
들어가며
정의: Spring이란 무엇인가?
배경: Spring은 어떻게 탄생했을까?
필요성: Spring은 어떤 기능을 제공할까?
핵심 요소: Spring에서 DI나 AOP와 같은 핵심 요소는 무엇이 있을까?
동작 원리: Spring은 어떻게 동작하는 걸까?
이전 글에서 Spring의 정의, 탄생 배경, 필요성 및 특징에 대해서 배우고 Spring이 강조하는 핵심인 POJO 프로그래밍에 대해서 살펴봤다.이해할 수 있었다. 이번에는 이러한 POJO 프로그래밍을 기반으로 제공되는 IoC와 DI, AOP, PSA에 대해서 파헤쳐보려 한다.
제어의 역전, IoC와 의존성 주입, DI
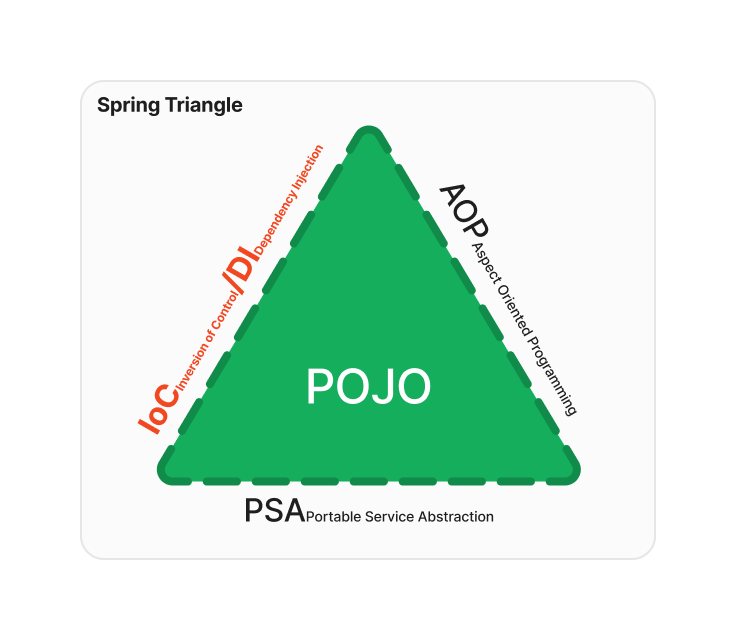
IoC와 DI, AOP, PSA 중 IoC와 DI에 대해서 알아보자.
IoC(Inversion of Control)란?
IoC(Inversion of Control)란 제어의 역전을 의미한다.
IoC의 핵심 개념은 객체를 제어할 수 있는 권한을 객체 내부에서 가지는 것이 아니라, 외부에서 객체를 제어하고 관리할 수 있도록 역전시켜주는 것이다.
왜 객체의 제어권을 내부가 아닌 외부가 가지도록 해야하는 것인지 생각해보자.
정말 IoC가 왜 필요한 걸까?
- 객체지향 원칙을 잘 지키기 위함이다.
- 역할과 관심을 분리하여 응집도를 높이고 결합도는 낮추며, 변경에 유연한 코드를 작성할 수 있는 구조로 만들 수 있기 때문이다.
이는 객체를 관리할 수 있는 제어권을 개발자(사용자)가 아닌 Spring이 가지게 되는 것으로 이해하였다.
DI(Dependency Injection)란?
DI(Dependency Injectio)는 의존성 주입을 뜻한다.
DI는 객체 간의 의존관계를 직접 설정하는 것이 아니라 외부에서 생성하여 주입시키는 개념으로 동작하는 디자인 패턴이다.
DI에 대해서 위키백과에서는 하나의 객체가 다른 객체의 의존성을 제공하는 테크닉이라고 말하고 있다.
DI에서의 의존성이란 하나의 객체가 다른 객체를 사용할 때 의존성이 있다고 말한다. 그리고 서로 다른 두 객체 간의 의존관계(의존성)를 맺어주는 것을 의존성 주입(DI)이라고 말할 수 있다.
여기서 객체간의 관계를 외부에서 주입시키는 것을 통해 DI는 왜 필요한지 궁금해졌고 DI의 필요성에 대해서 학습해보니 아래 2가지로 DI의 필요성을 설명할 수 있을 것 같다.
- 관심사 분리
- Interface를 통한 DI
DI를 통한 관심사 분리
객체를 생성하고 생성한 객체의 인스턴스를 사용하는 로직을 분리함으로 코드의 가독성과 재사용성을 높여준다. 이로 인해 해당 모듈을 테스트하는 것도 수월해진다.
💡 new 키워드를 통한 객체 생성과 관련하여
직접 new 키워드를 통해 객체를 생성하는 것은 객체지향적 관점에서 바라보면 문제가 발생할 수 있다.
먼저
new키워드를 사용하여 객체를 생성할 경우 참조할 클래스가 바뀌면 이 클래스를 사용하는 모든 클래스들을 수정해야 하는 번거로움이 생긴다.또한,
new키워드를 사용하여 의존관계가 있는 객체를 생성할 때, 클래스들 간에 강한 결합(Tight Coupling) 이 이루어 지는데, 이는 DI(의존성 주입) 관점에서 바라보면 좋지 않다고 볼 수 있다.
Interface(인터페이스)를 통한 DI(의존성 주입) 구현
모듈 사이에 인터페이스를 두어 클래스 범주에서 서로의 의존관계를 제거하고 런타임 환경에서 서로의 관계를 동적으로 주입하는 방식으로 결합도가 낮아지고 유연성을 높일 수 있다.
인터페이스를 통해 느슨한 의존성 주입을 구현할 수 있게 된다.
느슨한 의존성 주입이라는 것은 외부에서 변경이 가능한 인터페이스를 생성자에 주입함으로 생성된 객체가 구현체에 의존하지 않아 객체지향의 특징인 다형성을 향상시킬 수 있게 된다는 개념이다.
IoC와 DI는 무슨 관계인가?
스프링의 삼각형에서는 DI라고만 언급되었는데 DI를 말할 때 IoC가 거론되는 것인지, IoC는 DI와 어떠한 밀접한 관련이 있는지 알아보자.
IoC는 원칙의 개념으로, DI는 IoC라는 원칙을 지키기 위한 다양한 디자인 패턴 중 하나이다. IoC와 DI 모두 객체간의 결합을 느슨하게 만들어 유연하고 확장성이 뛰어난 코드를 작성하기 위한 목표를 가지기에 밀접한 관련이 있다고 볼 수 있는 것이다.
말로만 설명하니 너무 장황하게 글을 쓴 것 같다. 그래서 IoC와 DI라는 개념을 예시 코드를 통해 살펴보려 한다.
class 햄버거 {
public void 햄버거_만들기() {
고기패티 patty = new 고기패티();
patty.굽기();
}
}
class 고기패티 {
public void 굽기() {
...
}
}위 코드는 햄버거 클래스와 고기패티 클래스를 나타내고 있는데, 햄버거와 고기패티의 관계는 직접 new 연산자를 통해 고기패티 인스턴스를 생성하도록 작성했기 때문에 개발자가 정하게 된다.
그런데 햄버거가 고기패티가 아닌 치킨패티 클래스를 새롭게 정의해서 사용해야 한다면 아래와 같이 수정해야 한다.
class 햄버거 {
public void 햄버거_만들기() {
// 고기패티 patty = new 고기패티();
// bread.굽기();
치킨패티 patty = new 치킨패티();
patty.굽기();
}
}
class 고기패티 {
public void 굽기() {
...
}
}
// 새로운 치킨패티 클래스 정의
class 치킨패티 {
public void 굽기() {
...
}
}당연하게도 햄버거의 코드에 위와 같이 고칠 수 밖에 없을 것이다. 기존에 고기패티를 사용하던 객체가 햄버거밖에 없어서 망정이지, 만약 고기패티 클래스를 사용하는 객체가 수십 개만 있다고 하더라도 모든 객체의 코드를 수정해야 한다.
하지만 앞에서 배운 Spring의 IoC와 DI를 적용한다면 이 문제를 쉽게 해결할 수 있다. IoC와 DI를 고려하여 위 코드를 수정해보자.
// 햄버거가 사용하는 메서드를 패티라는 인터페이스의 추상 메서드로 정의한다.
interface 패티 {
void 굽기();
}
class 햄버거 {
// 인터페이스 타입의 패티 필드를 선언한다.
private 패티 patty;
// 햄버거의 생성자를 통해 외부에서 생성된 인스턴스를 받아서 패티를 초기화한다.
public 햄버거(패티 patty) {
this.patty = patty;
}
public void 햄버거_만들기() {
// 외부에서 받아온 패티 인스턴스의 메서드를 호출한다.
patty.굽기();
}
}
// 패티 인터페이스의 구현체(고기패티)
class 고기패티 implements 패티 {
public void 굽기() {
...
}
}
// 패티 인터페이스의 구현체(치킨패티)
class 치킨패티 implements 패티 {
public void 굽기() {
...
}
}위 코드는 햄버거 클래스가 패티를 직접 생성하는 것이 아니라 생성자를 통해서 외부에서 받아오도록 작성되었다. 이를 통해 햄버거는 패티를 알고 있지 않으며, 그저 patty에 할당된 인스턴스가 굽기()라는 메서드를 가지고 있다는 것만 알고 있게 된다.
여기서 햄버거의 인스턴스가 만들어질 때 파라미터로 햄버거가 사용하는 패티라는 외부에서 객체를 생성해서 전달해주어야 한다. 여기서 말하는 외부가 바로 Spring이다.
Spring을 통해 햄버거가 사용할 패티를 고기패티로 할지 치킨패티로 할지 아니면 XX패티로 할지 여부를 결정할 수 있다. 그 방법은 간단하다. 개발자가 설정 클래스에 햄버거가 사용할 객체를 치킨패티로 설정해두면, Spring을 통해 애플리케이션이 실행되며 설정 클래스의 파일을 해석하여 치킨패티 객체를 생성해 햄버거의 생성자의 인자로 전달해주게 되는 것이다.
그래서 개발자가 직접 패티 객체를 생성하는 것이 아니라 Spring이 패티 객체를 생성하여 의존 관계를 맺어주는 것을 IoC, 그 과정에서 치킨패티를 햄버거의 생성자를 통해 주입해주는 것을 DI라고 말할 수 있다.
의존성을 주입하는 3가지 방법
class 햄버거 {
빵 bread;
패티 patty;
public 햄버거(빵 bread, 패티 patty) {
this.bread = new 빵();
this.patty = new 패티();
}
}위 코드와 같이 햄버거가 빵과 패티를 사용하고 있는데, 햄버거가 빵과 패티에 대해 의존성이 있다고 말할 수 있다.
여기서 만약 빵이 변경된다면 햄버거에게도 영향을 줄 수 있다. 빵 객체가 변경되면 햄버거에서도 수정이 필요할 수 있고, 궁극적으로 햄버거의 기능이 이전과 같다고 볼 수 없다.
위와 같이 햄버거와 빵의 관계를 맺어주는 것이 의존성 주입, DI라는 것을 앞에서 배웠다. 그런데 어떻게 객체의 의존성을 주입해줄 수 있을까?
기본적으로 의존성을 주입하는 방법에는 아래 3가지가 있다.
- 생성자를 통한 주입
- Setter 메소드를 통한 주입
- Interface를 통한 주입
생성자 주입
먼저 생성자 주입 방식으로 위 코드를 변경해보고 살펴보자.
class 햄버거 {
빵 bread;
패티 patty;
public 햄버거(빵 bread, 패티 patty) {
this.bread = bread;
this.patty = patty;
}
}기존에는 생성자에서 빵과 패티의 인스턴스를 직접 생성했다면, 생성자 주입 방식은 생성자를 호출할 때 외부에서 빵과 패티의 의존성을 주입받는다.
Setter 주입
이번에는 Setter 메소드를 통해 빵과 패티의 의존성을 주입받도록 코드를 수정해보자.
class 햄버거 {
빵 bread;
패티 patty;
// 빵 객체에 대한 Setter 메소드
public void set빵(빵 bread) {
this.bread = bread;
}
// 패티 객체에 대한 Setter 메소드
public void set패티(패티 patty) {
this.patty = patty;
}
}Setter를 이용한 주입 방법은 의존성을 입력받는 Setter 메소드를 만들고 이 메소드를 호출하여 의존성을 주입받는다.
Interface 주입
마지막으로 Interface를 통해 의존성을 주입하도록 코드를 변경해보자.
interface 햄버거 {
void 내용물(빵 bread, 패티 patty);
}
class 데리버거 implements 햄버거 {
빵 bread;
패티 patty;
@Override
public void 내용물(빵 bread, 패티 patty) {
this.bread = bread;
this.patty = patty;
}
}이 방법은 의존성을 주입하는 메서드를 포함하는 인터페이스를 작성하고, 인터페이스의 구현체를 통해 애플리케이션 실행 시점에 의존성을 주입받는다.
Setter 주입처럼 메소드를 외부에서 호출해야 하는 것은 유사하나, 의존성 주입 메서드를 빠뜨릴 수 있는 Setter 주입과는 다르게 @Override를 통해 메서드 구현을 강제할 수 있다는 차이점이 있다.
Spring에서 의존성을 주입하는 방법
Spring을 사용하지 않고 DI를 달성하는 방법들에 대해서 알아보았는데, Spring을 사용한다면 이러한 DI를 더욱 편하게 사용할 수 있게 되는데 그 방법들에 대해서 알아보자.
의존성 자동 주입 - @Autowired
아래 코드는 BurgerService라는 의존성을 주입받는 BurgerController 코드이다.
@Controller
public class BurgerController {
private final BurgerService burgerService;
public BurgerController(BurgerService burgerService) {
this.burgerService = burgerService;
}
}BurgerController는 생성자를 통해 BurgerService의 의존성을 주입받고 있는데 특정한 BurgerService를 인자로 받는 생성자가 상위 모듈이라던지, 어디에선가는 반드시 호출이 되어야 한다.
@SpringBootApplication
public class BurgetApplication {
public static void main(String[] args) {
SpringApplication.run(BurgetApplication.class, args);
}
}그런데, BurgerController보다 상위 모듈의 코드를 뒤져봐도 BurgerController의 생성 시 BurgerService의 인스턴스를 주입하는 코드를 찾을 수 없다.
그럼에도BurgerService가 주입된 BurgerController를 사용할 수가 있는데, 이는 Spring의 자동으로 의존성을 주입해주기 때문이다.
Spring은 빈(Bean)으로 등록된 객체에 한해, 자동으로 인스턴스를 생성해주는데 이때, 필요한 의존성도 자동으로 주입해주게 된다.
그런데 Spring이 어떻게 의존성을 자동으로 주입해주는 걸까?
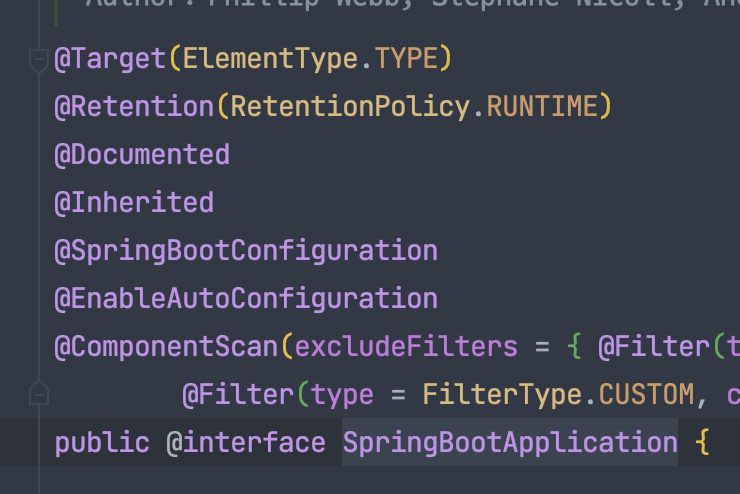
✅ @SpringBootApplication을 통한 의존성 자동 주입
@SpringBootApplication어노테이션을 살펴보면,@ComponentScan가 존재함을 알 수 있는데,@ComponentScan는@Component가 부여된 클래스들을 탐색하여 Spring의 빈으로 등록해준다.@Controller,@Service,@Repository은@Component를 적절한 목적에 따라 명시하기 위한 어노테이션이다.이와 관련된 내용은 스프링 공식 자료에서도 살펴볼 수 있었다.
결국 위 BurgerController 코드에서 BurgerService에 대한 의존성을 주입받는 과정은 @Controller 어노테이션이 부여되어 있기에 가능한 일이라는 것을 알게 되었다.
@ComponentScan가 @Component를 가지는 클래스들을 스캔하면서 BurgerController 또한 스프링 빈으로 등록해주게 된다.
@Service
public class BurgerService {
@Autowired
private BurgerRepository burgerRepository;
}그래서 위처럼 BurgerService 코드가 스프링 빈으로 등록될 수 있도록 했다면 아래와 같이 BurgerController 코드에서 @Autowired 어노테이션을 사용해 BurgerService의 의존성을 주입받을 수 있다.
@Controller
public class BurgerController {
@Autowired
private BurgerService burgerService;
}그렇다면 @Autowired 어노테이션을 통해 의존성을 주입하는 방법에는 무엇이 있을까?
@Autowired를 통한 의존성 주입 방법 3가지
Spring에서는 @Autowired 어노테이션을 이용해 의존성을 주입받을 수 있는 3가지 방법을 사용할 수 있다.
- 필드 주입
- Setter 주입
- 생성자 주입
필드 주입
먼저 가장 간단한 주입 방법인 필드 주입을 살펴보자.
@Controller
public class BurgerController {
@Autowired
private BurgerService burgerService;
}위에서 본 코드와 동일하다. burgerService 필드 위에 @Autowired 어노테이션만 붙여주면 Spring이 자동으로 의존성을 주입해주게 된다.
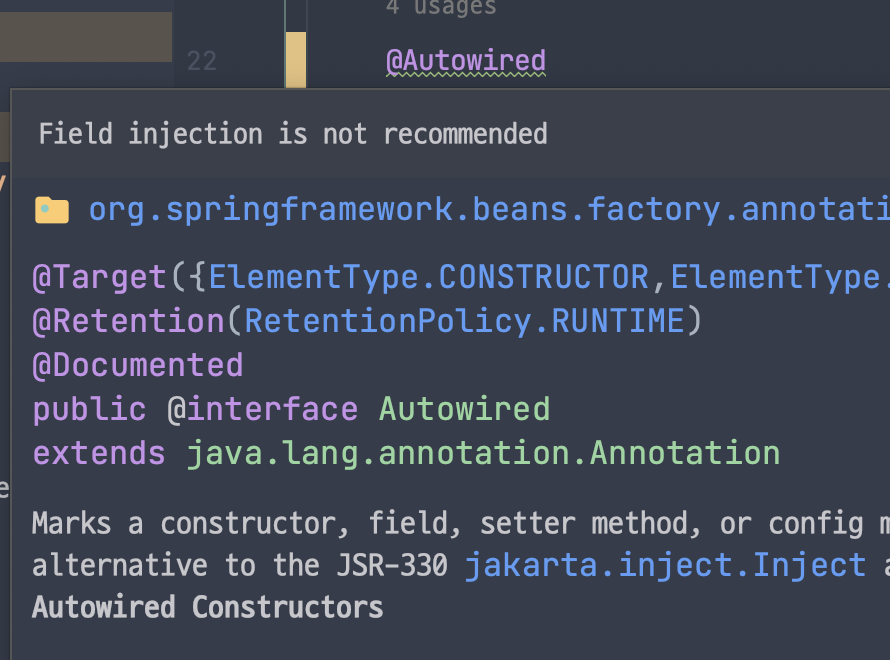
🤔 필드 주입은 지양해야 한다?
Intellij에서
@Autowired을 통해 필드 주입을 사용하면 위와 같은 경고를 확인할 수 있다.Spring이 이러한 필드 주입을 권장하지 않는 이유는 수동으로 의존성을 주입해야 하는 테스트같은 경우 생성자나 Setter 메소드도 존재하지 않기에 직접 의존성을 주입할 수 없기 때문이다.
결국 필드 주입을 사용하게 되면 객체 간의 의존성이 프레임워크에 강하게 종속된다는 문제가 발생한다.
Setter 주입
다음으로 Setter를 통해 주입하는 방법을 보자.
@Controller
public class BurgerController {
private BurgerService burgerService;
@Autowired
public void setBurgerService(BurgerService burgerService) {
this.burgerService = burgerService;
}
}위와 같이 Setter 메소드에 @Autowired 어노테이션을 부여하면 Spring이 자동으로 의존성을 주입해준다.
Setter 주입을 사용할 경우 빈 생성자 또는 빈 정적 팩토리 메서드가 필요하다. 또한, final 필드를 만들 수 없고 의존성의 불변을 보장할 수 없다.
그렇다면 Setter 주입 방식을 사용하면 안될 것 같은데 Setter 주입 방식을 사용하는 이유가 있을까?
Setter 주입 방식의 경우 불변 보장이 안된다는 점을 보면, 런타임 환경에서 Setter 메소드를 호출하면 이미 주입했던 의존성을 변경할 수가 있게 된다. 그래서 런타임 환경에서 의존성을 변경하거나 선택적으로 의존성을 주입해야 할 경우 사용될 수 있다.
생성자 주입
마지막으로 생성자 주입 방식에 대해서 알아보자.
@Controller
public class BurgerController {
private final BurgerService burgerService;
public BurgerController(BurgerService burgerService) {
this.burgerService = burgerService;
}
}위와 같이 생성자 주입 방식을 이용하면 객체가 최초로 생성될 시점에 Spring이 자동으로 의존성을 주입해준다.
이러한 생성자 주입 방식은 Spring에서 공식적으로 적극적으로 권장하고 있다.
💡 생성자 주입시 @Autowired 어노테이션가 없는 이유?
위 코드를 보면
@Autowired어노테이션이 작성되어 있지 않다.Spring 4.3 이후부터 생성자가 한 개만 있다면 해당 생성자에 Spring이 자동으로
@Autowired어노테이션을 붙여주기 때문에 생성자가 하나일 경우 생략해도 무방하다.@RequiredArgsConstructor @Controller public class BurgerController { private final BurgerService burgerService;또한, 위와 같이 Lombok 의
@RequiredArgsConstructor어노테이션까지 활용한다면 간단한 코드 작성만으로 생성자 주입을 활용하여 의존성 주입을 할 수 있다.
생성자 주입 VS Setter 주입
필드 주입 방식은 Spring에서도 공식적으로 지양하고 있다. 그러면 생성자 주입 방식과 Setter 주입 방식중 어떤 방식을 사용해야 할까?
결론부터 말하자면 Spring 공식에서도 밀어주고 있는 생성자 주입 방식을 사용하는 것이 적절할 것으로 생각된다.
Spring 공식 문서의 자료를 살펴보면 아래와 같이 이야기 하고 있음을 알 수 있다.

이를 간단히 번역해보면 아래와 같다.
- 생성자 주입과 Setter 주입 중 선택하여 의존성을 주입할 수 있지만, 기본적으로는 생성자 주입을 추천한다.
- 생성자 주입된 컴포넌트들은 초기화된 상태로 클라이언트에 반환되기 때문에 생성자 주입을 권장한다.
- Setter 주입은 주로 클래스 내에서 기본 값을 할당할 수 있는 선택적 의존성을 주입할 때만 사용해야 한다.
이 밖에도 생성자 주입을 사용해야 하는 이유는 많은데, 여기서는 객체의 불변성 확보, NullPointerException 방지, 순환 참조 방지 3가지만 살펴보려 한다.
1. 객체의 불변성 확보,
필드를 final 키워드로 만들 수 있기 때문에 의존성 주입이 생성자 호출시 최초 1회만 이루어지기 때문에 의존관계를 불변으로 만들어 줄 수 있다.
2. NullPointerException 방지
생성자 주입이 아닌 필드 주입이나 Setter 주입은 new 키워드로 객체를 생성할 때, NullPointerExceptiondl 발생할 수 있다. 하지만 생성자 주입은 객체 생성 시점에 모든 의존성을 주입해주기 때문에 Null으르 의도적으로 삽입하지 않는 한 NullPointerException이 발생할 수 없다.
3. 순환 참조 방지
생성자 주입을 사용하면 Spring을 통해 애플리케이션의 시작되는 시점(객체의 생성 시점)에 순환 참조 에러를 예방할 수 있다.
서로 다른 두 객체가 서로를 의존하고 있을 경우 서로를 계속 호출하게 되어 StackOverflow 에러가 발생하게 되는데, 생성자 주입을 통해 의존하고 있는 객체가 순환 참조가 일어나게 되면 Bean에 등록하기 위해 객체를 생성하는 과정에서 다음과 같이 순환 참조가 발생하기 때문에 애플리케이션 구동 시점에 에러를 통해서 문제를 방지할 수 있다.
Spring Boot 2.6 버전 이상부터는 필드 주입이나 Setter 주입도 기본으로 순환 참조 문제를 방지할 수 있다고 한다.
Spring의 핵심 요소 중 하나인 IoC와 DI에 대해서 알아보니 IoC와 DI가 왜 Spring에서 제공하는 이점 중 하나인지 명확하게 알고 배우고 느낄 수 있었다.
관점 지향 프로그래밍, AOP
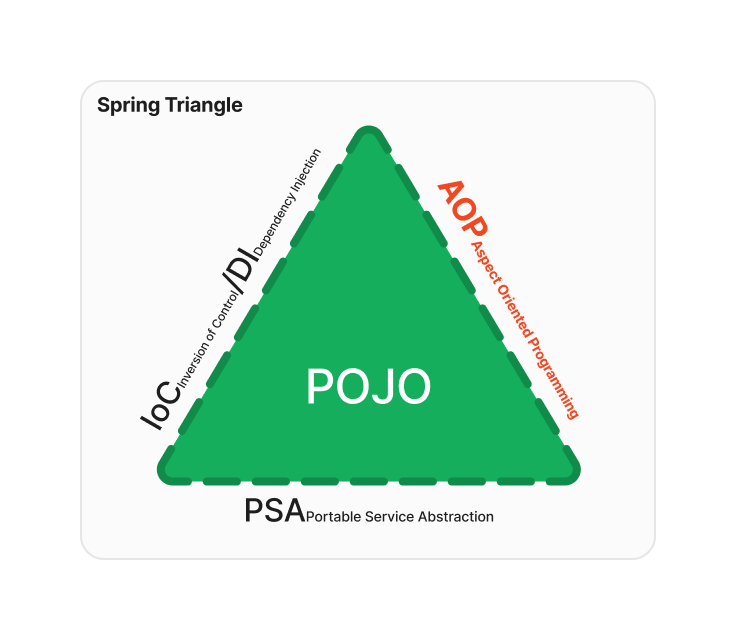
좀 길어지긴 했는데 Spring의 핵심 요소 중 첫번째로 IoC와 DI에 대해서 알아보았다. 두번 째로는 AOP 차례이다.
AOP(Aspect Oriented Programming)란?
AOP는, 관점 지향 프로그래밍이라는 뜻을 가지는데, 위키백과에선 AOP에 대해 다음과 같이 말하고 있다.
관점 지향 프로그래밍(Aspect Oriented Programming, AOP)은 횡단 관심사(cross-cutting concern)의 분리를 허용함으로써 모듈성을 증가시키는 것이 목적인 프로그래밍 패러다임이다.
AOP의 정의를 보면 어려운 용어 투성이다. 용어들을 하나씩 살펴보니 그래도 이해하기 수월했다.
횡단 관심사는 무엇인가?
AOP에서 가장 먼저 언급하고 있는 횡단 관심사란 무엇을 뜻하는 것일까?
횡단 관심사(cross-cutting concern)는 소프트웨어 개발에서 핵심 기능 이외의 공통적인 로직이나 기능을 말한다. 이러한 관심사는 여러 모듈 또는 객체에서 반복적으로 나타나며, 애플리케이션의 여러 부분에 걸쳐 퍼져 있는 경우가 많다.
이를 통해 애플리케이션을 개발할 때 구현해야 할 기능들을 보면, 크게 핵심 관심사항과 공통 관심사항으로 분류된다는 것을 알아차릴 수 있다. 또한, 관점 지향 프로그래밍은 핵심 관심사항보다는 공통 관심사항에 초점을 두고 있다고 생각된다.
AOP의 목적
AOP는 공통 관심사항(=횡단 관심사)을 분리하여 모듈성을 증가시키는 것에 목적을 두고 있다고 배웠다. 그러면 모듈성을 어떻게 증가시킬 수 있을까?
특정 기능을 개발하기 위해 핵심 관심사항과 공통 관심사항을 분류한 후, 이 사항들을 기준으로 모듈화를 진행하면 AOP의 목적인 모듈성을 증가시킬 수 있게 된다.
모듈화란 공통적으로 가지는 로직이나 기능을 하나의 단위로 묶는 작업을 뜻한다.
AOP의 필요성
공통 관심사항을 분리하여 모듈화하여 모듈성을 증가시키고자 하는 AOP의 목적을 통해 어떤 상황에, 어떤 요구사항에 AOP가 필요하게 되는지 알아볼 필요가 있다고 생각이 든다.
핵심 관심사항을 예로 들어보면 햄버거를 주문하거나 주문한 햄버거를 변경 하는 것 등을 생각해볼 수 있다. 그리고 공통 관심사항은 모든 핵심 관심사항에 공통적으로 적용되는 관심사항으로 시스템 로깅이나 보안 등과 관련된 기능들이 핵심 관심사항에 공통적으로 반영되어야 한다.
그런데, 핵심 관심사항과 공통 관심사항에 대한 코드나 로직이 함께 작성되어 있다면, 공통 관심사항과 관련하여 중복 코드가 작성될 수 있다.
이 예시를 이해하기 쉽도록 아래 예시코드를 작성해보았다.
class 햄버거_가게 {
public void 주문하기() {
주문 관련 로직 // 1. 핵심 관심사항
로깅 관련 로직 // 2. 공통 관심사항
}
public void 주문_변경하기() {
주문_변경 관련 로직 // 3. 핵심 관심사항
로깅 관련 로직 // 4. 공통 관심사항
}
...
}위처럼 주문하기() 메서드와 주문_변경하기() 메서드는 각자가 가지는 핵심 관심사항 1번, 3번이 있다. 그런데 2번, 4번과 같이 공통 관심사항에 대한 코드가 중복으로 작성되어 있다면, 공통 관심 사항을 수행하는 로직이 변경될 경우 모든 중복 코드를 찾아서 일일이 수정해주어야만 하는 번거로움이 생기게 된다.
위 예제코드에 발생한 중복 코드 문제를 해결하기 위해서는 공통 관심사항에 대한 코드들을 별도의 객체로 분리하여, 분리한 객체에서 공통 관심사항을 구현한 코드를 호출하는 방식으로 동작하도록 변경해야 한다.
이는 결국 AOP의 원칙을 따라야 한다는 것이며, 애플리케이션에 전반적으로 적용되어 있는 공통 관심사항들을 핵심 비즈니스 로직으로부터 분리해내기 위해서 AOP가 필요하다는 것을 알 수 있었다.
OOP와 AOP의 관계?
Spring Document의 Aspect Oriented Programming with Spring 부분을 보면 다음과 같이 말하고 있다.
Aspect-Oriented Programming (AOP) complements Object-Oriented Programming (OOP) by providing another way of thinking about program structure. The key unit of modularity in OOP is the class, whereas in AOP the unit of modularity is the aspect. Aspects enable the modularization of concerns such as transaction management that cut across multiple types and objects. (Such concerns are often termed crosscutting concerns in AOP literature.)
Spring 공식에서는 AOP가 OOP를 보완하는 방법이라고 말하고 있다.
결국 AOP는 OOP를 더욱 발전시키기 위한 개념이고, 하나의 소프트웨어가 하나의 거대한 OOP라고 한다면 모듈화의 단위로 적용할 수 있는 AOP는 트랙잭션 관리 등과 같은 문제를 모듈화할 수 있기 때문이라고 한다.
AOP 관련 용어
AOP를 구현하는 방법을 알아보기에 앞서, AOP에서 사용되는 용어들을 알고 있어야 한다. AOP에서 사용되는 용어들은 Aspect, Advice, JoinPoint, PointCut, Target과 같은 것들이 있다.
- Aspect
- Target Object
- Advice
- JoinPoint
- PointCut
위 용어들은 무엇이고 AOP를 위해 어떤 역할을 담당하는지 자세하게 들여다보자.
Aspect
Aspect는 횡단 관심사(= 공통 기능, 부가 기능)를 모듈화 한 것을 의미한다. 또한, AOP의 기본 모듈로써 애플리케이션의 핵심 기능을 가지고 있지는 않지만 애플리케이션을 구성하기 위한 중요한 요소이다.
부가 기능을 정의한
Advice와 이 부가 기능을 어디에 적용할지 결정하는Pointcut를 통틀어 Aspect라고 한다.
Target(Object)
Target은 Aspect, 즉 부가기능을 적용할 대상을 뜻한다. 클래스나 메서드가 이에 해당된다.
Advice
Advice란 Target에게 제공할 부가 기능이 구현된 모듈이다. 실질적으로 어떤 부가 기능을 해야 할지를 정의하고 있는 구현체이다.
JoinPoint
JoinPoint란 애플리케이션이 실행되었을 때, Advice가 적용될 위치를 의미한다. 이는 메서드 진입 지점이나 생성자 호출 시점, 필드에서 값을 꺼내올 때 등 다양한 시점에 적용이 가능하다.
PointCut
Pointcut이란 Advice에 적용할 JoinPoint를 선별하는 작업이나 기능을 정의한 모듈이다. 즉, JoinPoint에 대한 상세 스펙을 정의한 것으로 구체적으로 Advice가 실행될 지점을 정할 수 있다.
이렇게 AOP에서 사용되는 용어들이 무엇인지 알아보았다. 그런데, 설명만으로는 애플리케이션(프로그램)의 실행 흐름에서 위 용어들이 어떤 역할을 수행하는지 한 눈에 이해하기는 어렵다고 느껴졌다.
예를 들어서 commonLogging(로깅 관련 로직)이나 commonRuntime(실행시간 측정 로직) 등을 부가기능으로 제공한다고 한다면 프로그램 실행 단위에서 각 용어들은 아래 그림과 같이 동작하게 된다.
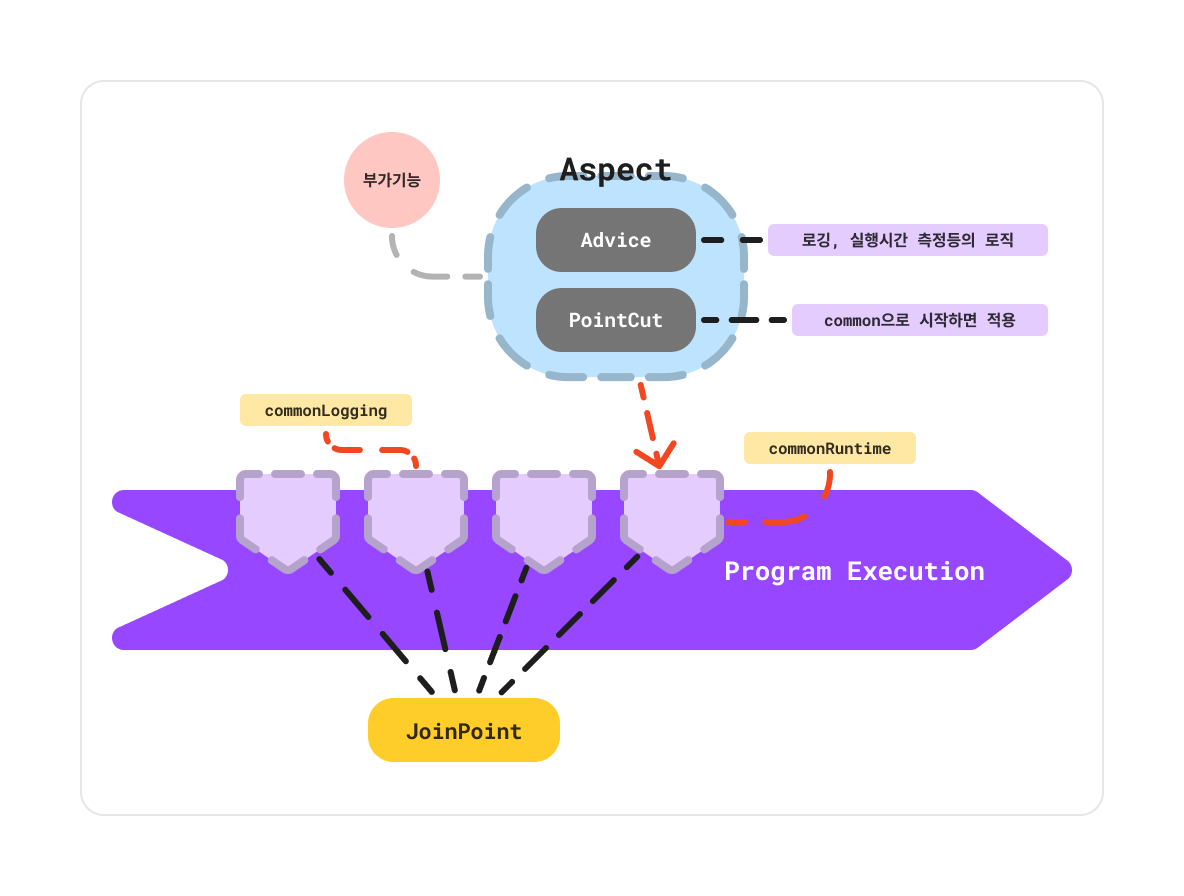
프로그램 실행 흐름 내부에는 각각 부가기능인 Advice들이 적용될 위치인 JoinPoint들이 존재한다. 그리고 로깅 관련 로직이나 실행시간 측정 로직과 같은 부가 기능은 Advice가 된다. 또한, 이 부가 기능을 어디에 적용할지 결정할 PointCut은 Advice가 common으로 시작할 경우 적용할 수 있도록 해준다.
여기서 중요한 점은 Advice와 PointCut을 통틀어 Aspect라고 볼 수 있으며, commonLogging나 commonRuntime라는 메서드들은 부가기능을 적용할 수 있는 지점인 JoinPoint에 해당된다.
AOP를 구현하는 방법
AOP를 구현하기 위해 사용되는 용어를 배웠으니 이제는 AOP가 어떻게 구현되는지, 핵심 기능에 공통 기능을 어떻게 삽입할 수 있을지, 그리고 궁극적으로 Spring에서 AOP를 어떻게 제공하는지를 알아보자. 이 부분에 대해서는 김영한님의 강의를 보고 더 쉽게 이해할 수 있었다.
AOP를 구현하는 방법으로는 아래 3가지 방법이 있다.
- 컴파일 시점에 코드에 공통 기능 삽입
- 클래스 로딩 시점에 바이트코드에 공통 기능 삽입
- 런타임 시점에 프록시 객체를 생성하여 공통 기능 삽입
위 방법들은 부가기능을 삽입하는 시점별로 구분하여 AOP를 적용하는 것으로 보인다. AOP를 구현하는 방법이 시점마다 어떻게 다른걸까? 그리고 Spring에서는 위 3가지 방법 중 어떤 것을 사용할까?
1. 컴파일 시점
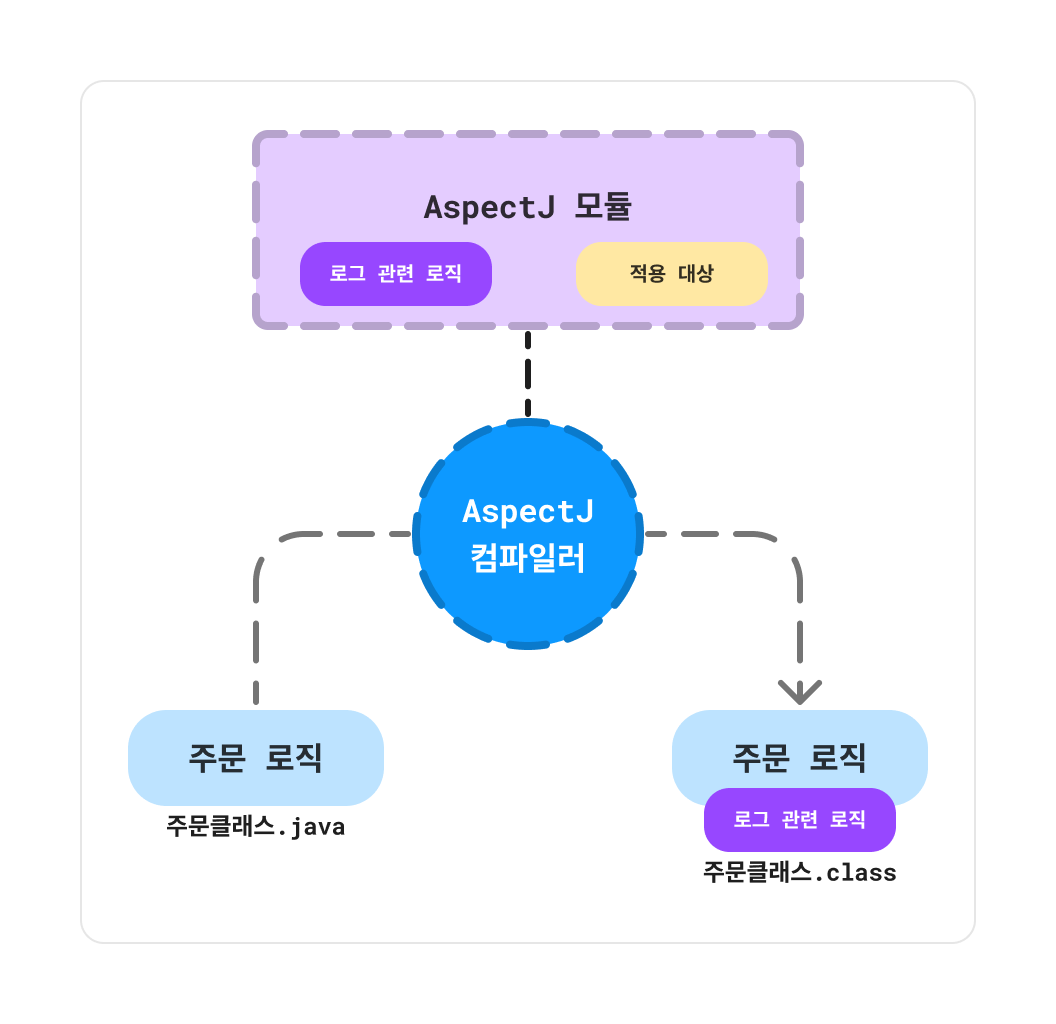
컴파일 시점에 AOP를 통해 부가기능을 삽입하는 방법은 .java 소스 코드를 컴파일하여 .class로 만드는 시점에 이루어진다. 이때, AspectJ라는 라이브러리를 통해 AspectJ 컴파일러를 사용해야 한다.
AspectJ 컴파일러는 AspectJ 모듈을 통해 주문클래스가 부가기능 적용 대상인지 먼저 확인하고, 부가기능을 삽입한다.
이를 통해 컴파일된 .class 파일에는 AspectJ를 통해 삽입된 부가기능 로직이 포함되게 된다.
이러한 컴파일 시점에 부가기능을 삽입하는 방법은 AspectJ 라이브러리가 필수적이고, 이를 적용하기 위해서는 복잡할 수 있다는 단점이 있다.
💡 AspectJ란?
AspectJ 라이브러리는 Java 코드에서 동작하는 객체에 대한 AOP 기술 제공을 목표로 하는 기술이다. 사실상 Java 진영에서는 표준 기술이라고 해도 무방하며, 성능이 뛰어나고 제공되는 기능 또한 다양하지만, Spring AOP에 비해서는 어렵고 복잡하다.
여기서, 핵심 기능에 부가기능에 삽입되는 것을 Weaving(위빙)이라고 한다.
2. 클래스 로딩 시점
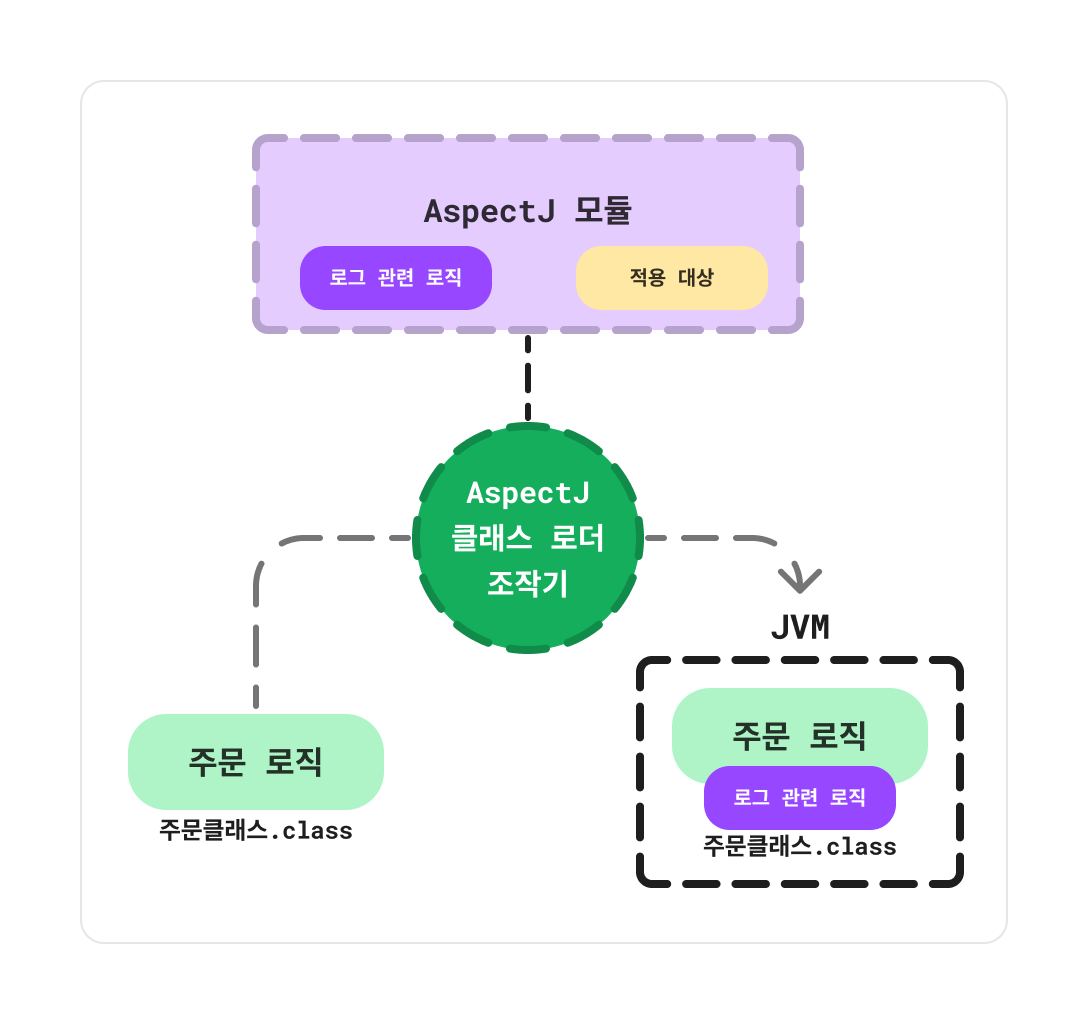
클래스 로딩 시점에 부가기능을 삽입하는 방법은 소스코드를 컴파일한 뒤, 클래스를 로딩하는 시점에 클래스의 정보를 변경하여 JVM에 올리게 된다.
Java는 .class 파일을 JVM 내부의 클래스 로더에 보관하는데 이때, JVM에 해당 파일을 올리기 전에 해당 파일의 정보를 조작할 수 있는 기능을 제공한다.
클래스 로딩 시점에 부가기능을 삽입하는 방법 또한 AspectJ 라이브러리를 통한 클래스 로더 조작기가 필요하다는 단점이 존재한다.
3. 런타임 시점
런타임 시점에 부가기능을 삽입하는 방법은 컴파일도 다 끝나고, 클래스 로더에 클래스도 올라간 후, 이미 Java의 main() 메서드가 실행되고 난 후에 Java가 제공하는 범위 안에서 부가기능을 적용하는 방법이다.
Spring에서는 컴파일 시점, 클래스 로딩 시점이 아닌 런타임 시점에 부가기능을 삽입하는 방법을 통해 AOP를 제공하고 있다.
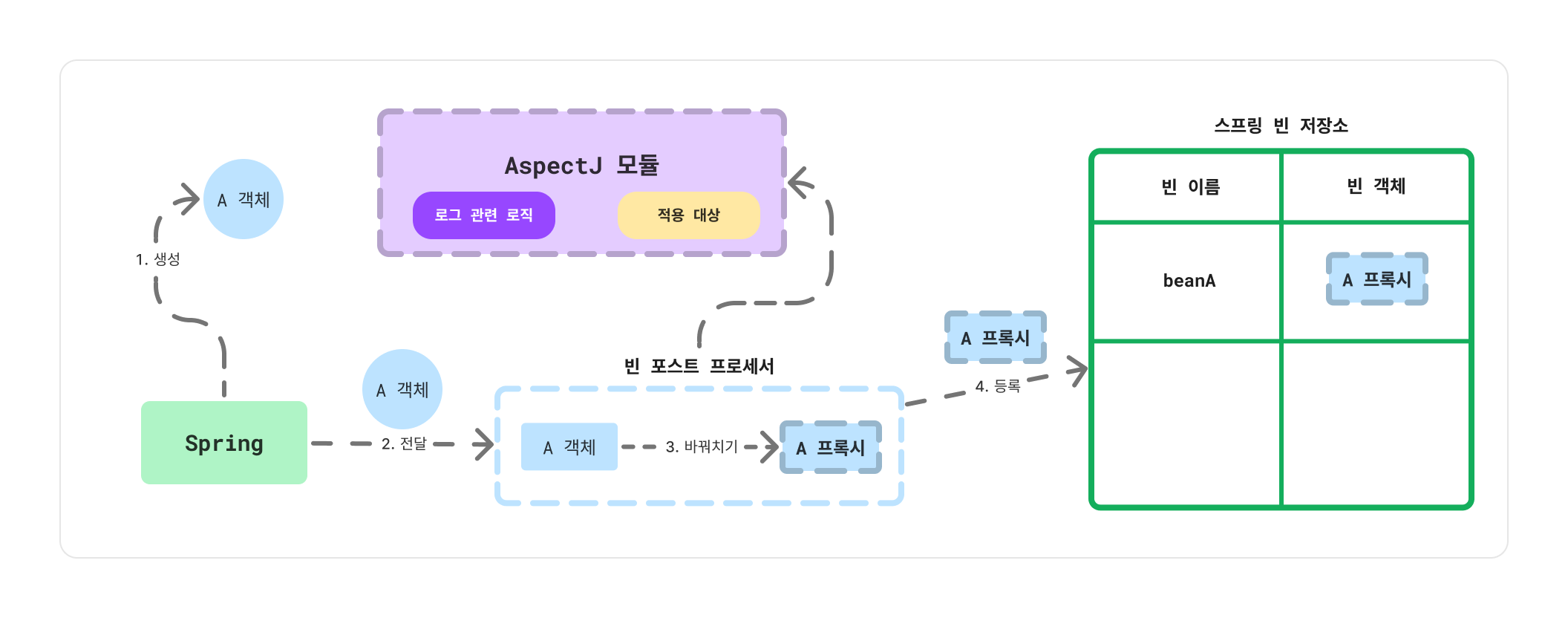
위 사진처럼 DI나 빈 포스트 프로세서와 같은 것들을 사용한다면 Proxy(프록시)를 통해 Spring Bean에 부가기능을 삽입할 수 있다.
Spring에서 A라는 객체의 빈을 만들 때, 빈 포스트 프로세서를 통해 A 타입의 프록시를 만들고 A 프록시를 Spring Bean으로 등록하게 된다. 중간에 A 프록시를 만들 때 AspectJ 모듈을 통해 로그 관련 로직과 같은 부가기능을 추가할 수 있다.
하지만, 프록시를 사용하기 때문에 아래와 같은 제약이 따른다.
- 프록시는 메서드 오버라이딩 개념으로 동작하기 때문에 메서드가 실행되는 시점에만 AOP를 통해 부가기능을 삽입할 수 있다.
- 스프링 빈으로 등록되어야만 AOP를 통해 부가기능을 삽입할 수 있다.
컴파일 시점이나 클래스 로딩 시점에 부가기능을 삽입할 때 보다 강력한 기능을 사용할 수는 없지만, AspectJ 라이브러리를 직접 사용하는 것이 아니라, Spring에서 해당 라이브러리의 문법을 차용하여 프록시 방식으로 AOP를 제공하기 때문에 AspectJ 컴파일러나 AspectJ 클래스 로더 조작기와 같은 복잡한 설정을 하지 않아도 Spring을 통해 보다 편하게 AOP를 적용할 수 있다.
🤔 프록시(Proxy)란?
자신이 클라이언트가 사용하려고 하는 실제 대상인 것처럼 위장하여 클라이언트의 요청을 받아주는 것(=대리인, 대리자)을 뜻한다. 프록시 패턴을 이용하면 결과적으로 AOP의 목적을 이룰 수 있게 된다.
- 기존 코드를 변경하지 않고도 요구사항을 만족시킬 수 있다.
- 중복 코드를 제거할 수 있다.
🛠️ Spring에서 AOP를 구현하는 방법들
- IoC/DI 컨테이너
- Dynamic Proxy
- 데코레이터 패턴이나 프록시 패턴
- 자동 프록시 생성 기법
- 빈 오브젝트의 후처리 조작 기법
Spring에서의 AOP를 사용하는 방법은?
이러한 AOP의 원칙을 Spring에서는 핵심 3요소 중 하나로 언급하고 있다. 그만큼 AOP를 강력하게 지원하고 있다는 의미로 보았는데 Spring에서 AOP를 어떻게 사용할 수 있는지 예제코드를 통해 설명해보려 한다.
implementation 'org.springframework.boot:spring-boot-starter-aop'여기서는 Spring Boot, Gradle을 이용해 예제를 작성하였다. Spring에서 AOP를 사용하기 위해 아래와 같은 의존성을 추가하였다.
데리버거.java
@Component
public class 데리버거 implements 햄버거 {
@Override
public void common_order() {
주문 관련 로직 // 핵심 관심사항
}
@Override
public void change_order() {
주문변경 관련 로직 // 핵심 관심사항
}
}먼저 데리버거 클래스를 보자.
Spring에서는 스프링 빈으로 등록된 객체들에만 AOP를 적용할 수 있기 때문에 데리버거 클래스를 @Component 어노테이션을 붙여 스프링 빈으로 등록하였다.
다음으로 실행시간을 측정하는 부가기능인 Aspect를 정의하고, common_order() 메서드에 이를 적용하여 메서드 실행시간을 측정할 수 있도록 Aspect 클래스를 작성해보자.
실행시간측정.java
@Component
@Aspect
public class 실행시간측정 {
@Pointcut("execution(* common*(..))")
pricate void pointCutTarget() {
}
@Around("pointCutTarget()")
public void measure(ProceedingJoinPoint proceedingJoinPoint) {
long start = System.currentTimeMillis();
System.out.println(System.currentTimeMillis() - start);
}
}위와 같이 실행시간측정이라는 Aspect 클래스를 작성하였다. 이 클래스 또한, 스프링 빈으로 등록되어야 하기 때문에 @Component 어노테이션을 붙였으며, 이 클래스가 Aspect 클래스임을 알려주기 위해 @Aspect어노테이션을 붙였다.
그리고 Aspect의 Advice를 담당하는 measure() 메서드를 보면 @Around 어노테이션을 사용하고 있는데, 이는 Advice를 구현하기 위한 종류 중 하나이다.
🤔 Spring이 제공하는 Advice의 종류
@Around(메소드 실행 전후): Advice가 Target 메소드를 감싸서 Target의 메소드 실행 전/후, 또는 Exception 발생 시점에 Advice 기능을 수행한다.@Before(이전): Advice Target 메소드가 실행되기 전에 Advice 기능을 수행한다.@After(이후): Target 메소드의 결과여부에 상관없이(즉 성공, 예외 관계없이) Target 메소드 실행 후 Advice 기능을 수행한다.@AfterReturning(성공 후): Target 메소드가 성공적으로 결과값을 반환 후에 Advice 기능을 수행한다.@AfterThrowing(예외 발생 이후) : Target 메소드 실행 중에 예외가 발생한 경우 Advice 기능을 수행한다.
위 코드에서는 @Around 어노테이션을 붙였기 때문에 메소드 실행 전이나 후에 실행 시간을 측정하는 코드를 작성했다고 볼 수 있다.
또한 common으로 시작하는 메서드에만 적용하기 위해 @Pointcut 어노테이션을 붙인 pointCutTarget() 메서드를 만들어 @Around 어노테이션의 설정에 추가하였다.
테스트코드.java
@SpringBootTest
public class 햄버거_테스트 {
@Autowired
private 햄버거 햄버거;
@Test
void test() {
햄버거.common_order();
햄버거.change_order();
}
}이제 이렇게 적용한 AOP가 잘 적용되는지 테스트코드를 통해서 검증해보면 common_order() 메서드에 한해서만 실행시간 측정이라는 부가기능이 실행되는 것을 알 수 있을 것이다.
결국, 해당 메서드를 실행하기 전과 후 시점에 관련 로그를 출력할 수 있고 기존 코드에 중복으로 작성되었던 중복 코드를 제거할 수 있었다.
이렇게 Spring에서 말하는 핵심요소 중 하나인 AOP라는 것에 대해서 배우고, 이해할 수 있었다. 기본적으로 AOP와 관련된 용어들이나 동작흐름을 알아야 Spring에서 AOP를 구현할 수 있음을 알게 되었고 개발을 하면서 중복 코드의 제거나 유지보수를 용이하게 하기 위해서는 AOP가 대부분 필수적 요소가 될 것이라고 느낄 수 있었다.
일관된 서비스 추상화, PSA
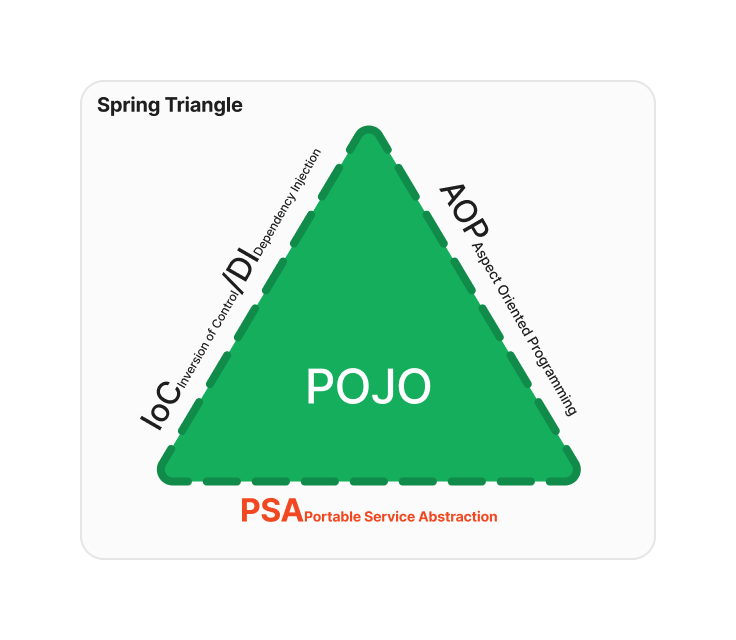
IoC와 DI, AOP를 모두 보았으니 마지막으로 PSA에 대해서 살펴보자.
PSA(Portable Service Abstraction)란?
Portable Service Abstraction를 직역하면 휴대용 서비스 추상화라고 하지만, 이것만 보아선 PSA가 뭔지 잘 몰랐다. 그리고 PSA를 정의하고 있는 많은 자료들은 PSA를 환경의 변화와 관계없이 일관된 방식의 기술로의 접근 환경을 제공하는 추상화 구조라고 말하고 있다. 그런데 이 말도 잘 이해가 가지 않았다.
여러 자료를 살펴본 후 내가 이해한 PSA는 다음과 같다.
어떠한 기술을 추상화하여 보다 편하게 사용할 수 있도록 하고, 이를 다른 곳에도 적용할 수 있도록 동일한 방식을 제공하는 방법이다.
백기선님은 PSA를 잘 만든 인터페이스라고도 표현하셨는데 이는 결국, 개발하는 환경이나 기술이 변하더라도 동일하거나 유사한 방식을 제공하는 것 아닐까?
PSA의 목적과 필요성에 대해서
PSA(Portable Service Abstraction)의 뜻을 살펴보면서 PSA의 목적과 필요성에 대해서 알아보자.
Service Abstraction(서비스 추상화)와 Portable(휴대용)의 의미
먼저 PSA에서 언급하고 있는 Service Abstraction(=서비스 추상화)는 무엇을 뜻하는 걸까?
서비스가 추상화되었다는 것은 서비스의 내용을 몰라도 그 서비스를 이용할 수 있다는 것이다. 이때, JDBC를 하나의 예로 들 수 있다.
Spring으로 웹 애플리케이션 개발을 할 때, 데이터베이스 접근 기술로 JDBC를 대부분 많이 이용해왔다. 그런데, JDBC가 어떻게 구현되어있는지도 모르고 관심도 없는 상태로 JDBC를 이용하지만 JDBC를 이용함으로 Spring에서 데이터베이스에 접근할 수 있었다.
만약 MySQL로 개발하다가 MariaDB로 데이터베이스 변경해야할 요구사항이 등장했다면, MySQL과 MariaDB의 사용방법이 같다고 볼 수 없기에 기존에 작성한 MySQL 코드를 변경해야한다.
그런데, Spring에서는 데이터베이스 접근방식을 동일하게 두고, MySQL에서 MariaDB로 데이터베이스를 변경할 수 있도록 해준다. 이는 Spring에서 데이터베이스 서비스를 추상화한 인터페이스를 제공해주기 때문이다.
*JDBC(ava DataBase Connectivity)는 Spring은 Java를 이용해 데이터베이스 접근방식을 규정한 인터페이스이다.
다음으로 이러한 서비스 추상화에 Portable(=휴대용)이라는 용어가 붙는다면 어떻게 이해할 수 있을까? Portable 은 휴대용이라는 의미를 가진다. Portable을 JDBC를 예로 이해해보면 다음과 같다.
JDBC를 기반으로 데이터베이스 접근 로직을 개발했다면, MySQL에서 MariaDB로 데이터베이스를 변경하더라고 데이터베이스 접근 로직의 변경 없이 사용할 수 있다.
데이터베이스 접근 로직의 변경 없이 데이터베이스 변경이 가능한 것은 JDBC가 추상화 계층으로서 데이터베이스 접근과 관련된 공통적인 인터페이스를 제공하기 때문이라는 것을 알 수 있다.
이를 통해, PSA는 특정 기술과 관련된 서비스를 추상화하는 목적을 가지고 서비스와 관련된 내용을 잘 모르더라도 동일한 방식으로 사용할 수 있도록 하여 개발자의 편의성을 향상시키기 위한 필요를 위해 등장했다고 이해할 수 있었다.
Spring PSA의 종류
Spring은 Spring Web MVC, Spring Transaction, Spring Cache 등 다양한 PSA를 제공한다. 이번 글에서는 Spring Web MVC와 Spring Transaction에 대해서만 간단하게 살펴보자.
Spring Web MVC
먼저 Spring Web MVC에서 PSA를 어떻게 제공하는지 알아보려고 한다. 이를 위해 필자의 프로젝트 코드를 인용하였다.
UserController.java
@RequiredArgsConstructor
@RestController
@RequestMapping("/api")
public class UserController {
private final UserService userService;
@PostMapping("/signup")
public ResponseEntity<SecurityMemberDto> signup(@Valid @RequestBody SecurityMemberDto request) {
return ResponseEntity.ok(userService.signup(request));
}
@GetMapping("/userinfo")
public ResponseEntity<SecurityMemberDto> getUserInfo(getUserInfoDto request) {
return ResponseEntity.ok(userService.getUserInfo(request));
}위 클래스는 @RestController 어노테이션이 붙어 있는데, @RestController 어노테이션을 사용하면 요청을 매핑할 수 있는 컨트롤러 역할을 수행할 수 있는 클래스가 된다.
그래서 위 컨트롤러 클래스에서는 @RequestMapping이나 @GetMapping, @PostMappong 어노테이션에 원하는 url을 설정하면 Spring이 자동으로 매핑을 해주기 때문에 해당 url로 요청이 올 경우 해당 url에 매핑된 메서드가 호출되어 적절한 응답을 주게 된다.
본래는 HttpServlet을 상속받고 doGet()이나 doPost() 메서드를 구현하는 작업을 해야한다. 하지만, Spring에 내장된 Tomcat을 사용하면서 HttpServelet을 사용하지 않아도 되는 이유는 앞서 보았듯이 @RequestMapping, @GetMapping 어노테이션을 사용하면 Spring이 자동으로 매핑해주기 때문이다.
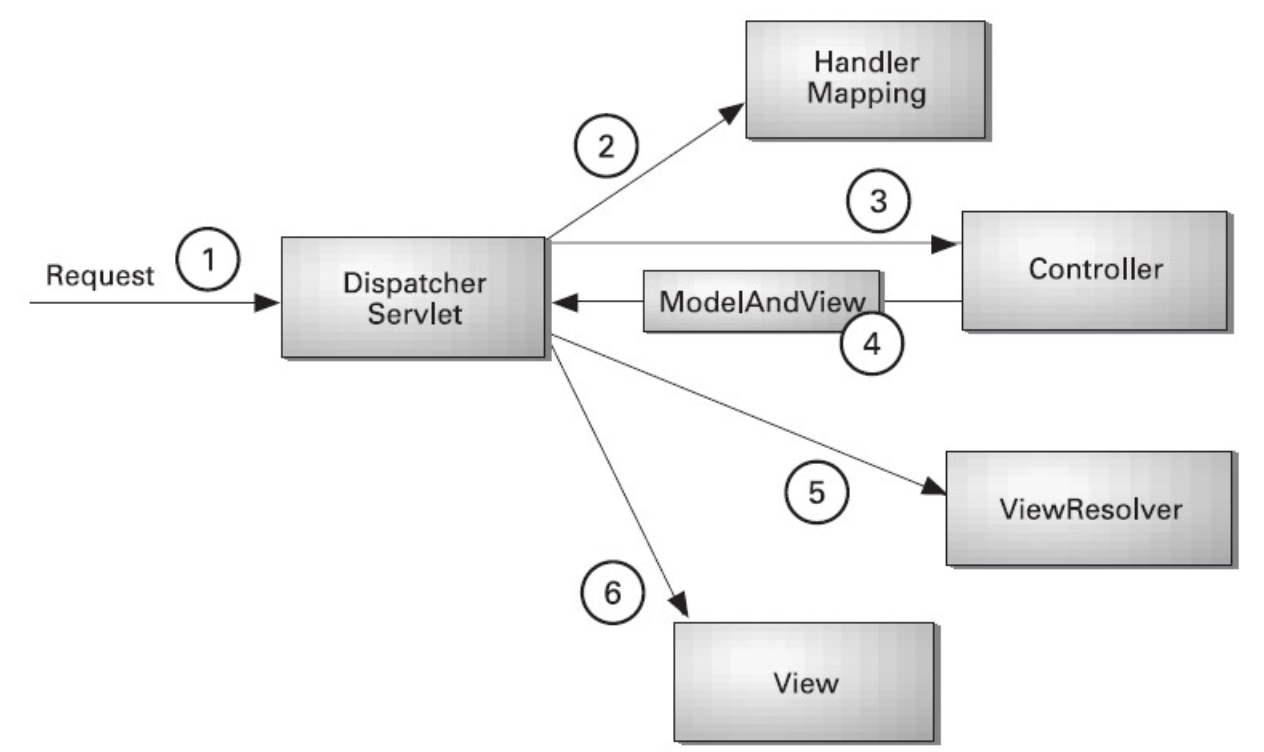
또한, 위 그림을 통해 Spring Web MVC를 통한 PSA의 이점을 다시 한번 생각해볼 수 있다. 위 그림은 Spring Web MVC의 동작 흐름인데, 1번을 보면 Request를 통해 가장 먼저 Dispatcher Servlet이 요청을 받게 된다.
그러나, 필자가 개발한 위 컨트롤러 코드를 보면 Dispatcher Servlet과 관련된 설정이나 코드를 작성하지 않았음에도 불구하고 정상적으로 Spring Web MVC를 사용할 수 있었다.
결국, 서블릿을 직접 개발하지 않아도 Spring Web MVC라는 PSA를 사용하면
@Controller, @RequestMapping과 같은 어노테이션과 같은 기술들을 기반으로 개발자가 서블릿을 보다 편하게 개발할 수 있으며, 기존 코드를 유지보수하기 쉬워진다. 그리고 PSA의 목적인 서비스 추상화를 통해 개발자에게 편의성을 제공하다는 점에 주목할 수 있다.
💡 서블릿(Servlet)이란?
서블릿은 클라이언트 요청을 처리하고, 그 결과를 다시 클라이언트에게 전송하는 Servlet 클래스의 구현 규칙을 지킨 Java 프로그램이다.
이전의 웹 프로그램들은 클라이언트의 요청에 대한 응답으로 만들어진 페이지를 넘겨 주었으나, 현재는 동적인 페이지를 가공하기 위해서 웹 서버가 다른 곳에 도움을 요청한 후 가공된 페이지를 넘겨주게 된다. 이때 서블릿을 사용하게 되면 웹 페이지를 동적으로 생성하여 클라이언트에게 반환해 줄 수 있다.
Spring Transaction
다음으로 데이터베이스와 관련된 PSA 중 하나인 Spring Transaction에 대해서 알아보자.
먼저 Transaction(트랜잭션)에 대해서 간단히 짚고 넘어가자. IT위키에서는 트랜잭션을 다음과 같이 정의하고 있다.
💬 Transaction(트랜잭션)이란?
트랜잭션은 데이터베이스 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위이다. 또한, 한꺼번에 수행되어야 할 일련의 연산이라는 의미이다.
이전부터 웹 개발을 통해 데이터베이스를 다루면서 트랜잭션을 깊게 사용해보지는 않았지만, 내가 이해하고 있는 트랜잭션에 대해서 간단히 설명해보면 다음과 같다.
데이터베이스와 데이터를 주고받는 특정한 작업을 위해 A, B, C 순서로 작업이 완료 되어야 한다고 하면, A, B, C 작업 중 하나라도 정상적으로 완료되지 않으면 모든 작업을 롤백 처리해야한다.
실제로 트랜잭션을 처리하기 위해서는 아래와 같은 SQL 코드들을 직접 개발자가 작성해야 한다고 한다.
try {
...
// DB 접속정보 생략
conn.setAutoCommit(false);
Statement stmt = conn.createStatetment();
// 쿼리문 작성
String SQL = "INSERT INTO Board VALUES (1, 1, 'title', 'lango')";
stmt.executeUpdate(SQL);
// 정상적이라면 쿼리 적용
conn.commit();
} catch(SQLException se) {
// 작업 중 하나라도 예외발생시 롤백 처리
conn.rollback();
}일일이 setAutoCommit()과 commit(), rollback() 메서드를 호출해야 하니 개발자 입장에서는 번거롭다고 느낄 수 있다.
그런데 Spring이 제공하는 @Transactional 어노테이션을 이용한다면 보다 쉽게 트랜잭션을 적용할 수 있다.
@Transactional
public void save(Board board);위 코드와 같이 Board라는 객체를 데이터베이스 저장하는 메소드와 같은 트랜잭션을 적용할 메소드에 @Transactional 어노테이션을 붙여주기만 하면 트랜잭션을 처리 로직을 보다 간단하게 작성할 수 있다.
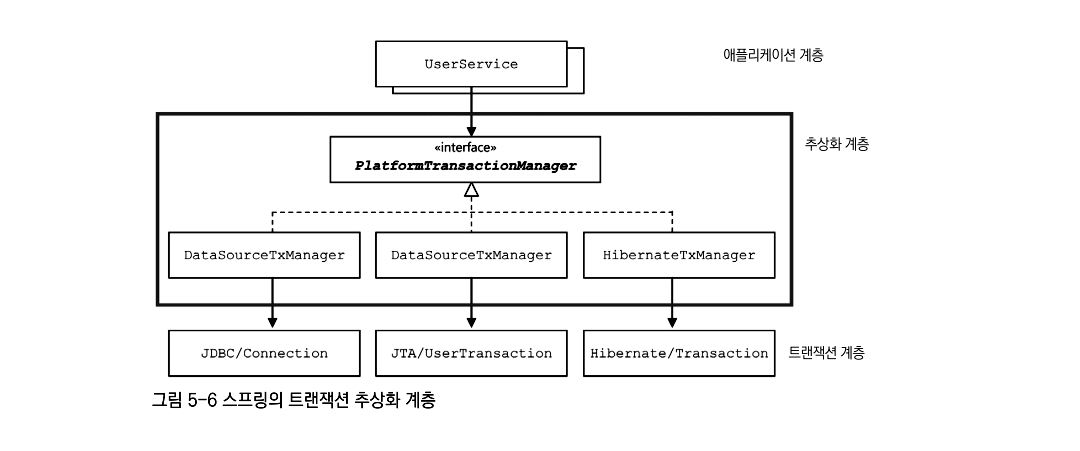
Spring Transaction의 핵심은 추상화 계층의 인터페이스인 FlatformTransactionManager 인터페이스를 두고 이를 구현하는 다양한 서비스의 비즈니스 로직을 추상화 해두었다는 점에 주목해야 한다.
그래서 개발자는 내부적으로 데이터베이스 매핑 전략에 구애받지 않고, 단순하게 FlatformTransactionManager를 선언하여 사용하면 된다. 이때, JDBC를 사용한다면 DatasourceTransactionManager를, JPA를 사용한다면 JpaTransactionManager를, Hibernate를 사용한다면HibernateTransactionManager로 언제든지 원하는 구현체로 변경하여 사용할 수 있게 된다.
이로 인해, 기존 비즈니스 로직과 관련된 코드를 변경하지 않고, 실제로 트랜잭션을 처리할 구현체를 사용하는 기술에 따라 유연하게 바꿀 수 있다.
이렇게 Spring Web MVC와 Spring Transaction이라는 Spring이 제공하는 PSA들을 살펴보니 서비스 추상화 전략을 통해 개발자에게 보다 편한 개발환경을 제공하기 위한 목적을 가지고 있음을 느낄 수 있었다.
마치며
저번 글에서는 Spring의 정의와 탄생배경, POJO 프로그래밍을 지향하는 Spring의 기본적인 개념들을 보았다면, 이번에는 Spring이 직접적으로 제안하고 강조하고 있는 핵심적인 요소인 IoC와 DI, AOP, PSA를 배우고 이해할 수 있었다.
Java와 Spring을 통한 개발을 해오면서 제대로 이해하지 못했거나, 이론으로 자세히 숙지하지 못했던 지식이나 내용들을 다시 한번 배우고, 정리할 수 있어서 개인적으로 뜻깊었던 학습시간이었던 것 같다.
물론, 교과서적인 내용만을 주로 다루고 개인적인 견해나 고민들을 많이 다루지는 못했지만, Spring에 대한 기초지식과 왜 Spring 개발을 하려고 하는지와 같은 대한 본질적인 질문에 이제는 답할 수 있을 것 같다.
다음 글에서는 Spring의 내부에서 어떻게 동작하는지 어떤 흐름으로 기능이 실행되는지에 대한 기술적인 내용을 배우고 이해한 후 기록을 남겨보려고 한다.
본 글은 학습하며 작성한 글이기에 틀리거나 잘못된 내용이 기록될 수 있습니다.
잘못된 내용이 있다면 언제든지 지적해주십시오. 다시 학습하여 정정하도록 하겠습니다.참고자료 출처
