
통계학
통계에 대해 간략히 배웠다.
(사실 너무 오랜만에 하는거라 기억이 잘 안나긴하지만 그래도 한번 했던거라 나름 무난하게 들을 수 있다)
Numpy는 안배워서 몰랐는데
알고보니 Numpy의 기본 내장함수를 이용하여 Python에서 어려운 연산을 쉽게 해결할 수 있었다.
여기서 왜 사람들이 Numpy를 찾아서 썼는지 알 수 있었다.
통계학 강의는 어렵지 않았던게 <확률과 통계>를 나름 집중해서 들었다면 충분히 이해할만한 내용이었다. 오늘까지만일수도...
- 기본 Numpy의 성능 (Numpy이용시 기존 Python 코드보다 효율성이 더 높음!)
start = time.time( ) -- 시작시간
Python Codes...
end = time.time( ) -- 끝나는 시간
print(end - start)
-- 코드 실행시간을 알 수 있음
-
기본 Numpy 활용
평균 - .mean( )
중앙값 - .median( ) -- 중앙에 위치한 값
표준편차 - .std( ) -- 데이터가 분포되어 있는 정도 -
난수 관련
난수 생성(실수) - .random.rand( )
정수 난수 생성 - .random.randint( 원하면 범위 지정 ) -
소수점 처리
f-string 이용해서 표기
print(f'평균은 {_mean:.3f}')
-- f-string에서 정수의 자리수 -> '0Nd' N에 원하는 숫자 적기
-- f-string에서 소수의 자리수 -> '0Nf' N에 원하는 숫자 적기
통계학 기초
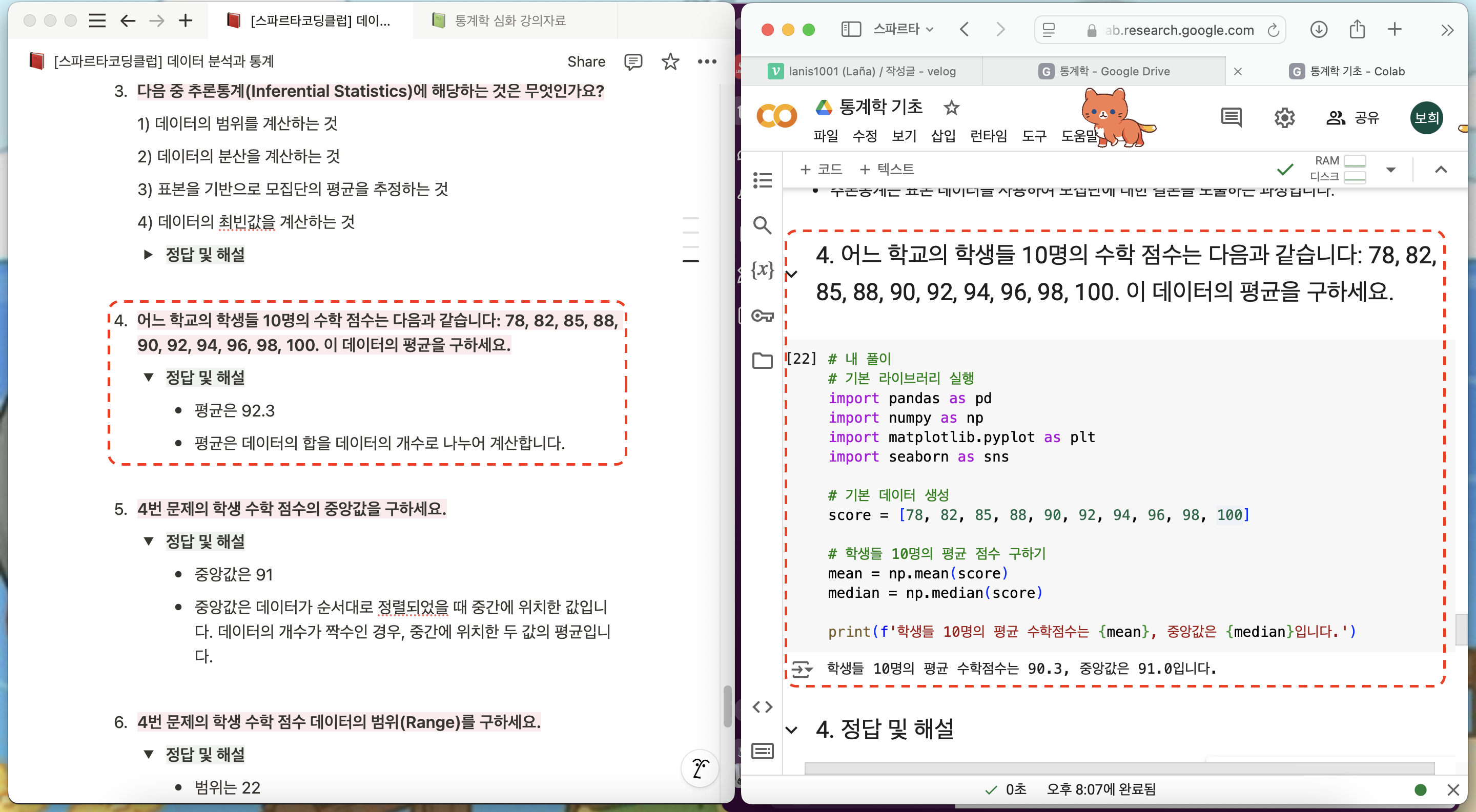
요고 학습자료에 정답이 달라서 계속 체크해봤는데 아무리 봐도 90.3이 평균으로 나온다..!
그래서 질문방에 올렸더니 90.3으로 나오는게 맞다구 해주셔서 그냥 내가 정답을 고쳐서 정답처리 하고 넘어갔다.
연습문제 오답 - 2주차
1주차는 틀린게 없어서 넘어갔다!
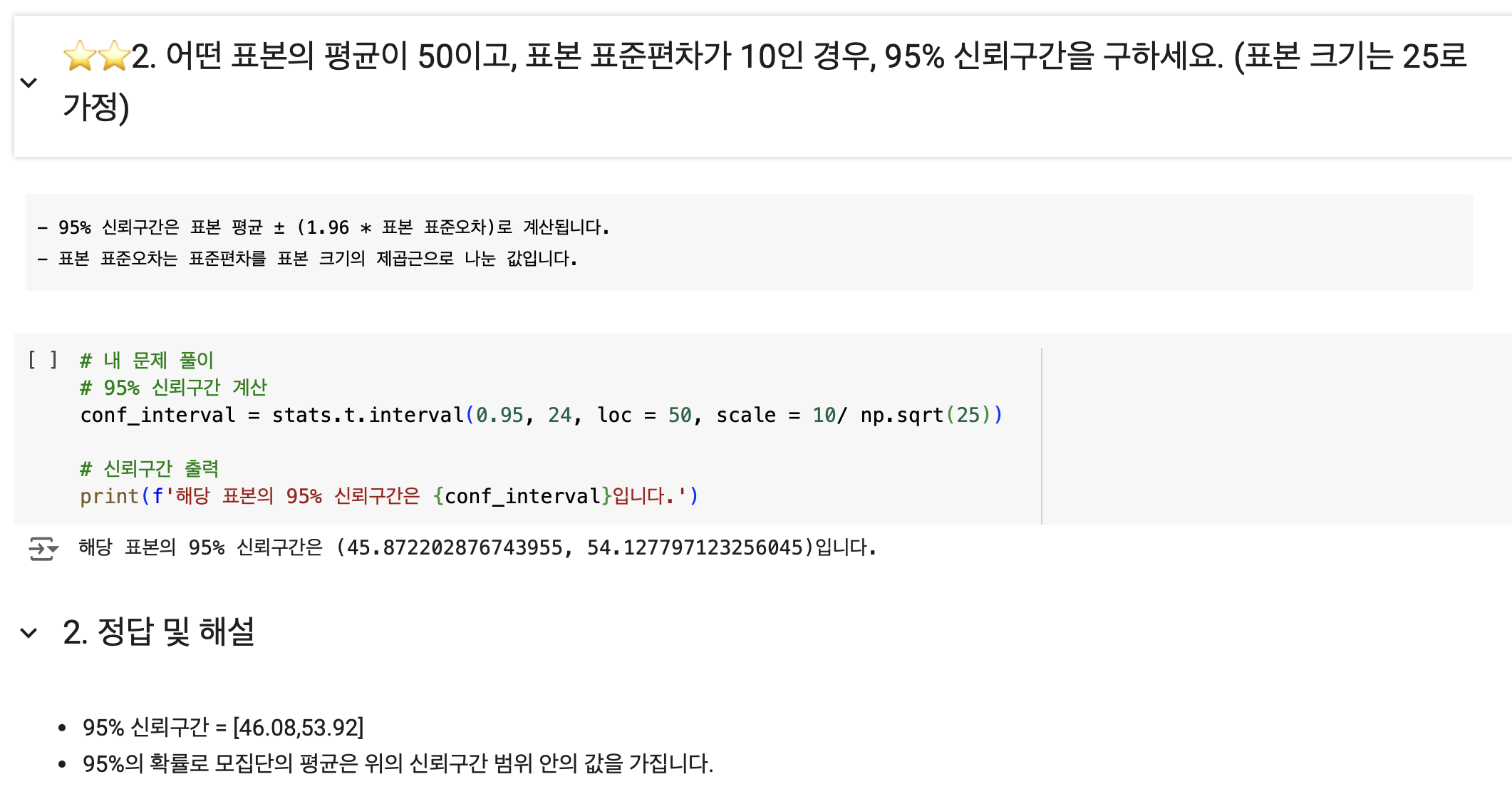
- 이 문제는 그냥 신뢰구간을 구할 때, 표준 편차를 표본 크기의 제곱으로 나누어야 한다라는 것만 알고 넘어가면 될듯 하다.

- 표준편차는 데이터의 분포정도를 나타내는 것을 말한다.

- 카이제곱분포는 범주형 데이터의 독립성 검정을 나타낸다.
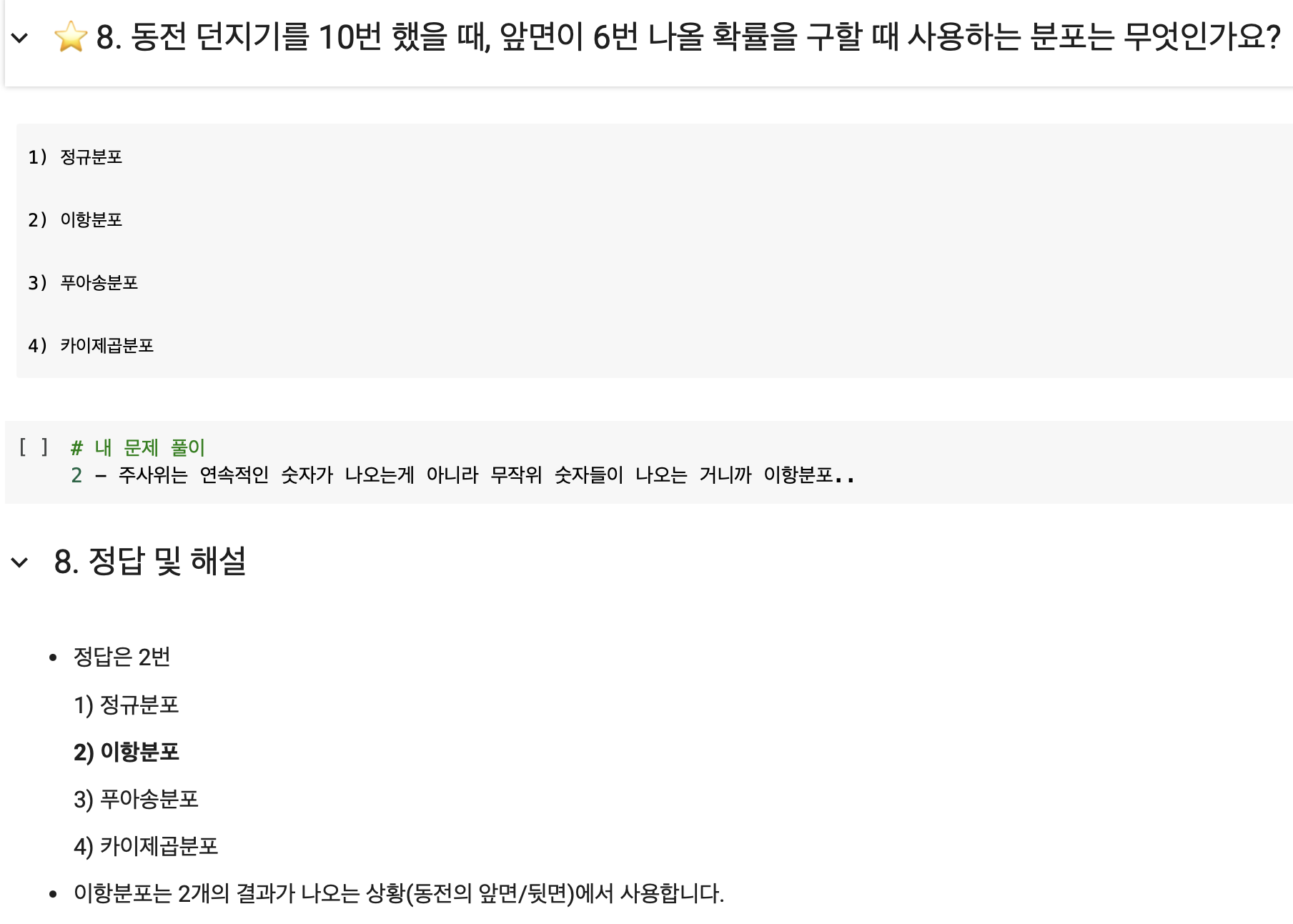
- 주사위를 무작위로 돌렸을 때, 나오는 숫자들은 연속적이지 않으니 이항분포로 나타낼 수 있다.
SQL, Python, Code Kata