
컬럼간 상관관계 분석
- 타겟 변수 간 상관관계 확인
# 범주형 변수 - 타켓 변수 간 상관관계 확인
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# ✅ 데이터 불러오기
train = pd.read_csv('train.csv')
# ✅ 1. 수치형 변수만 선택
numeric_cols = train.select_dtypes(include=[np.number]).columns.tolist()
# ✅ 2. 상관관계 행렬 계산
correlation_matrix = train[numeric_cols].corr()
# ✅ 3. 수치형 변수 간의 상관관계 분석 (Heatmap)
plt.figure(figsize=(12, 8))
sns.heatmap(correlation_matrix, annot=True, fmt=".2f", cmap="coolwarm", linewidths=0.5)
plt.title("📊 Feature Correlation Matrix", fontsize=14)
plt.show()
# ✅ 4. 타겟 변수(허위매물여부)와 개별 변수의 상관관계
correlation_with_target = correlation_matrix['허위매물여부'].sort_values(ascending=False)
print("🔎 타겟 변수와 상관관계가 높은 상위 10개 변수:")
print(correlation_with_target.head(10))
None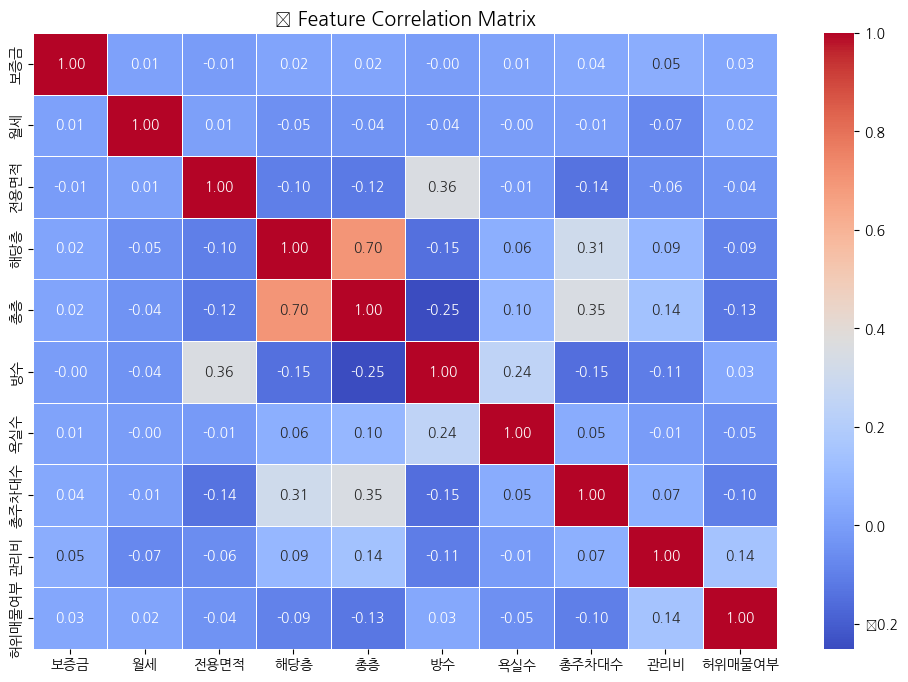
수치형 변수 간의 상관관계 Heatmap
'''
# 출력결과
🔎 타겟 변수와 상관관계가 높은 상위 10개 변수:
허위매물여부 1.000000
관리비 0.144892
방수 0.033380
보증금 0.027893
월세 0.021438
전용면적 -0.038733
욕실수 -0.049357
해당층 -0.090369
총주차대수 -0.103203
총층 -0.125895
Name: 허위매물여부, dtype: float64
'''- 상관관계가 높은 변수들의 분포 시각화
# 상관관계가 높은 변수들의 분포 시각화
import seaborn as sns
import matplotlib.pyplot as plt
# ✅ 한글 폰트 설정 (Colab 실행 후 한 번만 설정하면 됨)
plt.rc('font', family='NanumGothic')
# ✅ 허위매물여부에 따른 변수 분포 시각화
important_features = ["관리비", "방수", "보증금", "월세", "전용면적"]
fig, axes = plt.subplots(len(important_features), 2, figsize=(12, 20))
for i, feature in enumerate(important_features):
# Boxplot (허위매물여부별 분포 비교)
sns.boxplot(x=train["허위매물여부"], y=train[feature], ax=axes[i, 0])
axes[i, 0].set_title(f"[{feature}] Boxplot", fontsize=14)
# Histogram (전체 분포 확인)
sns.histplot(train[feature], kde=True, bins=30, ax=axes[i, 1])
axes[i, 1].set_title(f"[{feature}] Histogram", fontsize=14)
plt.tight_layout()
plt.show()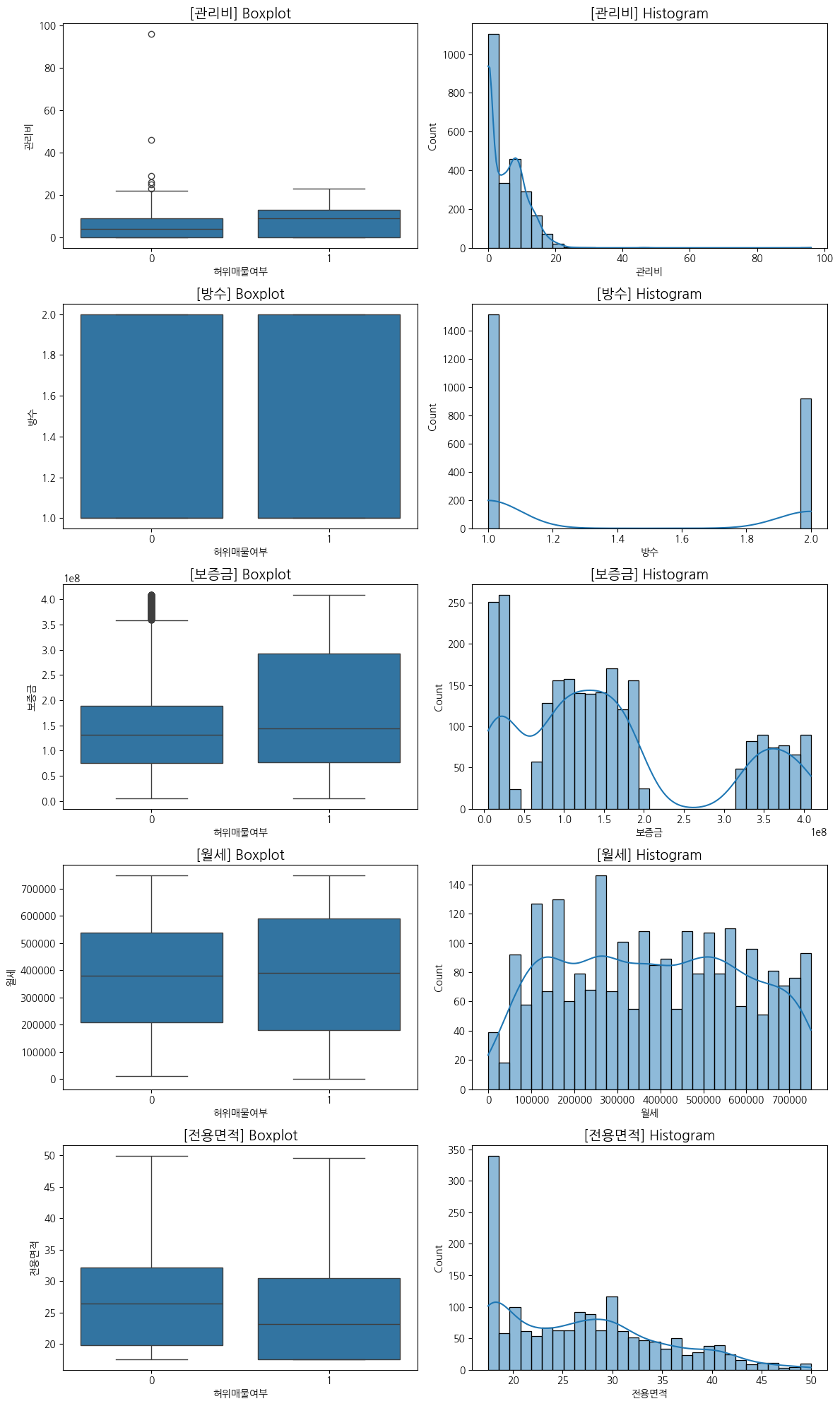
관리비와 전용면적은 데이터가 왼쪽으로 치우쳐져있으며, 방수와 보증금은 특정값만 존재하기도 하며, 월세는 0원부터 약 80만원 정도까지 다양하게 분포되어 있는 것을 알 수 있다.
- 월세 0원 처리
# 계약유형 컬럼 생성
train["계약유형"] = train["월세"].apply(lambda x: "전세" if x == 0 else "월세")
# 계약유형 분포 확인
print(train["계약유형"].value_counts())
# Boxplot: 계약유형별 보증금 분포 시각화
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 5))
sns.boxplot(x="계약유형", y="보증금", data=train)
plt.title("계약유형별 보증금 분포")
plt.show()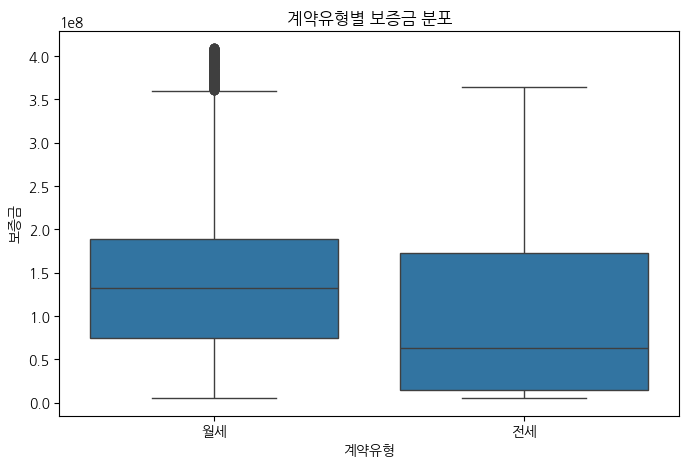
전세보다 월세가 훨씬 데이터가 더 많고 전세는 모델이 학습해서 분류하기엔 너무 적은 데이터라서 월세 0원 즉, (상식적으로) 전세인 데이터는 제거하는 것이 모델 학습에 효과적이라고 판단된다.
'''
계약유형
월세 2448
전세 4
Name: count, dtype: int64
'''최종 코드 취합
다들 주말동안 해본 모델링을 공유하고 이젠 각자 가장 정확도가 높게 나온(데이콘 기준) 코드를 모아서 하나의 코드로 취합하는 작업을 시작하였다.
아직 완벽하게 최종본이 나온 것은 아니지만 발표 자료도 만들며 해야했기 때문에 보다 효율적으로 프로젝트를 하기 위해서 두 팀으로 나누어 하나는 모델링 코드, 하나는 발표 자료 준비 이렇게 나누어서 작업을 진행하는 중이다.
최종적인 코드나 발표 자료 준비는 내일이나 모레쯤 마무리 될 듯 하다.
SQL, Python, Code Kata