🏠부동산 허위매물
우리팀이 고른 부동산 허위매물에 관한 분류 머신러닝은 실제 데이콘이라는 플랫폼에서 열리는 AI경진대회 중 하나로 실제 대회에 개인적으로 참가해서 각자 모델을 만들어보고 제출하여 정확도 점수를 가장 높게 받으면 된다.
주제
부동산 허위매물 분류 AI알고리즘 개발
설명
부동산 매물관련 정보가 포함된 데이터를 활용하여 허위매물을 분류하는 AI 알고리즘을 개발
규칙 및 대회 일정
-
규칙


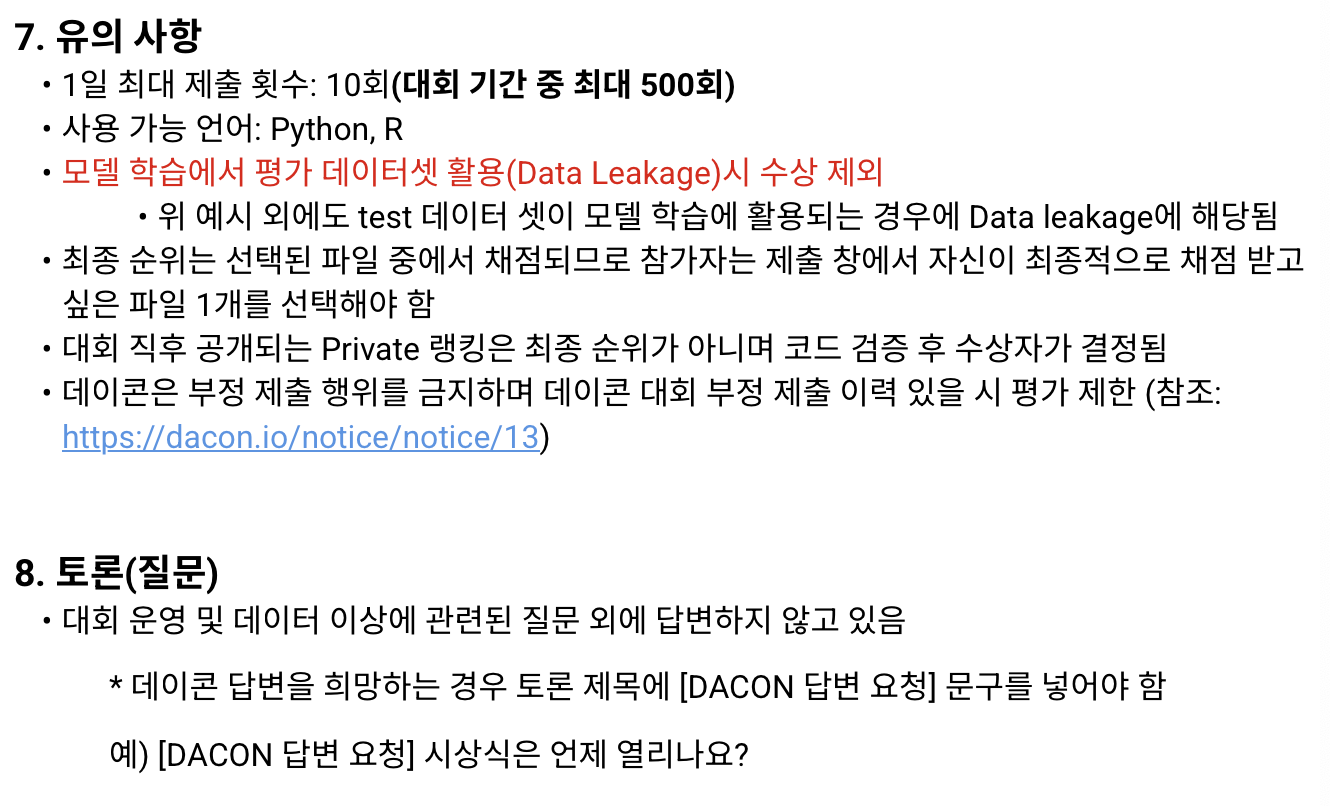
- F1 Score로 정확도 판별
- 개인으로만 참여가능, 외부 데이터 사용 불가
- F1 Score로 정확도 판별
-
대회 일정

1월 6일 ~ 2월 28일까지 제출 가능!!
데이터
-
trian.csv
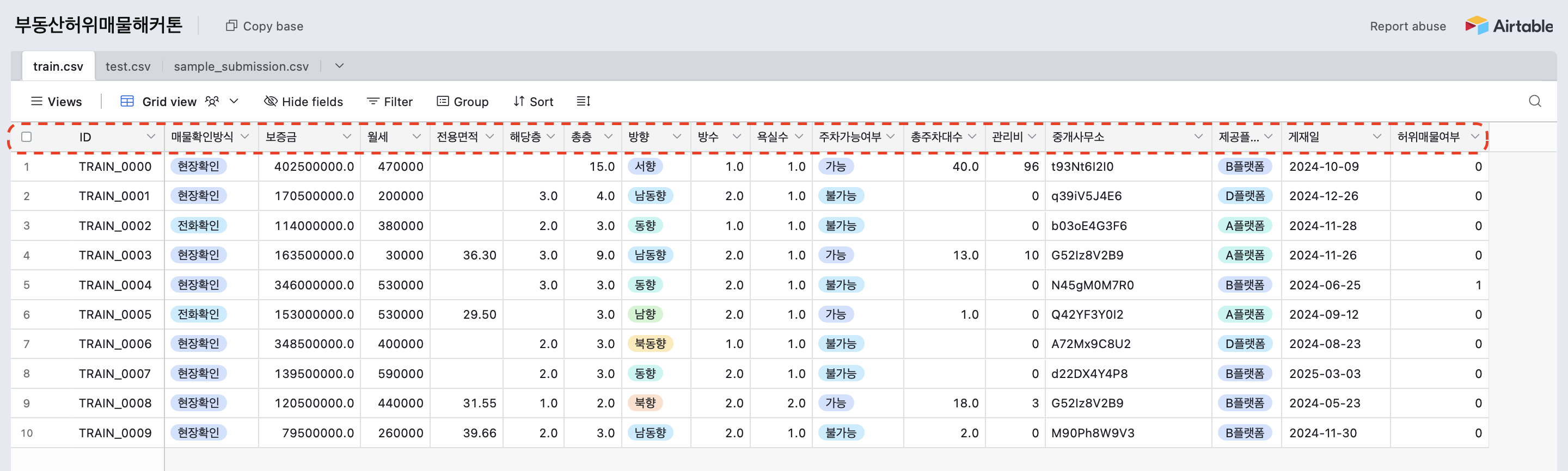
학습 데이터에는 허위매물여부(= 분류 모델이 맞춰야 하는 정답)이 나와있다.
-
test.csv
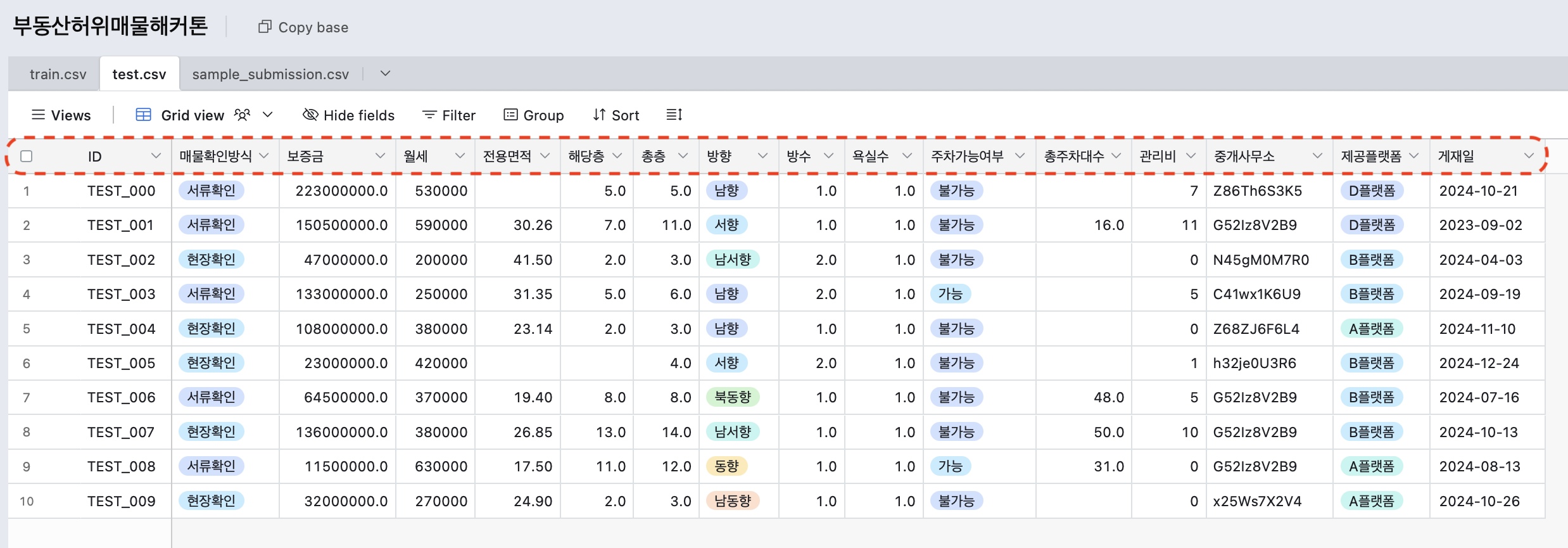
실험 데이터에는 허위매물여부가 빠져있다.
-
sample_submission.csv
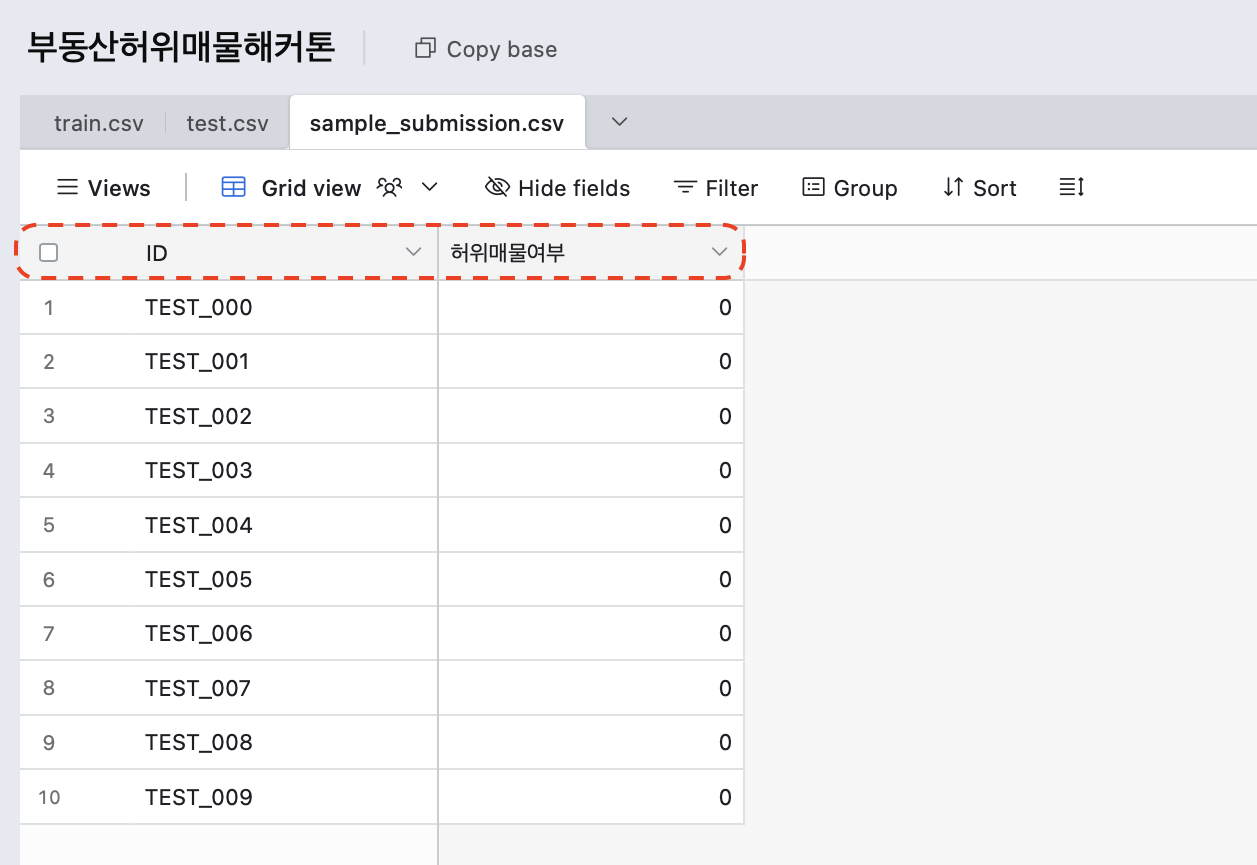
파일 제출 양식으로 모델 완성 후 ID - 허위매물여부 두 개의 컬럼만 매치해서 csv 파일로 만든다음 제출해야한다.
1차 제출

기본 랜덤포레스트 모델 / 정확도 0.6522 / 제출 당시 217등...
기본적인 모델이 어떻게 얼마나 학습할 수 있는지를 봤다.
0.5 이상을 하길래 조금만 더 하면 금방 점수가 높아질 수 있을 것이라 생각했다.
👩🏻💻 Python Code
성준님의 코드를 참고하여 기본 랜덤포레스트 모델을 만들었다.


- 기본 데이터셋 불러오기
# data 처리를 위한 library
import pandas as pd
import numpy as np
# 데이터 불러오기
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')- train 데이터 전처리
# train 데이터 전처리
# 0. 필요없는 컬럼 지우기 -- 'ID','방향','중개사무소','제공플랫폼','게재일'
train2 = train.drop(columns = ["ID","방향","중개사무소","제공플랫폼","게재일"])
# 1. '방수','욕실수' 결측치 1로 채우기
train2[['방수','욕실수']] = train[['방수','욕실수']].fillna(1) # 방수, 욕실수 결측치 1로 채우기
# 2. 조건에 따라 총주차대수 변경 -- 가능 -> 1, 불가능 -> 0
train2.loc[(train2['주차가능여부'] == '가능') & (train2['총주차대수'].isna()), '총주차대수'] = 1 # 주차 가능 & 결측치 = 1
train2.loc[(train2['주차가능여부'] == '불가능') & (train2['총주차대수'].isna()), '총주차대수'] = 0 # 주차 불가능 & 결측치 = 0
# 3. 전용면적
train2['전용면적'] = train2['전용면적'].fillna(train2['전용면적'].mean().round(1))
# 4. 해당층
train2['해당층'] = train2['해당층'].fillna(train2['해당층'].mean().round(1))- train 데이터 인코딩하기(라벨인코딩)
# '매물확인방식'(서류/현장확인) / '주차가능여부'(가능/불가능) => 라벨인코딩 (원핫->컬럼이 늘어남)
# 0. 라벨인코더 불러오기
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
# 1. 라벨 인코딩할 컬럼 리스트
cols = ['매물확인방식','주차가능여부']
# 2. 각 컬럼에 대해 라벨 인코딩 적용
for col in cols:
train2[col] = le.fit_transform(train2[col])
# 매물확인방식 = 0(현장확인)/1(전화확인)/2(서류확인)
# 주차가능여부 = 0(가능)/1(불가능)
''' [[인코딩 전 후 값 확인]]
# 변환 전 원본 값 확인
print("매물확인방식 원본 값:", train['매물확인방식'].unique())
print("주차가능여부 원본 값:", train['주차가능여부'].unique())
# 변환 후 적용
train['매물확인방식'] = le.fit_transform(train['매물확인방식'])
train['주차가능여부'] = le.fit_transform(train['주차가능여부'])
# 변환 후 값 확인
print("매물확인방식 변환 후 값:", train['매물확인방식'].unique())
print("주차가능여부 변환 후 값:", train['주차가능여부'].unique())
# 결과 확인 출력용
train2.head(10)
'''- test 데이터 전처리
# test 데이터 전처리
# 0. 필요없는 컬럼 지우기 -- 'ID','방향','중개사무소','제공플랫폼','게재일'
test2 = test.drop(columns = ["ID","방향","중개사무소","제공플랫폼","게재일"])
# 1. '방수','욕실수' 결측치 1로 채우기
test2[['방수','욕실수']] = test[['방수','욕실수']].fillna(1) # 방수, 욕실수 결측치 1로 채우기
# 2. 조건에 따라 총주차대수 변경 -- 가능 -> 1, 불가능 -> 0
test2.loc[(test2['주차가능여부'] == '가능') & (test2['총주차대수'].isna()), '총주차대수'] = 1 # 주차 가능 & 결측치 = 1
test2.loc[(test2['주차가능여부'] == '불가능') & (test2['총주차대수'].isna()), '총주차대수'] = 0 # 주차 불가능 & 결측치 = 0
# 3. 전용면적
test2['전용면적'] = test2['전용면적'].fillna(test2['전용면적'].mean().round(1))
# 4. 해당층
test2['해당층'] = test2['해당층'].fillna(test2['해당층'].mean().round(1))- test 데이터 인코딩하기(라벨인코딩)
# '매물확인방식'(서류/현장확인) / '주차가능여부'(가능/불가능) => 라벨인코딩 (원핫->컬럼이 늘어남)
# 0. 라벨인코더 불러오기
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
# 1. 라벨 인코딩할 컬럼 리스트
cols = ['매물확인방식','주차가능여부']
# 2. 각 컬럼에 대해 라벨 인코딩 적용
for col in cols:
test2[col] = le.fit_transform(test2[col])
# 매물확인방식 = 0(현장확인)/1(전화확인)/2(서류확인)
# 주차가능여부 = 0(가능)/1(불가능)
''' [[인코딩 전 후 값 확인]]
# 변환 전 원본 값 확인
print("매물확인방식 원본 값:", test['매물확인방식'].unique())
print("주차가능여부 원본 값:", test['주차가능여부'].unique())
# 변환 후 적용
test['매물확인방식'] = le.fit_transform(test['매물확인방식'])
test['주차가능여부'] = le.fit_transform(test['주차가능여부'])
# 변환 후 값 확인
print("매물확인방식 변환 후 값:", test['매물확인방식'].unique())
print("주차가능여부 변환 후 값:", test['주차가능여부'].unique())
# 결과 확인 출력용
print(test2.head(10))
'''- 랜덤 포레스트 모델 학습 및 예측 결과
# 랜덤 포레스트 기본 라이브러리 불러오기
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 독립변수(X), 종속변수(y) 설정
X_train = train2.drop(columns=['허위매물여부'])
y_train = train2['허위매물여부']
# 랜덤포레스트 회귀 모델 생성 및 학습
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train,y_train)
# 예측 및 평가
y_pred = rf.predict(test2)
# 예측 결과 저장
final = pd.DataFrame({"허위매물여부" : y_pred}, index = test["ID"])
final
final.to_csv("데이콘허위매물(1).csv")2차 제출

하이퍼파라미터 랜덤으로 최적의 조합 추가 / 정확도 0.83647 / 제출 당시 93등
성준님의 코드를 공유받고 각자 해본 결과 라영님의 기본 모델이 정확도 0.81로 가장 높은 정확도를 가져서 그걸 스켈레톤 코드로 활용하기로 하였다.
👩🏻💻 Python Code
라영님의 코드 중 일부만 발췌...

라영님의 코드 + 내가 추가한 것 이 0.83이 나와서 어떤 부분이 달라졌는지 확인해보았다.
-
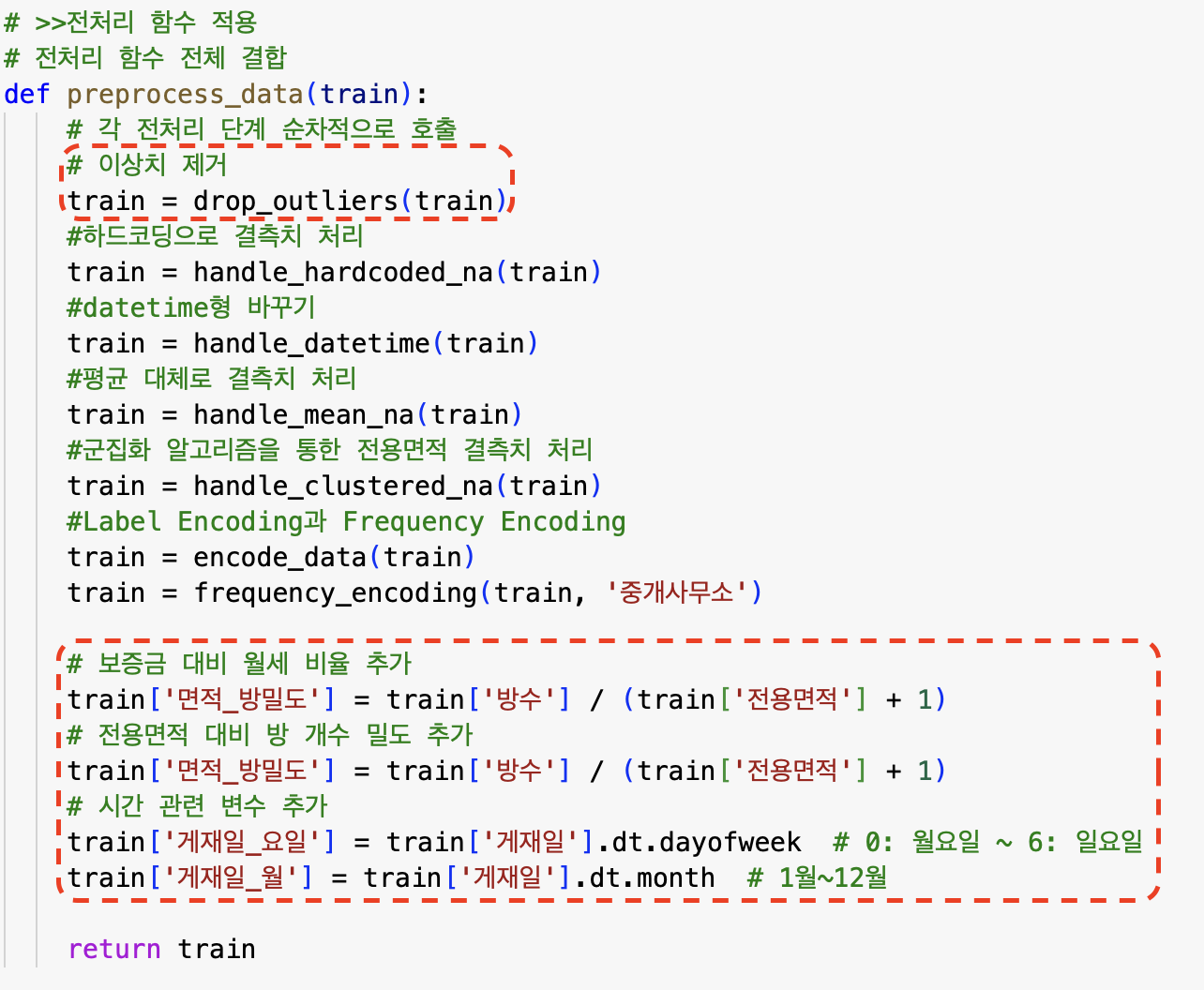
보증금 이상치 처리
-
총주차대수 -> 중앙값 / 총층,해당층 => 그룹별 평균 해당층 결측치 대체

-
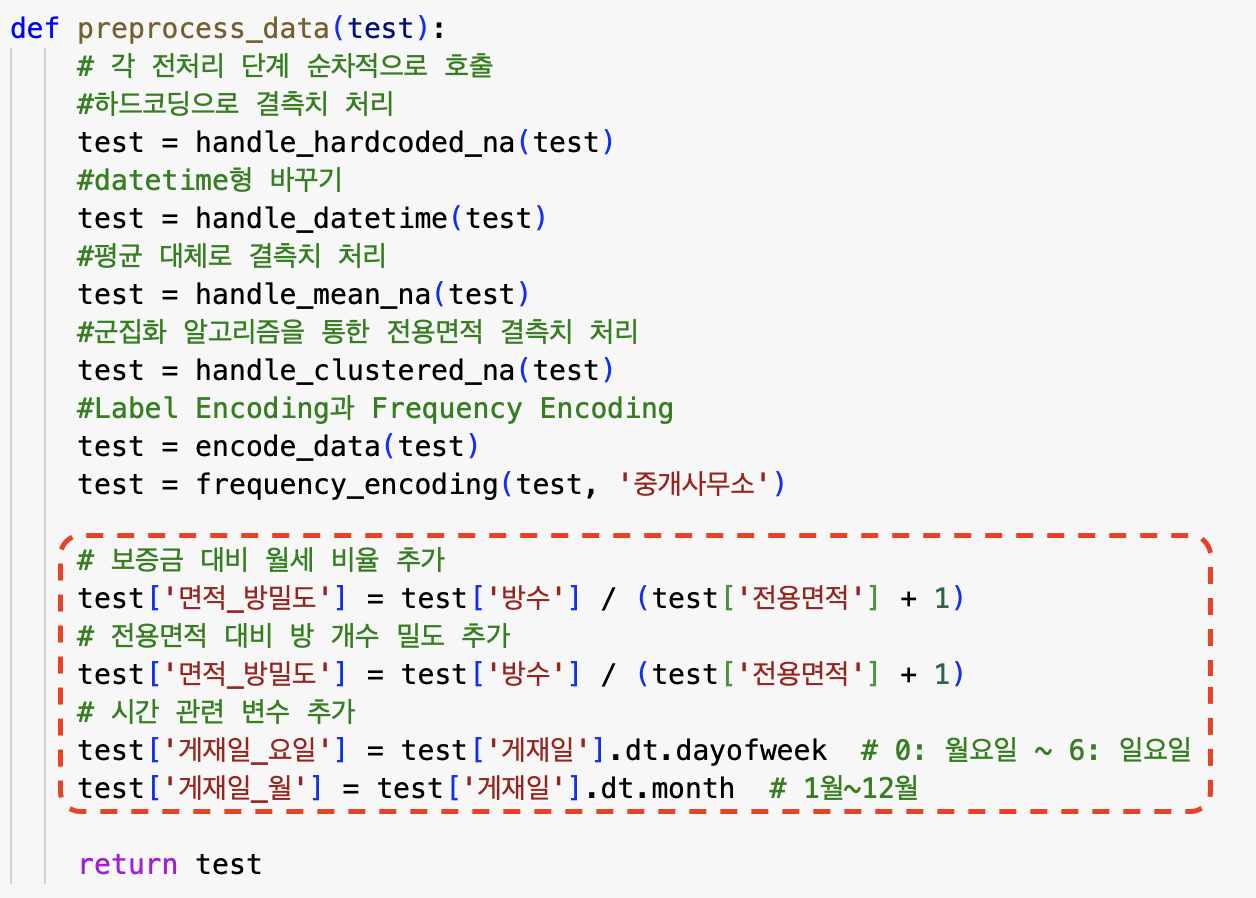
보증금 대비 월세 비율, 전용면적 대비 방 개수 밀도, 시관관련 변수 추가
-
모델링 학습시 랜덤 서치 적용 -> 최적의 하이퍼파라미터 출력 및 학습
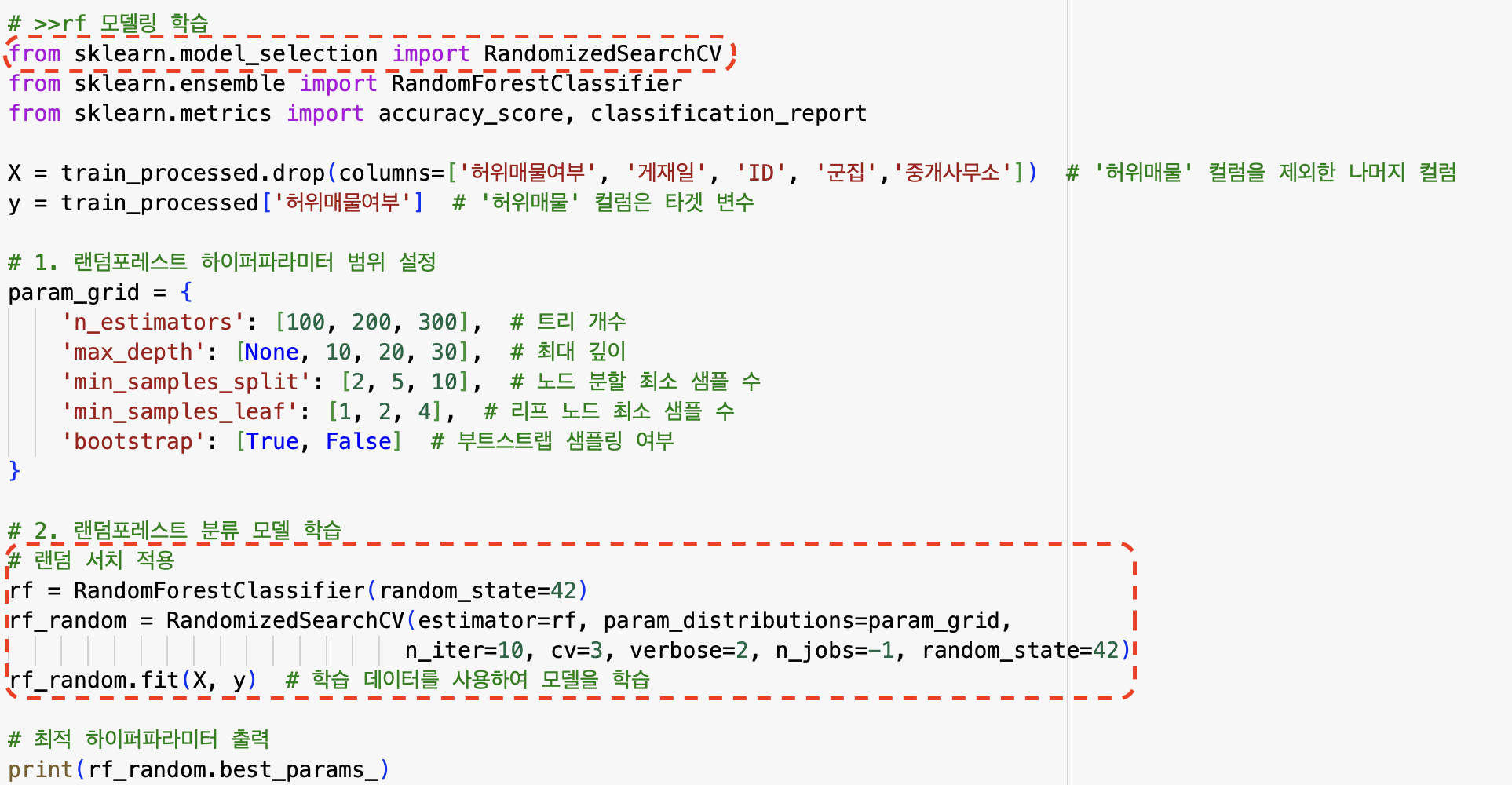
-
train -> 이상치 처리 / test -> 이상치 처리 놉

이렇게 5가지가 달라진거였다! 가장 크게 적용된 것은 새로운 변수를 생성하고 하이퍼파라미터를 랜덤으로 돌려서 최적의 조합을 기본 모델에 추가한 것이었다.
3차 제출

처음부터 다시 해본 모델 / 정확도 0.467826087 / 기본 제출 파일과 점수가 똑같음 = 등수 없음
👩🏻💻 Python Code
가장 마지막으로 제출한 3차는 놀랍게도 기본 제출 양식과 똑같은 0.46으로 기존 모델보다 절반이상 줄었다..
아마 점수가 크게 오르지 않아서 처음부터 다시 했더니 저런 점수가 나온 것 같다
- 데이터 전처리
# >> 전처리 과정 함수
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.cluster import KMeans
# ✅ 결측치 처리 함수 정의
def handle_na(train):
train = train.copy()
# 중앙값 대체
train["전용면적"].fillna(train["전용면적"].median(), inplace=True)
train["총주차대수"].fillna(train["총주차대수"].median(), inplace=True)
# 해당층은 총층의 중앙값으로 대체
train["해당층"].fillna(train.groupby("총층")["해당층"].transform("median"), inplace=True)
# 방수, 욕실수는 1로 대체
train["방수"].fillna(1, inplace=True)
train["욕실수"].fillna(1, inplace=True)
# 총층은 최빈값으로 대체
train["총층"].fillna(train["총층"].mode()[0], inplace=True)
return train
# ✅ train, test 데이터 결측치 처리 적용
train_cleaned = handle_na(train)
test_cleaned = handle_na(test)
# ✅ 남은 해당층 결측치 처리 (총층의 최빈값으로 대체)
def handle_remaining_na(train):
train = train.copy()
# 해당층 남은 결측치는 총층의 최빈값으로 대체
train["해당층"].fillna(train["총층"].mode()[0], inplace=True)
return train
# 최종 결측치 처리 적용
train_final = handle_remaining_na(train_cleaned)
test_final = handle_remaining_na(test_cleaned)
from sklearn.impute import SimpleImputer
# ✅ 결측치 처리 함수 정의
def handle_missing_values(train):
train = train.copy()
# ✅ 수치형 변수 - 중앙값 대체
numeric_cols = ["총주차대수", "전용면적"]
median_imputer = SimpleImputer(strategy="median")
train[numeric_cols] = median_imputer.fit_transform(train[numeric_cols])
# ✅ 수치형 변수 - 최빈값 대체
mode_cols = ["방수", "욕실수"]
mode_imputer = SimpleImputer(strategy="most_frequent")
train[mode_cols] = mode_imputer.fit_transform(train[mode_cols])
# ✅ 해당층 결측치 처리 - 같은 총층 그룹 내 중앙값 대체
train["해당층"] = train.groupby("총층")["해당층"].transform(lambda x: x.fillna(x.median()))
# ✅ 범주형 변수 - 결측치 "Unknown" 대체
categorical_cols = ["방향", "중개사무소", "제공플랫폼"]
train[categorical_cols] = train[categorical_cols].fillna("Unknown")
return train
# ✅ 결측치 처리 적용
train_cleaned = handle_missing_values(train)
# ✅ 결측치 처리 후 데이터 확인
print(train_cleaned.isnull().sum())
train = pd.read_csv('train.csv')
train.head()
from datetime import datetime- Feature Engineering 함수
# ✅ Feature Engineering 함수 정의
def feature_engineering(train):
train = train.copy()
# ✅ 보증금-월세 비율
train["보증금_월세비율"] = train["보증금"] / (train["월세"] + 1)
# ✅ 면적 대비 방 개수 밀도
train["면적_방밀도"] = train["방수"] / (train["전용면적"] + 1)
# ✅ 날짜 관련 Feature
train["게재일"] = pd.to_datetime(train["게재일"])
train["게재일_차이"] = (datetime.today() - train["게재일"]).dt.days
train["게재일_요일"] = train["게재일"].dt.dayofweek # 0(월) ~ 6(일)
train["게재일_월"] = train["게재일"].dt.month
# ✅ 층 관련 Feature
train["층비율"] = train["해당층"] / (train["총층"] + 1)
# ✅ 주차 가능 여부 (0/1 변환)
train["주차가능여부"] = (train["총주차대수"] > 0).astype(int)
return train
# ✅ Feature Engineering 적용
train_featured = feature_engineering(train_cleaned)
# ✅ 생성된 Feature 확인
print(train_featured[["보증금_월세비율", "면적_방밀도", "게재일_차이", "층비율", "주차가능여부"]].head())- Target & One-Hot & Label Encoding
# >> 타겟 인코딩 코드
from sklearn.model_selection import KFold
# ✅ 타겟 인코딩 함수
def target_encoding(train, test, target_col, categorical_cols, smoothing=10):
train = train.copy()
test = test.copy()
# ✅ KFold 설정 (과적합 방지)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for col in categorical_cols:
target_mean = train.groupby(col)[target_col].mean()
global_mean = train[target_col].mean() # 전체 평균
# ✅ 스무딩 적용
train[f"{col}_타겟인코딩"] = train[col].map(lambda x: (target_mean.get(x, global_mean) * len(train[train[col] == x]) + global_mean * smoothing) / (len(train[train[col] == x]) + smoothing))
# ✅ test 데이터에도 같은 매핑 적용
test[f"{col}_타겟인코딩"] = test[col].map(lambda x: target_mean.get(x, global_mean))
return train, test
# ✅ 타겟 인코딩 적용
categorical_cols = ["제공플랫폼", "매물확인방식", "중개사무소"]
train_encoded, test_encoded = target_encoding(train_featured, test_cleaned, target_col="허위매물여부", categorical_cols=categorical_cols)
# ✅ 변환 결과 확인
print(train_encoded[[f"{col}_타겟인코딩" for col in categorical_cols]].head())
# >> 범주형 변수 인코딩
from sklearn.preprocessing import LabelEncoder
# ✅ 범주형 변수 인코딩 함수
def encode_categorical_features(train, test):
train = train.copy()
test = test.copy()
# One-Hot Encoding (주차가능여부)
train = pd.get_dummies(train, columns=['주차가능여부'], drop_first=True)
test = pd.get_dummies(test, columns=['주차가능여부'], drop_first=True)
# Label Encoding (방향, 매물확인방식)
le = LabelEncoder()
# 학습 데이터에서 fit
train['방향'] = le.fit_transform(train['방향'].astype(str))
train['매물확인방식'] = le.fit_transform(train['매물확인방식'].astype(str))
# 테스트 데이터에서 transform, 학습 데이터에 없던 레이블은 "UNKNOWN" 또는 -1로 처리
test['방향'] = test['방향'].apply(lambda x: le.transform([x])[0] if x in le.classes_ else -1)
test['매물확인방식'] = test['매물확인방식'].apply(lambda x: le.transform([x])[0] if x in le.classes_ else -1)
return train, test
# ✅ 범주형 변수 인코딩 적용
train_encoded, test_encoded = encode_categorical_features(train_encoded, test_encoded)
# ✅ 변환 결과 확인
print(train_encoded.head())- Feature Importance
# >> Feature 중요도 확인
from sklearn.ensemble import RandomForestClassifier
# ✅ Feature, Target 정의
X = train_encoded.drop(columns=['허위매물여부', 'ID', '게재일'], errors='ignore')
y = train_encoded['허위매물여부']
# ✅ 랜덤포레스트 모델 학습
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)
# ✅ Feature 중요도 추출
feature_importances = pd.DataFrame({
'Feature': X.columns,
'Importance': rf.feature_importances_
}).sort_values(by='Importance', ascending=False)
# ✅ 중요도 높은 Feature 상위 15개 선택
top_features = feature_importances['Feature'].head(15).tolist()
print("✅ 선택된 중요 Feature 목록:", top_features)
# ✅ 중요 Feature만 선택하여 데이터셋 업데이트
X_selected = train_encoded[top_features]
X_test_selected = test_encoded[top_features]- test 데이터가 train 데이터와 맞지 않을 때 디버깅
# ✅ test_encoded에 존재하는 valid_top_features만 선택
valid_top_features_test = [feature for feature in valid_top_features if feature in test_encoded.columns]
print("✅ test_encoded에 존재하는 유효한 선택된 중요 Feature 목록:", valid_top_features_test)
# ✅ test 데이터셋에서 유효한 중요 Feature만 선택
X_test_selected = test_encoded[valid_top_features_test]
# One-Hot Encoding 다시 확인
train_encoded = pd.get_dummies(train_encoded, drop_first=True)
test_encoded = pd.get_dummies(test_encoded, drop_first=True)
# train과 test 데이터셋의 컬럼을 비교하여 누락된 컬럼 찾기
missing_in_test = [col for col in top_features if col not in test_encoded.columns]
print("✅ test_encoded에 없는 컬럼:", missing_in_test)
# test_encoded에 없는 컬럼은 제외한 valid_top_features
valid_top_features_test = [feature for feature in top_features if feature not in missing_in_test]
# 유효한 feature로 test 데이터셋 업데이트
X_test_selected = test_encoded[valid_top_features_test]
# test_encoded에 존재하는 컬럼만 선택
valid_top_features_test = [feature for feature in top_features if feature in test_encoded.columns]
# 유효한 feature로 test 데이터셋 업데이트
X_test_selected = test_encoded[valid_top_features_test]
# 유효한 feature로 train 데이터셋 업데이트
X_selected = train_encoded[valid_top_features_test]
# test_encoded에 누락된 컬럼을 0으로 추가
missing_in_test = [col for col in top_features if col not in test_encoded.columns]
for col in missing_in_test:
test_encoded[col] = 0
# 이제 동일한 컬럼이 있는 train_encoded와 test_encoded를 사용할 수 있습니다.
X_selected = train_encoded[top_features]
X_test_selected = test_encoded[top_features]- Random Forest Model + Hyper Parameters
# >> 하이퍼파라미터 튜닝
from sklearn.model_selection import GridSearchCV
# ✅ 랜덤포레스트 하이퍼파라미터 검색 공간 설정
param_grid = {
'n_estimators': [100, 200, 300], # 트리 개수
'max_depth': [10, 20, 30, None], # 최대 깊이
'min_samples_split': [2, 5, 10], # 분할 최소 샘플 수
'min_samples_leaf': [1, 2, 4], # 리프 노드 최소 샘플 수
'bootstrap': [True, False] # 부트스트랩 샘플링 여부
}
# ✅ GridSearchCV 실행 (교차 검증 3-Fold)
rf_grid = GridSearchCV(RandomForestClassifier(random_state=42),
param_grid,
cv=3,
n_jobs=-1,
verbose=2)
# ✅ 모델 학습 (Feature Selection 된 데이터 사용)
rf_grid.fit(X_selected, y)
# ✅ 최적 하이퍼파라미터 출력
print("✅ Best Parameters:", rf_grid.best_params_)
# ✅ 최적 모델 저장
best_rf = rf_grid.best_estimator_
# ✅ 최적 모델로 재학습
best_rf.fit(X_selected, y)
# ✅ 예측 수행
test_pred = best_rf.predict(X_test_selected)
# ✅ 결과 저장
submission = pd.DataFrame({
'ID': test['ID'],
'허위매물여부': test_pred
})
submission.to_csv('데이콘허위매물.csv', index=False, encoding='utf-8-sig')진짜.. EDA부터 다시 해서 컬럼들의 상관관계를 살펴봐야하나 보다...
마무리
4차 제출부터 Coming Soon...