
<Pandas 2회차>
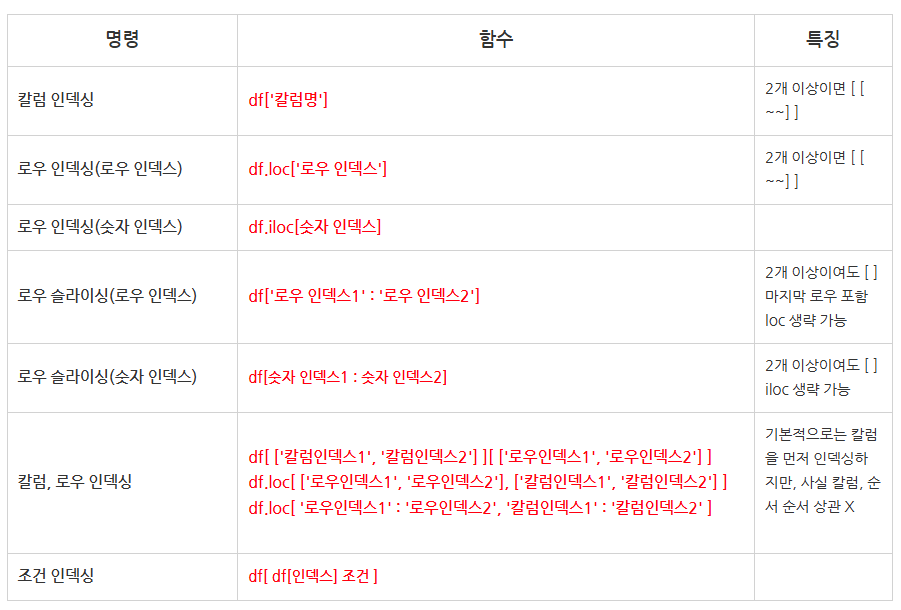
데이터 선택하기
1. 고유값 확인 unique( )
#orders 에서 "주문상태" 고유값 확인
orders["주문상태"].unique()
# array(['delivered', 'invoiced', 'shipped', 'processing', 'unavailable', 'canceled'], dtype=object)2. 원하는 행만 선택해서 조회(loc생략 가능)
# orders에서 주문이 취소된 행을 찾아, 첫번째 행만 선택
# (.loc)생략 가능!
order.loc[orders["주문상태"] == 'canceled'][:1]
# 주문ID: 397
orders[orders["주문상태"] == 'canceled'][:1]
# 주문ID: 397
# 같은 결과를 출력
.loc생략
참고자료: 네이버 블로그
2개 이상이어도 생략 가능
- 팀원의 어시

3. orders에서 마지막 행 선택(iloc 이용)
orders.tail(1)
# 주문ID: 999 데이터 출력
orders.iloc(-1)
# 주문ID: 999 데이터 출력
# 같은 결과를 출력⭐
.iloc(-1)
=.tail(1)
같은 결과를 출력함으로써 같은 역할을 하는 함수라는 것을 알 수 있었음!
굳이 상황에 맞는 함수를 외울 필요 없이 알고 있는 것만으로도 충분히 응용할 수 있다는 것을 파악
데이터 변형
- 컬럼 삭제
# df1["col2"] delete
df1.drop(columns = "col2", inplace = True)
# inplace = True/False 즉시 변경 유/무- 데이터 타입 변경하기
# df1["col1"] 타입을 float64 -> int64
df1["col1"].astype("int64")
df1.dtypes
# col1 - float64로 출력
df1["col1"] = df1["col1"].astype("int64")
df1.dtypes
# col1 - int64로 출력같은 컬럼에 할당해줘야 데이터 타입이 변경되는 것을 확인할 수 있음!
astype()에는 inplace= 가 없기 때문...
결측치 처리(삭제)
- 전체의 결측값을 확인하고 싶을 때
# df1
df1.isna().sum()
# df1의 각 컬럼별 전체 null 값의 개수를 알 수있음!- 전체 행, 열 알기
# df1 - 100 rows, 45 columns
df1.shape
# (100, 45)결측값 처리(삽입)
- 복사본 생성
# df1의 복사본인 df2 만들기
# deep = True/False (독립 유무)
# deep= True (default)
df2 = df1.copy()
df2 = df1.copy(deep=True)
# 전혀 다른 파일로 저장됨(흔히 아는 독립적인 복사본)
# deep = False
df2 = df1.copy(deep=False)
# df2/1에서 수정할 경우 연동되어 같이 변경됨오늘은 양이 많아서 새롭게 알게 된 것들만 자세히 적어보았다!
특히 loc가 왜 생략해도 가능한지 굉장히 궁금해서 구글링을 해도 시원하게 해결되는 느낌이 아니었는데, 팀원의 도움으로 이미 [] 자체가 인덱싱을 하기 때문에 생략이 가능하다는 것을 알게되었다.
SQL, Python, Code Kata