼저 AWS EKS에 대해서 개념적인 부분을 살펴보도록 하자.

EKS란 Elastic Kubernetes Service의 줄임말로, AWS에서 쿠버네티스 클러스터를 손쉽게 구축 및 관리할 수 있게 해주는 AWS의 완전 관리형 서비스이다.
EKS를 사용하면 직접 마스터 노드와 워커 노드를 연결하는 과정에 관여하지 않아도 되기 때문에 직접 클러스터를 구축하는 것보다 쉽게 클러스터를 구축할 수 있다. 이 때, 마스터 노드를 AWS에서 자체 관리해주므로 보다 효율적으로 운영 및 유지보수할 수 있다.
또한, 손쉽게 클릭만으로 워커노드를 생성하고 소멸시킬 수 있으며, 기본적인 장애 대응책이 마련되어 있기 때문에 직접 클러스터를 구축하는 것보다 AWS의 EKS를 사용하는 것이 더욱 좋을 수 있다.
그래서 EKS를 사용하면 개발자는 클러스터를 배포하고 운영하는 데 필요한 작업을 최소화하고, Kubernetes에 익숙한 방식으로 애플리케이션을 개발하고 배포할 수 있게 된다.
EKS Cluster를 구축할 때 VPC를 지정해야 하는 이유는?
EKS Cluster를 생성할 때 필수적으로 VPC를 지정하도록 하고 있기에 클러스터를 생성할 때 VPC를 지정하지 않으면 생성할 수 없도록 되어 있다. 왜 클러스터를 구축하는 데 왜 VPC가 필요한 것일까?
AWS의 VPC에 대해서는 이전 회고록에서 한번 다루어던 적이 있으니 개념적인 부분에 대해서는 해당 글을 참고하자.
일반적으로 EKS는 워크 노드의 네트워크와는 조금 다른 네트워크 체계를 가지고 있다. 그래서 명시적으로 엔드 포인트를 설정하지 않는면 클러스터 외부에서 Pod로 통신할 수 없다.
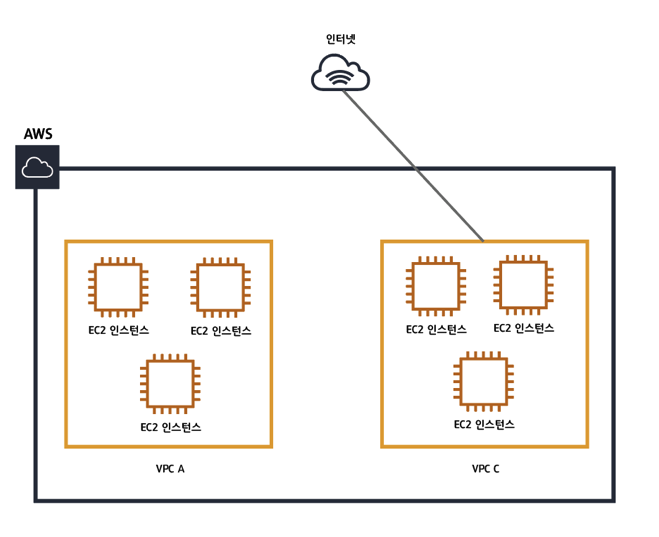
하지만 EKS를 생성할 때 AWS VPC를 연결해준다면, 클러스터의 내부 주소 IP 대역을 사용할 수 있고, 자동으로 클러스터 외부와의 통신이 가능하도록 해준다.
따라서, AWS EKS 클러스터를 생성할 때 새로운 VPC를 생성하거나 기존 VPC를 선택하여 지정해야한다.
EKS를 생성하고 사용할 때 IAM 사용자가 필요한 이유는?
다음으로 EKS를 생성하고 사용할 때 IAM 사용자를 추가하여 해당 사용자를 통해 EKS에 접근토록 하였다. 왜 별도의 IAM 사용자를 추가해야 하는지 살펴보도록 하자.
IAM이란 AWS의 리소스에 대해 개별적으로 접근제어와 권한을 가지도록 계정 또는 그룹을 생성, 관리하는 서비스이다. 예를 들자면 어떤 IAM 계정은 EC2 서비스만 접근할 수 있도록 권한을 부여하고, 다른 IAM 계정은 S3 서비스만 접근할 수 있도록 권한을 나눌 수 있다.
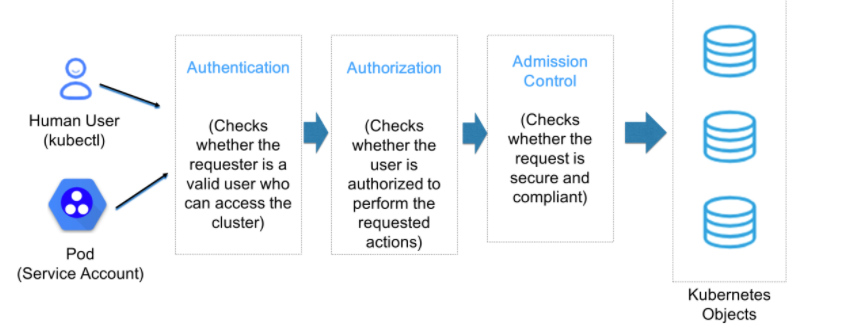
간단하게 쿠버네티스의 API Server에 접근하기까지의 절차를 살펴보면 다음과 같다.
1. 인증(Authentication)
요청 > 인증(Authentication)
먼저 요청에 대한 작업을 실행시키기 위해 요청을 보낸 사용자가 클러스터에 등록된 사용자인지 확인하는 인증 과정을 거친다.
2. 인가(Authorization)
인증 > 인가(Authorization)
인증 과정을 통과했다면, 해당 사용자가 요청에 대한 작업을 지시할 수 있는 권한이 있는지를 검증하는 인가 과정을 거친다.
3. 심사(Admission Control)
인가 > 심사(Admission Control)
앞에서 인증 및 인가를 통과했다면 해당 사용자가 보낸 요청에 대한 적절성 여부를 확인하는 심사 과정(Admission Control)을 거친다.
무사히 심사 과정을 마친다면 요청 승인이 되지만, 하나라도 적절치 않은 내용이 있다면 요청 반려가 된다.
결국 EKS 클러스터 접근을 위한 자격 증명을 관리하기 위해, 그리고 이 후 클러스터 관리를 위한 권한을 분리하기 위해서 IAM 사용자를 생성하고 별도의 정책별로 구분하여 관리해야 하는 것이 바람직하다고 느꼈다.
WebRTC에 대해서
파이널 프로젝트에 영상 채팅 기능을 추가하기 위해서 WebRTC라는 기술이 필요하게 되었다. WebRTC의 기본적인 개념에 대해서 공부하고 기록해보려 한다.
WebRTC(Web Real-Time Communication)란?

WebRTC(Web Real-Time Communication)는 웹 브라우저에서 서로 통신할 수 있도록, 즉 실시간 통신을 구현할 수 있는 API이다.
WebRTC는 웹 브라우저에서 비디오, 오디오 및 데이터를 실시간으로 처리하며, 주로 P2P(peer-to-peer) 통신을 위해 설계되었다. 여기서 P2P 통신은 서버를 거치지 않고 클라이언트 간에 직접적으로 데이터를 주고받는 방식으로, 더욱 빠르고 안정적인 통신이 가능하다.
WebRTC는 Google, Mozilla, Opera 등 다양한 기업과 개발자들이 참여하여 개발되었다.
WebRTC의 다양한 기능들
WebRTC는 다양한 기능을 제공하는데 그 중 주요 기능은 다음과 같다.
Real-time communication
WebRTC는 비디오, 오디오 및 데이터 통신을 실시간으로 처리할 수 있다. 또한, P2P 통신을 지원하므로 서버를 거치지 않고 직접적으로 데이터를 주고받을 수 있다.
Signaling
WebRTC는 P2P 통신을 위한 Signaling 프로토콜을 지원한다. 이를 통해 두 클라이언트 간의 연결을 설정하고 통신할 수 있다.
NAT traversal
WebRTC는 NAT(Network Address Translation) 트래버셜을 지원하여, 네트워크 환경이 다른 클라이언트 간의 통신도 가능하다.
Screen sharing
WebRTC는 브라우저 상에서 화면 공유 기능을 제공한다. 이를 통해 화상 회의나 원격 지원 등에 활용할 수 있다.
WebRTC는 HTML5, JavaScript 및 CSS를 사용하여 구현되는데, 브라우저에서 WebRTC API를 호출하면, 브라우저는 자체적으로 웹캠 및 마이크와 같은 장치를 탐색하고 데이터를 처리하게 된다. 또한, WebRTC API를 사용하여 P2P 연결을 설정하고 데이터를 주고받을 수 있다.
WebRTC의 구성 방식은?
다음으로 WebRTC가 어떻게 구성되어있는지 알아보자.
웹 브라우저가 서로 실시간 통신을 하기 위해서는 다음과 같은 조건이 필요하다.
- 기기의 스트리밍 오디오 및 비디오, 그리고 주고받는 데이터
- 통신하고자 하는 기기의 IP 주소와 포트 등 네트워크 통신을 위한 데이터
- 발생할 수 있는 에러의 보고 여부, 세션 초기화를 위한 신호 통신 관리
- 해상도 및 코덱의 적합성 여부 등 capability 정보 교환
- 실제 연결 이후, 스트리밍 오디오, 비디오, 데이터 통신 여부
이 조건들을 충족하기 위해서 WebRTC는 다음과 같은 객체들을 제공하고 있다.
MediaStream
MediaStream은 비디오와 오디오, 즉 카메라와 마이크 등의 스트림을 제공하는 객체이다.
사용자의 카메라, 마이크 등의 미디어 입력 장치에서 비디오 및 오디오 스트림을 가져와서 이를 MediaStream 객체로 만들게 된다. 이후 만든 비디오 및 오디오 스트림을 브라우저 상에서 제공하기 위한 객체라고 볼 수 있다.
RTCPeerConnection
RTCPeerConnection은 P2P 연결을 생성하고 관리하는 객체이다.
P2P 연결을 생성하기 위해, 각 Peer는 RTCPeerConnection 객체를 생성하고, 상대 Peer와 연결하게 된다.
RTCPeerConnection은 ICE 프레임워크와 SDP(Session Description Protocol)를 이용하여 P2P 연결을 생성하며, NAT(Network Address Translation)과 같은 중개 서버를 사용하여 P2P 연결을 수행한다.
따라서, RTCPeerConnection은 비디오 및 오디오 스트림을 상대 Peer에 전송하고, 받아들이기 위해 미디어 코덱 처리 및 대역폭 제어 등의 작업을 수행한다고 보면 된다.
RTCDataChannel
RTCDataChannel은 일반적으로 P2P 데이터를 전송하기 위한 객체이다.
RTCDataChannel은 RTCPeerConnection을 이용하여 생성할 수 있으며, 상대 Peer와 직접적으로 데이터를 전송할 수 있다. 또한, 비디오 및 오디오 스트림 외에도 일반적인 데이터를 P2P로 전송할 수 있다.
그리고 데이터를 전송할 경우 대역폭 제어 및 데이터 전송의 신뢰성 확보를 위한 기능을 제공한다.
따라서, WebRTC는 MediaStream, RTCPeerConnection, RTCDataChannel 이 3가지의 객체들을 통해 P2P 통신, 즉 데이터 교환을 수행하는데, MediaStream은 비디오 및 오디오 스트림을 제공하며, RTCPeerConnection은 P2P 연결을 생성하고 관리하며, RTCDataChannel은 P2P 데이터 전송을 수행하게 된다.
이렇게 RTCPeerConnection들이 통신할 수 있도록 해주는 과정을 시그널링(Signaling)이라고 한다.
WebRTC의 통신 방식들에는 무엇이 있을까?
WebRTC의 통신 방식에는 Signaling(Mesh), MCU, SFU 3가지의 서버 방식이 있늗데, 이 3가지 방식에 대해서 살펴보자.
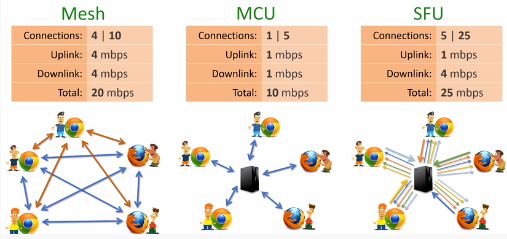
Mesh
모든 Peer가 연결되어 별도의 중계서버가 필요없는 방식이다. 다만, 너무 많은 Peer가 연결되면 클라이언트의 부하가 기하급수적으로 커지게 되기에 1:1 연결에 적합하다고 볼 수 있다. 특히 비디오나 오디오 없이 텍스트 데이터 정도만 주고받는 경우라면 괜찮을 수도 있다.
MCU(Multi-point Control Unit)
미디어 트래픽을 중계하는 하나의 중앙 서버를 통해 클라이언트에게 데이터를 전송하는 방식이다. 클라이언트의 부하가 줄어들기는 하지만, 비디오나 오디오를 결합하는 과정에서 비용이 커질 수 있다. 그래서 MCU는 N:M 연결에 적합하다고 볼 수 있다.
MCU 방식은 WebRTC의 핵심인 실시간성이 저해된다는 특징이 있다.
SFU(Selective Forwarding Unit)
MCU와 유사하게 비슷하게 중앙 서버를 통해 미디어 트래픽을 중계하는 방식이다. MCU와 다른 점은 실시간성을 보장하기 때문에 DownLink가 본인을 제외한 갯수만큼 존재하여 Mesh 방식과 거의 비슷한 수준의 지연시간을 보여준다. 그렇기에 중앙서버와 클라이언트 모두 어느 정도 부하를 감당해야 한다. 그래서 SFU는 1:N 또는 소규모 N:M 실시간 스트리밍에 적합하다고 볼 수 있다.
여기까지 WebRTC라는 기술에 대해서 간단하게 살펴보았다. 하나의 서버만으로는 P2P 통신을 구현할 수 없기에 이론적인 부분만 본다면 솔직히 이해가 안가는 것도 많고 어려운 내용이라고 생각이 들었다.
실질적으로 WebRTC를 앞으로 자주 다루게 될 텐데, 이번엔 개념적인 측면에서만 알아보았다면, 다음에는 WebRTC를 구현하는 방법이라던가, WebRTC를 구현하기 위한 시그널링 서버, 즉 Web Socket에 대해서 알아보려고 한다.
Final..
18주차 부터 온전히 파이널 프로젝트를 진행하기 시작하였다.
프로젝트를 기획하고 설계 하면서 나와 팀원들이 프로젝트를 통해 녹여내고 싶은 것은 무엇인지 고민하게 되었다. 단순히 컨셉이나 아이디어를 통해 하나의 프로젝트를 구축하는 것은 크게 어렵지 않을 수도 있지만, 카카오 클라우드 스쿨 교육과정을 지내오면서 보고 느끼고 생각했던 문제들을 다룰 수 있는 컨셉의 프로젝트를 하려고 하니 막막한 점도 없지 않았다.
물론, 정해진 일정 안에서 하고 싶은 모든 것들을 할 수는 없다. 그래서 1주 단위로 스프린트를 진행하며 각자 해야할 분량을 정하고, 그 다음 주에는 각자가 해온 분량에 대한 내용을 공유하고 병합하고 새로운 일정을 분담하는 방식으로 진행하려 하는데 만만치가 않을 것으로 보인다.
이 과정 속에서 자연스럽게 팀원들을 리드하는 팀 리드의 역할을 맡게 되었는데, 나를 위해서도 팀원들을 위해서도 일정 관리와 구현 가능성을 잘 따져서 프로젝트를 완성까지 이끌어 낼 수 있도록 최선을 다할 계획이다.
혹여 잘못된 내용이 있다면 지적해주시면 정정하도록 하겠습니다.참고자료 출처
